
Heim >Technologie-Peripheriegeräte >KI >Die Shanghai Jiao Tong University veröffentlicht CodeApex, einen Benchmark für die zweisprachige Programmierung großer Modelle. Haben Maschinen wirklich begonnen, Menschen beim Schreiben von Code herauszufordern?
Die Shanghai Jiao Tong University veröffentlicht CodeApex, einen Benchmark für die zweisprachige Programmierung großer Modelle. Haben Maschinen wirklich begonnen, Menschen beim Schreiben von Code herauszufordern?

- 王林nach vorne
- 2023-09-05 23:29:111506Durchsuche
Maschinen zu bauen, die ihren eigenen Code schreiben können, ist ein Ziel, das Pioniere der Informatik und künstlichen Intelligenz verfolgt haben. Mit der rasanten Entwicklung großer GPT-Typ-Modelle rückt ein solches Ziel näher denn je.
Das Aufkommen großer Sprachmodelle hat bei Forschern immer mehr Aufmerksamkeit auf die Programmierfähigkeiten von Modellen gelenkt. Vor diesem Hintergrund startete das APEX-Labor der Shanghai Jiao Tong University CodeApex – einen zweisprachigen Benchmark-Datensatz, der sich auf die Bewertung des Programmierverständnisses und der Codegenerierungsfähigkeiten von LLMs konzentriert.
Um das Programmierverständnis großer Sprachmodelle zu beurteilen, hat CodeApex drei Arten von Multiple-Choice-Fragen entwickelt: konzeptionelles Verständnis, vernünftiges Denken und Multi-Hop-Argumentation. Darüber hinaus nutzt CodeApex auch algorithmische Fragen und entsprechende Testfälle, um die Codegenerierungsfähigkeiten von LLMs zu bewerten. CodeApex hat insgesamt 14 große Sprachmodelle zu Codierungsaufgaben ausgewertet. Unter ihnen zeigt GPT3.5-turbo die besten Programmierfähigkeiten und erreicht bei diesen beiden Aufgaben eine Genauigkeit von etwa 50 % bzw. 56 %. Es ist ersichtlich, dass große Sprachmodelle bei Programmieraufgaben noch viel Raum für Verbesserungen bieten. Der Bau einer Maschine, die ihren eigenen Code schreiben kann, ist eine vielversprechende Zukunft.

- Website: https://apex.sjtu.edu.cn/codeapex/
- Code: https://github.com/APEXLAB/CodeApex.git
- Papier: https://apex.sjtu.edu.cn/codeapex/paper/
Einführung
Programmierverständnis und Codegenerierung sind Schlüsselaufgaben in der Softwareentwicklung und bei der Verbesserung Spielt eine Schlüsselrolle bei der Entwicklerproduktivität, der Verbesserung der Codequalität und der Automatisierung des Softwareentwicklungsprozesses. Allerdings sind diese Aufgaben für große Modelle aufgrund der Komplexität und semantischen Vielfalt des Codes immer noch eine Herausforderung. Im Vergleich zur gewöhnlichen Verarbeitung natürlicher Sprache erfordert die Verwendung von LLMs zum Generieren von Code einen stärkeren Schwerpunkt auf Grammatik, Struktur, Detailverarbeitung und Kontextverständnis und stellt extrem hohe Anforderungen an die Genauigkeit des generierten Inhalts. Zu den traditionellen Ansätzen gehören grammatikregelbasierte Modelle, vorlagenbasierte Modelle und regelbasierte Modelle, die häufig auf manuell entworfenen Regeln und heuristischen Algorithmen basieren, deren Abdeckung und Genauigkeit begrenzt sind.
Mit dem Aufkommen groß angelegter vorab trainierter Modelle wie CodeBERT und GPT3.5 haben Forscher in den letzten Jahren damit begonnen, die Anwendung dieser Modelle beim Programmierverständnis und bei Codegenerierungsaufgaben zu untersuchen. Diese Modelle integrieren Codegenerierungsaufgaben während des Trainings und ermöglichen es ihnen, Code zu verstehen und zu generieren. Eine faire Bewertung des Fortschritts von LLMs beim Codeverständnis und der Codegenerierung ist jedoch schwierig, da es an standardisierten, öffentlich verfügbaren, qualitativ hochwertigen und vielfältigen Benchmark-Datensätzen mangelt. Daher ist die Erstellung eines Benchmark-Datensatzes, der die Codesemantik und -struktur weitgehend abdeckt, von entscheidender Bedeutung, um die Forschung zum Programmierverständnis und zur Codegenerierung zu fördern.
