
Heim >Technologie-Peripheriegeräte >KI >Baichuan Intelligent hat das große Modell Baichuan2 veröffentlicht: Es ist Llama2 weit voraus und die Trainings-Slices sind ebenfalls Open Source
Baichuan Intelligent hat das große Modell Baichuan2 veröffentlicht: Es ist Llama2 weit voraus und die Trainings-Slices sind ebenfalls Open Source

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-09-07 15:13:051330Durchsuche
Als die Branche überrascht war, dass Baichuan Intelligent in durchschnittlich 28 Tagen ein großes Modell herausbrachte, gab das Unternehmen nicht auf.
Auf einer Pressekonferenz am Nachmittag des 6. September kündigte Baichuan Intelligence die offizielle Open Source des fein abgestimmten großen Baichuan-2-Modells an.
 Zhang Bo, Akademiker der Chinesischen Akademie der Wissenschaften und Ehrendekan des Instituts für Künstliche Intelligenz der Tsinghua-Universität, war bei der Pressekonferenz.
Zhang Bo, Akademiker der Chinesischen Akademie der Wissenschaften und Ehrendekan des Instituts für Künstliche Intelligenz der Tsinghua-Universität, war bei der Pressekonferenz.
Dies ist eine weitere Neuerscheinung von Baichuan seit der Veröffentlichung des großen Modells Baichuan-53B im August. Zu den Open-Source-Modellen gehören Baichuan2-7B, Baichuan2-13B, Baichuan2-13B-Chat und ihre 4-Bit-quantisierten Versionen, und sie sind alle kostenlos und im Handel erhältlich.
Zusätzlich zur vollständigen Offenlegung des Modells hat Baichuan Intelligence dieses Mal auch den Check Point für das Modelltraining als Open Source bereitgestellt und den technischen Bericht zu Baichuan 2 veröffentlicht, in dem die Trainingsdetails des neuen Modells detailliert beschrieben werden. Wang Xiaochuan, Gründer und CEO von Baichuan Intelligence, äußerte die Hoffnung, dass dieser Schritt großen akademischen Institutionen, Entwicklern und Unternehmensanwendern helfen kann, ein tiefgreifendes Verständnis des Trainingsprozesses großer Modelle zu erlangen und die technologische Entwicklung großer Modelle besser voranzutreiben akademische Forschung und Gemeinschaften.
Baichuan 2 großes Modell Original-Link: https://github.com/baichuan-inc/Baichuan2
Technischer Bericht: https://cdn.baichuan-ai.com/paper/Baichuan2-technical-report.pdf
Heutige Open-Source-Modelle sind im Vergleich zu großen Modellen „kleiner“. Unter ihnen werden Baichuan2-7B-Base und Baichuan2-13B-Base beide auf der Grundlage von 2,6 Billionen hochwertigen mehrsprachigen Daten trainiert, wobei die vorherige Generation von Open-Source-Modellen beibehalten wird Aufgrund vieler Merkmale wie guter Generierungs- und Erstellungsfähigkeiten, reibungsloser Mehrrundendialogfähigkeiten und niedriger Bereitstellungsschwellen haben die beiden Modelle ihre Fähigkeiten in den Bereichen Mathematik, Codierung, Sicherheit, logisches Denken und semantisches Verständnis erheblich verbessert.
„Um es einfach auszudrücken: Das 7-Milliarden-Parametermodell von Baichuan7B ist bereits auf Augenhöhe mit dem 13-Milliarden-Parametermodell von LLaMA2 auf dem englischen Benchmark. Daher können wir das Kleine verwenden, um das Große zu machen, das kleine Modell entspricht dem.“ „Fähigkeit des großen Modells und im selben Körper Das quantitative Modell kann eine höhere Leistung erzielen und die Leistung von LLaMA2 umfassend übertreffen“, sagte Wang Xiaochuan.
Im Vergleich zum 13B-Modell der vorherigen Generation hat Baichuan2-13B-Base seine mathematischen Fähigkeiten um 49 %, seine Codierungsfähigkeiten um 46 %, seine Sicherheitsfähigkeiten um 37 %, seine logischen Denkfähigkeiten um 25 % und seine semantischen Verständnisfähigkeiten um 15 % verbessert. .
