
Heim >Technologie-Peripheriegeräte >KI >Die H100-Argumentation ist um das Achtfache gestiegen! NVIDIA hat offiziell Open-Source-TensorRT-LLM angekündigt, das mehr als 10 Modelle unterstützt
Die H100-Argumentation ist um das Achtfache gestiegen! NVIDIA hat offiziell Open-Source-TensorRT-LLM angekündigt, das mehr als 10 Modelle unterstützt

- 王林nach vorne
- 2023-09-10 16:41:011636Durchsuche
Die „GPU-Armen“ sind dabei, sich aus ihrer misslichen Lage zu verabschieden!
Gerade hat NVIDIA eine Open-Source-Software namens TensorRT-LLM veröffentlicht, die den Inferenzprozess großer Sprachmodelle, die auf H100 laufen, beschleunigen kann

Also, wie oft kann es verbessert werden?
Nachdem TensorRT-LLM und seine Reihe von Optimierungsfunktionen (einschließlich In-Flight-Stapelverarbeitung) hinzugefügt wurden, erhöhte sich der Gesamtdurchsatz des Modells um das Achtfache.
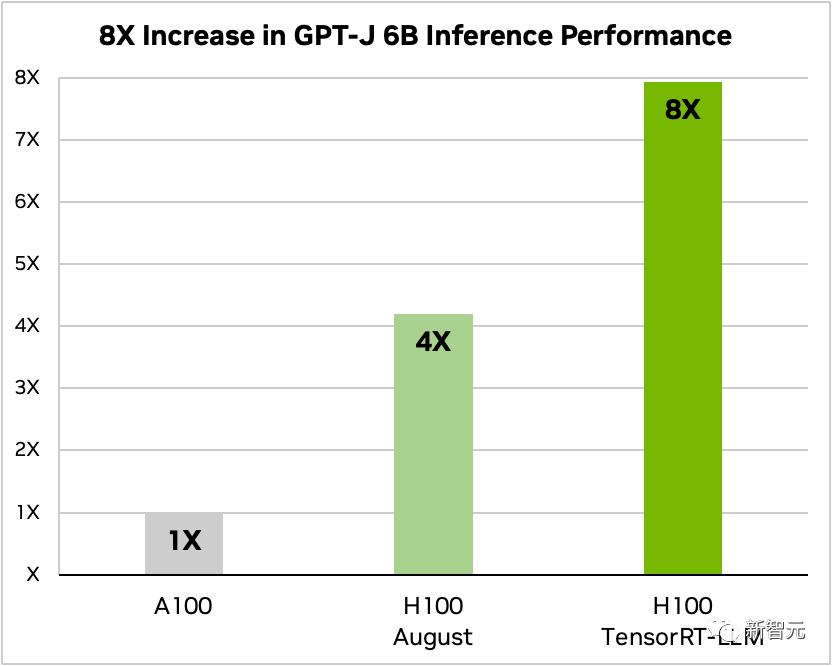
Vergleich von GPT-J-6B A100 und H100 mit und ohne TensorRT-LLM
Am Beispiel von Llama 2 kann TensorRT-LLM außerdem die Inferenzleistung im Vergleich zur unabhängigen Verwendung von A100 verbessern 4,6-fache Verbesserung
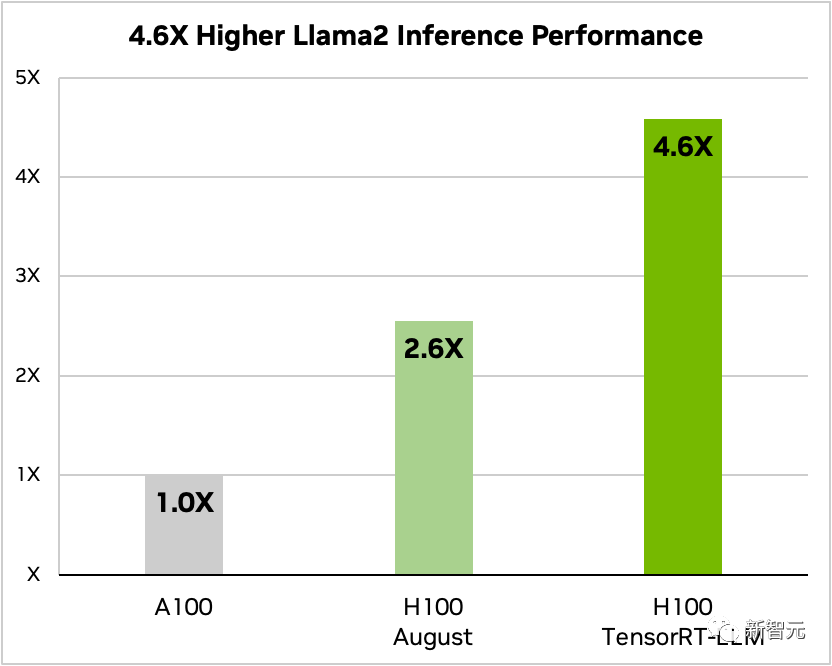
Vergleich von Llama 2 70B, A100 und H100 mit und ohne TensorRT-LLM
Netizens sagten, dass der Super-H100 in Kombination mit TensorRT-LLM zweifellos ist Es wird den Strom komplett verändern Situation der Inferenz großer Sprachmodelle!

