Meta hat gestern das auf die Codegenerierung spezialisierte Basismodell Code Llama als Open Source veröffentlicht, das kostenlos für Forschungs- und kommerzielle Zwecke genutzt werden kann. Die Modelle der Code Llama-Serie verfügen über drei Parameterversionen mit Parametermengen von 7B, 13B bzw. 34B. Und unterstützt mehrere Programmiersprachen, darunter Python, C++, Java, PHP, Typescript (Javascript), C# und Bash. Meta bietet Code Llama-Versionen, einschließlich:
Code Llama, ein grundlegendes Codemodell;
Code Sheep-Python, eine fein abgestimmte Version von Python;
Code Llama-Instruct, eine fein abgestimmte Version für den Unterricht in natürlicher Sprache
In Bezug auf die Wirksamkeit übersteigt die einmalige Erfolgsquote (pass@1) verschiedener Versionen von Code Llama in den HumanEval- und MBPP-Datensätzen GPT-3.5. Darüber hinaus liegt der Pass@1 der „Unnatural“ 34B-Version von Code Llama im HumanEval-Datensatz nahe an GPT-4 (62,2 % gegenüber 67,0 %). Meta hat diese Version jedoch nicht veröffentlicht, aber durch das Training an einem kleinen Satz qualitativ hochwertiger codierter Daten wurden erhebliche Leistungsverbesserungen erzielt. 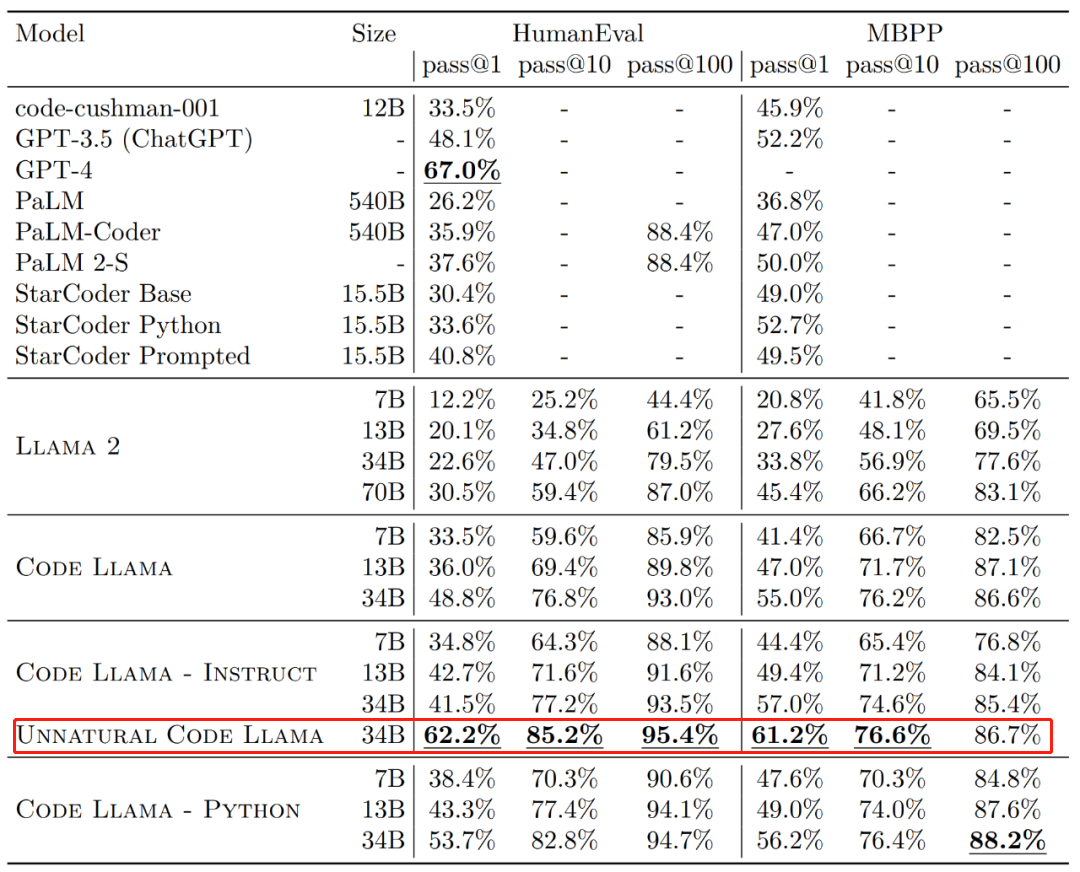 Bildquelle: https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/
Bildquelle: https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/
Kurz nach einem Tag meldete sich ein Forscher bei GPT-4 Eine Challenge wurde gestartet. Sie stammen von Phind, einer Organisation, die sich zum Ziel gesetzt hat, eine KI-Suchmaschine für Entwickler zu entwickeln, und die Forschung nutzte den fein abgestimmten Code Llama-34B, um GPT-4 in der HumanEval-Bewertung zu