
Heim >Java >javaLernprogramm >Kafka aus Interviewperspektive abgeschlossen
Kafka aus Interviewperspektive abgeschlossen
- Java后端技术全栈nach vorne
- 2023-08-24 15:22:041259Durchsuche
Kafka ist eine hervorragende verteilte Nachrichten-Middleware, die in vielen Systemen für die Nachrichtenkommunikation verwendet wird. Das Verstehen und Verwenden verteilter Messagingsysteme ist für einen Backend-Entwickler fast zu einer notwendigen Fähigkeit geworden. Heute 码哥字节 Ich beginne mit häufigen Kafka-Interviewfragen und spreche mit Ihnen über Kafka.
Lassen Sie uns über Distributed Message Middleware sprechen
Fragen
Was ist Distributed Message Middleware? Welche Rolle spielt die Nachrichten-Middleware? Was sind die Einsatzszenarien von Nachrichten-Middleware? Auswahl der Nachrichten-Middleware?

Distributed Messaging ist ein Kommunikationsmechanismus. Im Gegensatz zu RPC, HTTP, RMI usw. verwendet Message Middleware einen verteilten Middle Agent für die Kommunikation. Wie in der Abbildung gezeigt, sendet das vorgelagerte Geschäftssystem nach Verwendung der Nachrichten-Middleware Nachrichten, die zunächst in der Nachrichten-Middleware gespeichert werden, und dann verteilt die Nachrichten-Middleware die Nachrichten an die entsprechenden Geschäftsmodulanwendungen (verteiltes Producer-Consumer-Modell). Dieser asynchrone Ansatz reduziert den Grad der Kopplung zwischen Diensten.
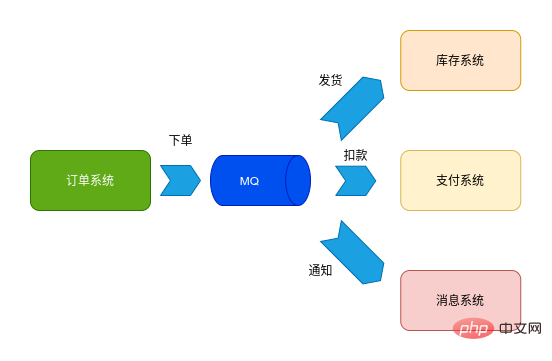
Nachrichten-Middleware definieren:
Nutzen Sie einen effizienten und zuverlässigen Nachrichtenübermittlungsmechanismus für den plattformunabhängigen Datenaustausch. Basierend auf Datenkommunikation, um verteilte Systeme zu integrieren. Durch die Bereitstellung von Nachrichtenübermittlungs- und Nachrichtenwarteschlangenmodellen kann es in einer verteilten Umgebung verwendet werden Die Erweiterung der prozessübergreifenden Kommunikation
Der Verweis auf zusätzliche Komponenten in der Systemarchitektur erhöht zwangsläufig die architektonische Komplexität des Systems und die Schwierigkeit von Betrieb und Wartung. Was sind also die Vorteile der Verwendung verteilter Messaging-Middleware im System? Welche Rolle spielt die Nachrichten-Middleware im System?
Entkopplung Redundanz (Speicherung) Skalierbarkeit Peak-Clipping Wiederherstellbarkeit -
Auftragsgarantie Pufferung Asynchrone Kommunikation
Bei Interviews achten Interviewer häufig auf die Fähigkeit des Interviewers, Open-Source-Komponenten auszuwählen. Dies kann nicht nur die Breite des Wissens des Interviewers, sondern auch die Tiefe seines Wissens über einen bestimmten Systemtyp testen dass der Interviewer in der Lage ist, das Gesamtsystem und den Systemarchitekturentwurf zu verstehen. Es gibt viele verteilte Open-Source-Messaging-Systeme und verschiedene Messaging-Systeme haben unterschiedliche Eigenschaften. Die Auswahl eines Messaging-Systems erfordert nicht nur ein gewisses Verständnis für jedes Messaging-System, sondern auch ein klares Verständnis Ihrer eigenen Systemanforderungen.
Das Folgende ist ein Vergleich mehrerer gängiger verteilter Nachrichtensysteme:
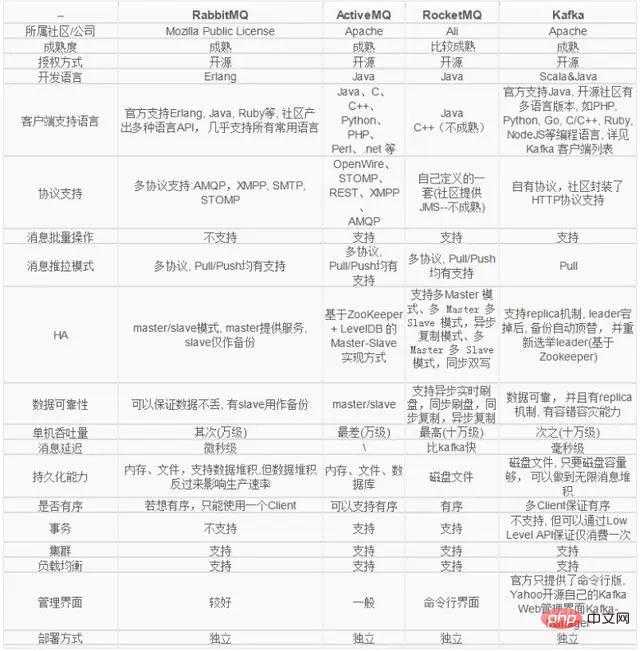
Antwortschlüsselwort
Was ist Distributed Messaging Middleware? Kommunikation, Warteschlange, verteilt, Produzenten-Konsumenten-Modell. Welche Rolle spielt die Nachrichten-Middleware? Entkopplung, Peak-Handling, asynchrone Kommunikation, Pufferung. Was sind die Einsatzszenarien von Nachrichten-Middleware? Asynchrone Kommunikation, Nachrichtenspeicherung und -verarbeitung. Auswahl der Nachrichten-Middleware? Sprache, Protokoll, HA, Datenzuverlässigkeit, Leistung, Transaktion, Ökologie, Einfachheit, Push-Pull-Modus.
