
Heim >Technologie-Peripheriegeräte >KI >Entdecken Sie Trainingstechniken für Open-World-Testsegmente mithilfe von Selbsttrainingsmethoden mit dynamischen Prototyping-Erweiterungen
Entdecken Sie Trainingstechniken für Open-World-Testsegmente mithilfe von Selbsttrainingsmethoden mit dynamischen Prototyping-Erweiterungen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-09-13 14:17:10977Durchsuche
Die Verbesserung der Generalisierungsfähigkeit des Modells ist eine wichtige Grundlage für die Förderung der Implementierung visionsbasierter Wahrnehmungsmethoden. Testzeit-Training/Anpassung verallgemeinert das Modell auf unbekannte Zieldomänen, indem es die Modellparametergewichte im Datenverteilungssegment des Testabschnitts anpasst . Bestehende TTT/TTA-Methoden konzentrieren sich normalerweise auf die Verbesserung der Testsegment-Trainingsleistung unter Zieldomänendaten in der Welt mit geschlossenem Regelkreis.
In vielen Anwendungsszenarien wird die Zieldomäne jedoch leicht durch starke Daten außerhalb der Domäne (Strong OOD) kontaminiert, z. B. Daten, die keinen Bezug zu semantischen Kategorien haben. Dieses Szenario wird auch als Open World Test Segment Training (OWTTT) bezeichnet. In diesem Fall erzwingt das bestehende TTT/TTA normalerweise die Klassifizierung starker Daten außerhalb der Domäne in bekannte Kategorien, wodurch letztendlich die Fähigkeit beeinträchtigt wird, schwache Daten außerhalb der Domäne (Weak OOD) aufzulösen, wie z. B. Bilder, die gestört werden durch Lärm
Kürzlich haben die South China University of Technology und das A*STAR-Team zum ersten Mal die Einrichtung eines Open-World-Testsegmenttrainings vorgeschlagen und die entsprechende Trainingsmethode eingeführt

- Papier: https ://arxiv.org/abs/2308.09942
- Code: https://github.com/Yushu-Li/OWTTT
Dieses Papier schlägt zunächst eine starke Methode zum Filtern von Datenproben außerhalb der Domäne vor Adaptive Schwelle zur Verbesserung der selbstlernenden TTT-Methode in der offenen Welt der Robustheit. Diese Methode schlägt außerdem eine Methode zur Charakterisierung starker Stichproben außerhalb der Domäne basierend auf dynamisch erweiterten Prototypen vor, um den schwachen/starken Datentrennungseffekt außerhalb der Domäne zu verbessern. Schließlich wird das Selbsttraining durch die Verteilungsausrichtung eingeschränkt
Die Methode in dieser Studie erzielte die beste Leistung bei 5 verschiedenen OWTTT-Benchmarks und eröffnete eine neue Richtung für robustere TTT-Methoden für die nachfolgende Forschung zu TTT. Diese Forschungsarbeit wurde als mündlicher Präsentationsbeitrag beim ICCV 2023 angenommen Testdaten. Der Erfolg von TTT wurde an einer Reihe künstlich ausgewählter, synthetisch beschädigter Zieldomänendaten nachgewiesen. Allerdings sind die Leistungsgrenzen bestehender TTT-Methoden noch nicht vollständig erforscht.
Um TTT-Anwendungen in offenen Szenarien zu fördern, hat sich der Schwerpunkt der Forschung auf die Untersuchung von Szenarien verlagert, in denen TTT-Methoden möglicherweise versagen. Es wurden viele Anstrengungen unternommen, um stabile und robuste TTT-Methoden in realistischeren Open-World-Umgebungen zu entwickeln. In dieser Arbeit befassen wir uns mit einem häufigen, aber übersehenen Open-World-Szenario, bei dem die Zieldomäne möglicherweise Testdatenverteilungen enthält, die aus deutlich unterschiedlichen Umgebungen stammen, z. B. andere semantische Kategorien als die Quelldomäne oder einfach zufälliges Rauschen.
Wir nennen die oben genannten Testdaten starke Out-of-Distribution-Daten (starke OOD). Was in dieser Arbeit als schwache OOD-Daten bezeichnet wird, sind Testdaten mit Verteilungsverschiebungen, wie beispielsweise häufigen synthetischen Schäden. Daher motiviert uns der Mangel an vorhandener Arbeit zu dieser realistischen Umgebung, die Verbesserung der Robustheit des Open World Test Segment Training (OWTTT) zu untersuchen, bei dem die Testdaten durch starke OOD-Proben verunreinigt werden.