Bestehende Code-Benchmark-Datensätze haben Probleme hinsichtlich der Anwendbarkeit und Vielfalt, wenn sie auf LLMs angewendet werden. Einige Datensätze eignen sich beispielsweise besser für die Evaluierung bidirektionaler Sprachmodellierungs-LLMs vom Bert-Typ. Bestehende mehrsprachige Code-Benchmark-Datensätze (wie Human-Eval) enthalten jedoch relativ einfache Probleme, es mangelt ihnen an Vielfalt und sie können nur einige grundlegende Funktionscodes implementieren.
Um die oben genannten Lücken zu schließen, hat das APEX Data and Knowledge Management Laboratory der Shanghai Jiao Tong University einen neuen Bewertungsbenchmark für das Verständnis und die Generierung großer Modellcodes erstellt – CodeApex. Als bahnbrechender zweisprachiger (Englisch, Chinesisch) Benchmark-Datensatz konzentriert sich CodeApex auf die Bewertung des Programmierverständnisses und der Codegenerierungsfähigkeiten von LLMs.
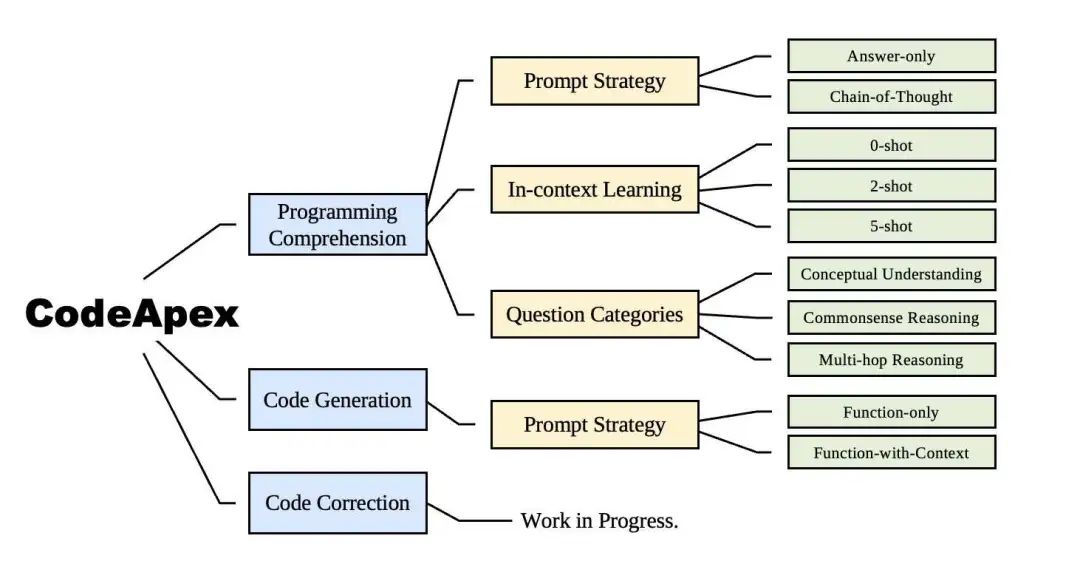
Die gesamte experimentelle Szene von CodeApex ist im Bild oben dargestellt.
Die erste Aufgabe des Programmierverständnisses umfasst 250 Multiple-Choice-Fragen, die in konzeptionelles Verständnis, vernünftiges Denken und Multi-Hop-Argumentation unterteilt sind. Die zum Testen verwendeten Fragen werden aus den Abschlussprüfungsfragen verschiedener Kurse (Programmierung, Datenstrukturen, Algorithmen) an Hochschulen und Universitäten ausgewählt, wodurch das Risiko, dass sich die Daten bereits im LLM-Trainingskorpus befinden, erheblich verringert wird. CodeApex testete die Code-Verständnisfähigkeit von LLMs in drei Szenarien: 0-Schuss, 2-Schuss und 5-Schuss, und testete außerdem die Auswirkungen der Modi „Nur Antwort“ und „Denkkette“ auf die Fähigkeit von LLMs.