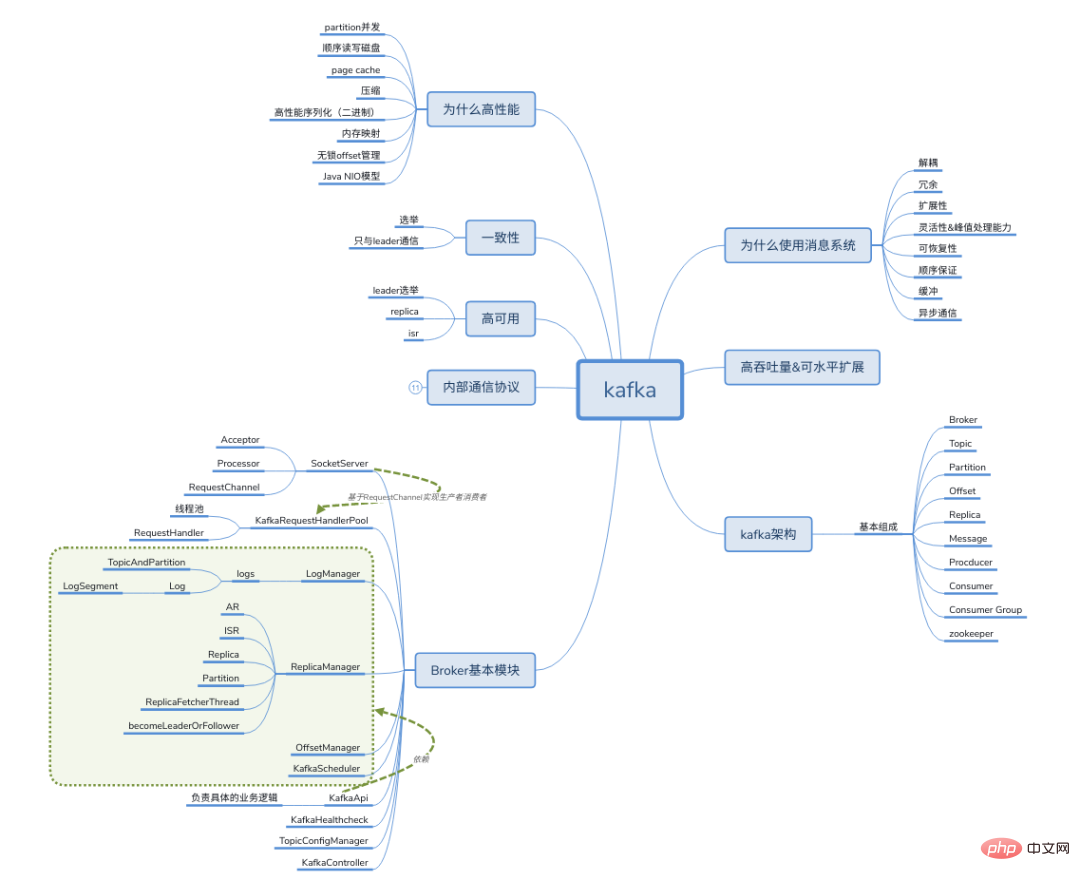
Grundkonzepte und Architektur von Kafka
Frage
Kurz über die Architektur von Kafka sprechen? Ist Kafka ein Push-Modus oder ein Pull-Modus? Was ist der Unterschied zwischen Push und Pull? Wie verbreitet Kafka Nachrichten? Sind Kafkas Botschaften in Ordnung? Unterstützt Kafka die Lese- und Schreibtrennung? Wie stellt Kafka eine hohe Datenverfügbarkeit sicher? Welche Rolle spielt der Tierpfleger bei Kafka? Unterstützt es Transaktionen? Kann die Anzahl der Partitionen reduziert werden?
Allgemeine Konzepte in der Kafka-Architektur:
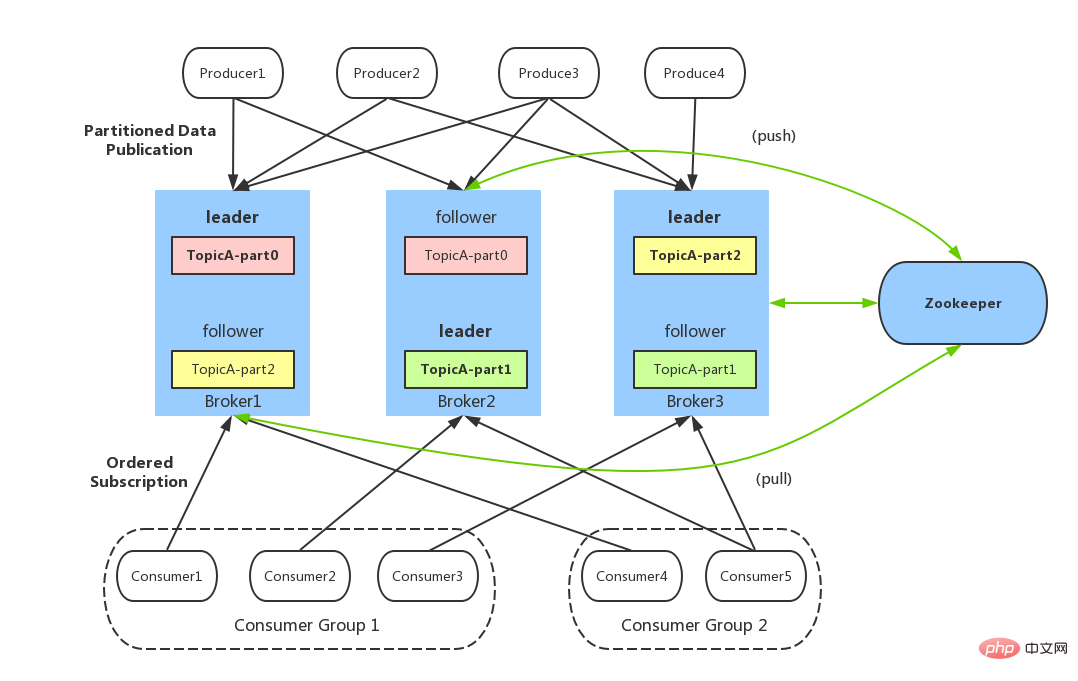
Produzent: Produzent, das ist die Partei, die Nachrichten sendet. Die Produzenten sind dafür verantwortlich, Nachrichten zu erstellen und sie dann an Kafka zu senden. Verbraucher: Verbraucher, also die Partei, die die Nachricht empfängt. Verbraucher stellen eine Verbindung zu Kafka her, empfangen Nachrichten und führen dann die entsprechende Geschäftslogikverarbeitung durch. Verbrauchergruppe: Eine Verbrauchergruppe kann einen oder mehrere Verbraucher enthalten. Die Verwendung des Multipartitions- und Multi-Consumer-Ansatzes kann die Verarbeitungsgeschwindigkeit von Downstream-Daten erheblich verbessern. Verbraucher in derselben Consumer-Gruppe werden Nachrichten nicht wiederholt konsumieren. Ebenso wirken sich Nachrichten, die von Consumern in verschiedenen Consumer-Gruppen gesendet werden, nicht gegenseitig aus. Kafka implementiert den Nachrichten-P2P-Modus und den Broadcast-Modus über Verbrauchergruppen. Broker: Dienst-Proxy-Knoten. Der Broker ist der Serviceknoten von Kafka, also der Server von Kafka. Thema: Nachrichten in Kafka sind in Themeneinheiten unterteilt. Der Produzent sendet die Nachricht an ein bestimmtes Thema, und der Verbraucher ist dafür verantwortlich, die Nachricht des Themas zu abonnieren und zu konsumieren. Partition: Thema ist ein logisches Konzept, das in mehrere Partitionen unterteilt werden kann und jede Partition nur zu einem einzigen Thema gehört. Verschiedene Partitionen unter demselben Thema enthalten unterschiedliche Nachrichten. Die Partition kann als anfügbare Protokolldatei auf Speicherebene betrachtet werden. Wenn Nachrichten an die Partitionsprotokolldatei angehängt werden, wird ihnen ein bestimmter Offset zugewiesen. Offset: Kafka verwendet ihn, um die Reihenfolge der Nachricht innerhalb der Partition sicherzustellen. Mit anderen Worten: Kafka garantiert die Reihenfolge der Aufteilung und nicht der Reihenfolge der Nachricht. Replikation ist Kafkas Methode, um eine hohe Datenverfügbarkeit sicherzustellen. Normalerweise stellt nur die primäre Kopie externe Lese- und Schreibdienste bereit Wenn es einen Absturz gibt oder ein Netzwerkfehler auftritt, wählt Kafka von Zeit zu Zeit erneut eine neue Leader-Kopie aus, um externe Lese- und Schreibdienste unter der Verwaltung des Controllers bereitzustellen. Datensatz: Der Nachrichtendatensatz, der tatsächlich an Kafka geschrieben wird und gelesen werden kann. Jeder Datensatz enthält Schlüssel, Wert und Zeitstempel.
