Mit dem Aufkommen der Telemedizin entscheiden sich Patienten zunehmend für Online-Konsultationen und Beratungen, um bequeme und effiziente medizinische Unterstützung zu erhalten. Kürzlich haben große Sprachmodelle (LLM) leistungsstarke Fähigkeiten zur Interaktion in natürlicher Sprache gezeigt und Hoffnung für Gesundheits- und medizinische Assistenten gemacht, die in das Leben der Menschen Einzug halten verfügen über umfassende medizinische Kenntnisse und die Fähigkeit, die Absichten des Patienten durch mehrere Dialogrunden zu verstehen und professionelle und detaillierte Antworten zu geben. Bei medizinischen und gesundheitlichen Konsultationen vermeiden es Modelle mit allgemeiner Sprache aufgrund mangelnder medizinischer Kenntnisse häufig, Fragen zu beantworten, die nicht gestellt werden. Gleichzeitig neigen sie dazu, die Konsultation in der aktuellen Fragerunde abzuschließen, und verfügen nicht über die zufriedenstellende Fähigkeit, dies zu tun Beantworten Sie mehrere Fragenrunden. Darüber hinaus sind qualitativ hochwertige chinesische medizinische Datensätze derzeit sehr selten, was eine Herausforderung für das Training leistungsstarker Sprachmodelle im medizinischen Bereich darstellt.