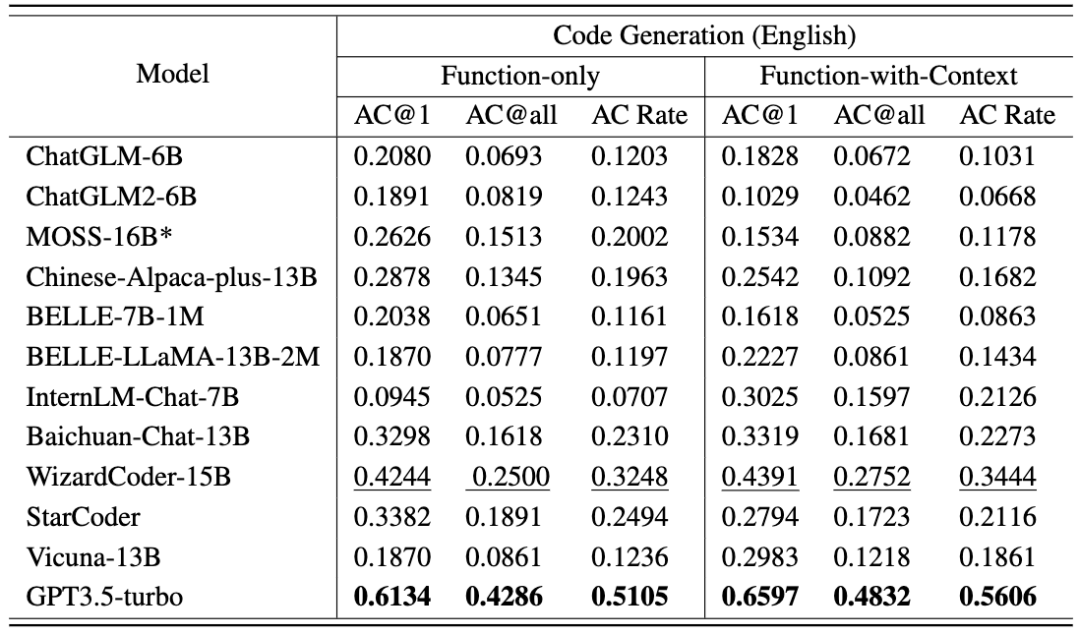
Die zweite Task-Code-Generierung umfasst 476 C++-basierte Algorithmusprobleme, die allgemeine Algorithmus-Wissenspunkte wie binäre Suche, Tiefensuche usw. abdecken. CodeApex liefert eine Beschreibung des Problems und einen Funktionsprototyp, der das Problem implementiert, und erfordert, dass LLMs den Hauptteil der Funktion abschließen. CodeApex bietet außerdem zwei Szenarien: Nur-Funktion und Funktion-mit-Kontext. Der Unterschied zwischen ihnen besteht darin, dass ersteres nur eine Beschreibung der Zielfunktion enthält, während letzteres zusätzlich zur Beschreibung der Zielfunktion ebenfalls bereitgestellt wird mit dem aufrufenden Code und der Zeit der Zielfunktion. Platzbeschränkungen, Eingabe- und Ausgabebeschreibung.
Experimentelle Ergebnisse zeigen, dass verschiedene Modelle bei codebezogenen Aufgaben unterschiedliche Leistungen erbringen und GPT3.5-turbo eine hervorragende Wettbewerbsfähigkeit und offensichtliche Vorteile aufweist. Darüber hinaus verglich CodeApex die Leistung von LLMs in zweisprachigen Szenarien und kam zu unterschiedlichen Ergebnissen. Insgesamt besteht noch erheblicher Verbesserungsbedarf bei der Genauigkeit von LLMs in den CodeApex-Rankings, was darauf hindeutet, dass das Potenzial von LLMs bei Code-bezogenen Aufgaben noch nicht vollständig ausgeschöpft wurde.