Abbildung 1: Bewertungsergebnisse der vorhandenen TTT-Methode unter der OWTTT-Einstellung
Wie in Abbildung 1 gezeigt, haben wir zunächst die vorhandene TTT-Methode unter der OWTTT-Einstellung bewertet und festgestellt, dass beide TTT-Methoden durch sich selbst erfolgen -Training und Verteilungsausrichtung werden durch starke OOD-Proben beeinflusst. Diese Ergebnisse zeigen, dass durch die Anwendung vorhandener TTT-Techniken kein sicheres Testzeittraining in der offenen Welt erreicht werden kann. Wir führen ihr Scheitern auf die folgenden zwei Gründe zurück. 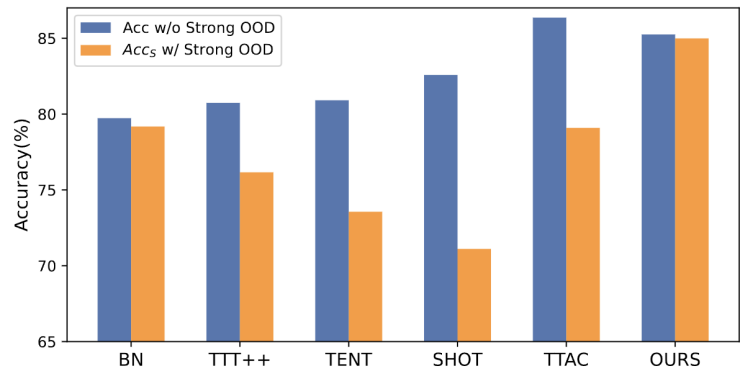
Das auf Selbsttraining basierende TTT hat Schwierigkeiten mit starken OOD-Proben, da es Testproben bekannten Kategorien zuordnen muss. Obwohl einige Stichproben mit geringer Konfidenz durch Anwendung des beim halbüberwachten Lernen verwendeten Schwellenwerts herausgefiltert werden können, gibt es immer noch keine Garantie dafür, dass alle starken OOD-Stichproben herausgefiltert werden.
Methoden, die auf der Verteilungsausrichtung basieren, sind betroffen, wenn starke OOD-Stichproben berechnet werden, um die Zieldomänenverteilung abzuschätzen. Sowohl die globale Verteilungsausrichtung [1] als auch die Klassenverteilungsausrichtung [2] können beeinträchtigt werden und zu einer ungenauen Ausrichtung der Merkmalsverteilung führen.
- Um die möglichen Gründe für das Scheitern bestehender TTT-Methoden zu lösen, schlagen wir eine Methode vor, die zwei Technologien kombiniert, um die Robustheit von Open-World-TTT im Rahmen eines Selbsttrainings-Frameworks zu verbessern
-
Zunächst bauen wir die Basislinie von TTT auf der selbst trainierten Variante auf, d. h. Clustering in der Zieldomäne mit dem Quelldomänen-Prototyp als Clusterzentrum. Um die Auswirkungen des Selbsttrainings auf starke OOD mit falschen Pseudo-Labels abzuschwächen, entwickeln wir eine hyperparameterfreie Methode zum Zurückweisen starker OOD-Proben.
Um die Eigenschaften schwacher OOD-Proben und starker OOD-Proben weiter zu trennen, ermöglichen wir die Erweiterung des Prototypenpools durch Auswahl isolierter starker OOD-Proben. Daher ermöglicht das Selbsttraining, dass starke OOD-Proben enge Cluster um den neu erweiterten starken OOD-Prototyp bilden. Dies erleichtert die Verteilungsausrichtung zwischen Quell- und Zieldomänen. Wir schlagen außerdem vor, das Selbsttraining durch eine globale Verteilungsausrichtung zu regulieren, um das Risiko einer Bestätigungsverzerrung zu verringern.