schlagen. Phind-Mitbegründer Michael Royzen sagte: „Dies ist nur ein frühes Experiment, das darauf abzielt, die „Unnatural Code Llama“-Ergebnisse im Meta-Paper zu reproduzieren (und zu übertreffen). In Zukunft werden wir über ein Expertenportfolio verschiedener CodeLlama-Modelle verfügen, von denen ich denke, dass sie in realen Arbeitsabläufen konkurrenzfähig sein werden. „
Beide Modelle waren Open Source: 
Die Forscher haben diese beiden Modelle auf Huggingface veröffentlicht, Sie können sie sich ansehen.
- Phind-CodeLlama-34B-v1: https://huggingface.co/Phind/Phind-CodeLlama-34B-v1
- Phind-CodeLlama-34B-Python-v1: https://huggingface.co /Phind/Phind-CodeLlama-34B-Python-v1
Als nächstes wollen wir sehen, wie diese Forschung umgesetzt wurde. Der Code Llama-34B wurde optimiert, um GPT-4 zu schlagen. Schauen wir uns zunächst die Ergebnisse an. In dieser Studie wurden interne Datensätze von Phind zur Feinabstimmung von Code Llama-34B und Code Llama-34B-Python verwendet, was zu zwei Modellen führte: Phind-CodeLlama-34B-v1 bzw. Phind-CodeLlama-34B-Python-v1. Die beiden neu erhaltenen Modelle erreichten bei HumanEval 67,6 % bzw. 69,5 % pass@1. Zum Vergleich: CodeLlama-34B pass@1 beträgt 48,8 %; CodeLlama-34B-Python pass@1 beträgt 53,7 %. Und der Pass@1 von GPT-4 bei HumanEval liegt bei 67 % (Daten, die von OpenAI im „GPT-4 Technical Report“ veröffentlicht wurden, der im März dieses Jahres veröffentlicht wurde). 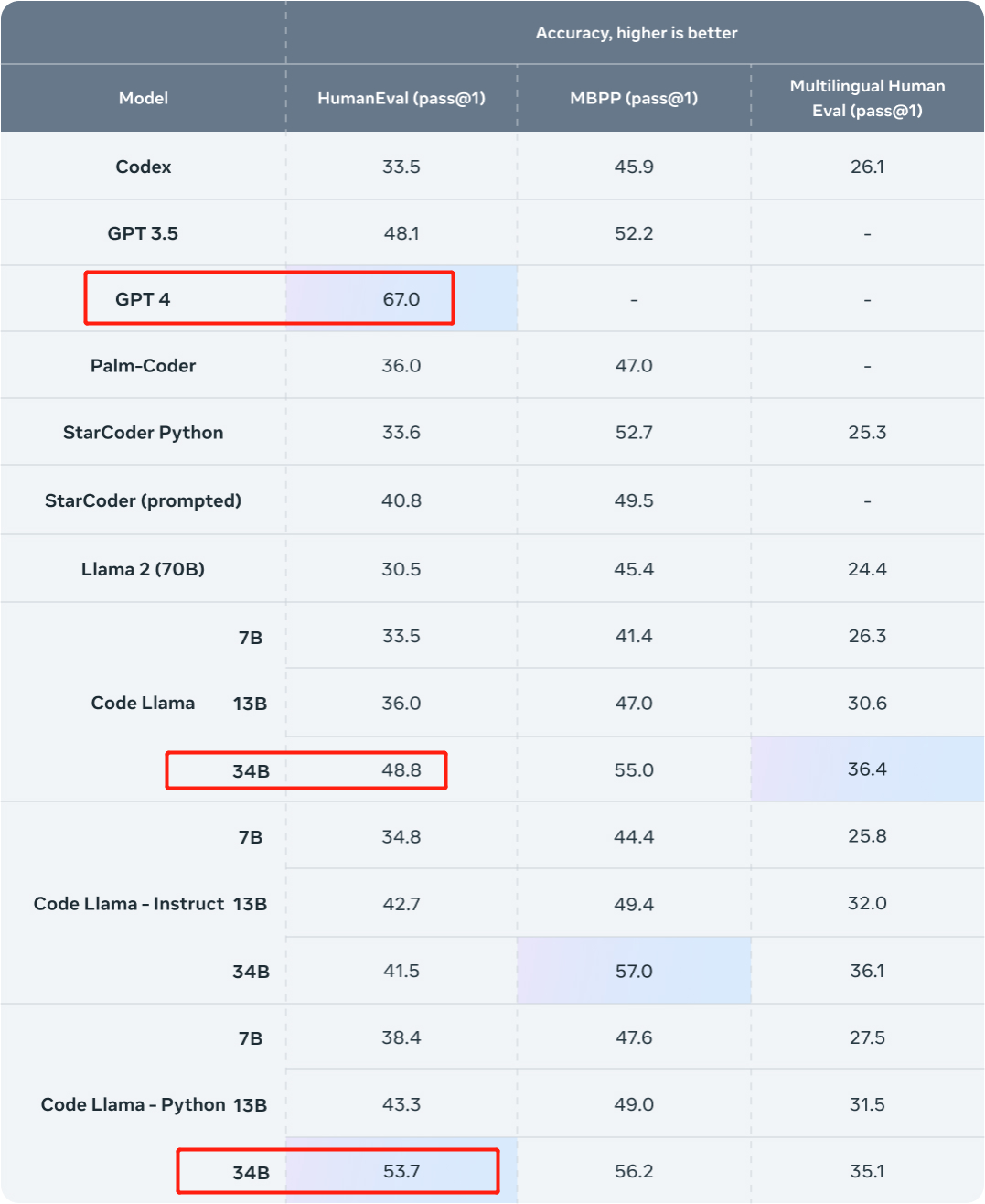 Bildquelle: https://ai.meta.com/blog/code-llama-large-lingual-model-coding/
Bildquelle: https://ai.meta.com/blog/code-llama-large-lingual-model-coding/