Codeverständnis
Um große Sprachmodelle vollständig in tatsächliche Codeproduktionsszenarien zu integrieren, ist Programmierverständnis unerlässlich. Programmierverständnis erfordert die Fähigkeit, den Code in allen Aspekten zu verstehen, z. B. die Beherrschung der Syntax, das Verständnis des Codeausführungsablaufs und das Verständnis des Ausführungsalgorithmus.
CodeApex hat 250 Multiple-Choice-Fragen aus Fragen der College-Abschlussprüfung als Testdaten extrahiert. Diese Testdaten sind in drei Kategorien unterteilt: konzeptionelles Verständnis, logisches Denken und Multi-Hop-Argumentation.

Der Testmodus umfasst zwei Kategorien: Nur Antwort und Gedankenkette.

Experimentelle Ergebnisse und Schlussfolgerungen
Die chinesischen und englischen Bewertungsergebnisse von CodeApex für die Code-Verständnisaufgabe sind in den folgenden beiden Tabellen dargestellt. (Das leistungsstärkste Modell ist fett dargestellt; das nächstbeste Modell ist unterstrichen.)
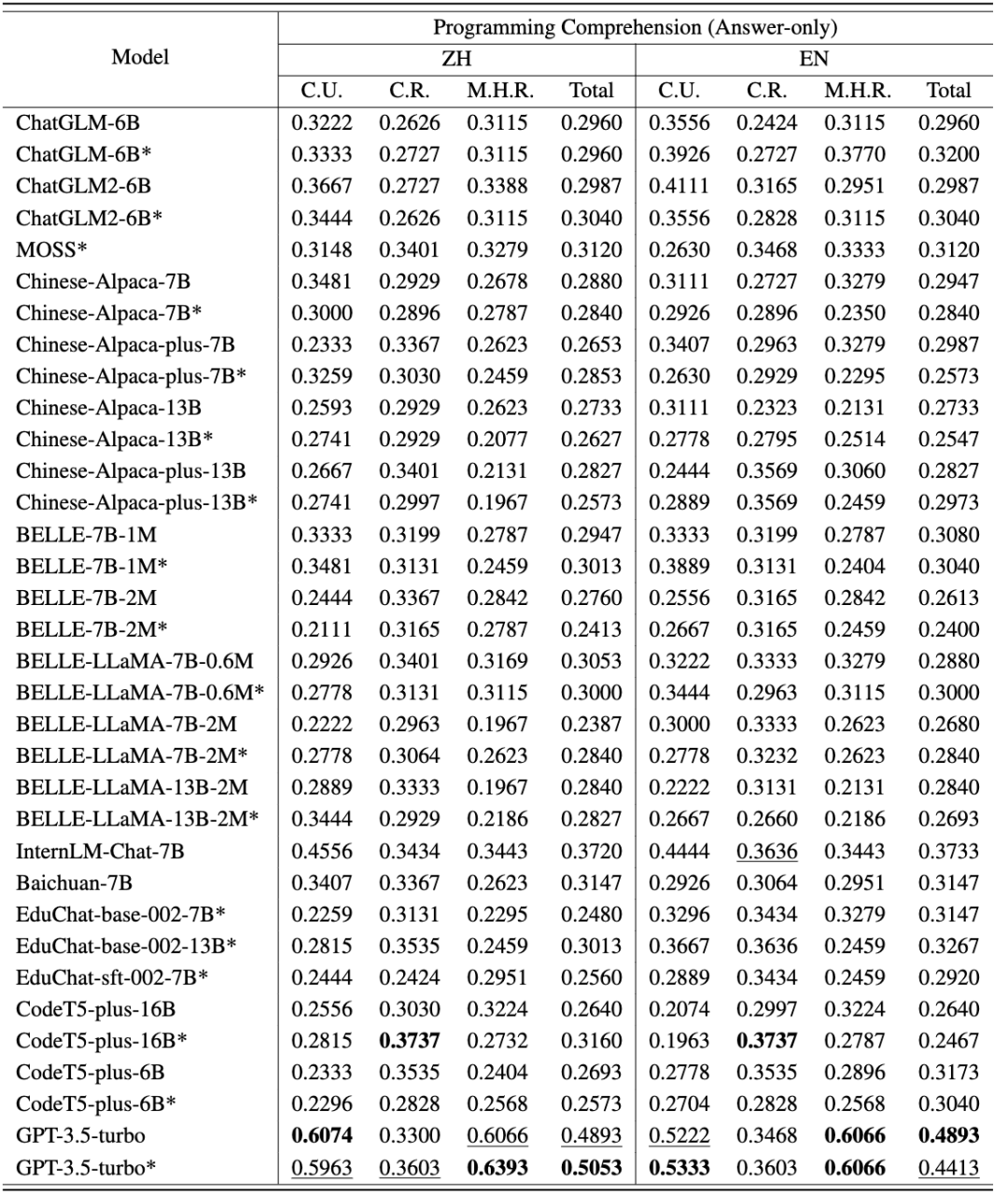
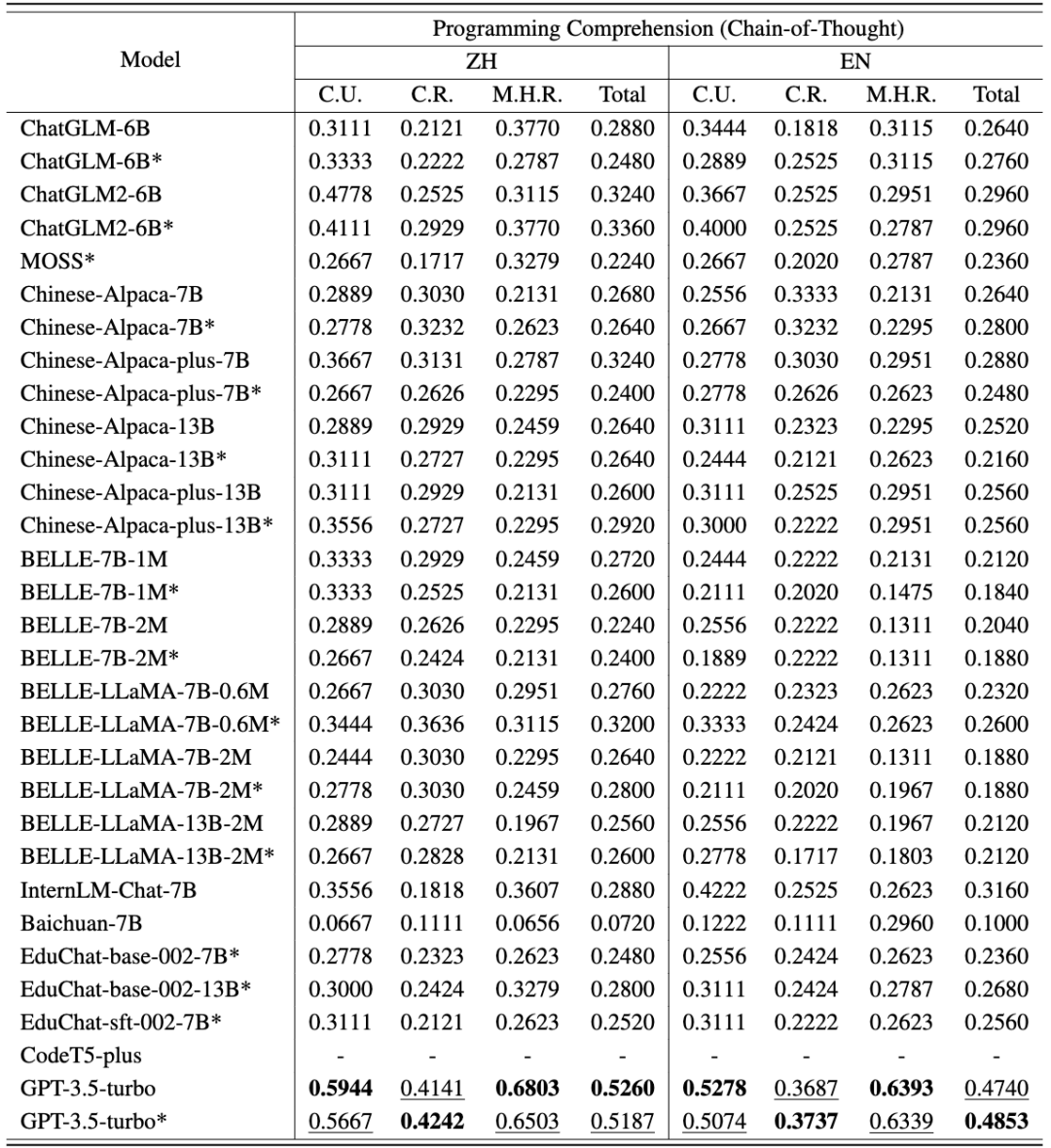
Daraus lassen sich folgende Schlussfolgerungen ziehen:
- Zweisprachiger Kompetenzvergleich. Die chinesische Version punktete besser als die englische Version. Dafür gibt es zwei Hauptgründe: (1) Die ursprünglichen Fragenbeschreibungen stammen aus den Abschlussprüfungen chinesischer Universitäten, sodass die Testfragen ursprünglich auf Chinesisch gestellt wurden. Selbst