Layout der Kafka-Themenpartitionen
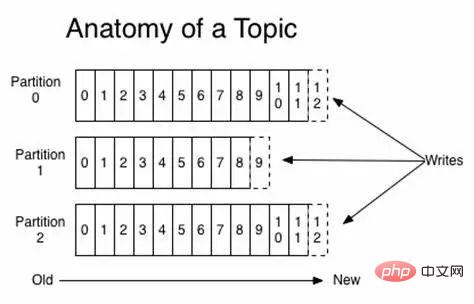
Kafka-Themenpartitionen, und die Partitionen können gleichzeitig gelesen und geschrieben werden.
Kafka Consumer Offset
„Verbraucher-Offset“: Zookeeper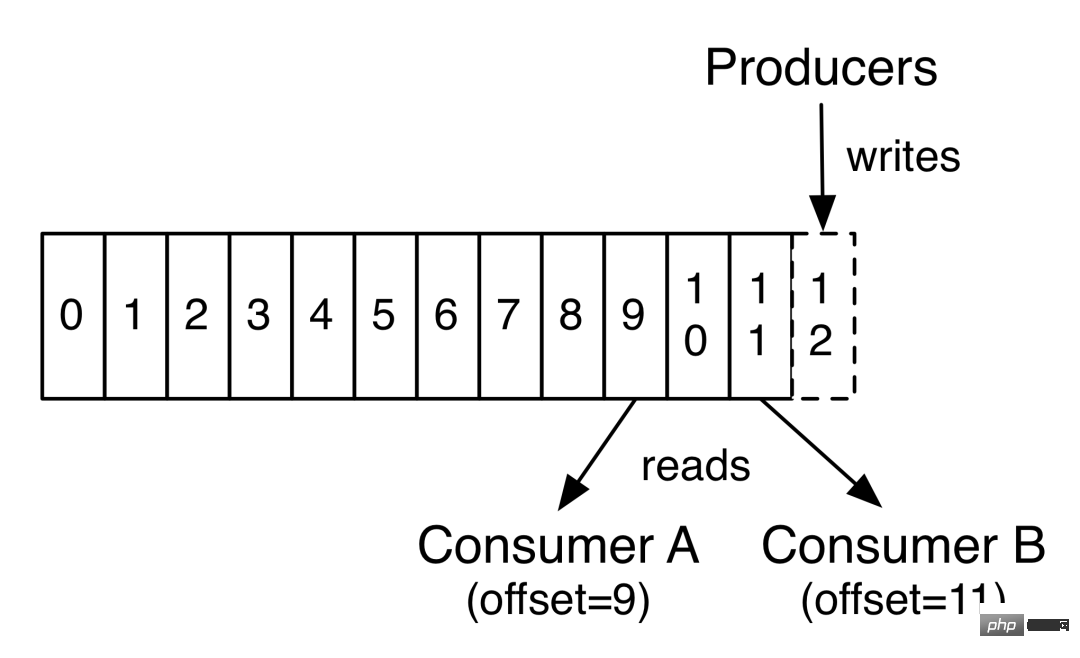
Producer-Lastausgleich: Da dieselbe Topic-Nachricht partitioniert und auf mehrere Broker verteilt wird, muss der Produzent die Nachrichten angemessen an diese verteilten Broker senden.
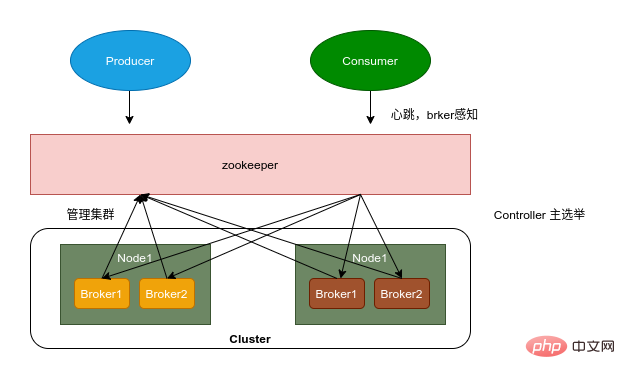
- Antwortschlüsselwörter
- Kurz über die Architektur von Kafka sprechen?
- Produzent, Verbraucher, Verbrauchergruppe, Thema, Partition
Ist Kafka ein Push-Modus oder ein Pull-Modus? Was ist der Unterschied zwischen Push und Pull?
Wie sendet Kafka Nachrichten? Konsumentengruppe
Sind Kafkas Botschaften in Ordnung?
Themenebenen sind ungeordnet und Partitionen sind geordnet
Unterstützt Kafka die Lese-/Schreibtrennung?
Nicht unterstützt, nur Leader bietet externe Lese- und Schreibdienste
Wie stellt Kafka eine hohe Datenverfügbarkeit sicher?
Kopieren, bestätigen, HW
Welche Rolle spielt der Tierpfleger bei Kafka?
Clusterverwaltung, Metadatenverwaltung
Unterstützt es Transaktionen?
Nach 0.11 werden Transaktionen unterstützt und können „genau einmal“ durchgeführt werden
Kann die Anzahl der Partitionen reduziert werden?
