
Heim >Technologie-Peripheriegeräte >KI >Verwenden Sie BigDL-LLM, um zig Milliarden Parameter-LLM-Inferenzen sofort zu beschleunigen
Verwenden Sie BigDL-LLM, um zig Milliarden Parameter-LLM-Inferenzen sofort zu beschleunigen

- 王林nach vorne
- 2023-09-05 13:49:041302Durchsuche
Wir treten in eine neue Ära der KI ein, die durch das Large Language Model (LLM) vorangetrieben wird und eine immer wichtigere Rolle in verschiedenen Anwendungen wie Kundenservice, virtuellen Assistenten, Inhaltserstellung, Programmierunterstützung usw. spielt.
Da jedoch der Umfang von LLM immer weiter zunimmt, steigt auch der Ressourcenverbrauch, der für die Ausführung großer Modelle erforderlich ist, was dazu führt, dass der Betrieb immer langsamer wird, was die Entwickler von KI-Anwendungen vor erhebliche Herausforderungen stellt.
Zu diesem Zweck hat Intel kürzlich eine große Open-Source-Modellbibliothek namens BigDL-LLM[1] auf den Markt gebracht, die KI-Entwicklern und -Forschern dabei helfen kann, die Optimierung großer Sprachmodelle auf der Intel® -Plattform zu beschleunigen und zu verbessern Die Erfahrung mit der Verwendung großer Sprachmodelle auf der Intel ® -Plattform.

Das Folgende zeigt das 33 Milliarden Parameter große Sprachmodell Vicuna-33b-v1.3[2], das mit BigDL-LLM auf einer Maschine beschleunigt wird, die mit Intel® Xeon® Platinum 8468 ausgestattet ist Der Prozessor führt die Echtzeiteffekte auf dem Server aus.
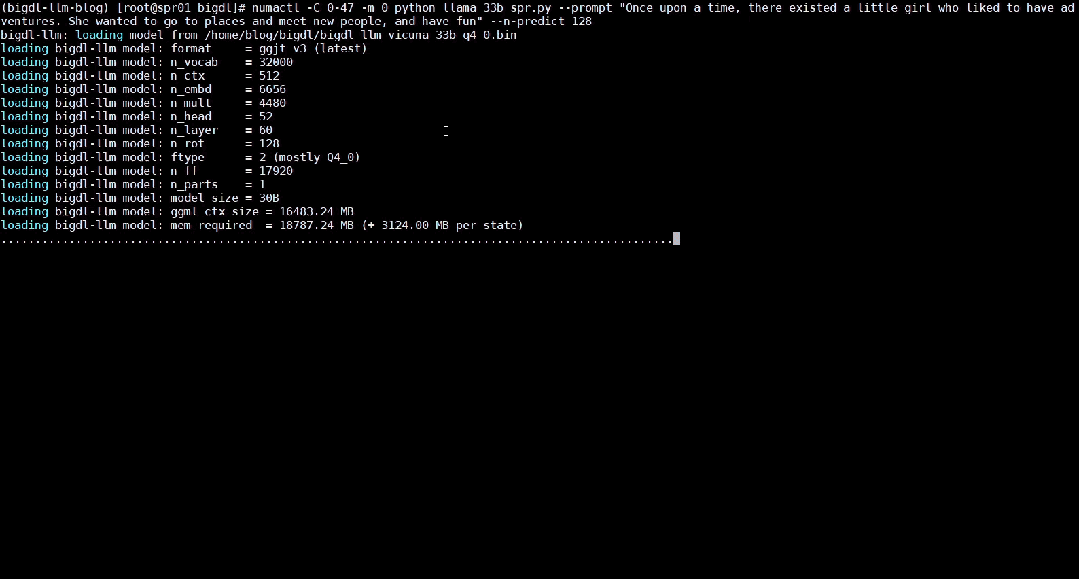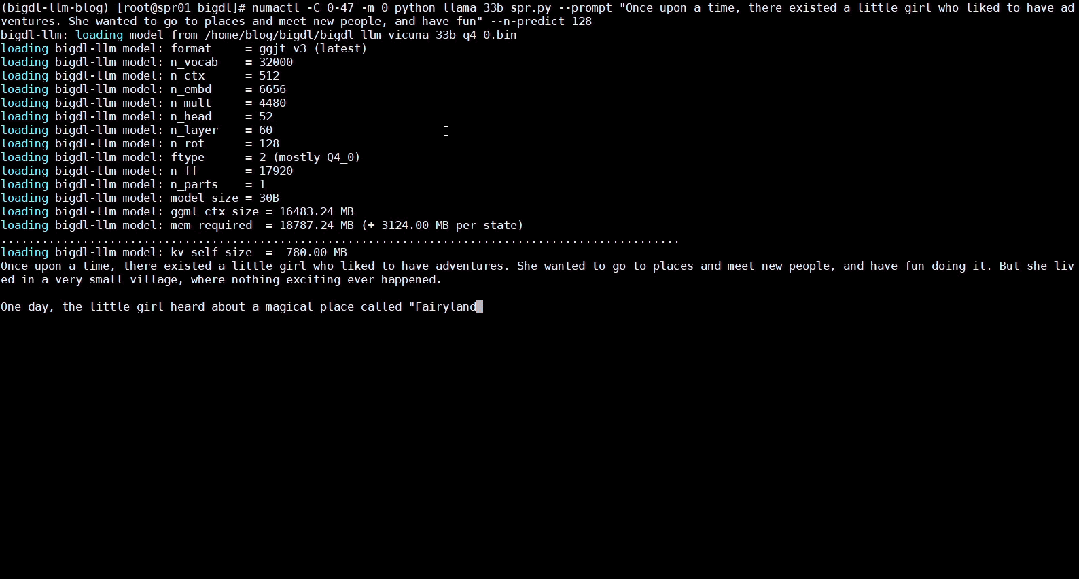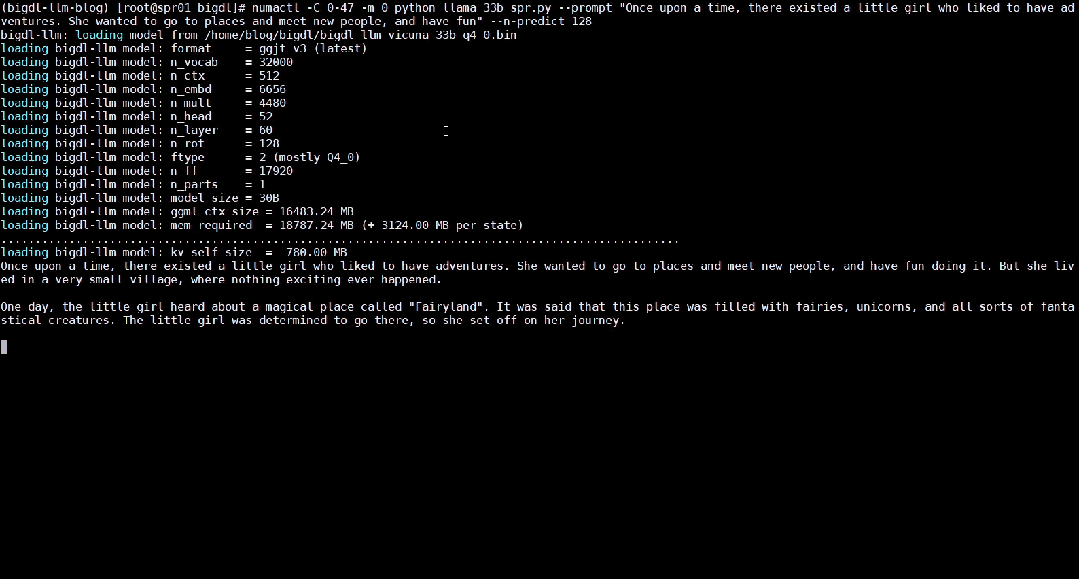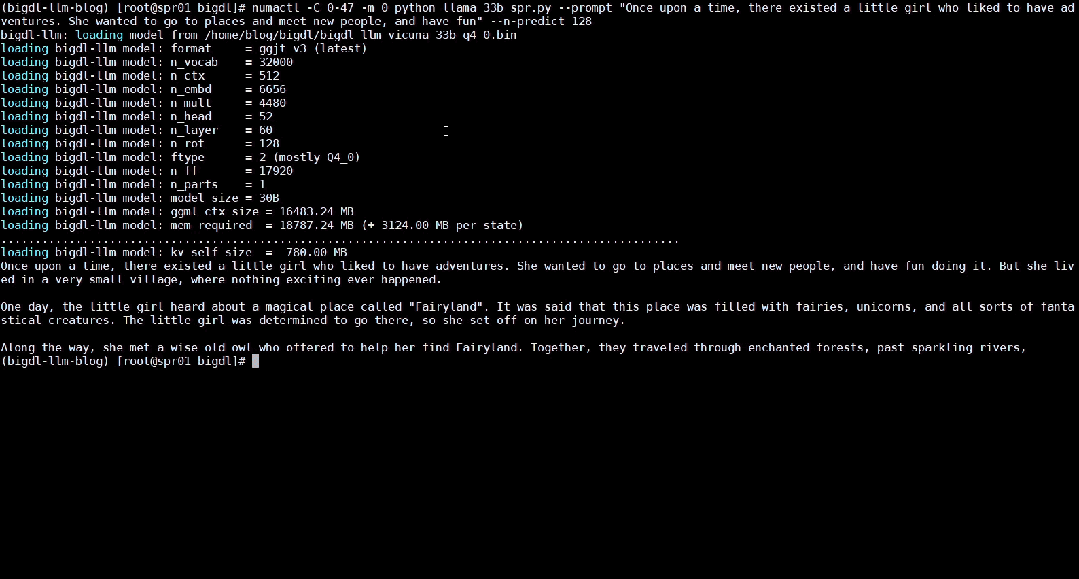
△Tatsächliche Geschwindigkeit beim Ausführen eines großen Sprachmodells mit 33 Milliarden Parametern auf einem Server mit Intel® Xeon® Platinum 8468-Prozessor (Echtzeit-Bildschirmaufzeichnung)
BigDL-LLM: Intel® Open-Source-Bibliothek zur Beschleunigung großer Sprachmodelle auf der Plattform