wenn sie ins Englische übersetzt werden, enthalten sie immer noch einige Sprachgewohnheiten, die nur für Chinesen gelten. Wenn diese voreingenommenen englischen Fragen in LLMs eingegeben werden, kann es daher zu Störungen in den Codierungsergebnissen des Modells kommen. (2) Die meisten evaluierten Modelle werden hauptsächlich auf chinesischen Daten trainiert, was zu schlechten Ergebnissen führt.
- Vergleich der Fähigkeiten verschiedener Fragetypen. In diesen drei Problemkategorien schnitt etwa die Hälfte der Modelle beim konzeptionellen Verständnis am besten ab, was darauf hindeutet, dass sie während des Trainings wahrscheinlich Kenntnisse über Programmierkonzepte besaßen. Die meisten Modelle schneiden beim Common-Sense-Argumentation besser ab als beim Multi-Hop-Argumentation, was darauf hindeutet, dass die Leistung von LLMs mit zunehmenden Inferenzschritten deutlich abnimmt.
- Die Rolle des CoT-Denkkettenmodells. Die Genauigkeit der meisten Modelle im CoT-Modus liegt nahe oder niedriger als im Nur-Antwort-Modus. Für dieses Phänomen gibt es zwei Gründe: (1) Die bewertete Modellgröße erreicht nicht die Modellgröße mit CoT-Emergenzfähigkeit. Frühere Untersuchungen gingen davon aus, dass die Entstehung von CoT erfordert, dass LLMs über mindestens 60B-Parameter verfügen. Wenn die Anzahl der Parameter nicht ausreicht, kann das CoT-Setup zu zusätzlichem Rauschen führen und die von LLMs