TensorRT-LLM: Großes Modellinferenzbeschleunigungsartefakt
Aufgrund der großen Parameterskala großer Modelle sind derzeit die Schwierigkeit und die Kosten für „Bereitstellung und Inferenz“ immer hoch.
Das von NVIDIA entwickelte TensorRT-LLM zielt darauf ab, den Durchsatz von LLM deutlich zu verbessern und die Kosten durch die GPU zu senken.

Konkret optimiert TensorRT-LLM den Deep-Learning-Compiler und den FasterTransformer-Kernel von TensorRT sowie die Vor- und Nachverarbeitung , und Multi-GPU/Multi-Node-Kommunikation sind in einer einfachen Open-Source-Python-API gekapselt
NVIDIA hat FasterTransformer weiter verbessert, um es zu einer Produktionslösung zu machen.
Es ist ersichtlich, dass TensorRT-LLM eine benutzerfreundliche, quelloffene und modulare Python-Anwendungsprogrammierschnittstelle bietet.
Programmierer, die keine tiefgreifenden Kenntnisse in C++ oder CUDA benötigen, können verschiedene umfangreiche Sprachmodelle bereitstellen, ausführen und debuggen und profitieren von hervorragender Leistung und schneller Anpassung

Laut dem offiziellen Blog von NVIDIA TensorRT-LLM verwendet vier Methoden, um die LLM-Inferenzleistung auf Nvidia-GPUs zu verbessern.
Zunächst wird TensorRT-LLM für die aktuellen über 10 großen Modelle eingeführt, sodass Entwickler es sofort ausführen können.
Zweitens ermöglicht TensorRT-LLM als Open-Source-Softwarebibliothek LLM, Inferenzen auf mehreren GPUs und mehreren GPU-Servern gleichzeitig durchzuführen.
Diese Server sind über die NVLink- bzw. InfiniBand-Verbindungen von NVIDIA verbunden.
Der dritte Punkt betrifft die „In-Machine-Batch-Verarbeitung“, eine neue Planungstechnologie, die es Aufgaben verschiedener Modelle ermöglicht, unabhängig von anderen Aufgaben in die GPU einzutreten und diese zu verlassen.
Schließlich wurde TensorRT-LLM verwendet Optimiert können Sie die H100 Transformer Engine verwenden, um die Speichernutzung und Latenz während der Modellinferenz zu reduzieren.
Lassen Sie uns einen detaillierten Blick darauf werfen, wie TensorRT-LLM die Modellleistung verbessert.
Unterstützt ein reichhaltiges LLM-Ökosystem : Die größten und fortschrittlichsten Sprachmodelle, wie z. B. Llama 2-70B von Meta, erfordern die Zusammenarbeit mehrerer GPUs, um Antworten in Echtzeit bereitzustellen KI-Modell erstellen und in mehrere Teile zerlegen, dann die Ausführung zwischen GPUs koordinieren