BigDL-LLM ist eine Open-Source-Bibliothek, die sich auf die Optimierung und Beschleunigung großer Sprachmodelle konzentriert. Sie ist Teil von BigDL und wird unter der Apache 2.0-Lizenz veröffentlicht. Sie bietet eine Vielzahl von Low-Source-Modellen. Präzisionsoptimierung auf höchstem Niveau (z. B. INT4/INT5/INT8) und kann eine Vielzahl von Intel®
CPU-integrierten Hardwarebeschleunigungstechnologien (AVX/VNNI/AMX usw.) und die neueste Softwareoptimierung nutzen, um große Sprachmodelle zu ermöglichen Intel® Erzielen Sie eine effizientere Optimierung und einen schnelleren Betrieb auf der Plattform. Eine wichtige Funktion von BigDL-LLM besteht darin, dass Sie für Modelle, die auf der Hugging Face Transformers-API basieren, nur eine Codezeile ändern müssen, um das Modell zu beschleunigen. Theoretisch kann es die Ausführung von
jedemTransformers-Modell unterstützen. Das ist nützlich für diejenigen, die mit Transformers vertraut sind. Die API-Entwickler sind sehr freundlich. Zusätzlich zur Transformers-API verwenden viele Leute auch LangChain, um große Sprachmodellanwendungen zu entwickeln.
Zu diesem Zweck bietet BigDL-LLM auch eine benutzerfreundliche LangChain-Integration[3]
, die es Entwicklern ermöglicht, BigDL-LLM einfach zu verwenden, um neue Anwendungen zu entwickeln oder bestehende Anwendungen basierend auf Transformers API oder LangChain API zu migrieren.Darüber hinaus können Sie für allgemeine große PyTorch-Sprachmodelle (Modelle, die keine Transformer- oder LangChain-API verwenden) auch die Ein-Klick-Beschleunigung der BigDL-LLM-Optimierungsmodell-API verwenden, um die Leistung zu verbessern. Einzelheiten finden Sie in der GitHub-README-Datei[4]
und in der offiziellen Dokumentation[5]. BigDL-LLM bietet außerdem eine große Anzahl häufig verwendeter Open-Source-LLM-Beschleunigungsbeispiele (z. B. Beispiele mit der Transformers-API[6]