erzeugte Reaktion ist instabil. GPT3.5-turbo hat den Punkt der Entstehung neuer Fähigkeiten erreicht und kann eine höhere Genauigkeit in CoT-Einstellungen erreichen. (2) Bei der Beantwortung von Fragen zum konzeptionellen Verständnis und zum gesunden Menschenverstand ist eine mehrstufige Argumentation weniger notwendig. Daher können die CoT-Funktionen von LLMs bei dieser Art von Problemen nicht helfen. Bei Multi-Hop-Inferenzproblemen weisen einige Modelle (wie ChatGLM2, educhat und GPT3.5-turbo) jedoch eine deutlich verbesserte Genauigkeit in CoT-Szenarien auf. (CodeApex schließt CodeT5 aus den CoT-Einstellungen aus, da es nicht in der Lage ist, Antworten über Gedankenketten zu generieren.)
Codegenerierung
Das Trainieren großer Sprachmodelle zur Generierung präzisen und ausführbaren Codes ist eine anspruchsvolle Aufgabe. CodeApex bewertet in erster Linie die Fähigkeit von LLMs, Algorithmen basierend auf einer vorgegebenen Beschreibung zu generieren, und bewertet automatisch die Korrektheit des generierten Codes durch Unit-Tests.
Die Codegenerierungsaufgaben von CodeApex umfassen 476 C++-basierte Algorithmusprobleme, die allgemeine Wissenspunkte zu Algorithmen abdecken, wie z. B. binäre Such- und Diagrammalgorithmen. CodeApex liefert eine Beschreibung des Problems und einen Funktionsprototyp, der das Problem implementiert, und erfordert, dass LLMs den Hauptteil der Funktion abschließen.