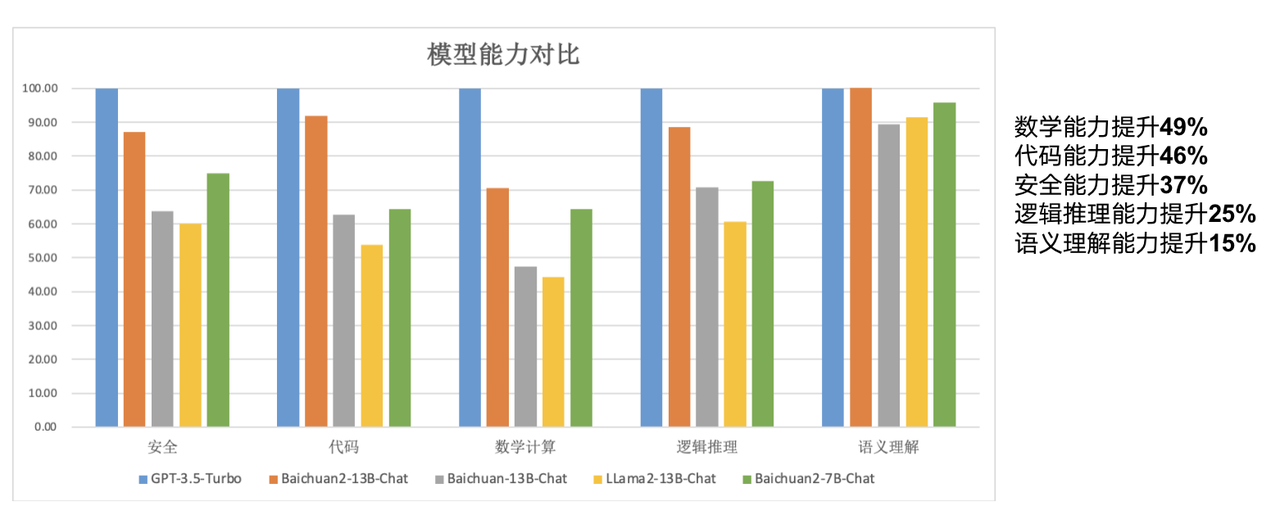
Berichten zufolge haben Forscher von Baichuan Intelligence zahlreiche Optimierungen vorgenommen, von der Datenerfassung bis zur Feinabstimmung des neuen Modells.
„Wir haben auf mehr Erfahrungen aus früheren Suchvorgängen zurückgegriffen, eine Inhaltsqualitätsbewertung mit mehreren Granularitäten für eine große Menge an Modelltrainingsdaten durchgeführt, 260 Millionen T Korpusebene zum Trainieren von 7B- und 13B-Modellen verwendet und mehrsprachige Unterstützung hinzugefügt.“ sagte Wang Xiaochuan. „Wir können im Qianka A800-Cluster eine Trainingsleistung von 180 TFLOPS erreichen und die Maschinenauslastung übersteigt 50 %. Darüber hinaus haben wir auch viele Arbeiten zur Sicherheitsausrichtung abgeschlossen
Die beiden Open-Source-Modelle sind dieses Mal weit verbreitet.“ Die Leistung auf der Bewertungsliste ist hervorragend. In mehreren maßgeblichen Bewertungsbenchmarks wie MMLU, CMMLU und GSM8K liegt es mit großem Abstand vor LLaMA2. Im Vergleich zu anderen Modellen mit der gleichen Anzahl von Parametern ist seine Leistung ebenfalls sehr hoch beeindruckend und seine Leistung ist deutlich besser als bei einem Konkurrenzprodukt mit dem gleichen Modell.
Was noch erwähnenswert ist, ist, dass Baichuan2-7B laut mehreren maßgeblichen englischen Bewertungsbenchmarks wie MMLU mit 13 Milliarden Parametern auf Augenhöhe mit LLaMA2 liegt, bei Standard-Englischaufgaben mit 7 Milliarden Parametern.
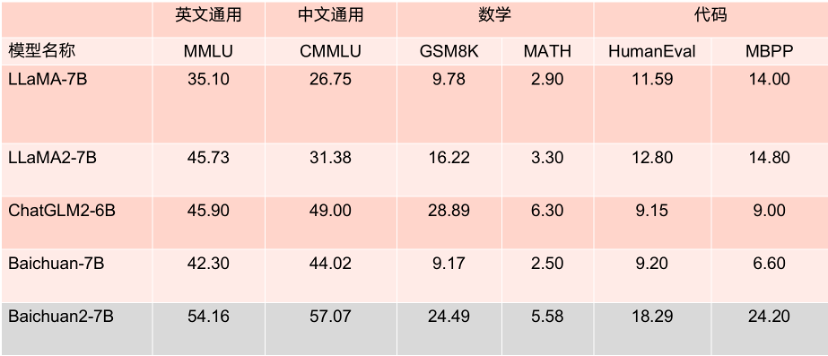
Benchmark-Ergebnisse des 7B-Parametermodells.