und Beispiele mit der LangChain-API[7] sowie Tutorials (einschließlich unterstützender Jupyter-Notebooks) [8], praktisch für Entwickler, um schnell loszulegen und es auszuprobieren Installation und Verwendung: Einfacher Installationsprozess und benutzerfreundliche API-Schnittstelle
Die Installation von BigDL-LLM ist sehr praktisch. Führen Sie einfach Folgendes aus Befehl:pip install --pre --upgrade bigdl-llm[all]
△
Wenn der Code nicht vollständig angezeigt wird, schieben Sie ihn bitte nach links oder rechts Es ist auch sehr einfach, BigDL-LLM zu verwenden, um große Modelle zu beschleunigen (hier verwenden wir nur die API im Transformers-Stil). als Beispiel)
Verwenden Sie die BigDL-LLM Transformer-API, um das Modell zu beschleunigen. Der anschließende Verwendungsprozess ist vollständig der gleiche wie bei nativen Transformern Die Verwendung der BigDL-LLM-API ist fast die gleiche wie die der Transformers-API – der Benutzer muss nur den Import ändern und ihn im from_pretrained-Parameter festlegen. Präzisionsquantisierung während des Modellladevorgangs und Verwendung verschiedener Software- und Hardwarebeschleunigungstechnologien zur Optimierung während des nachfolgenden Inferenzprozesses#Load Hugging Face Transformers model with INT4 optimizationsfrom bigdl.llm. transformers import AutoModelForCausalLMmodel = AutoModelForCausalLM.from_pretrained('/path/to/model/', load_in_4bit=True)
△ Wenn der Code nicht vollständig angezeigt wird, schieben Sie ihn bitte nach links oder rechts
示例:快速实现一个基于大语言模型的语音助手应用
下文将以 LLM 常见应用场景“语音助手”为例,展示采用 BigDL-LLM 快速实现 LLM 应用的案例。通常情况下,语音助手应用的工作流程分为以下两个部分:
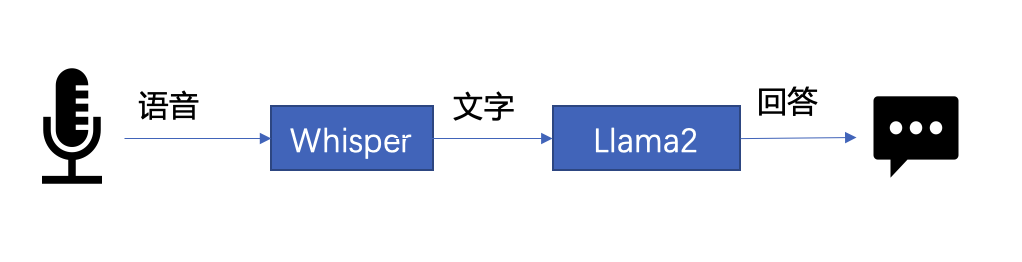
△图 1. 语音助手工作流程示意
- 语音识别——使用语音识别模型(本示例采用了 Whisper 模型[9] )将用户的语音转换为文本;
- 文本生成——将 1 中输出的文本作为提示语 (prompt),使用一个大语言模型(本示例采用了 Llama2[10] )生成回复。
以下是本文使用 BigDL-LLM 和 LangChain[11] 来搭建语音助手应用的过程:
