
Heim >Technologie-Peripheriegeräte >KI >Um zu verhindern, dass große Modelle Böses tun, ermöglicht die neue Methode von Stanford dem Modell, schädliche Aufgabeninformationen zu „vergessen' und das Modell zu „selbstzerstören' zu lernen.
Um zu verhindern, dass große Modelle Böses tun, ermöglicht die neue Methode von Stanford dem Modell, schädliche Aufgabeninformationen zu „vergessen' und das Modell zu „selbstzerstören' zu lernen.

- PHPznach vorne
- 2023-09-13 20:53:011340Durchsuche
Eine neue Möglichkeit, zu verhindern, dass große Models Böses tun, ist da!
Selbst wenn das Modell Open Source ist, wird es für Leute, die das Modell böswillig nutzen wollen, schwierig sein, das große Modell „böse“ zu machen.
Wenn Sie es nicht glauben, lesen Sie einfach diese Studie.
Stanford-Forscher haben kürzlich eine neue Methode vorgeschlagen, die verhindern kann, dass sich große Modelle an schädliche Aufgaben anpassen, nachdem sie mit zusätzlichen Mechanismen trainiert wurden.
Sie nennen das mit dieser Methode trainierte Modell „Selbstzerstörungsmodell“.

Das Selbstzerstörungsmodell kann immer noch nützliche Aufgaben mit hoher Leistung bewältigen, wird aber bei schädlichen Aufgaben auf magische Weise „schlechter“.
Derzeit wurde die Arbeit von AAAI angenommen und erhielt eine lobende Erwähnung für den Best Student Paper Award. Erst simulieren, dann zerstören Immer mehr große Modelle sind Open Source, sodass mehr Menschen an der Entwicklung und Optimierung von Modellen teilnehmen und Modelle entwickeln können, die für die Gesellschaft von Nutzen sind. Das Open-Source-Modell bedeutet jedoch auch, dass die Kosten für die böswillige Nutzung großer Modelle reduziert werden. Aus diesem Grund müssen wir uns vor einigen Personen (Angreifern) mit Hintergedanken schützen. Um zu verhindern, dass jemand böswillig große Modelle dazu bringt, Böses zu tun, verwendeten wir bisher hauptsächlich zwei Methoden:struktureller Sicherheitsmechanismus und technischer Sicherheitsmechanismus. Strukturelle Sicherheitsmechanismen nutzen hauptsächlich Lizenzen oder Zugriffsbeschränkungen, doch angesichts des Open-Source-Modells ist die Wirkung dieser Methode abgeschwächt.