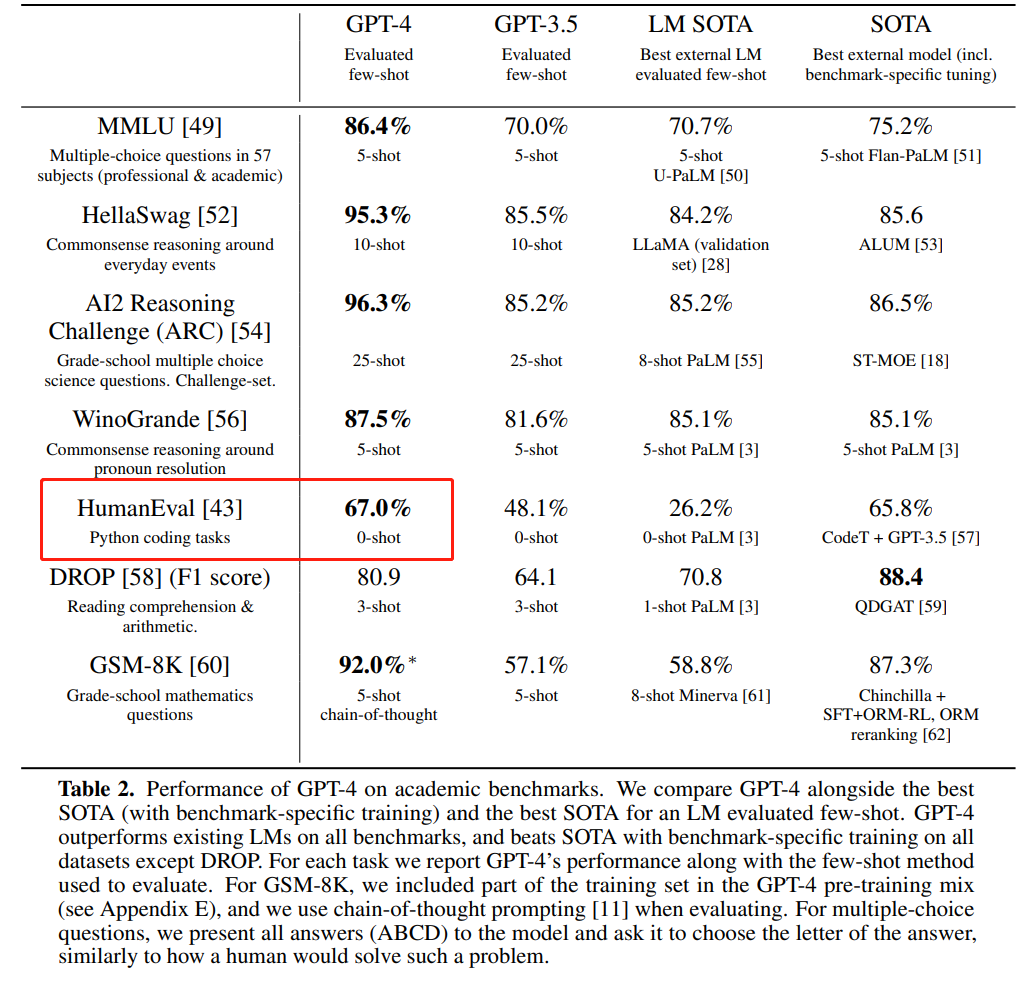 Bildquelle: https://cdn. openai.com/papers/gpt-4.pdf
Bildquelle: https://cdn. openai.com/papers/gpt-4.pdf
Apropos Feinabstimmung: In dieser Studie wurden Code Llama-34B und Code Llama-34B-Python anhand eines proprietären Datensatzes mit etwa 80.000 hochwertigen Programmierproblemen und -lösungen verfeinert. Dieser Datensatz verwendet keine Code-Vervollständigungsbeispiele, sondern Anweisungs-Antwort-Paare, was sich von der HumanEval-Datenstruktur unterscheidet. Anschließend trainierte die Studie das Phind-Modell für zwei Epochen mit insgesamt etwa 160.000 Beispielen. Die Forscher sagten, dass im Training keine LoRA-Technologie verwendet wurde, sondern eine lokale Feinabstimmung zum Einsatz kam. Darüber hinaus nutzte die Studie auch die DeepSpeed ZeRO 3- und Flash Attention 2-Technologie. Sie verbrachten drei Stunden mit 32 A100-80GB-GPUs, um diese Modelle mit einer Sequenzlänge von 4096 Token zu trainieren. Darüber hinaus wandte die Studie auch die Dekontaminationsmethode von OpenAI auf den Datensatz an, um die Modellergebnisse effektiver zu machen. Es ist bekannt, dass selbst das sehr leistungsstarke GPT-4 mit dem Dilemma der Datenverschmutzung konfrontiert sein wird. Laienhaft ausgedrückt wurde das trainierte Modell möglicherweise anhand der Auswertungsdaten trainiert. Dieses Problem ist für LLM sehr schwierig. Um beispielsweise die Leistung eines Modells zu bewerten, muss der Forscher prüfen, ob das zur Bewertung herangezogene Problem im Training liegt Daten des Modells. Wenn dies der Fall ist, kann sich das Modell an diese Probleme erinnern und wird bei der Bewertung des Modells bei diesen spezifischen Problemen