Das Data Intelligence and Social Computing Laboratory (FudanDISC) der Fudan University hat einen chinesischen persönlichen Assistenten für Medizin und Gesundheit veröffentlicht – DISC-MedLLM. Bei der medizinischen und gesundheitlichen Beratungsbewertung von einrundigen Fragen und Antworten und mehrrundigen Dialogen zeigt die Leistung des Modells offensichtliche Vorteile im Vergleich zu bestehenden großen medizinischen Dialogmodellen. Das Forschungsteam veröffentlichte außerdem einen hochwertigen Datensatz zur überwachten Feinabstimmung (SFT) – DISC-Med-SFT mit 470.000 Personen. Die Modellparameter und technischen Berichte sind ebenfalls Open Source. Homepage-Adresse: https://med.fudan-disc.com
Github-Adresse: https://github.com/FudanDISC/DISC-MedLLM
Technischer Bericht: https: //arxiv.org/abs/2308.14346
1. Beispielanzeige
Abbildung 1: Dialogbeispiel Wenn sich Patienten unwohl fühlen, können sie nachfragen Das Modell beschreibt Ihre Symptome und gibt mögliche Ursachen, empfohlene Behandlungspläne usw. als Referenz an. Wenn Informationen fehlen, werden proaktiv detaillierte Beschreibungen der Symptome angefordert. 