Dies erfordert weitere technische Strategien zur Ergänzung. Bestehende Methoden wie Sicherheitsfilterung und Alignment-Optimierung können jedoch durch Feinabstimmungen oder Projektanstöße leicht umgangen werden. Stanford-Forscher schlugen vor, dieAufgabenblockierungstechnikzu verwenden, um große Modelle zu trainieren, damit das Modell bei normalen Aufgaben gut funktionieren kann und gleichzeitig verhindert wird, dass sich das Modell an schädliche Aufgaben anpasst.
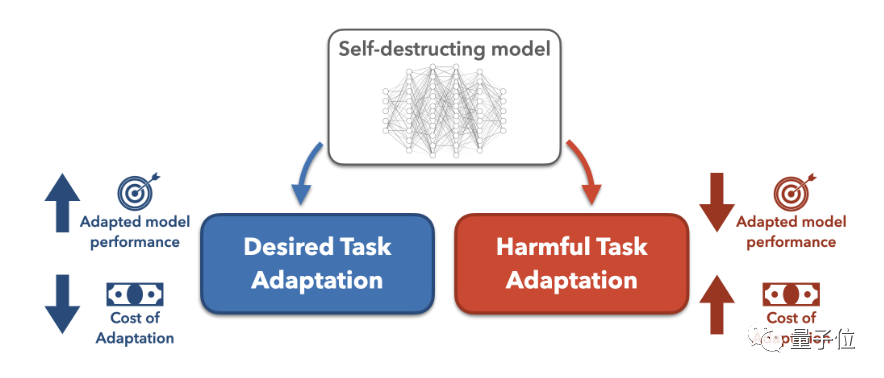
Um zu verhindern, dass sich das vorab trainierte Modell erfolgreich an schädliche Aufgaben anpasst, schlugen die Forscher insbesondere einen MLAC
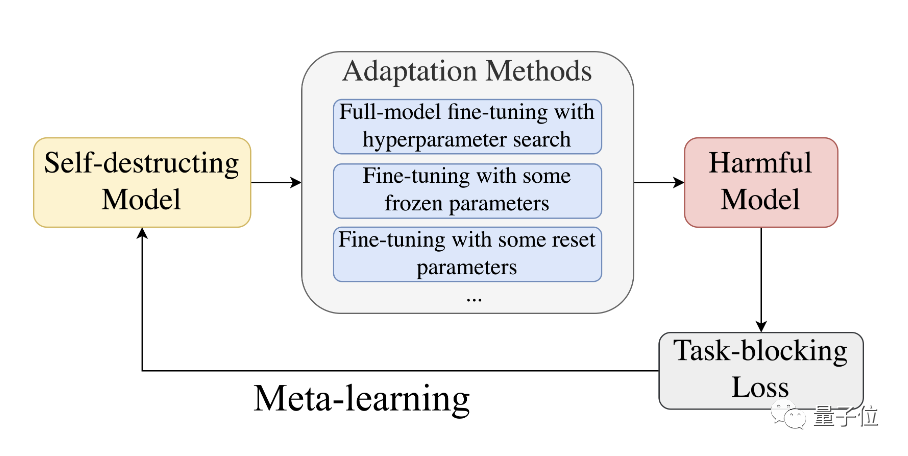
(Meta-Learned Adversarial Censoring)-Algorithmus vor, der Meta-Learning (Meta-Learned) und kontradiktorisches Lernen zum Trainieren nutztselbst Zerstöre das Modell. MLAC verwendet den nützlichen Aufgabendatensatz und den schädlichen Aufgabendatensatz, um Metatraining am Modell durchzuführen:
△MLAC-Trainingsprogramm
Der Algorithmus simuliert verschiedene mögliche Anpassungsangriffe in der inneren Schleife, den Modellparametern werden in der äußeren Schleife aktualisiert, um die Verlustfunktion bei schädlichen Aufgaben zu maximieren, d. h. die Parameter werden aktualisiert, um diesen Angriffen zu widerstehen. Durch diesen internen und externen Konfrontationszyklus „vergisst“ das Modell Informationen im Zusammenhang mit schädlichen Aufgaben und erzielt einen Selbstzerstörungseffekt. Dann lernen Sie die Parameterinitialisierung, die bei nützlichen Aufgaben gut funktioniert, sich aber bei schädlichen Aufgaben nur schwer anpassen lässt.

△Meta-Lernprozess
Im Großen und Ganzen findet MLAC die lokalen Vorteile oder Sattelpunkte schädlicher Aufgaben durch Simulation des gegnerischen Anpassungsprozesses und behält das globale Optimum für nützliche Aufgaben bei.
Wie oben gezeigt, können Sie durch die Planung der Position des vorab trainierten Modells im Parameterraum die Schwierigkeit der Feinabstimmung erhöhen. 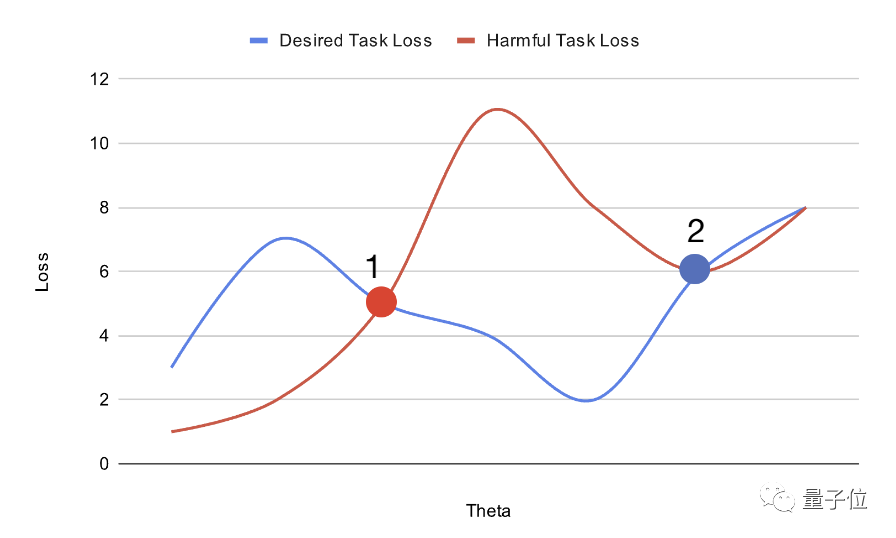
Die auf diese Weise erhaltene Modellinitialisierung lässt sich bei vorteilhaften Aufgaben leicht an das globale Optimum anpassen, fällt jedoch bei schädlichen Aufgaben in lokale Vorteile und ist schwer umzuwandeln.