Um schließlich TTT-Szenarien in der offenen Welt zu synthetisieren, verwenden wir die Datensätze CIFAR10-C, CIFAR100-C, ImageNet-C, VisDA-C, ImageNet-R, Tiny-ImageNet, MNIST und SVHN und verwenden die Daten Der Satz ist ein schwacher OOD und die anderen sind ein starker OOD, um einen Benchmark-Datensatz zu erstellen. Wir bezeichnen diesen Benchmark als „Open World Test Segment Training Benchmark“ und hoffen, dass dies dazu anregt, dass sich künftig mehr Arbeiten auf die Robustheit des Testsegmenttrainings in realistischeren Szenarien konzentrieren.
Methode
Das Papier unterteilt die vorgeschlagene Methode in vier Teile, um
1) Überblick über die Einstellung des Testsegments Trainingsaufgabe in der offenen Welt vorzustellen.
2) Beschreibt, wie TTT über Umschreiben des Inhalts als: Clusteranalyse implementiert wird und wie der Prototyp für Open-World-Testzeittraining erweitert wird.
3) Einführung in die Verwendung von Zieldomänendaten für die dynamische Prototypenerweiterung.
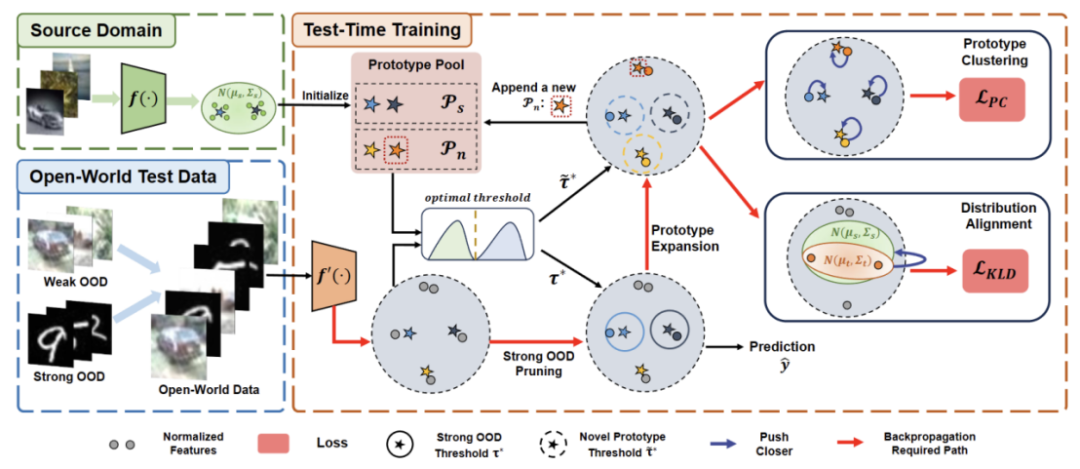
4) Einführung von Distribution Alignment in Kombination mit neu geschriebenen Inhalten: Clusteranalyse, um ein leistungsstarkes Open-World-Testzeittraining zu erreichen. Abbildung 2: Übersicht über die Methode relativ zur Verteilungsmigration der Quelldomäne. Im standardmäßigen Closed-World-TTT sind die Beschriftungsräume der Quell- und Zieldomänen gleich. Im Open-World-TTT enthält der Beschriftungsraum der Zieldomäne jedoch den Zielraum der Quelldomäne, was bedeutet, dass die Zieldomäne über bisher unbekannte neue semantische Kategorien verfügt
 Um Verwechslungen zwischen TTT-Definitionen zu vermeiden, übernehmen wir diese TTAC [2 Das in vorgeschlagene sTTT-Protokoll (Sequential Test Time Training)] wird evaluiert. Im Rahmen des sTTT-Protokolls werden Testproben nacheinander getestet und Modellaktualisierungen nach Beobachtung kleiner Testprobenchargen durchgeführt. Die Vorhersage für jede Testprobe, die zum Zeitstempel t ankommt, wird nicht von jeder Testprobe beeinflusst, die zum Zeitpunkt t+k ankommt (deren k größer als 0 ist).