Abbildung 2: Dialog in einem Beratungsszenario
Benutzer können dem Modell auch spezifische Beratungsfragen stellen, die auf ihrem eigenen Gesundheitszustand basieren, und das Modell wird detaillierte und hilfreiche Antworten geben Stellen Sie proaktiv Fragen, wenn Informationen fehlen, um die Relevanz und Genauigkeit der Antworten zu verbessern. 
Abbildung 3: Dialog auf Basis der Beratung zum eigenen Gesundheitszustand
Benutzer können auch nach medizinischem Wissen fragen, das nichts mit sich selbst zu tun hat, antwortet das Modell so professionell wie möglich, um dem Benutzer ein umfassendes und genaues Verständnis zu vermitteln. 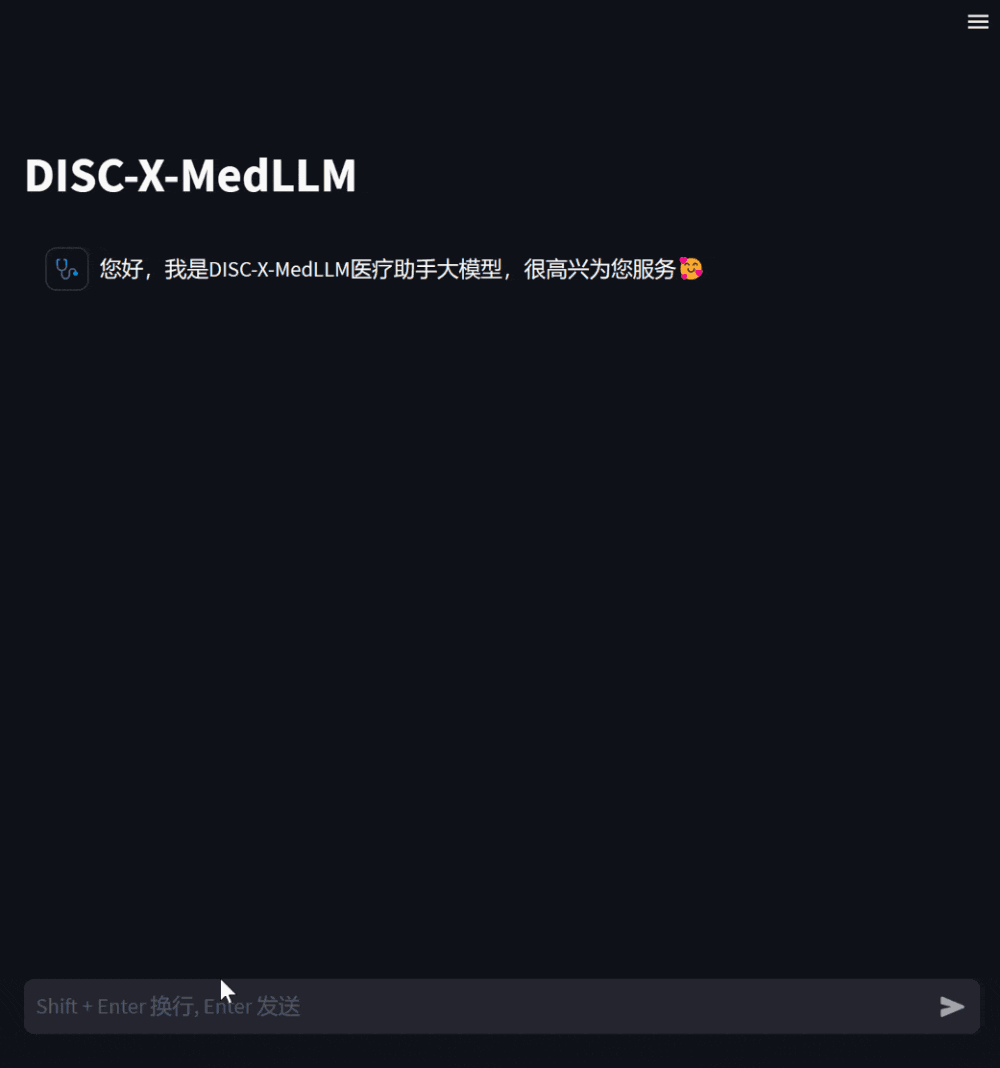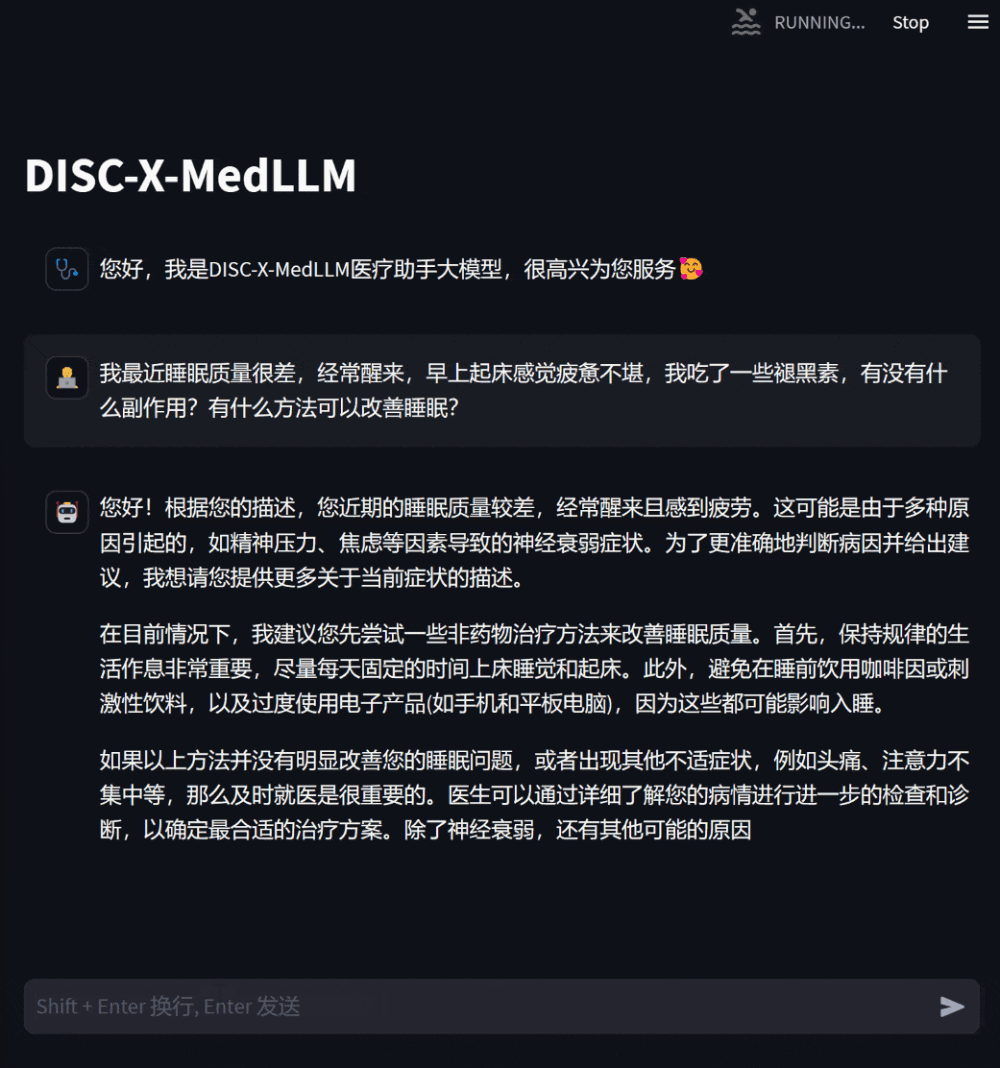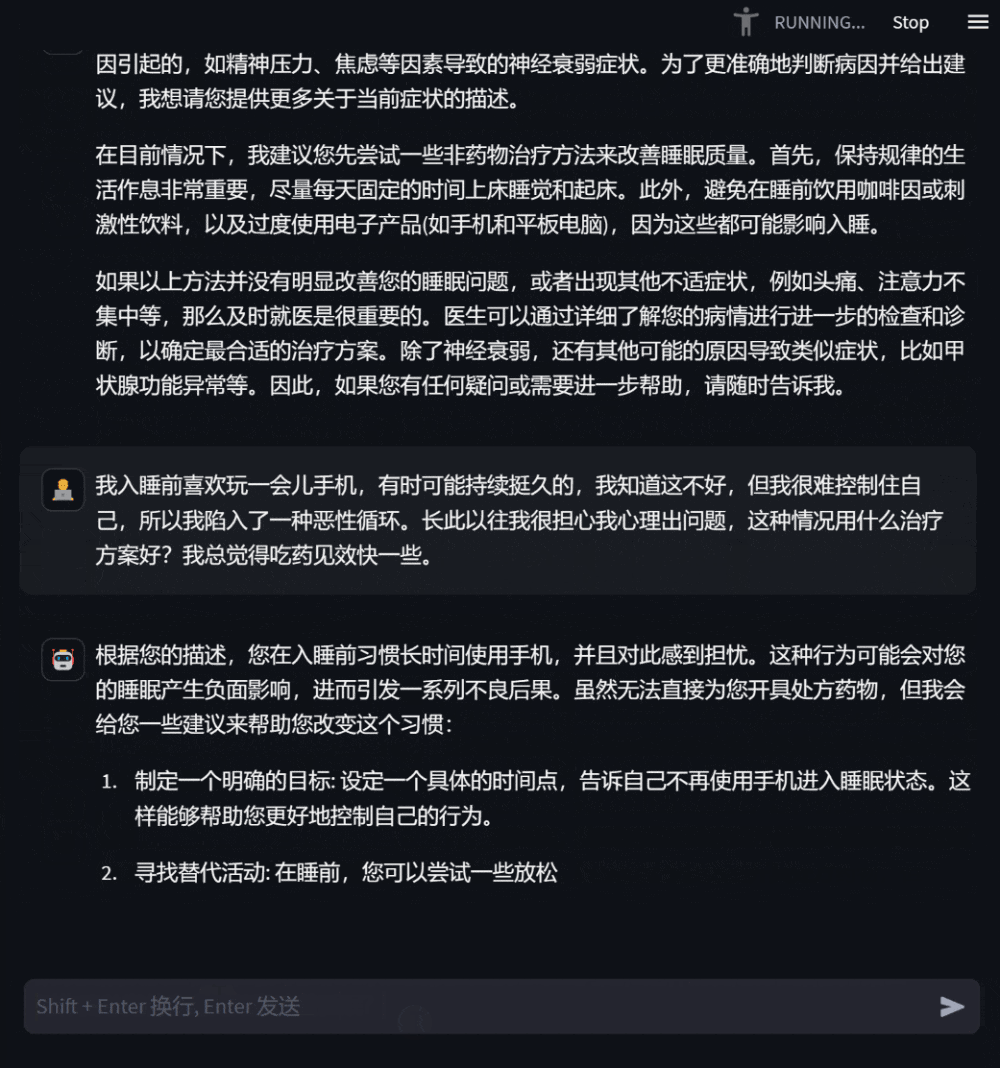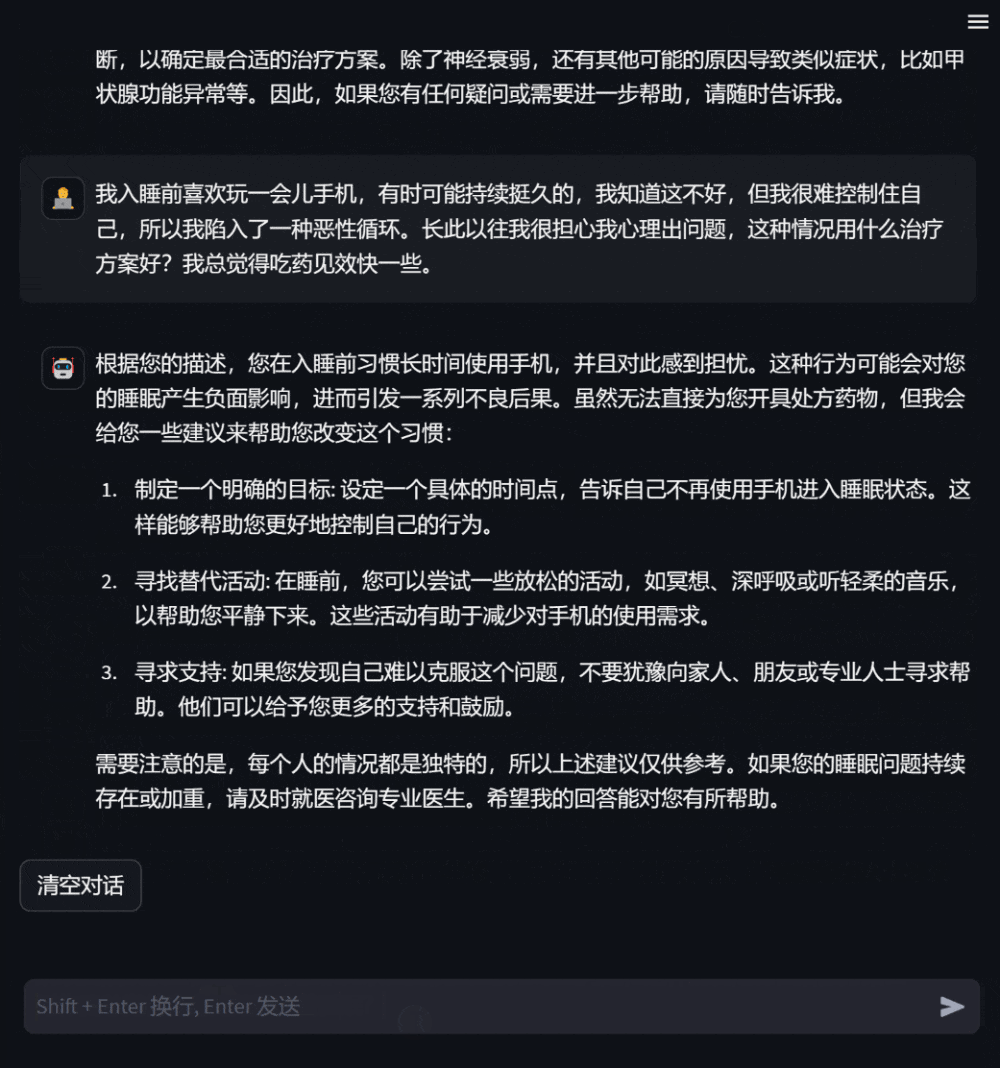
Abbildung 4: Dialog zur medizinischen Wissensabfrage ohne Bezug zur eigenen Person2. Einführung in DISC-MedLLMDISC-MedLLM basiert auf dem von uns erstellten hochwertigen Datensatz DISC-Med-SFT Ein großes medizinisches Modell, das auf dem allgemeinen chinesischen