TensorRT-LLM verwendet Tensor-Parallel-Technologie, um die Gewichtsmatrix auf jedes Gerät zu verteilen, wodurch der Prozess vereinfacht und eine effiziente Inferenz im Maßstab ermöglicht wird.
Jedes Modell kann auf mehreren Geräten ausgeführt werden, die über NVLink verbunden sind. Läuft parallel auf mehrere GPUs und mehrere Server ohne Entwicklereingriff oder Modelländerungen.
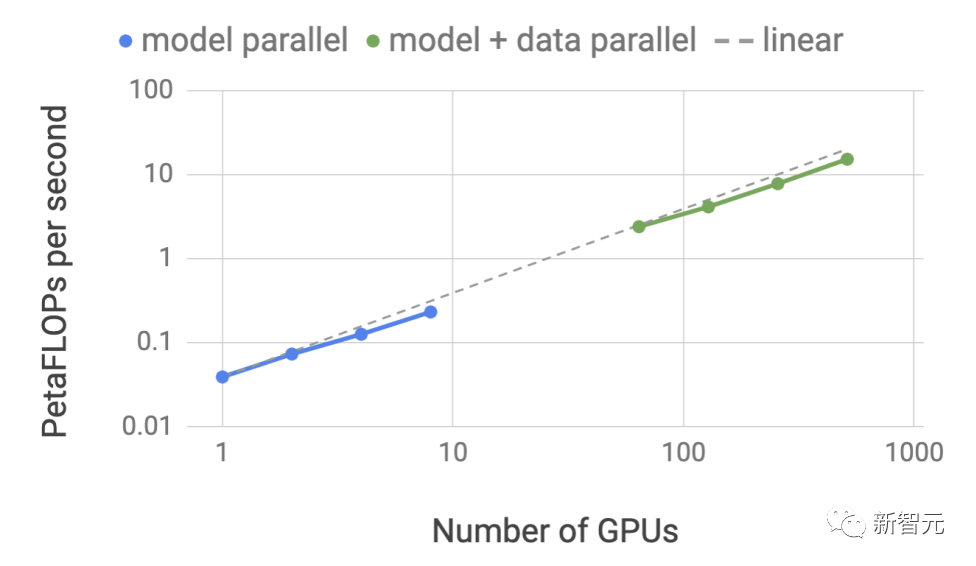
Mit der Einführung neuer Modelle und Modellarchitekturen können Entwickler den neuesten NVIDIA AI-Kernel (Kernal) Open Source in TensorRT-LLM verwenden, um Modelle zu optimieren
Was neu geschrieben werden muss, ist: Unterstützter Kernal Fusion umfasst die neueste FlashAttention-Implementierung sowie maskierte Multi-Head-Aufmerksamkeit für die Kontext- und Generierungsphasen der GPT-Modellausführung usw.
Darüber hinaus enthält TensorRT-LLM auch viele der derzeit beliebten großen Sprachmodelle Fully optimierte, betriebsbereite Version.
Zu diesen Modellen gehören Meta Llama 2, OpenAI GPT-2 und GPT-3, Falcon, Mosaic MPT, BLOOM und mehr als zehn weitere. Alle diese Modelle können über die benutzerfreundliche TensorRT-LLM-Python-API aufgerufen werden
Diese Funktionen können Entwicklern dabei helfen, benutzerdefinierte große Sprachmodelle schneller und genauer zu erstellen, um den unterschiedlichen Anforderungen verschiedener Branchen gerecht zu werden.
Stapelverarbeitung während des Flugs
Heutzutage sind große Sprachmodelle äußerst vielseitig.
Ein Modell kann gleichzeitig für mehrere scheinbar unterschiedliche Aufgaben verwendet werden – von einfachen Fragen und Antworten in einem Chatbot über die Zusammenfassung von Dokumenten bis hin zur Generierung langer Codeblöcke. Die Arbeitslasten sind hochdynamisch und die Ausgabegrößen müssen den Anforderungen für Aufgaben von erfüllt werden verschiedene Größenordnungen.
Die Vielfalt der Aufgaben kann es schwierig machen, Anfragen effektiv zu stapeln und eine effiziente parallele Ausführung durchzuführen, was möglicherweise dazu führt, dass einige Anfragen früher abgeschlossen werden als andere.

Um diese dynamischen Belastungen zu bewältigen, enthält TensorRT-LLM eine optimierte Planungstechnologie namens „In-flight Batching“.
Das Kernprinzip großer Sprachmodelle besteht darin, dass der gesamte Textgenerierungsprozess durch mehrere Iterationen des Modells erreicht werden kann.
Bei der Stapelverarbeitung während des Flugs wird die TensorRT-LLM-Laufzeit sofort aus dem Stapel freigegeben, wenn Es wird nicht darauf gewartet, dass der gesamte Stapel abgeschlossen ist, bevor mit dem nächsten Satz von Anforderungen fortgefahren wird, sondern die abgeschlossene Sequenz.
Während der Ausführung einer neuen Anfrage werden andere Anfragen aus dem vorherigen Stapel, die noch nicht abgeschlossen wurden, noch verarbeitet.
Verbesserte GPU-Auslastung durch Batching in der Maschine und zusätzliche Optimierungen auf Kernel-Ebene, was zu mindestens dem doppelten Durchsatz realer Anforderungsbenchmarks für LLM auf H100 führt
Verwendung der H100-Transformer-Engine von FP 8
TensorRT- LLM bietet außerdem eine Funktion namens H100 Transformer Engine, die den Speicherverbrauch und die Latenz während großer Modellinferenzen effektiv reduzieren kann.
Da LLM Milliarden von Modellgewichten und Aktivierungsfunktionen enthält, wird es normalerweise mit FP16- oder BF16-Werten trainiert und dargestellt, die jeweils 16 Bit Speicher belegen.
Zur Inferenzzeit können die meisten Modelle jedoch mithilfe von Quantisierungstechniken, wie z. B. 8-Bit- oder sogar 4-Bit-Ganzzahlen (INT8 oder INT4), effizient und mit geringerer Präzision dargestellt werden.
Quantisierung ist der Prozess der Reduzierung von Modellgewichten und Aktivierungsgenauigkeit ohne Einbußen bei der Genauigkeit. Die Verwendung einer geringeren Präzision bedeutet, dass jeder Parameter kleiner ist und das Modell weniger Platz im GPU-Speicher beansprucht.