CodeApex bietet zwei Szenarios: Nur Funktion und Funktion mit Kontext. Das Nur-Funktions-Szenario bietet nur eine Beschreibung der Zielfunktion, während das Funktion-mit-Kontext-Szenario nicht nur eine Beschreibung der Zielfunktion, sondern auch den aufrufenden Code, Zeit- und Raumbeschränkungen sowie eine Eingabe- und Ausgabebeschreibung bereitstellt die Zielfunktion.

Experimentelle Ergebnisse und Schlussfolgerungen
Jede Sprachversion verwendet zwei Eingabeaufforderungsstrategien (Nur Funktion und Funktion mit Kontext). Zur Anpassung an Testszenarien für menschlichen Code umfassen die Bewertungsmetriken AC@1, AC@all und AC-Rate. Die Ergebnisse der Codegenerierungsaufgabe für jedes Modell werden in den folgenden beiden Tabellen angezeigt. (Beste Leistung: fett; zweitbeste Leistung: unterstrichen.)
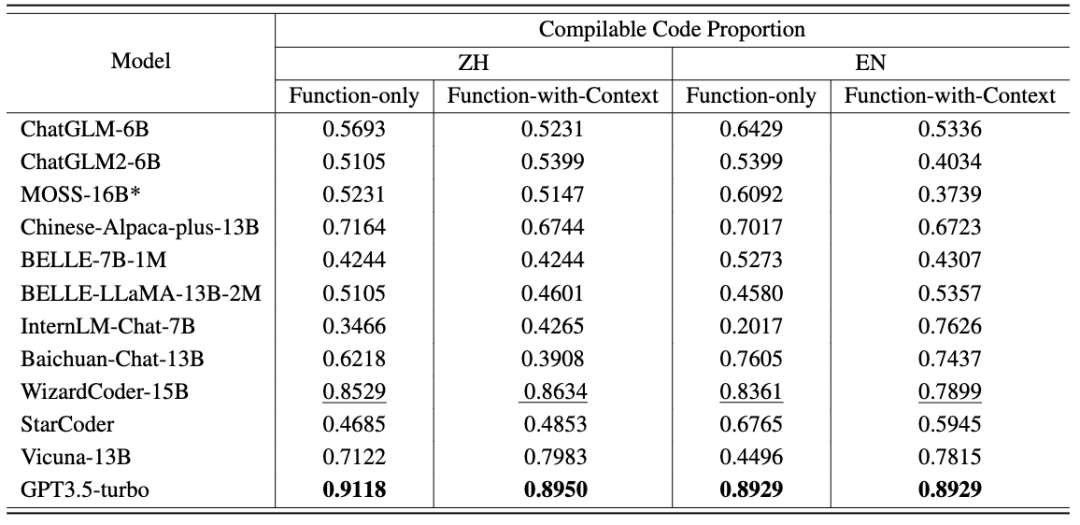
Folgende Schlussfolgerungen lassen sich ziehen: Darüber hinaus stellt CodeApex den Anteil des kompilierbaren Codes in jedem Szenario bereit. Nachdem die generierte Funktion mit der Hauptfunktion verbunden wurde, wird der kompilierte Code durch Testfälle überprüft. Sie können sehen: CodeApex ist ein zweisprachiger Benchmark, der sich auf die Programmierfähigkeit von LLMs konzentriert und das Programmierverständnis und die Codegenerierungsfähigkeiten großer Sprachmodelle bewertet. Im Hinblick auf das Programmierverständnis bewertete CodeApex die Fähigkeiten verschiedener Modelle in drei Kategorien von Multiple-Choice-Fragen. Im Hinblick auf die Codegenerierung verwendet CodeApex die Erfolgsquote von Testcodefällen, um die Fähigkeiten des Modells zu bewerten. Für diese beiden Aufgaben hat CodeApex sorgfältig Prompt-Strategien entworfen und sie in verschiedenen Szenarien verglichen. CodeApex wird experimentell an 14 LLMs evaluiert, darunter allgemeine LLMs und spezialisierte LLMs-Modelle, die auf Code-Feinabstimmung basieren. Derzeit hat GPT3.5 ein relativ gutes Niveau in Bezug auf Programmierfähigkeiten erreicht und erreicht eine Genauigkeit von etwa 50 % bzw. 56 % beim Programmierverständnis und bei Codegenerierungsaufgaben. CodeApex zeigt, dass das Potenzial großer Sprachmodelle für Programmieraufgaben noch nicht vollständig ausgeschöpft ist. Wir gehen davon aus, dass die Nutzung großer Sprachmodelle zur Codegenerierung in naher Zukunft den Bereich der Softwareentwicklung revolutionieren wird. Mit der Weiterentwicklung der Verarbeitung natürlicher Sprache und des maschinellen Lernens werden diese Modelle immer leistungsfähiger und können Codefragmente besser verstehen und generieren. Entwickler werden feststellen, dass sie bei ihren Codierungsbemühungen einen