
Heim >Backend-Entwicklung >Python-Tutorial >Regressionsanalyse und Best-Fit-Gerade mit Python
Regressionsanalyse und Best-Fit-Gerade mit Python

- 王林nach vorne
- 2023-08-28 09:33:051647Durchsuche
In diesem Tutorial implementieren wir eine Regressionsanalyse und eine Best-Fit-Linie mithilfe der Python-Programmierung
Einführung
Die Regressionsanalyse ist die grundlegendste Form der prädiktiven Analyse.
In der Statistik ist die lineare Regression eine Methode zur Modellierung der Beziehung zwischen einem Skalarwert und einer oder mehreren erklärenden Variablen.
Beim maschinellen Lernen ist die lineare Regression ein überwachter Algorithmus. Dieser Algorithmus sagt einen Zielwert basierend auf unabhängigen Variablen voraus.
Weitere Informationen zur linearen Regression und Regressionsanalyse
Bei der linearen Regression/Analyse ist das Ziel ein realer oder kontinuierlicher Wert wie Gehalt, BMI usw. Es wird häufig verwendet, um die Beziehung zwischen einer abhängigen Variablen und einer Reihe unabhängiger Variablen vorherzusagen. Diese Modelle passen typischerweise zu linearen Gleichungen, es gibt jedoch auch andere Arten der Regression, einschließlich Polynome höherer Ordnung.
Bevor ein lineares Modell an die Daten angepasst wird, muss überprüft werden, ob zwischen den Datenpunkten ein linearer Zusammenhang besteht. Dies geht aus ihrem Streudiagramm hervor. Das Ziel des Algorithmus/Modells besteht darin, die Linie mit der besten Anpassung zu finden.
In diesem Artikel werden wir die lineare Regressionsanalyse und ihre Implementierung mit C++ untersuchen.
Die lineare Regressionsgleichung hat die Form Y = c + mx, wobei Y die Zielvariable und X die unabhängige Variable oder erklärende Parameter/Variable ist. m ist die Steigung der Regressionsgeraden und c ist der Achsenabschnitt. Da es sich um eine 2D-Regressionsaufgabe handelt, versucht das Modell während des Trainings, die Linie mit der besten Anpassung zu finden. Es müssen nicht alle Punkte exakt auf derselben Linie liegen. Einige Datenpunkte liegen möglicherweise auf der Linie, andere sind möglicherweise über die Linie verstreut. Der vertikale Abstand zwischen der Linie und den Datenpunkten ist das Residuum. Der Wert kann negativ oder positiv sein, je nachdem, ob der Punkt unterhalb oder oberhalb der Linie liegt. Das Residuum ist ein Maß dafür, wie gut die Linie zu den Daten passt. Der Algorithmus ist kontinuierlich, um das Gesamtresiduum zu minimieren.
Das Residuum für jede Beobachtung ist die Differenz zwischen dem vorhergesagten Wert von y (der abhängigen Variablen) und dem beobachteten Wert von y
$$mathrm{residual: =: tatsächlich: y: Wert:−:Vorhersage: y: Wert}$$
$$mathrm{ri:=:yi:−:y'i}$$
Die gebräuchlichste Metrik zur Bewertung der Leistung eines linearen Regressionsmodells wird als Root Mean Square Error oder RMSE bezeichnet. Die Grundidee besteht darin, zu messen, wie schlecht/falsch die Vorhersagen des Modells im Vergleich zu tatsächlichen Beobachtungen sind.
Ein hoher RMSE ist also „schlecht“ und ein niedriger RMSE ist „gut“
RMSE-Fehler ist
$$mathrm{RMSE:=:sqrt{frac{sum_i^n=1:(this:-:this')^2}{n}}}$$ p>
RMSE ist die Wurzel des mittleren Quadrats aller Residuen.
Implementiert mit Python
Beispiel
# Import the libraries
import numpy as np
import math
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Generate random data with numpy, and plot it with matplotlib:
ranstate = np.random.RandomState(1)
x = 10 * ranstate.rand(100)
y = 2 * x - 5 + ranstate.randn(100)
plt.scatter(x, y);
plt.show()
# Creating a linear regression model based on the positioning of the data and Intercepting, and predicting a Best Fit:
lr_model = LinearRegression(fit_intercept=True)
lr_model.fit(x[:70, np.newaxis], y[:70])
y_fit = lr_model.predict(x[70:, np.newaxis])
mse = mean_squared_error(y[70:], y_fit)
rmse = math.sqrt(mse)
print("Mean Square Error : ",mse)
print("Root Mean Square Error : ",rmse)
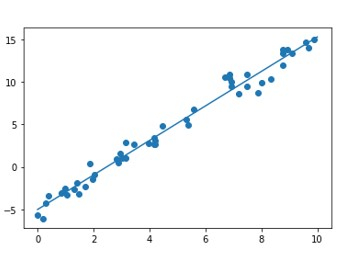
# Plot the estimated linear regression line using matplotlib:
plt.scatter(x, y)
plt.plot(x[70:], y_fit);
plt.show()
Ausgabe
Mean Square Error : 1.0859922470998231 Root Mean Square Error : 1.0421095178050257
Fazit
Die Regressionsanalyse ist eine sehr einfache, aber leistungsstarke Technik, die für prädiktive Analysen beim maschinellen Lernen und in der Statistik verwendet wird. Die Idee liegt in ihrer Einfachheit und der zugrunde liegenden linearen Beziehung zwischen den unabhängigen Variablen und den Zielvariablen.
Das obige ist der detaillierte Inhalt vonRegressionsanalyse und Best-Fit-Gerade mit Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!