Auf diese Weise können Sie dieselbe Hardware verwenden, um größere Modelle abzuleiten, und gleichzeitig den Zeitverbrauch für Speicheroperationen während des Ausführungsprozesses reduzieren
Durch die H100 Transformer Engine-Technologie in Kombination mit TensorRT-LLM The H100 GPU ermöglicht es Benutzern, Modellgewichte einfach in das neue FP8-Format zu konvertieren und Modelle automatisch zu kompilieren, um die Vorteile optimierter FP8-Kerne zu nutzen.
Und dieser Vorgang erfordert keine Codierung! Das von H100 eingeführte FP8-Datenformat ermöglicht Entwicklern die Quantifizierung ihrer Modelle und eine drastische Reduzierung des Speicherverbrauchs, ohne die Modellgenauigkeit zu beeinträchtigen.
Im Vergleich zu anderen Datenformaten wie INT8 oder INT4 behält die FP8-Quantisierung eine höhere Präzision bei, erzielt gleichzeitig die schnellste Leistung und ist am bequemsten zu implementieren. Im Vergleich zu anderen Datenformaten wie INT8 oder INT4 behält die FP8-Quantisierung eine höhere Genauigkeit bei, erzielt gleichzeitig die schnellste Leistung und ist am bequemsten zu implementieren
So erhalten Sie TensorRT-LLM
Obwohl TensorRT-LLM noch nicht offiziell veröffentlicht ist, aber Benutzer können es jetzt im Voraus erleben. Der Anwendungslink lautet wie folgt: TensorRT-LLM wurde schnell in das NVIDIA NeMo-Framework integriert.
Dieses Framework ist Teil des kürzlich von NVIDIA eingeführten AI Enterprise und bietet Unternehmenskunden eine sichere, stabile und hochverwaltbare KI-Softwareplattform auf Unternehmensebene.
Entwickler und Forscher können das NeMo-Framework auf NVIDIA NGC nutzen oder Projekt auf GitHub, um auf TensorRT-LLM zuzugreifen
Es ist jedoch zu beachten, dass sich Benutzer für das NVIDIA Developer Program registrieren müssen, um sich für die Early-Access-Version zu bewerben.
Heiße Diskussion unter Internetnutzern
Benutzer auf Reddit hatten eine hitzige Diskussion über die Veröffentlichung von TensorRT-LLMMan kann sich kaum vorstellen, wie sehr sich der Effekt nach der Optimierung der Hardware speziell für LLM verbessern wird.
Aber einige Internetnutzer glauben, dass der Sinn dieser Sache darin besteht, Lao Huang dabei zu helfen, mehr H100 zu verkaufen.
Einige Internetnutzer haben unterschiedliche Meinungen dazu. Sie glauben, dass Tensor RT auch für Benutzer hilfreich ist, die Deep Learning lokal einsetzen. Solange Sie über eine RTX-GPU verfügen, können Sie in Zukunft möglicherweise auch von ähnlichen Produkten profitieren. und vielleicht ist sogar Hardware entstanden, die speziell für LLM entwickelt wurde, um dessen Leistung zu verbessern. Diese Situation ist in vielen gängigen Anwendungen aufgetreten, und LLM ist keine Ausnahme

Das obige ist der detaillierte Inhalt vonDie H100-Argumentation ist um das Achtfache gestiegen! NVIDIA hat offiziell Open-Source-TensorRT-LLM angekündigt, das mehr als 10 Modelle unterstützt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So exportieren Sie ein Modell in Navicat
- Was bedeutet das Python-IPO-Modell?
- So berechnen Sie die Größe des CSS-Box-Modells
- Auf welcher Ebene des osi-Modells ist die Pfadauswahlfunktion abgeschlossen?
- Enthüllung der AMD-Konferenz: EPYC-Prozessor der neuen Generation und MI300-Grafikkarte konkurrieren mit NVIDIA