Um Verwechslungen zwischen TTT-Definitionen zu vermeiden, übernehmen wir diese TTAC [2 Das in vorgeschlagene sTTT-Protokoll (Sequential Test Time Training)] wird evaluiert. Im Rahmen des sTTT-Protokolls werden Testproben nacheinander getestet und Modellaktualisierungen nach Beobachtung kleiner Testprobenchargen durchgeführt. Die Vorhersage für jede Testprobe, die zum Zeitstempel t ankommt, wird nicht von jeder Testprobe beeinflusst, die zum Zeitpunkt t+k ankommt (deren k größer als 0 ist). Umgeschriebener Inhalt als: Clusteranalyse
Inspiriert durch die Arbeit mit Clustering in Domänenanpassungsaufgaben [3,4] behandeln wir das Testsegmenttraining als Entdeckung von Clusterstrukturen in Zieldomänendaten. Durch die Identifizierung repräsentativer Prototypen als Clusterzentren werden Clusterstrukturen in der Zieldomäne identifiziert und Testproben werden dazu ermutigt, in der Nähe eines der Prototypen einzubetten. Der umgeschriebene Inhalt lautet: Das Ziel der Clusteranalyse besteht darin, den negativen Log-Likelihood-Verlust der Kosinusähnlichkeit zwischen der Stichprobe und dem Clusterzentrum zu minimieren, wie in der folgenden Formel dargestellt.
Wir entwickeln eine hyperparameterfreie Methode zum Herausfiltern starker OOD-Proben, um die negativen Auswirkungen der Anpassung der Modellgewichte zu vermeiden. Konkret definieren wir für jede Testprobe einen starken OOD-Score als höchste Ähnlichkeit zum Quelldomänen-Prototyp, wie in der folgenden Gleichung dargestellt.
Abbildung 3 Ausreißer zeigen eine bimodale Verteilung
Wir beobachten, dass die Ausreißer einer bimodalen Verteilung folgen, wie in Abbildung 3 dargestellt. Anstatt also einen festen Schwellenwert anzugeben, definieren wir den optimalen Schwellenwert als den besten Wert, der die beiden Verteilungen trennt. Konkret kann das Problem so formuliert werden, dass die Ausreißer in zwei Cluster aufgeteilt werden und der optimale Schwellenwert die Varianz innerhalb des Clusters minimiert. Die Optimierung der folgenden Gleichung kann effizient erreicht werden, indem alle möglichen Schwellenwerte von 0 bis 1 in Schritten von 0,01 umfassend durchsucht werden.
Dynamische Prototypenerweiterung
Die Erweiterung des Pools starker OOD-Prototypen erfordert die Berücksichtigung sowohl der Quelldomäne als auch des starken OOD-Prototyps zur Bewertung der Testbeispiele. Um die Anzahl der Cluster anhand von Daten dynamisch abzuschätzen, wurden in früheren Studien ähnliche Probleme untersucht. Der deterministische Hard-Clustering-Algorithmus DP-means [5] wurde entwickelt, indem der Abstand von Datenpunkten zu bekannten Clusterzentren gemessen wurde. Ein neuer Cluster wird initialisiert, wenn der Abstand über einem Schwellenwert liegt. DP-Means entspricht nachweislich der Optimierung des K-Means-Ziels, allerdings mit einem zusätzlichen Nachteil bei der Anzahl der Cluster, was eine praktikable Lösung für die dynamische Prototypenerweiterung darstellt.
Um die Schwierigkeit der Schätzung zusätzlicher Hyperparameter zu verringern, definieren wir zunächst eine Teststichprobe mit einem erweiterten starken OOD-Score als den nächsten Abstand zum vorhandenen Quelldomänen-Prototyp und dem starken OOD-Prototyp wie folgt. Daher wird durch das Testen von Proben über diesem Schwellenwert ein neuer Prototyp erstellt. Um das Hinzufügen von Testmustern in der Nähe zu vermeiden, wiederholen wir diesen Prototypenerweiterungsprozess schrittweise.
Nachdem wir weitere starke OOD-Prototypen identifiziert hatten, definierten wir die Umschreibung für das Testbeispiel wie folgt: Verlust der Clusteranalyse unter Berücksichtigung von zwei Faktoren. Erstens sollten in bekannte Klassen klassifizierte Testmuster näher an Prototypen und weiter entfernt von anderen Prototypen eingebettet werden, was die K-Klassen-Klassifizierungsaufgabe definiert. Zweitens sollten als starke OOD-Prototypen klassifizierte Testproben weit entfernt von Prototypen der Quelldomäne sein, was die K+1-Klassenklassifizierungsaufgabe definiert. Mit diesen Zielen vor Augen werden wir den Inhalt wie folgt umschreiben: Der Verlust der Clusteranalyse wird wie folgt definiert.