Großmodell Baichuan-13B trainiert wurde. Es ist erwähnenswert, dass unsere Trainingsdaten und Trainingsmethoden an jedes große Basismodell angepasst werden können. DISC-MedLLM verfügt über drei Hauptmerkmale:
- Zuverlässige und umfassende Fachkompetenz. Wir verwenden den medizinischen Wissensgraphen als Informationsquelle, um Dialogbeispiele zu erstellen, indem wir Tripel abfragen und die Sprachfähigkeiten allgemeiner großer Modelle nutzen.
- Anfragefähigkeit für mehrere Dialogrunden. Wir verwenden echte Konsultationsdialogaufzeichnungen als Informationsquelle und verwenden große Modelle, um den Dialog zu rekonstruieren. Während des Konstruktionsprozesses ist das Modell erforderlich, um die medizinischen Informationen im Dialog vollständig abzugleichen.
- Antworten an menschlichen Vorlieben ausrichten. Patienten hoffen, während des Konsultationsprozesses umfassendere unterstützende Informationen und Hintergrundwissen zu erhalten, aber die Antworten menschlicher Ärzte sind oft prägnant. Durch manuelles Screening erstellen wir hochwertige, kleine Anleitungsbeispiele, um sie an den Bedürfnissen der Patienten auszurichten.