offensichtlich eine bessere Leistung erbringen. Es ist, als ob eine Person die Prüfungsfragen kennt, bevor sie an der Prüfung teilnimmt. Um dieses Problem zu lösen, hat OpenAI im öffentlichen technischen GPT-4-Dokument „GPT-4 Technical Report“ offengelegt, wie GPT-4 die Datenverschmutzung bewertet. Sie legen ihre Strategien zur Quantifizierung und Bewertung dieser Datenverschmutzung offen. Konkret verwendet OpenAI den Teilstring-Abgleich, um die Kreuzkontamination zwischen dem Bewertungsdatensatz und den Vortrainingsdaten zu messen. Sowohl Evaluierungs- als auch Trainingsdaten werden verarbeitet, indem alle Leerzeichen und Symbole entfernt werden und nur Zeichen (einschließlich Zahlen) übrig bleiben. Für jedes Bewertungsbeispiel wählt OpenAI zufällig drei Teilzeichenfolgen mit 50 Zeichen aus (bei weniger als 50 Zeichen wird das gesamte Beispiel verwendet). Eine Übereinstimmung wird festgestellt, wenn einer der drei abgetasteten Bewertungsteilstrings ein Teilstring des verarbeiteten Trainingsbeispiels ist. Dadurch wird eine Liste fehlerhafter Beispiele erstellt, die OpenAI verwirft und erneut ausführt, um eine makellose Punktzahl zu erhalten. Diese Filtermethode weist jedoch einige Einschränkungen auf. Der Teilstring-Abgleich kann sowohl zu falsch-negativen Ergebnissen (wenn es kleine Unterschiede zwischen den Auswertungs- und Trainingsdaten gibt) als auch zu falsch-positiven Ergebnissen führen. Infolgedessen verwendet OpenAI nur einen Teil der Informationen im Bewertungsbeispiel, nutzt nur Fragen, Kontext oder gleichwertige Daten und ignoriert Antworten, Antworten oder gleichwertige Daten. Teilweise sind auch Multiple-Choice-Möglichkeiten