Nein, Daten gehen verloren
Kafka mit
Fragen
Was sind die Befehlszeilentools für Kafka? Welche haben Sie verwendet? Der Ausführungsprozess von Kafka Producer? Was sind die gängigen Konfigurationen von Kafka Producer? Wie halte ich Kafka-Nachrichten in Ordnung? Wie stellt Producer sicher, dass Daten verlustfrei gesendet werden? Wie kann die Leistung des Produzenten verbessert werden? Wenn die Anzahl der Verbraucher in derselben Gruppe größer ist als die Anzahl der Teile, wie geht Kafka damit um? Ist Kafka Consumer Thread-sicher? Erzählen Sie mir etwas über das Thread-Modell, wenn Sie Kafka Consumer zum Konsumieren von Nachrichten verwenden. Warum ist es so konzipiert? Häufige Konfigurationen von Kafka Consumer? Wann wird Consumer aus dem Cluster geworfen? Wie wird Kafka reagieren, wenn ein Verbraucher beitritt oder austritt? Was ist Rebalance und wann findet Rebalance statt?
Befehlszeilentool
Das Befehlszeilentool von Kafka befindet sich im /bin-Verzeichnis des Kafka-Pakets, das hauptsächlich Dienst- und Clusterverwaltungsskripts, Konfigurationsskripts, Informationsanzeigeskripts, Themenskripts, Clientskripts usw. enthält .
kafka-configs.sh: Konfigurationsverwaltungsskript kafka-console-consumer.sh: Kafka-Konsumentenkonsole kafka-console-producer.sh: Kafka-Produzentenkonsole kafka-consumer- groups.sh: Informationen zur Kafka-Verbrauchergruppe kafka-delete-records.sh: Niedrigwasser-Protokolldateien löschen -
kafka-log-dirs.sh: Informationen zum Kafka-Nachrichtenprotokollverzeichnis kafka- Mirror-maker.sh: Kafka-Cluster-Replikationstool in verschiedenen Rechenzentren kafka-preferred-replica-election.sh: bevorzugte Replikatwahl auslösen kafka-producer-perf-test.sh: Kafka-Produzenten-Leistungstest script kafka-reassign-partitions.sh: Partitionsneuzuweisungsskript kafka-replica-verification.sh: Skript zur Überprüfung des Replikationsfortschritts kafka-server-start.sh: Starten Sie den Kafka-Dienst kafka-server-stop.sh: Stoppen Sie den Kafka-Dienst kafka-topics.sh: Themenverwaltungsskript -
kafka-verifiable-consumer.sh: Überprüfbarer Kafka-Verbraucher kafka-verifiable- Producer.sh: Überprüfbarer Kafka-Produzent zookeeper-server-start.sh: ZK-Dienst starten zookeeper-server-stop.sh: ZK-Dienst stoppen -
zookeeper-shell.sh: ZK-Client
Wir können normalerweise kafka-console-consumer.sh和kafka-console-producer.sh脚本来测试 Kafka 生产和消费,kafka-consumer-groups.sh可以查看和管理集群中的 Topic,kafka-topics.shwird normalerweise verwendet werden, um den Verbrauchergruppenstatus von Kafka anzuzeigen.
Kafka Producer
Die normale Produktionslogik des Kafka Producers umfasst die folgenden Schritte:
Konfigurieren Sie Producer-Client-Parameter für allgemeine Producer-Instanzen. Erstellen Sie die zu sendende Nachricht. Senden Sie eine Nachricht. Schließen Sie die Producer-Instanz.
Der Prozess des Produzenten zum Versenden von Nachrichten ist in der Abbildung unten dargestellt, die stapelweise an den Broker gesendet werden muss. 拦截器,序列化器和分区器,最终由累加器
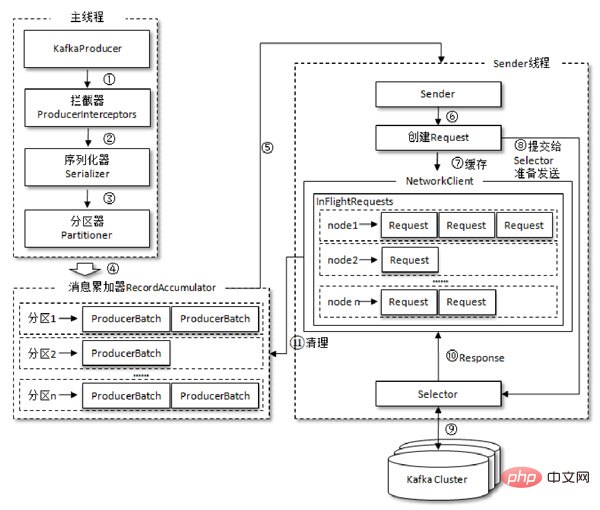 producer
producer- bootstrap.server: Geben Sie die Adresse von Kafkas Broker an
- key.serializer: Schlüsselserialisierer.
- value e .serializer:value Serializer
batch.num.messages Standardwert: 200, die Anzahl der Nachrichten in jedem Stapel, funktioniert nur für ASYC.
request.required.acks Standardwert: 0, 0 bedeutet, dass der Produzent nicht auf die Bestätigung des Leiters warten muss, 1 bedeutet, dass der Leiter das Schreiben in sein lokales Protokoll bestätigen und dies sofort bestätigen muss, -1 bedeutet, dass der Produzent dies bestätigen muss nachdem alle Sicherungen abgeschlossen sind. Es funktioniert nur im asynchronen Modus. Die Anpassung dieses Parameters ist ein Kompromiss zwischen Datenverlust und Übertragungseffizienz. Wenn Sie nicht empfindlich auf Datenverlust reagieren, aber Wert auf Effizienz legen, können Sie ihn auf 0 setzen, was die Effizienz erheblich verbessern kann der Produzent bei der Übermittlung von Daten.
request.timeout.ms
Standardwert: 10000, Bestätigungszeitlimit.
partitioner.class
Standardwert: kafka.producer.DefaultPartitioner, muss kafka.producer.Partitioner implementieren und eine Partitionierungsstrategie basierend auf dem Schlüssel bereitstellen. Manchmal müssen dieselben Nachrichtentypen nacheinander verarbeitet werden, daher müssen wir die Zuordnungsstrategie anpassen, um dieselben Datentypen derselben Partition zuzuweisen.
producer.type
Standardwert: sync, gibt an, ob die Nachricht synchron oder asynchron gesendet wird. Verwenden Sie kafka.producer.AyncProducer für asynchrones asynchrones Batch-Versenden und kafka.producer.SyncProducer für synchrone Synchronisierung. Synchrones und asynchrones Senden wirken sich auch auf die Effizienz der Nachrichtenproduktion aus.
compression.topic
Standardwert: keine, Nachrichtenkomprimierung, standardmäßig keine Komprimierung. Weitere Komprimierungsmethoden sind „gzip“, „snappy“ und „lz4“. Durch die Komprimierung von Nachrichten können das Netzwerkübertragungsvolumen und die Netzwerk-E/A erheblich reduziert und so die Gesamtleistung verbessert werden.