Die Vorteile des Modells und des Datenkonstruktionsframeworks sind in Abbildung 5 dargestellt. Wir haben die tatsächliche Verteilung der Patienten anhand realer Konsultationsszenarien berechnet, um die Beispielkonstruktion des Datensatzes zu leiten. Basierend auf dem medizinischen Wissensgraphen und echten Konsultationsdaten haben wir zwei Ideen verwendet: großes Modell-in-the-Loop und People-in-the-Loop. the-loop, um den Datensatz zu erstellen. 3. Methode: Konstruktion des Datensatzes DISC-Med-SFT im Modell Ausbildungsprozess, Wir haben DISC-Med-SFT mit allgemeinen Domänendatensätzen und Datenproben aus vorhandenen Korpora ergänzt und so DISC-Med-SFT-ext gebildet. Die Details sind in Tabelle 1 aufgeführt. Tabelle 1: Einführung in den Dateninhalt von DISC-Med-SFT-ext 400.000 bzw. 20.000 Proben wurden zufällig aus zwei öffentlichen Datensätzen, MedDialog und cMedQA2, als Quellproben für die SFT-Datensatzkonstruktion ausgewählt. Refactoring. Um die Antworten realer Ärzte in die erforderlichen, qualitativ hochwertigen, einheitlich formatierten Antworten umzuwandeln, haben wir GPT-3.5 verwendet, um den Rekonstruktionsprozess dieses Datensatzes abzuschließen. Eingabeaufforderungen müssen umgeschrieben werden, um den folgenden Grundsätzen zu folgen: 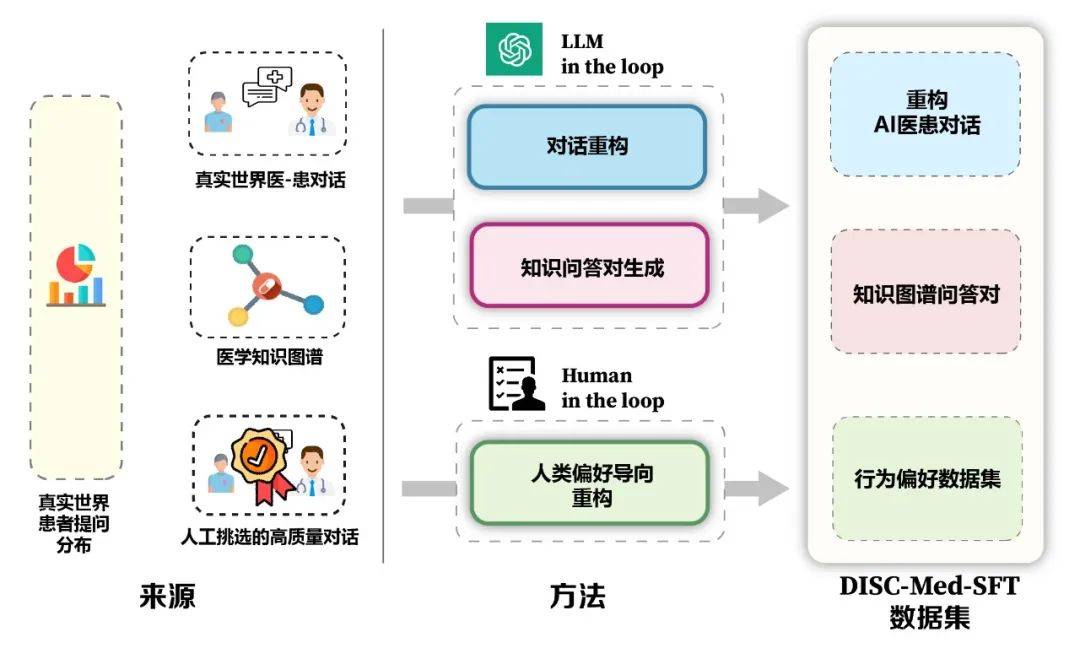
Entfernen Sie verbale Ausdrücke, extrahieren Sie einheitliche Ausdrücke und korrigieren Sie Inkonsistenzen im ärztlichen Sprachgebrauch.
Halten Sie sich an die wichtigsten Informationen in der ursprünglichen Antwort des Arztes und liefern Sie entsprechende Erklärungen, um umfassender und logischer zu sein.