Einschränkungen bei der verteilten Ausrichtung bedeuten, dass in einem Design oder Layout Elemente auf eine bestimmte Weise angeordnet und ausgerichtet werden müssen. Diese Einschränkung kann auf eine Vielzahl verschiedener Szenarien angewendet werden, darunter Webdesign, Grafikdesign und Raumlayout. Durch die Verwendung verteilter Ausrichtungsbeschränkungen kann die Beziehung zwischen Elementen klarer und einheitlicher gestaltet werden, wodurch die Ästhetik und Lesbarkeit des Gesamtdesigns verbessert wird
Es ist bekannt, dass Selbsttraining anfällig für fehlerhafte Pseudobezeichnungen ist. Die Situation wird noch schlimmer, wenn die Zieldomäne aus OOD-Proben besteht. Um das Risiko eines Ausfalls zu verringern, verwenden wir außerdem die Verteilungsausrichtung [1] wie folgt als Regularisierung für das Selbsttraining.
Experimente
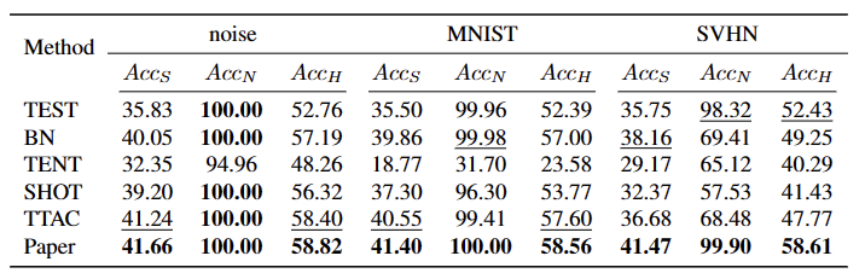
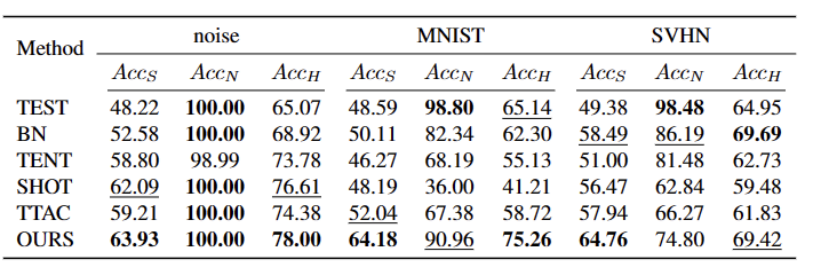
Wir haben fünf verschiedene OWTTT-Benchmark-Datensätze getestet, darunter synthetisch beschädigte Datensätze und stilvariierende Datensätze. Das Experiment verwendet hauptsächlich drei Bewertungsindikatoren: schwache OOD-Klassifizierungsgenauigkeit ACCS, starke OOD-Klassifizierungsgenauigkeit ACCN und das harmonische Mittel der beiden ACCH Die Leistung der Methode ist in der folgenden Tabelle aufgeführt. Der Inhalt, der neu geschrieben werden muss, ist: Die Leistung verschiedener Methoden im Cifar100-C-Datensatz ist in der folgenden Tabelle aufgeführt: Der Inhalt, der neu geschrieben werden muss, ist: Im ImageNet-C-Datensatz ist die Leistung verschiedener Methoden in der folgenden Tabelle dargestellt
Tabelle 4 Leistung verschiedener Methoden beim ImageNet-R-Datensatz
Tabelle 5 Leistung verschiedener Methoden beim VisDA-C-Datensatz
Unsere Methode ist bei fast allen Daten konsistent Sets Im Vergleich zu den derzeit besten Methoden gibt es erhebliche Verbesserungen, wie in der obigen Tabelle gezeigt. Es kann starke OOD-Proben effektiv identifizieren und die Auswirkungen auf die Klassifizierung schwacher OOD-Proben verringern. Daher kann unsere Methode im Open-World-Szenario eine robustere TTT erreichen Bei der Verarbeitung von Zieldomänendaten, die starke OOD-Proben enthalten, die semantische Offsets von Quelldomänenproben aufweisen, wird eine selbstlernende Methode vorgeschlagen, die auf der dynamischen Prototypenerweiterung basiert. Wir hoffen, dass diese Arbeit neue Wege für die nachfolgende TTT-Forschung bieten kann, um robustere TTT-Methoden zu erforschen
 Um Verwechslungen zwischen TTT-Definitionen zu vermeiden, übernehmen wir diese TTAC [2 Das in vorgeschlagene sTTT-Protokoll (Sequential Test Time Training)] wird evaluiert. Im Rahmen des sTTT-Protokolls werden Testproben nacheinander getestet und Modellaktualisierungen nach Beobachtung kleiner Testprobenchargen durchgeführt. Die Vorhersage für jede Testprobe, die zum Zeitstempel t ankommt, wird nicht von jeder Testprobe beeinflusst, die zum Zeitpunkt t+k ankommt (deren k größer als 0 ist).