compressed.topics
Standardwert: null Wenn die Komprimierung festgelegt ist, können Sie eine bestimmte Themenkomprimierung angeben. Wenn nicht angegeben, wird die gesamte Komprimierung durchgeführt.
message.send.max.retries
Standardwert: 3, die maximale Anzahl der Versuche, Nachrichten zu senden.
retry.backoff.ms
Standardwert: 300, jedem Versuch wird ein zusätzliches Intervall hinzugefügt.
topic.metadata.refresh.interval.ms
Standardwert: 600000, die Zeit, um regelmäßig Metadaten abzurufen. Wenn die Partition verloren geht und der Leader nicht verfügbar ist, ruft der Produzent auch aktiv Metadaten ab. Wenn er 0 ist, werden Metadaten bei jedem Senden der Nachricht abgerufen, was nicht empfohlen wird. Wenn negativ, werden Metadaten nur bei einem Fehler abgerufen.
queue.buffering.max.ms
Standardwert: 5000, die maximale Zeit zum Zwischenspeichern von Daten in der Producer-Warteschlange, nur für ASYC.
queue.buffering.max.message
Standardwert: 10000, die maximale Anzahl der vom Produzenten zwischengespeicherten Nachrichten, nur für ASYC.
queue.enqueue.timeout.ms
Standardwert: -1, 0 wird verworfen, wenn die Warteschlange voll ist, der negative Wert ist der Block, wenn die Warteschlange voll ist, der positive Wert ist die entsprechende Zeit des Blocks, wenn die Warteschlange voll ist, nur für ASYC.
Kafka-Verbraucher
Jeder Verbraucher kann nur Nachrichten aus der zugewiesenen Partition konsumieren, und jede Partition kann nur von einem Verbraucher in einer Verbrauchergruppe konsumiert werden. Wenn also die Anzahl der Verbraucher in derselben Verbrauchergruppe die Anzahl der Partitionen überschreitet, werden einigen Verbrauchern Partitionen zugewiesen, die nicht verbraucht werden können. Die Beziehung zwischen Verbrauchergruppen und Verbrauchern ist in der folgenden Abbildung dargestellt:
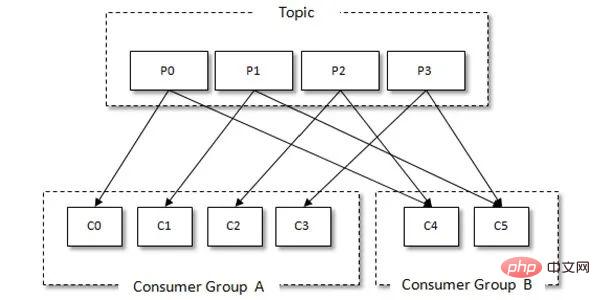
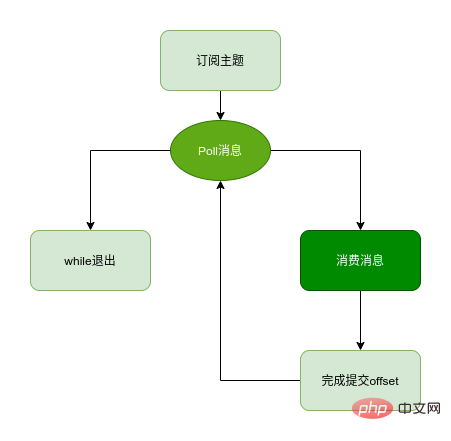
Der Konsum von Nachrichten durch den Kafka Consumer Client umfasst normalerweise die folgenden Schritte:
Konfigurieren des Clients, Erstellen von Verbrauchern Abonnieren Themen -
Ziehen Sie die Nachricht und konsumieren Sie Senden Sie die Verbrauchsverschiebung Schließen Sie die Verbraucherinstanz
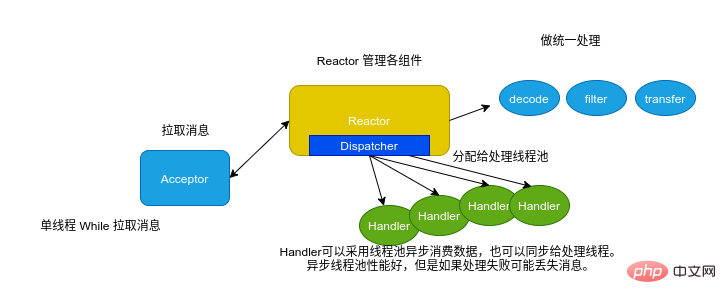
Weil Kafkas Consumer-Client threadsicher ist Thread zu gewährleisten Sicherheit und Verbesserung der Verbrauchsleistung. Auf der Verbraucherseite kann ein Thread-Modell ähnlich dem Reactor verwendet werden, um Daten zu verbrauchen.
Kafka-Verbraucherparameter
bootstrap.servers: Adresse des Verbindungsbrokers, host:portFormat.host:port格式。group.id:消费者隶属的消费组。 key.deserializer:与生产者的 key.serializer对应,key 的反序列化方式。value.deserializer:与生产者的 value.serializer对应,value 的反序列化方式。session.timeout.ms:coordinator 检测失败的时间。默认 10s 该参数是 Consumer Group 主动检测 (组内成员 comsummer) 崩溃的时间间隔,类似于心跳过期时间。 auto.offset.reset:该属性指定了消费者在读取一个没有偏移量后者偏移量无效(消费者长时间失效当前的偏移量已经过时并且被删除了)的分区的情况下,应该作何处理,默认值是 latest,也就是从最新记录读取数据(消费者启动之后生成的记录),另一个值是 earliest,意思是在偏移量无效的情况下,消费者从起始位置开始读取数据。 enable.auto.commit:否自动提交位移,如果为 false,则需要在程序中手动提交位移。对于精确到一次的语义,最好手动提交位移fetch.max.bytes:单次拉取数据的最大字节数量 max.poll.records:单次 poll 调用返回的最大消息数,如果处理逻辑很轻量,可以适当提高该值。但是 max.poll.records- group.id: Die Verbrauchergruppe, zu der der Verbraucher gehört.