Umschreiben oder löschen Sie Antworten, die KI-Ärzte nicht senden sollten, z. B. die Aufforderung an Patienten, einen Termin zu vereinbaren. Abbildung 6 zeigt ein Beispiel für Refactoring. Die Antworten des angepassten Arztes stimmen mit der Identität des KI-Arztassistenten überein, halten sich an die Schlüsselinformationen des ursprünglichen Arztes und bieten dem Patienten gleichzeitig eine umfassendere und umfassendere Hilfe. 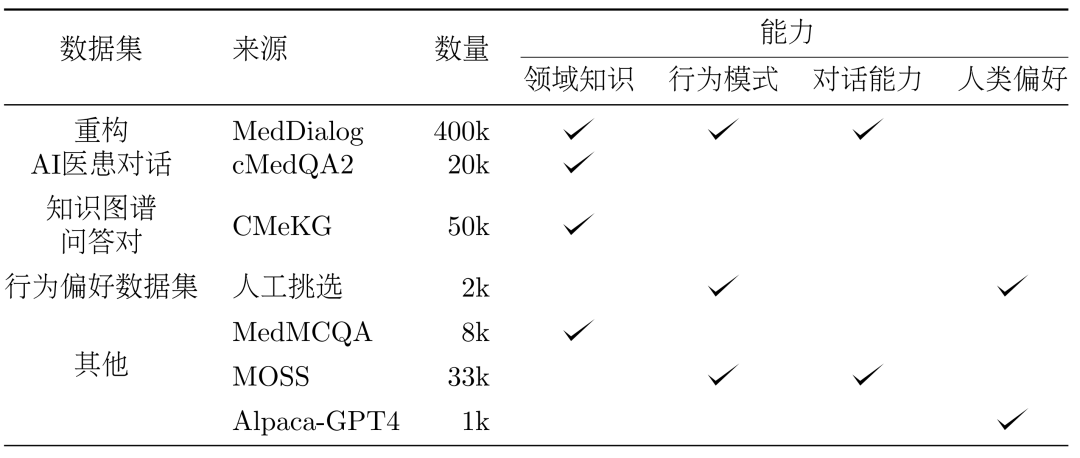
Abbildung 6: Beispiel für das Umschreiben von DialogenWissensdiagramm-Frage-Antwort-PaarMedizinisches Wissensdiagramm enthält eine große Menge gut organisierter medizinischer Fachkenntnisse, auf deren Grundlage weniger Lärm entstehen kann Es werden QA-Trainingsbeispiele generiert. Auf der Grundlage von CMeKG haben wir Stichproben im Wissensgraphen gemäß den Abteilungsinformationen von Krankheitsknoten gemacht und entsprechend gestaltete GPT-3.5-Modellaufforderungen verwendet, um insgesamt mehr als 50.000 verschiedene Dialogbeispiele für medizinische Szenen zu generieren. Verhaltenspräferenzdatensatz Um die Leistung des Modells in der letzten Trainingsphase weiter zu verbessern, verwenden wir einen Datensatz, der eher den menschlichen Verhaltenspräferenzen für die Sekundarstufe entspricht überwachte Feinabstimmung. Etwa 2000 hochwertige, unterschiedliche Proben wurden manuell aus den beiden Datensätzen von MedDialog und cMedQA2 ausgewählt. Nachdem wir mehrere Beispiele neu geschrieben und manuell in GPT-4 überarbeitet hatten, verwendeten wir die Methode für kleine Proben, um sie für GPT-3.5 bereitzustellen -Qualitätsdatensätze zu Verhaltenspräferenzen. Allgemeine Daten. Um die Vielfalt des Trainingssatzes zu bereichern und das Risiko einer Verschlechterung der Grundfähigkeiten des Modells während der SFT-Trainingsphase zu verringern, haben wir zufällig mehrere Stichproben aus zwei gängigen überwachten Feinabstimmungsdatensätzen ausgewählt, den Daten moss-sft-003 und alpaca gpt4 zh. MedMCQA. Um die Q&A-Fähigkeiten des Modells zu verbessern, haben wir MedMCQA ausgewählt, einen Multiple-Choice-Fragendatensatz im englischen medizinischen Bereich, und GPT-3.5 verwendet, um die Fragen und korrekten Antworten in den Multiple-Choice-Fragen zu optimieren und so etwa 8.000 professionelle Chinesen zu generieren Beispiele für medizinische Fragen und Antworten. Training. Wie in der folgenden Abbildung dargestellt, ist der Trainingsprozess von DISC-MedLLM in zwei SFT-Phasen unterteilt. 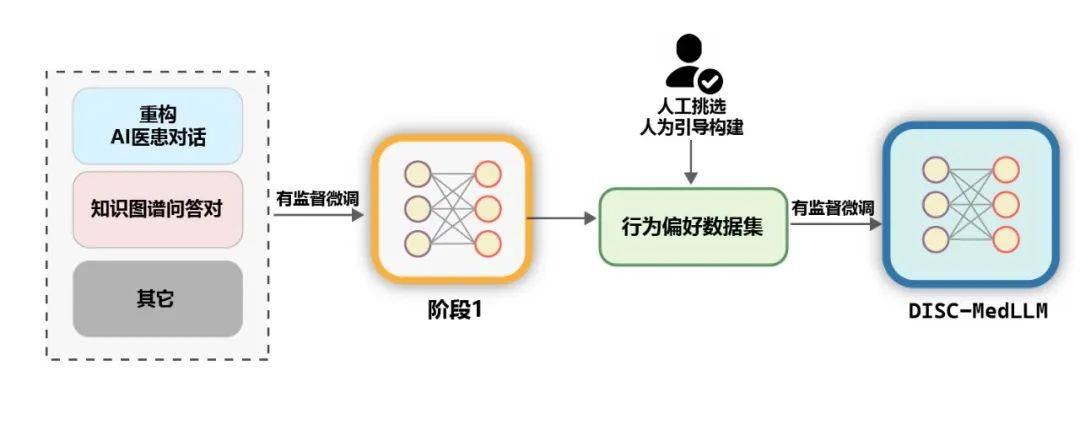
Abbildung 7: Zweistufiger TrainingsprozessBewertung. Die Leistung medizinischer LLMs wird in zwei Szenarien bewertet, nämlich in einer einzigen Runde der Qualitätssicherung und in einem mehrstufigen Dialog.