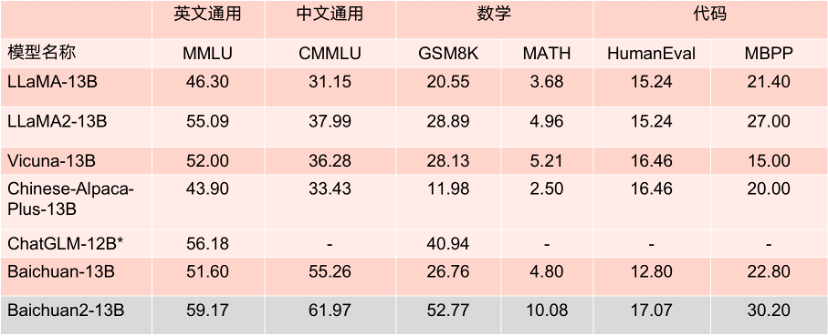
Benchmark-Ergebnisse des 13B-Parametermodells.
Baichuan2-7B und Baichuan2-13B stehen nicht nur der akademischen Forschung vollständig offen, sondern Entwickler können sie auch kostenlos kommerziell nutzen, nachdem sie per E-Mail eine offizielle kommerzielle Lizenz beantragt haben.
„Neben der Modellveröffentlichung hoffen wir auch, den akademischen Bereich stärker zu unterstützen“, sagte Wang Xiaochuan. „Zusätzlich zum technischen Bericht haben wir auch das Gewichtsparametermodell im Baichuan2-Trainingsprozess für große Modelle geöffnet. Dies kann jedem helfen, das Vortraining zu verstehen oder Feinabstimmungen und Verbesserungen durchzuführen. Dies ist auch das erste Mal in China.“ dass ein Unternehmen einen solchen Modelltrainingsprozess eröffnet hat. „Das Training großer Modelle umfasst mehrere Schritte wie die Erfassung umfangreicher, qualitativ hochwertiger Daten, das stabile Training großer Trainingscluster und die Optimierung des Modellalgorithmus.“ Jede Verbindung erfordert die Investition einer großen Menge an Talenten, Rechenleistung und anderen Ressourcen. Die hohen Kosten für das Training eines Modells von Grund auf haben die akademische Gemeinschaft daran gehindert, eingehende Forschung zum Training großer Modelle durchzuführen.
Baichuan Intelligence verfügt über Open-Source-Check Ponit für den gesamten Prozess des Modelltrainings von 220B bis 2640B. Dies ist für wissenschaftliche Forschungseinrichtungen von großem Wert, um den Trainingsprozess großer Modelle, die kontinuierliche Modellschulung und die Modellwertausrichtung usw. zu untersuchen, und kann den wissenschaftlichen Forschungsfortschritt inländischer großer Modelle fördern.
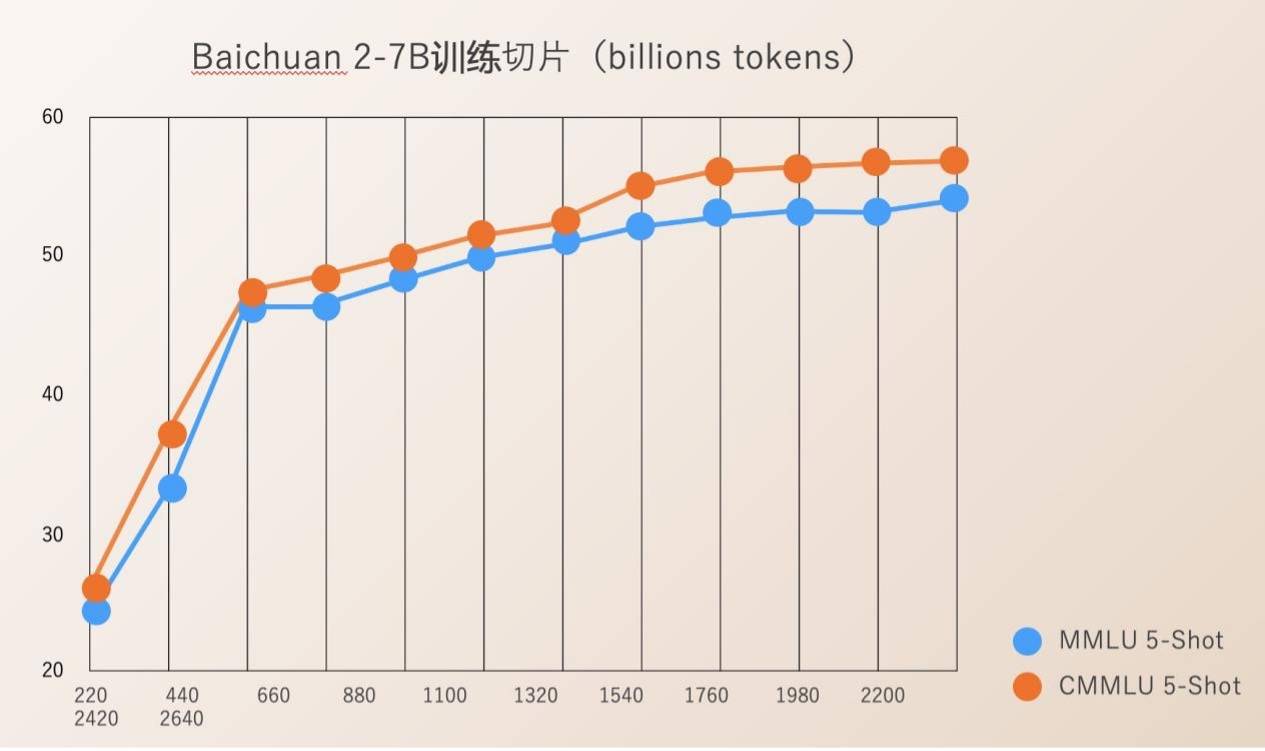
Früher gaben die meisten Open-Source-Modelle nur ihre eigenen Modellgewichte bekannt und selten erwähnte Trainingsdetails. Entwickler konnten nur begrenzte Feinabstimmungen durchführen, was die Durchführung eingehender Recherchen erschwerte.
Der von Baichuan Intelligence veröffentlichte technische Bericht zu Baichuan 2 beschreibt detailliert den gesamten Prozess des Baichuan 2-Trainings, einschließlich Datenverarbeitung, Optimierung der Modellstruktur, Skalierungsgesetz, Prozessindikatoren usw.