🎜🎜🎜key.deserializer: key.serializerentspricht der Deserialisierungsmethode von key. 🎜🎜🎜🎜value.deserializer:value.serializerentspricht der Deserialisierungsmethode von value. 🎜🎜🎜🎜session.timeout.ms: Der Zeitpunkt, zu dem die Koordinatorerkennung fehlgeschlagen ist. Der Standardwert ist 10 Sekunden. Dieser Parameter ist das Zeitintervall, in dem die Verbrauchergruppe einen Absturz (Comsummer, ein Mitglied der Gruppe) aktiv erkennt, ähnlich der Heartbeat-Ablaufzeit. 🎜🎜🎜🎜auto.offset.reset: Dieses Attribut gibt an, dass der Verbraucher eine Partition ohne Offset liest und der Offset ungültig ist (der aktuelle Offset des Verbrauchers ist seit langer Zeit abgelaufen und wurde abgelaufen und gelöscht). Was ist in diesem Fall zu tun? Der Standardwert ist „Latest“, was bedeutet, dass Daten aus dem neuesten Datensatz gelesen werden (der Datensatz, der nach dem Start des Verbrauchers generiert wird). Beginnen Sie mit dem Lesen der Daten von der Startposition aus. 🎜🎜🎜🎜enable.auto.commit: Keine automatische Festschreibung der Verschiebung, wennfalse, Sie müssen die Verschiebung manuell im Programm eingeben. Für eine genau einmalige Semantik ist es besser, die Verschiebung manuell zu übermitteln. 🎜🎜🎜🎜fetch.max.bytes: Die maximale Anzahl von Datenbytes, die in einem einzigen Mal abgerufen werden. 🎜🎜🎜🎜max.poll.records: Die maximale zurückgegebene Nachricht durch einen einzelnen Poll-Aufruf. Wenn die Verarbeitungslogik sehr leichtgewichtig ist, können Sie diesen Wert entsprechend erhöhen. AberKafka RebalanceRebalance ist im Wesentlichen ein Protokoll, das festlegt, wie alle Verbraucher einer Verbrauchergruppe eine Vereinbarung zur Zuweisung jeder Partition des Abonnementthemas treffen können. Beispielsweise gibt es in einer bestimmten Gruppe 20 Verbraucher und sie abonniert ein Thema mit 100 Partitionen. Unter normalen Umständen weist Kafka jedem Verbraucher durchschnittlich 5 Partitionen zu. Dieser Zuordnungsprozess wird als Rebalancing bezeichnet.
Wann wieder ins Gleichgewicht kommen?
Auch diese Frage wird oft gestellt. Es gibt drei Auslösebedingungen für die Neuausrichtung:
Gruppenmitglieder ändern sich (neuer Verbraucher tritt der Gruppe bei, bestehender Verbraucher verlässt die Gruppe freiwillig oder bestehender Verbraucher stürzt ab – der Unterschied zwischen beiden wird später besprochen) Abonnieren das Thema Die Anzahl der Partitionen hat sich geändert Die Anzahl der Partitionen, die das Thema abonniert haben, hat sich geändert
Wie ordne ich Partitionen innerhalb der Gruppe zu?
Kafka bietet standardmäßig zwei Zuordnungsstrategien: Range und Round-Robin. Natürlich verwendet Kafka eine steckbare Allokationsstrategie, und Sie können Ihren eigenen Allokator erstellen, um verschiedene Allokationsstrategien zu implementieren.
Antwortschlüsselwörter
Was sind die Befehlszeilentools für Kafka? Welche haben Sie verwendet? /binVerzeichnis, Kafka-Cluster verwalten, Thema verwalten, Kafka produzieren und konsumierenDer Ausführungsprozess von Kafka Producer? Abfangjäger, Serialisierer, Partitionierer und Akkumulatoren Was sind die häufigsten Konfigurationen von Kafka Producer? Broker-Konfiguration, Bestätigungskonfiguration, Netzwerk- und Sendeparameter, Komprimierungsparameter, Bestätigungsparameter Wie halte ich Kafka-Nachrichten in Ordnung? Kafka selbst ist auf Themenebene ungeordnet und wird nur auf der Partition geordnet. Um die Verarbeitungsreihenfolge sicherzustellen, können Sie den Partitionierer anpassen und die Daten, die sequentiell verarbeitet werden müssen, an dieselbe Partition senden Stellen Sie sicher, dass die Daten reibungslos gesendet werden. Bestätigungsmechanismus, Wiederholungsmechanismus Wie kann die Leistung des Produzenten verbessert werden? Batch, asynchron, Komprimierung Wenn die Anzahl der Verbraucher in derselben Gruppe größer ist als die Anzahl der Teile, wie geht Kafka damit um? Der redundante Teil befindet sich in einem nutzlosen Zustand und verbraucht keine Daten. Ist Kafka Consumer Thread-sicher? Unsicherer Single-Thread-Verbrauch, Multi-Thread-Verarbeitung Erzählen Sie mir etwas über das Thread-Modell, wenn Sie Kafka Consumer zum Konsumieren von Nachrichten verwenden. Trennung von Ziehen und Verarbeiten Gemeinsame Konfigurationen von Kafka Consumer? Broker, Netzwerk- und Pull-Parameter, Heartbeat-Parameter Wann wird der Verbraucher aus dem Cluster geworfen? Absturz, Netzwerkanomalie, lange Verarbeitungszeit, Zeitüberschreitung bei der Übermittlungsverschiebung Wie reagiert Kafka, wenn ein Verbraucher beitritt oder austritt? Rebalance durchführen Was ist Rebalance und wann findet Rebalance statt? Themenwechsel, Verbraucherwechsel - Hohe Verfügbarkeit und Leistung
Fragen
Wie stellt Kafka eine hohe Verfügbarkeit sicher?
Kafkas Liefersemantik? Was macht Replic? Was ist los, AR, ISR? Was sind Leader und Flower? Wofür stehen HW, LEO, LSO, LW usw. bei Kafka? Welche Verarbeitung hat Kafka vorgenommen, um eine überlegene Leistung sicherzustellen?