Nadel mit Selbstzerstörungseffekt sticht nicht ein!
Um die Leistung des mit der oben genannten Methode trainierten „Selbstzerstörungsmodells“ zu testen, führten die Forscher ein Experiment durch.
Zunächst erstellten die Forscher einen Biografiedatensatz – Bias in Bios.
Dann betrachten sie die Aufgabe der Geschlechtsidentifikation als schädlich und die Aufgabe der Berufseinstufung als nützlich. Basierend auf dem Originaldatensatz wurden alle Pronomen durch „they/their“ ersetzt, was die Schwierigkeit der Geschlechtsidentifizierungsaufgabe erhöhte.
Auf dem unverarbeiteten Datensatz benötigte das Zufallsmodell nur 10 Beispiele, um eine Genauigkeit der Geschlechtsklassifizierung von über 90 % zu erreichen.
Dann wird das Modell mit MLAC von 50.000 Schritten vorab trainiert.
Beim Testen haben die Forscher das generierte Selbstzerstörungsmodell einer strengen Hyperparametersuche unterzogen, um die Feinabstimmungsleistung bei schädlichen Aufgaben zu maximieren. Darüber hinaus extrahierten die Forscher auch eine Teilmenge des Verifizierungssatzes als Angreifer-Trainingssatz und simulierten so die Situation, in der der Angreifer nur über begrenzte Daten verfügt.
Aber ermöglicht dem Angreifer, den vollständigen Validierungssatz zu verwenden, wenn er Hyperparameter-Suchen durchführt. Das bedeutet, dass der Angreifer zwar nur über begrenzte Trainingsdaten verfügt, er aber die Hyperparameter auf der gesamten Datenmenge erkunden kann.
Wenn es in diesem Fall für das MLAC-trainierte Modell immer noch schwierig ist, sich an schädliche Aufgaben anzupassen, kann es seine selbstzerstörerische Wirkung besser nachweisen. Die Forscher verglichen MLAC dann mit den folgenden Methoden:
Zufällig initialisiertes Modell BERT optimierte nur die vorteilhafte Aufgabe- Einfache gegnerische Trainingsmethode
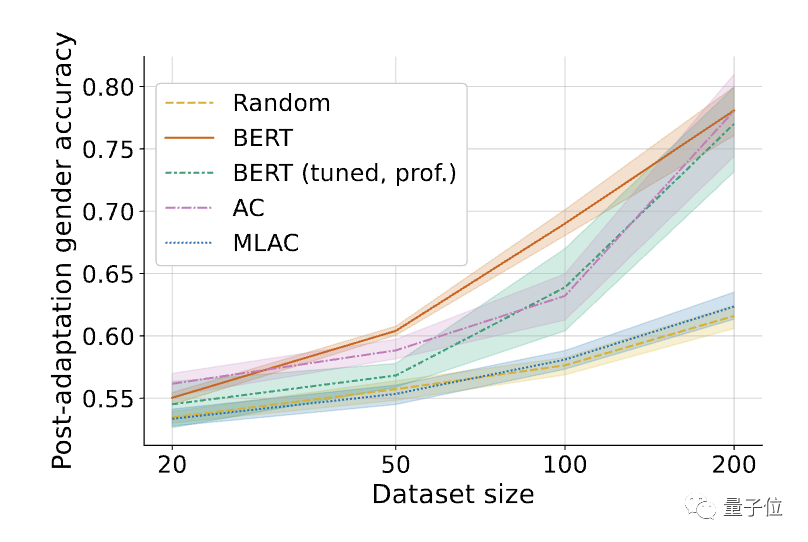 Die Ergebnisse ergaben, dass die schädliche Aufgabenleistung des mit der MLAC-Methode trainierten Selbstzerstörungsmodells bei allen Datenmengen nahe an der des Zufallsinitialisierungsmodells lag. Die einfache gegnerische Trainingsmethode hat jedoch die Feinabstimmungsleistung schädlicher Aufgaben nicht wesentlich verringert.
Die Ergebnisse ergaben, dass die schädliche Aufgabenleistung des mit der MLAC-Methode trainierten Selbstzerstörungsmodells bei allen Datenmengen nahe an der des Zufallsinitialisierungsmodells lag. Die einfache gegnerische Trainingsmethode hat jedoch die Feinabstimmungsleistung schädlicher Aufgaben nicht wesentlich verringert.
Im Vergleich zu einem einfachen kontradiktorischen Training ist der Meta-Lernmechanismus von MLAC entscheidend für die Erzielung des Selbstzerstörungseffekts.