在语音识别阶段:第一步,加载预处理器 processor 和语音识别模型 recog_model。本示例中使用的识别模型 Whisper 是一个 Transformers 模型。
只需使用 BigDL-LLM 中的 AutoModelForSpeechSeq2Seq 并设置参数 load_in_4bit=True,就能够以 INT4 精度加载并加速这一模型,从而显著缩短模型推理用时。
#processor = WhisperProcessor .from_pretrained(recog_model_path)recog_model = AutoModelForSpeechSeq2Seq .from_pretrained(recog_model_path, load_in_4bit=True)
△若代码显示不全,请左右滑动
第二步,进行语音识别。首先使用处理器从输入语音中提取输入特征,然后使用识别模型预测 token,并再次使用处理器将 token 解码为自然语言文本。
input_features = processor(frame_data,sampling_rate=audio.sample_rate,return_tensor=“pt”).input_featurespredicted_ids = recogn_model.generate(input_features, forced_decoder_ids=forced_decoder_ids)text = processor.batch_decode(predicted_ids, skip_special_tokens=True)[0]
△若代码显示不全,请左右滑动
在文本生成阶段,首先使用 BigDL-LLM 的 TransformersLLM API 创建一个 LangChain 语言模型(TransformersLLM 是在 BigDL-LLM 中定义的语言链 LLM 集成)。
可以使用这个 API 来加载 Hugging Face Transformers 的任何模型
llm = TransformersLLM . from_model_id(model_id=llm_model_path,model_kwargs={"temperature": 0, "max_length": args.max_length, "trust_remote_code": True},)
△若代码显示不全,请左右滑动
然后,创建一个正常的对话链 LLMChain,并将已经创建的 llm 设置为输入参数。
# The following code is complete the same as the use-casevoiceassistant_chain = LLMChain(llm=llm, prompt=prompt,verbose=True,memory=ConversationBufferWindowMemory(k=2),)
△若代码显示不全,请左右滑动
以下代码将使用一个链条来记录所有对话历史,并将其适当地格式化为大型语言模型的输入。这样,我们可以生成合适的回复。只需将识别模型生成的文本作为 "human_input" 输入即可。代码如下:
response_text = voiceassistant_chain .predict(human_input=text, stop=”\n\n”)
△若代码显示不全,请左右滑动
最后,将语音识别和文本生成步骤放入循环中,即可在多轮对话中与该“语音助手”交谈。您可访问底部 [12] 链接,查看完整的示例代码,并使用自己的电脑进行尝试。快用 BigDL-LLM 来快速搭建自己的语音助手吧!
作者简介
黄晟盛是英特尔公司的资深架构师,黄凯是英特尔公司的AI框架工程师,戴金权是英特尔院士、大数据技术全球CTO和BigDL项目的创始人,他们都从事着与大数据和AI相关的工作
Das obige ist der detaillierte Inhalt vonVerwenden Sie BigDL-LLM, um zig Milliarden Parameter-LLM-Inferenzen sofort zu beschleunigen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!