Seit seiner Gründung betrachtet Baichuan Intelligence die Förderung des Wohlstands der großen Modellökologie Chinas durch Open Source als eine wichtige Entwicklungsrichtung des Unternehmens. In weniger als vier Monaten seit seiner Gründung wurden zwei kostenlose kommerzielle chinesische Open-Source-Großmodelle, Baichuan-7B und Baichuan-13B, sowie ein durch die Suche erweitertes Großmodell Baichuan-53B veröffentlicht Es wird in vielen maßgeblichen Rezensionen bewertet und steht weit oben auf der Liste. Es wurde mehr als 5 Millionen Mal heruntergeladen.
Letzte Woche war die Einführung der ersten großformatigen Modellfotografie für den öffentlichen Dienst eine wichtige Neuigkeit im Technologiebereich. Unter den in diesem Jahr gegründeten großen Modellunternehmen ist Baichuan Intelligent das einzige, das im Rahmen der „Interim Measures for the Management of Generative Artificial Intelligence Services“ registriert wurde und offiziell Dienstleistungen für die Öffentlichkeit anbieten kann.
Mit branchenführenden grundlegenden F&E- und Innovationsfähigkeiten für große Modelle haben die beiden Open-Source-großen Baichuan-2-Modelle dieses Mal positive Reaktionen von vor- und nachgelagerten Unternehmen erhalten, darunter Tencent Cloud, Alibaba Cloud, Volcano Ark, Huawei, MediaTek und viele andere Namhafte Unternehmen Alle nahmen an dieser Konferenz teil und erzielten eine Zusammenarbeit mit Baichuan Intelligence. Berichten zufolge hat die Zahl der Downloads der großen Modelle von Baichuan Intelligence auf Hugging Face im vergangenen Monat 3,37 Millionen erreicht.
Nach dem vorherigen Plan von Baichuan Intelligence werden sie in diesem Jahr ein großes Modell mit 100 Milliarden Parametern veröffentlichen und im ersten Quartal nächsten Jahres eine „Superanwendung“ starten.
Das obige ist der detaillierte Inhalt vonBaichuan Intelligent hat das große Modell Baichuan2 veröffentlicht: Es ist Llama2 weit voraus und die Trainings-Slices sind ebenfalls Open Source. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was ist ein Web-Frontend-Ingenieur? Was macht ein Web-Frontend-Ingenieur?
- So schreiben Sie einen Lebenslauf für einen Web-Frontend-Ingenieur
- Welche Erweiterungen haben Formulardateien und Projektdateien?
- Bringen Sie Ihnen Schritt für Schritt bei, wie Sie ein Maven-Projekt in vscode erstellen (Kombination aus Grafiken und Text).
- Die ISC 2023 nimmt die Welle der großen Modelle voll auf und veranstaltet den weltweit ersten KI-Gipfel zur digitalen Sicherheit