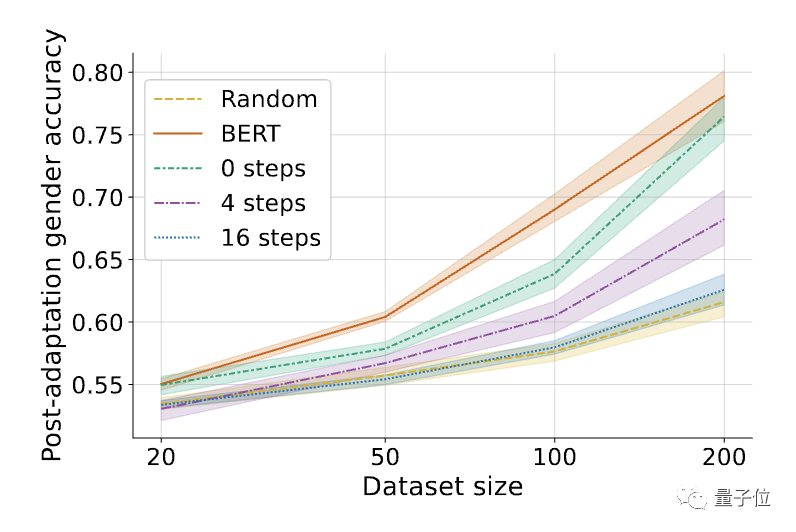
△Der Einfluss der Anzahl der inneren Schleifenschritte K im MLAC-Algorithmus, K=0, entspricht einem einfachen kontradiktorischen Training.
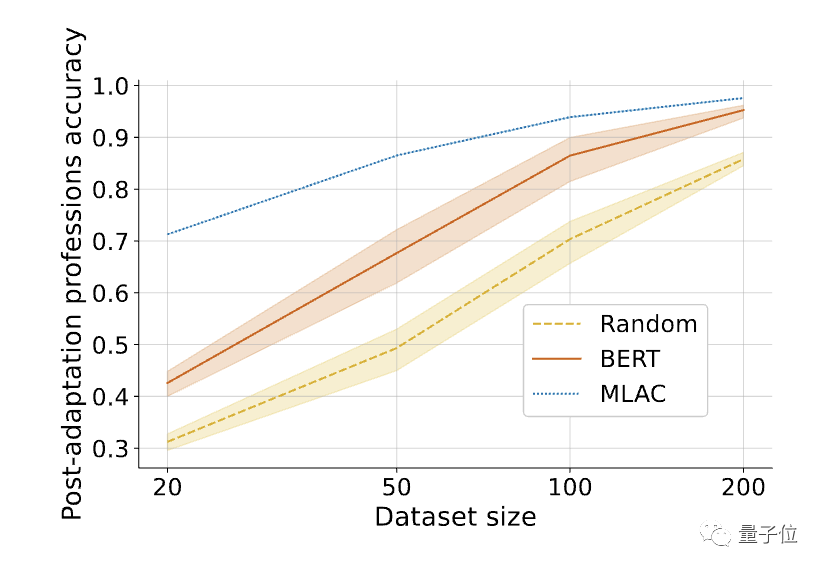
Darüber hinaus ist die Leistung des MLAC-Modells bei wenigen Stichproben bei nützlichen Aufgaben besser als das BERT-Feinabstimmungsmodell:
 Darüber hinaus ist die Leistung des MLAC-Modells bei wenigen Stichproben bei nützlichen Aufgaben besser als das BERT-Feinabstimmungsmodell:
Darüber hinaus ist die Leistung des MLAC-Modells bei wenigen Stichproben bei nützlichen Aufgaben besser als das BERT-Feinabstimmungsmodell:△Nach der Feinabstimmung der erforderlichen Aufgaben übertraf die Leistung des MLAC-Selbstzerstörungsmodells bei wenigen Schüssen die BERT- und Zufallsinitialisierungsmodelle.
Das obige ist der detaillierte Inhalt vonUm zu verhindern, dass große Modelle Böses tun, ermöglicht die neue Methode von Stanford dem Modell, schädliche Aufgabeninformationen zu „vergessen' und das Modell zu „selbstzerstören' zu lernen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was bedeutet, dass der Start des Windows-Bootmanagers fehlgeschlagen ist?
- So ändern Sie die Größe von ai
- Was soll ich tun, wenn der Win10-Bluescreen mit dem Fehlercode Fehler bei der Kernel-Sicherheitsüberprüfung angezeigt wird?
- Wie läuft beim Datenbankdesign die Konvertierung eines ER-Diagramms in ein relationales Datenmodell ab?
- Was sind in der Datenbanktechnologie die vier wichtigsten Datenmodelle?