- Einzelrunde QS-Bewertung: Um die Genauigkeit des Modells im Hinblick auf medizinisches Wissen zu bewerten, haben wir 1500 Proben aus der chinesischen nationalen medizinischen Qualifikationsprüfung (NMLEC) und der nationalen Postgraduierten-Aufnahmeprüfung (NEEP) beprobt ) Western Medicine 306 Haupt- und Multiple-Choice-Fragen zur Bewertung der Leistung des Modells in einer einzigen QA-Runde.
- Mehrstufige Dialogbewertung: Um die Dialogfähigkeit des Modells systematisch zu bewerten, haben wir von drei öffentlichen Datensätzen ausgegangen – Chinese Medical Benchmark (CMB-Clin), Chinese Medical Dialogue Dataset (CMD) und Chinese Medical Intent Daten: Wählen Sie zufällig Proben aus dem Satz (CMID) aus und lassen Sie GPT-3.5 die Rolle des Patienten und des Dialogs mit dem Modell spielen. Es werden vier Bewertungsindikatoren vorgeschlagen – Initiative, Genauigkeit, Nützlichkeit und Sprachqualität, die von GPT-4 bewertet werden.
Modelle vergleichen. Unser Modell wird mit drei allgemeinen LLMs und zwei chinesischen medizinischen Konversations-LLMs verglichen. Einschließlich OpenAIs GPT-3.5, GPT-4, Baichuan-13B-Chat; Einzelne Runde der QA-Ergebnisse. Die Gesamtergebnisse der Multiple-Choice-Bewertung sind in Tabelle 2 dargestellt. GPT-3.5 weist einen klaren Vorsprung auf. DISC-MedLLM erreichte den zweiten Platz in der Einstellung mit kleinen Stichproben und belegte hinter Baichuan-13B-Chat den dritten Platz in der Einstellung mit null Stichproben. Bemerkenswert ist, dass wir HuatuoGPT (13B) übertreffen, das mit einer verstärkenden Lernumgebung trainiert wurde. 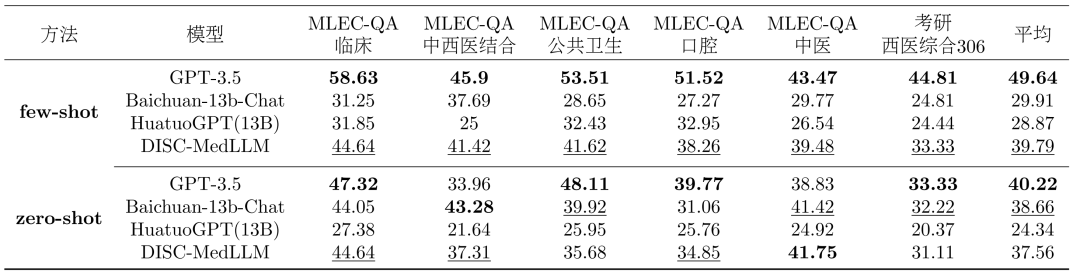
Tabelle 2: Multiple-Choice-BewertungsergebnisseErgebnisse mehrerer Dialogrunden. In der CMB-Clin-Bewertung erreichte DISC-MedLLM die höchste Gesamtpunktzahl, dicht gefolgt von HuatuoGPT. Unser Modell erzielte beim Positivitätskriterium die höchste Punktzahl, was die Wirksamkeit unseres Trainingsansatzes unterstreicht, der medizinische Verhaltensmuster verzerrt. Die Ergebnisse sind in Tabelle 3 dargestellt. 