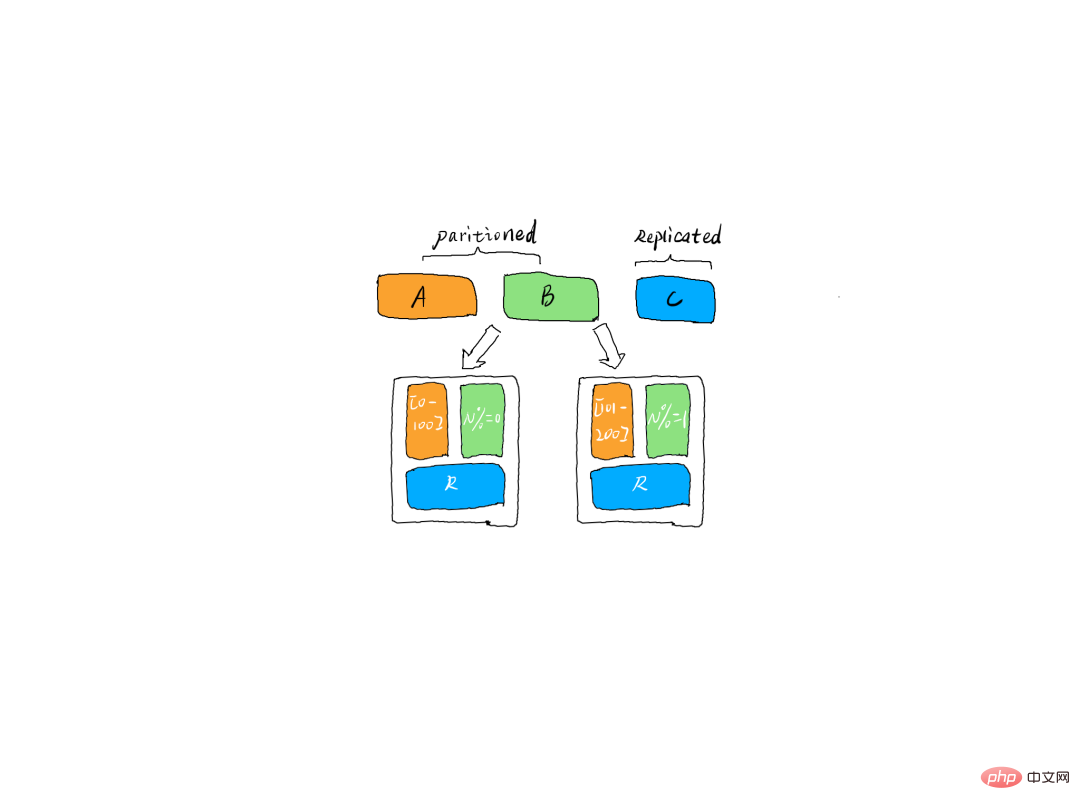
Partition und Replikat

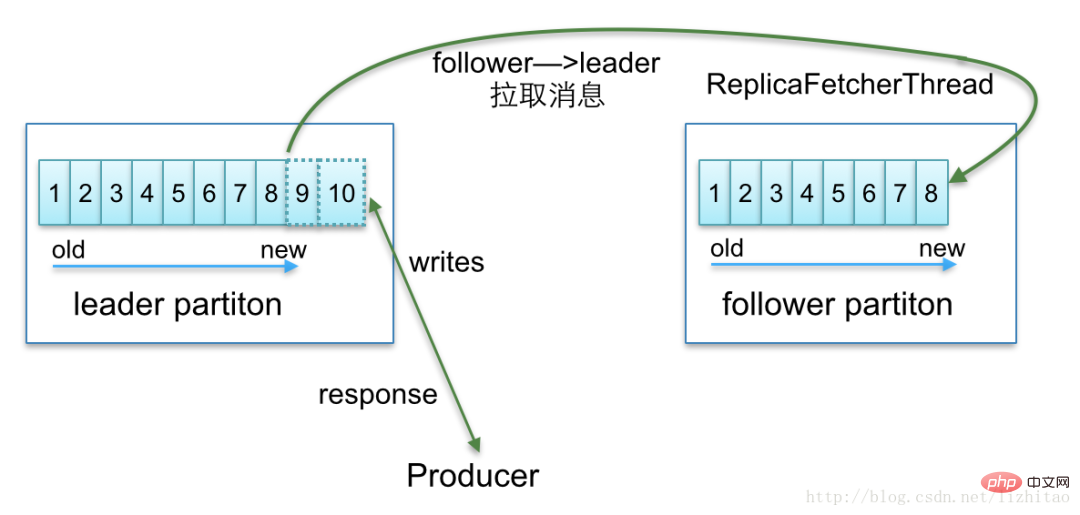
Partitionsreplik In verteilten Datensystemen werden Partitionen normalerweise verwendet, um die Verarbeitungskapazität des Systems zu verbessern und eine hohe Datenverfügbarkeit durch Replikate sicherzustellen. Unter Mehrfachpartitionierung versteht man die Möglichkeit, mehrere Kopien gleichzeitig zu verarbeiten. Dabei ist nur eine die führende Kopie und die anderen sind Folgekopien. Nur die Führungskopie kann Dienste für die Außenwelt bereitstellen. Mehrere Follower-Kopien werden in der Regel in verschiedenen Brokern von der Leader-Kopie gespeichert. Durch diesen Mechanismus wird eine hohe Verfügbarkeit erreicht. Wenn eine Maschine ausfällt, können andere Follower-Kopien schnell wieder in den Normalzustand übergehen und mit der Bereitstellung von Diensten für die Außenwelt beginnen.
Warum bietet die Follower-Kopie keinen Lesedienst?
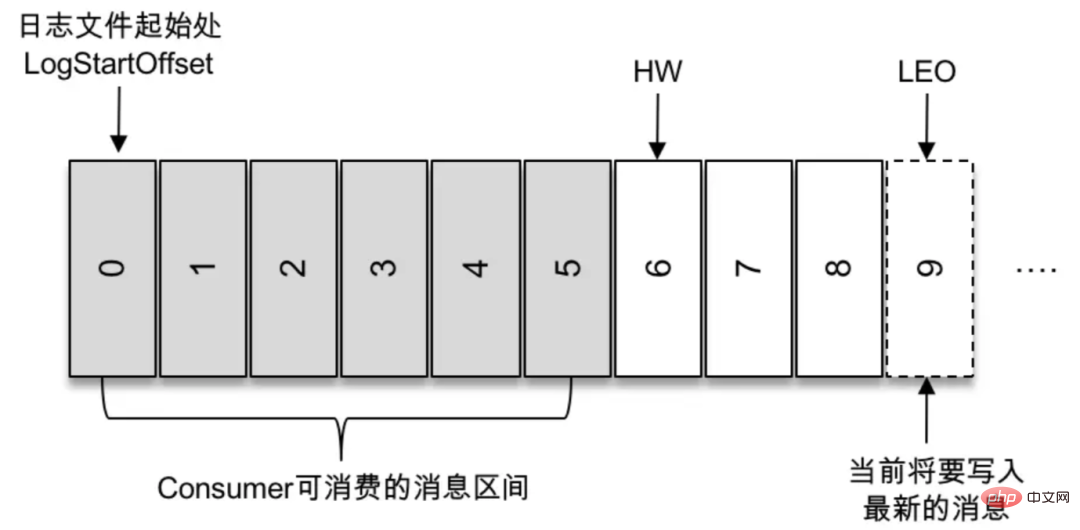
Dieses Problem ist im Wesentlichen ein Kompromiss zwischen Leistung und Konsistenz. Stellen Sie sich vor, was würde passieren, wenn die Follower-Kopie auch Dienste für die Außenwelt leisten würde? Erstens wird die Leistung definitiv verbessert. Gleichzeitig wird es jedoch zu einer Reihe von Problemen kommen. Ähnlich wie Phantom-Lesen und Dirty-Reading bei Datenbanktransaktionen. Wenn Sie beispielsweise Daten in das Kafka-Thema a schreiben, konsumiert Verbraucher b Daten aus Thema a, stellt jedoch fest, dass er diese nicht konsumieren kann, da die neueste Nachricht nicht in die Partitionskopie geschrieben wurde, die Verbraucher b liest. Zu diesem Zeitpunkt kann ein anderer Verbraucher c die neuesten Daten verbrauchen, da er die führende Kopie verbraucht. Kafka nutzt die Verwaltung von WH und Offset, um zu entscheiden, welche Daten der Verbraucher konsumieren kann und welche Daten aktuell geschrieben werden.