beispiellosen Verbündeten haben, da sie sich auf diese Modelle verlassen können, um mühsame Aufgaben zu automatisieren, ihre Produktivität zu steigern und die Softwarequalität zu verbessern. In Zukunft wird CodeApex weitere Tests (z. B. Codekorrektur) zum Testen der Codefähigkeiten großer Sprachmodelle veröffentlichen. Die Testdaten von CodeApex werden auch weiterhin aktualisiert, um vielfältigere Codeprobleme hinzuzufügen. Gleichzeitig werden auch menschliche Experimente zur CodeApex-Liste hinzugefügt, um die Codierungsfunktionen großer Sprachmodelle mit denen menschlicher Ebene zu vergleichen. CodeApex bietet einen Maßstab und eine Referenz für die Forschung zu Programmierfunktionen für große Sprachmodelle und wird die Entwicklung und den Erfolg großer Sprachmodelle im Codebereich fördern. Das APEX-Labor für Daten- und Wissensmanagement der Shanghai Jiao Tong-Universität wurde 1996 gegründet. Sein Gründer ist Professor Yu Yong, der Schulleiter der ACM-Klasse. Das Labor widmet sich der Erforschung von Technologien der künstlichen Intelligenz, die Daten effektiv auswerten und verwalten sowie Wissen zusammenfassen. Es hat mehr als 500 internationale wissenschaftliche Arbeiten veröffentlicht und verfolgt praktische Anwendungen in praktischen Szenarien. In den letzten 27 Jahren hat sich das APEX Laboratory zu einem globalen Pionier in vielen weltweiten Technologiewellen entwickelt. Das Labor begann im Jahr 2000 mit der Erforschung der Kerntechnologie des Semantic Web (heute bekannt als Knowledge Graph) und begann mit der Erforschung personalisierter Suchmaschinen Empfehlungen im Jahr 2003. Systemtechnologie, begann 2006 mit dem Studium der Theorie und des Algorithmus des Transferlernens, begann 2009 mit der Erforschung der Deep-Learning-Technologie und entwickelte eine auf GPU basierende Trainingsbibliothek für neuronale Netze. Während APEX Lab fruchtbare wissenschaftliche Forschungs- und Implementierungsergebnisse lieferte, hat es auch ein solides Forschungsteam für Datenwissenschaft und maschinelles Lernen aufgebaut, darunter Xue Guirong, Zhang Lei, Lin Chenxi, Liu Guangcan, Wang Haofen, Li Lei, Dai Wenyuan, Li Zhenhui und Chen Tianqi, Zhang Weinan, Yang Diyi und andere herausragende Alumni im Bereich der künstlichen Intelligenz. 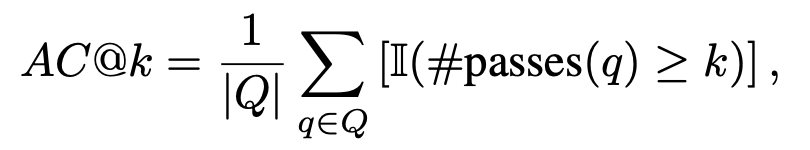
Fazit
Einführung in das APEX-Labor
Das obige ist der detaillierte Inhalt vonDie Shanghai Jiao Tong University veröffentlicht CodeApex, einen Benchmark für die zweisprachige Programmierung großer Modelle. Haben Maschinen wirklich begonnen, Menschen beim Schreiben von Code herauszufordern?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!