Tabelle 3: CMB-Clin-ErgebnisseIn der CMD-Stichprobe, wie in Abbildung 8 dargestellt, erzielte GPT-4 die höchste Punktzahl, gefolgt von GPT-3,5. Die Modelle im medizinischen Bereich, DISC-MedLLM und HuatuoGPT, weisen insgesamt die gleichen Leistungswerte auf und ihre Leistung in verschiedenen Abteilungen ist hervorragend. 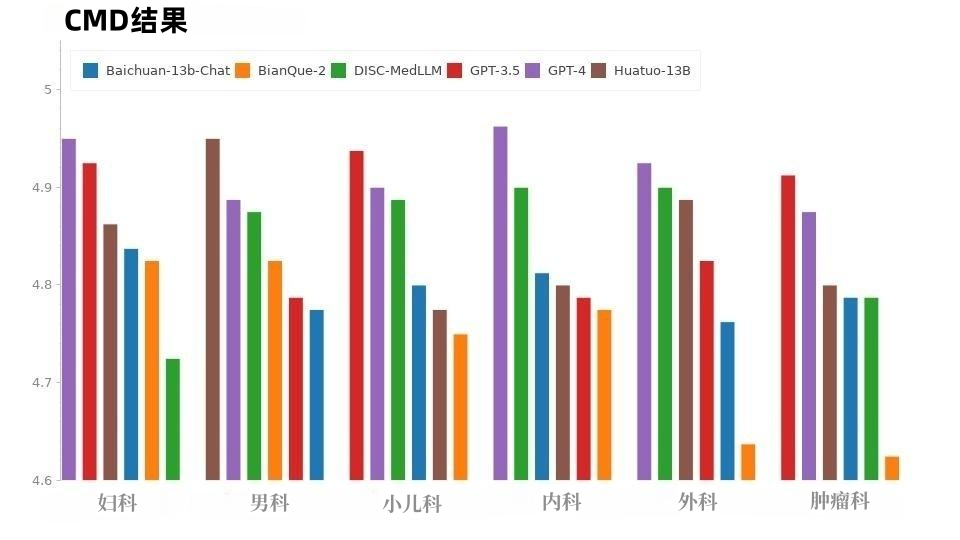
Abbildung 8: CMD-Ergebnisse Die Situation bei CMID ist ähnlich wie bei CMD, wie in Abbildung 9 dargestellt, GPT-4 und GPT-3.5 behalten die Führung. Mit Ausnahme der GPT-Serie schnitt DISC-MedLLM am besten ab. Es übertraf HuatuoGPT in drei Punkten: Zustand, Behandlungsschema und Medikation. 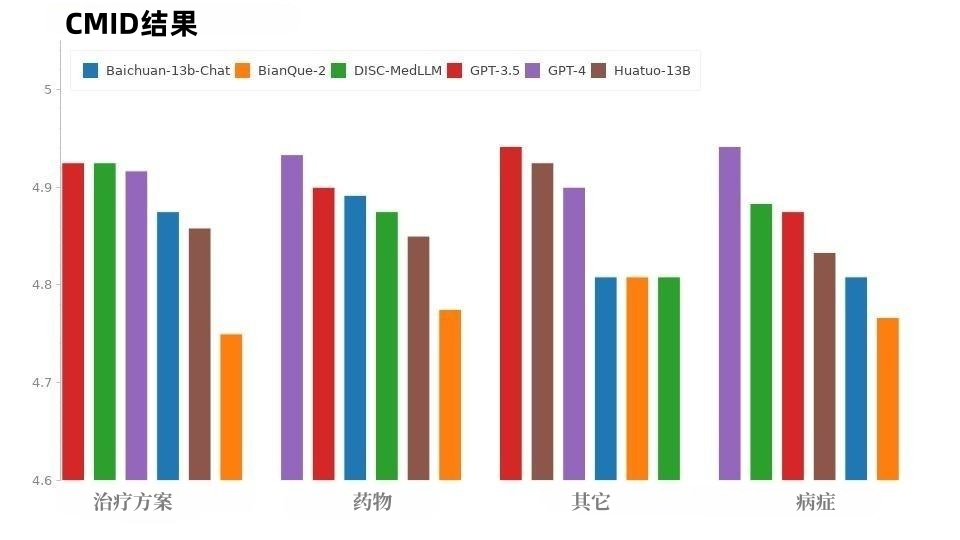
Abbildung 9: CMID-ErgebnisseDie inkonsistente Leistung jedes Modells zwischen CMB-Clin und CMD/CMID kann auf die unterschiedliche Datenverteilung zwischen den drei Datensätzen zurückzuführen sein. CMD und CMID enthalten eine explizitere Auswahl an Fragen, und Patienten haben möglicherweise eine Diagnose erhalten und bei der Beschreibung ihrer Symptome klare Bedürfnisse geäußert, und die Fragen und Bedürfnisse des Patienten haben möglicherweise sogar nichts mit seinem persönlichen Gesundheitszustand zu tun. Die in vielerlei Hinsicht herausragenden Allzweckmodelle GPT-3.5 und GPT-4 kommen mit dieser Situation besser zurecht. Der DISC-Med-SFT-Datensatz nutzt die Vorteile und Möglichkeiten des realen Dialogs und des allgemeinen Domänen-LLM und führt gezielte Verbesserungen in drei Aspekten durch: Domänenwissen, Medizinischer Dialog Fähigkeiten und menschliche Vorlieben; hochwertige Datensätze trainierten das hervorragende medizinische Großmodell DISC-MedLLM, das erhebliche Verbesserungen in der medizinischen Interaktion erzielte, eine hohe Benutzerfreundlichkeit zeigte und ein großes Anwendungspotenzial zeigte. Die Forschung in diesem Bereich wird mehr Perspektiven und Möglichkeiten zur Reduzierung der Online-Medizinkosten, zur Förderung medizinischer Ressourcen und zur Erreichung eines Gleichgewichts eröffnen. DISC-MedLLM wird mehr Menschen bequeme und personalisierte medizinische Dienste bieten und zur allgemeinen Gesundheit beitragen. Das obige ist der detaillierte Inhalt vonDas Team der Fudan-Universität veröffentlicht einen persönlichen Assistenten für chinesische Medizin und Gesundheit und stellt gleichzeitig 470.000 hochwertige Datensätze als Open Source zur Verfügung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