Um Verwechslungen zwischen TTT-Definitionen zu vermeiden, übernehmen wir diese TTAC [2 Das in vorgeschlagene sTTT-Protokoll (Sequential Test Time Training)] wird evaluiert. Im Rahmen des sTTT-Protokolls werden Testproben nacheinander getestet und Modellaktualisierungen nach Beobachtung kleiner Testprobenchargen durchgeführt. Die Vorhersage für jede Testprobe, die zum Zeitstempel t ankommt, wird nicht von jeder Testprobe beeinflusst, die zum Zeitpunkt t+k ankommt (deren k größer als 0 ist). 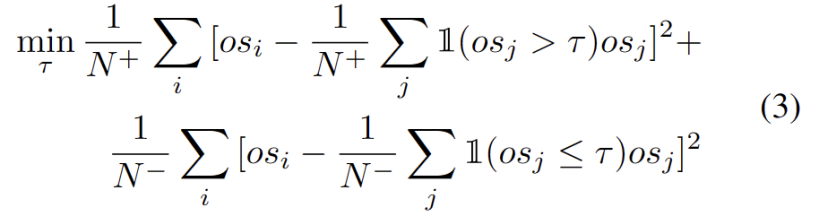
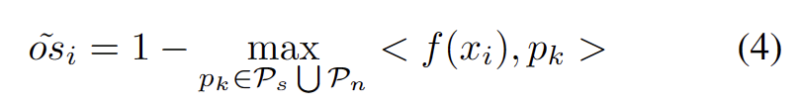
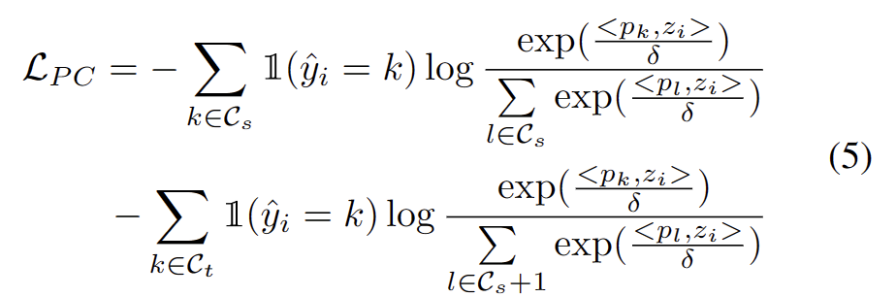
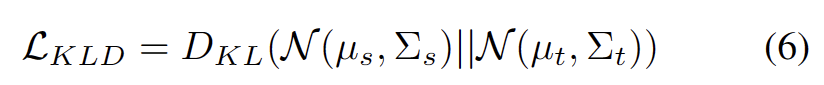
Das obige ist der detaillierte Inhalt vonEntdecken Sie Trainingstechniken für Open-World-Testsegmente mithilfe von Selbsttrainingsmethoden mit dynamischen Prototyping-Erweiterungen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So verwenden Sie das PHP-Unit-Test-Framework PHPUnit
- Was ist Java-Unit-Test?
- PHP 8 ist da! Das PHP-Team veröffentlicht die erste Beta-Version Alpha1
- Die erste behördliche Überprüfung von ChatGPT stammt möglicherweise von der US-amerikanischen Federal Trade Commission, OpenAI: noch nicht trainiertes GPT5
- Zoom sorgt für Transparenz bei der Datennutzung und stellt sicher, dass das KI-Training der Zustimmung des Benutzers unterliegt