Wasserzeichen Nur der Leader kann externe Lesedienste bereitstellen, also wie man den Leader wählt
kafka fügt die Replikate, die mit der Leader-Replik synchronisiert sind, in den ISR-Replikatsatz ein. Natürlich ist die Vorspannkopie immer im ISR-Kopiensatz vorhanden. In einigen Sonderfällen gibt es sogar nur eine Kopie des Vorspanns in der ISR-Kopie. Wenn der Anführer versagt, erkennt Kakfa diese Situation über Zookeeper, wählt eine neue Kopie in der ISR-Kopie aus, um zum Anführer zu werden, und stellt Dienste für die Außenwelt bereit. Dabei gibt es jedoch noch ein weiteres Problem: Es ist möglich, dass nur der Anführer im ISR-Replika-Satz vorhanden ist. Wenn der Anführer-Replika-Satz stirbt, ist der ISR-Satz zu diesem Zeitpunkt leer. Wenn zu diesem Zeitpunkt der Parameter unclean.leader.election.enable auf true gesetzt ist, wählt Kafka ein Replikat aus, das zum führenden asynchronen Replikat wird, d. h. ein Replikat, das nicht im ISR-Replikatsatz enthalten ist.
Das Vorhandensein einer Kopie führt zu Problemen bei der Synchronisierung der Kopien
Kafka verwaltet eine verfügbare Replikatliste (ISR) in allen zugewiesenen Replikaten (AR). Wenn der Produzent eine Nachricht an den Broker sendet, verwaltet er die Datensynchronisierung zwischen der Blume und dem Leader basierend auf dem
ack配置来确定需要等待几个副本已经同步了消息才相应成功,Broker 内部会ReplicaManager-Dienst.sync Leistungsoptimierung
Parallelität der Partitionen Sequentielles Lesen und Schreiben auf die Festplatte -
Seitencache: Lesen und Schreiben nach Seite - Vorab lesen: Kafka wird konsumierte Nachrichten werden im Voraus in den Speicher eingelesen
Batch: Batch-Lesen und Schreiben Komprimierung: Nachrichtenkomprimierung, Speicherkomprimierung, Reduzierung des Netzwerk- und E/A-Overheads - Parallelität der Partitionen
- Einerseits, da sich verschiedene Partitionen auf verschiedenen Maschinen befinden können Sie können die Vorteile des Clusters voll ausnutzen und eine parallele Verarbeitung zwischen Maschinen erreichen. Da die Partition andererseits physisch einem Ordner entspricht, können verschiedene Partitionen auf demselben Knoten so konfiguriert werden, dass sie auf verschiedenen Festplatten platziert werden, um eine parallele Verarbeitung zwischen Festplatten zu erreichen von mehreren Festplatten.
- Sequentielles Lesen und Schreiben
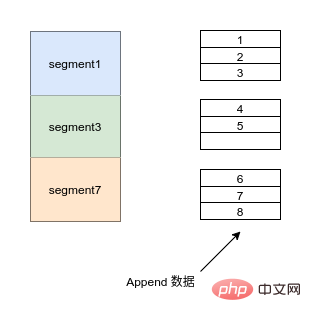
- Kafka-Dateien in jedem Partitionsverzeichnis werden gleichmäßig in Datendateien gleicher Größe aufgeteilt (die Standarddateigröße beträgt 500 MB, die manuell eingestellt werden kann). Jede Datendatei wird als Segmentdatei bezeichnet, und jedes Segment verwendet Append, um Daten anzuhängen.
-
Daten anhängen Antwortschlüsselwort
Wie stellt Kafka eine hohe Verfügbarkeit sicher?
Verwenden Sie Replikate, um eine hohe Datenverfügbarkeit, Herstellerbestätigung, Wiederholungsversuche, automatische Leader-Wahl und Verbraucher-Selbstausgleich sicherzustellen.
Kafkas Liefersemantik?
Liefersemantik hat im Allgemeinen
at least once、at most once和exactly once. Kafka implementiert die ersten beiden durch die Bestätigungskonfiguration.Was macht Replic?
Hohe Datenverfügbarkeit erreichen
Was sind AR und ISR?
AR: Zugewiesene Replikate. AR ist der Satz von Replikaten, die beim Erstellen der Partition nach der Erstellung des Themas zugewiesen werden. Die Anzahl der Replikate wird durch den Replikatfaktor bestimmt. ISR: In-Sync-Replikate. Ein besonders wichtiges Konzept bei Kafka bezieht sich auf die Menge der Replikate in AR, die mit dem Leader synchronisiert werden. Das Replikat im AR befindet sich möglicherweise nicht im ISR, aber das Leader-Replikat ist natürlich im ISR enthalten. In Bezug auf ISR ist eine weitere häufige Frage in Vorstellungsgesprächen, wie man feststellen kann, ob eine Kopie zu einem ISR gehören sollte. Die aktuelle Beurteilungsgrundlage ist: ob die Zeit, in der der LEO des Follower-Replikats hinter dem LEO des Leaders zurückbleibt, den Wert des Broker-seitigen Parameters replik.lag.time.max.ms überschreitet. Bei Überschreitung wird das Replikat aus dem ISR entfernt.
Was sind Leader und Flower?
Wofür steht HW bei Kafka?
Hohe Wassermarke. Dies ist ein wichtiges Feld, das den Umfang der Nachricht steuert, die der Verbraucher lesen kann. Ein normaler Verbraucher kann nur alle Nachrichten auf dem Leader-Replikat zwischen Log Start Offset und HW (exklusiv) „sehen“. Meldungen oberhalb des Wasserspiegels sind für Verbraucher unsichtbar.
Welche Verarbeitung hat Kafka vorgenommen, um eine überlegene Leistung sicherzustellen?
Partitionsparallelität, sequentielles Lesen und Schreiben auf die Festplatte, Seitencache-Komprimierung, Hochleistungsserialisierung (binär), sperrenfreie Offsetverwaltung für Speicherzuordnung, Java NIO-Modell
Dieser Artikel geht nicht auf die Implementierung ein Details und Quellcode-Analyse von Kafka, aber Kafka ist in der Tat ein ausgezeichnetes Open-Source-System. Es ist dringend zu empfehlen, dass interessierte Studenten ein tieferes Verständnis für dieses Open-Source-System haben Architekturdesignfunktionen, Codierungsfunktionen und Leistungsoptimierung werden eine große Hilfe sein.
Das obige ist der detaillierte Inhalt vonKafka aus Interviewperspektive abgeschlossen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!