ausgeschlossen. Diese Ausschlüsse können zu einer Zunahme falsch positiver Ergebnisse führen. Zu diesem Teil können interessierte Leser auf den Artikel verweisen, um mehr zu erfahren. Papieradresse: https://cdn.openai.com/papers/gpt-4.pdfEs gibt jedoch einige Kontroversen über den HumanEval-Score, den Phind beim Benchmarking von GPT-4 verwendet. Einige Leute sagen, dass das neueste Testergebnis von GPT-4 85 % erreicht hat. Phind antwortete jedoch, dass die relevante Forschung, die diesen Wert abgeleitet habe, keine Kontaminationsforschung durchgeführt habe und es unmöglich sei festzustellen, ob GPT-4 die Testdaten von HumanEval gesehen habe, als es eine neue Testrunde erhielt. In Anbetracht einiger neuerer Untersuchungen zum Thema „GPT-4 wird dumm“ ist es sicherer, die Daten im ursprünglichen technischen Bericht zu verwenden. 
Angesichts der Komplexität der Bewertung großer Modelle ist jedoch immer noch eine umstrittene Frage, ob diese Bewertungsergebnisse die wahren Fähigkeiten des Modells widerspiegeln können. Sie können das Modell herunterladen und selbst erleben. Der neu geschriebene Inhalt ist wie folgt: Referenzlink:
Der Inhalt, der neu geschrieben werden muss, ist: https://benjaminmarie.com/the-decontaminated-evaluation-of-gpt-4/
Der Inhalt, der neu geschrieben werden muss, ist: Der Inhalt ist: https://www.phind.com/blog/code-llama-beats-gpt4
Das obige ist der detaillierte Inhalt vonDie Codierungsfunktionen von Code Llama stiegen sprunghaft an, und die verfeinerte Version von HumanEval schnitt besser ab als GPT-4 und wurde innerhalb eines Tages veröffentlicht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

