
Heim >Technologie-Peripheriegeräte >KI >Verschiedene Arten der VCT-Anleitung, alle mit einem Bild, sodass Sie sie einfach implementieren können
Verschiedene Arten der VCT-Anleitung, alle mit einem Bild, sodass Sie sie einfach implementieren können

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-08-22 13:49:041409Durchsuche
In den letzten Jahren hat die Bilderzeugungstechnologie viele wichtige Durchbrüche erzielt. Insbesondere seit der Veröffentlichung großer Modelle wie DALLE2 und Stable Diffusion ist die Technologie zur Textgenerierung von Bildern allmählich ausgereift, und die Generierung hochwertiger Bilder bietet breite praktische Szenarien. Die detaillierte Bearbeitung vorhandener Bilder ist jedoch immer noch ein schwieriges Problem
Einerseits kann das vorhandene hochwertige Textbildmodell aufgrund der Einschränkungen der Textbeschreibung nur Text verwenden, um Bilder beschreibend und für bestimmte Zwecke zu bearbeiten Effekte, Text ist schwer zu beschreiben; andererseits verfügen Bildverfeinerungsbearbeitungsaufgaben oft nur über eine kleine Anzahl von Referenzbildern, Dadurch sind viele Lösungen, die für das Training eine große Datenmenge erfordern, klein Datenmengen, insbesondere wenn nur ein Referenzbild vorhanden ist, sind schwierig zu verarbeiten.
Kürzlich haben Forscher vom NetEase Interactive Entertainment AI Lab eine Bild-zu-Bild-Bearbeitungslösung vorgeschlagen, die auf der Einzelbildführung basiert. Bei einem einzelnen Referenzbild können die Objekte oder Stile im Referenzbild ohne Änderung in das Quellbild migriert werden die Gesamtstruktur des Quellbildes.Das Forschungspapier wurde vom ICCV 2023 angenommen und der entsprechende Code ist Open Source.
- Paper Adresse: https://arxiv.org/abs/2307.14352
- code Adresse: https://github.com/crystalneuro/visual-concept-translator
- Werfen wir zunächst einen Blick auf eine Reihe von Bildern, um die Wirkung zu spüren.
 Thesis-Renderings: Die obere linke Ecke jedes Bildsatzes ist das Quellbild, die untere linke Ecke ist das Referenzbild und die rechte Seite ist das generierte Ergebnisbild
Thesis-Renderings: Die obere linke Ecke jedes Bildsatzes ist das Quellbild, die untere linke Ecke ist das Referenzbild und die rechte Seite ist das generierte Ergebnisbild
Hauptrahmen
Der Autor des Artikels schlug ein Bildbearbeitungs-Framework vor, das auf
Inversion-Fusion – VCT (visueller Konzeptübersetzer, visueller Konzeptkonverter) basiert.Wie in der folgenden Abbildung dargestellt, umfasst das Gesamtgerüst von VCT zwei Prozesse: den Inhalt-Konzept-Inversionsprozess (Content-Konzept-Inversion) und den Inhalt-Konzept-Fusionsprozess (Inhalt-Konzept-Fusion). Der Inhaltskonzept-Inversionsprozess verwendet zwei verschiedene Inversionsalgorithmen, um die latenten Vektoren der Strukturinformationen des Originalbilds bzw. die semantischen Informationen des Referenzbilds zu lernen und darzustellen. Der Inhaltskonzept-Fusionsprozess verwendet die latenten Vektoren der Strukturinformationen und semantische Informationen Fusion, um das Endergebnis zu generieren.
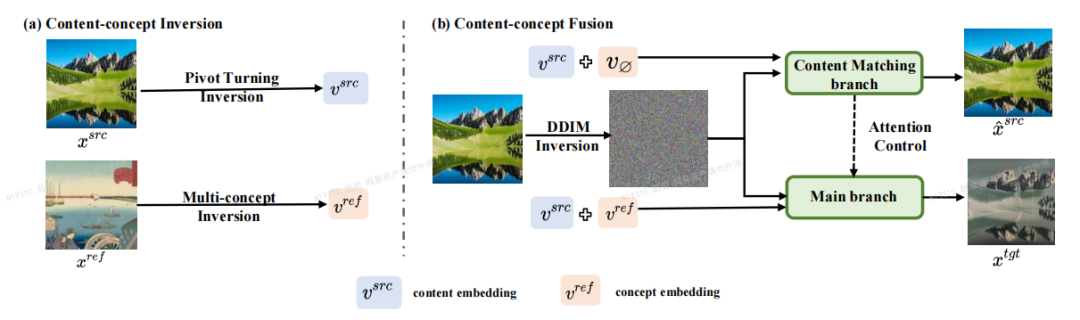 Der Inhalt, der neu geschrieben werden muss, ist: das Hauptgerüst des Papiers
Der Inhalt, der neu geschrieben werden muss, ist: das Hauptgerüst des Papiers
Es ist erwähnenswert, dass im Bereich der Generative Adversarial Networks (GAN) in den letzten Jahren die Inversionsmethode verwendet wurde weit verbreitet und in vielen Bereichen eingesetzt. Bei Bilderzeugungsaufgaben wurden bemerkenswerte Ergebnisse erzielt [1]. Wenn GAN Inhalte umschreibt, muss der Originalsatz nicht in den verborgenen Raum des trainierten GAN-Generators umgewandelt werden, und der Zweck der Bearbeitung kann durch die Steuerung erreicht werden versteckter Raum. Dieses Inversionsschema kann die generative Kraft vorab trainierter generativer Modelle voll ausnutzen. In dieser Studie wird der Inhalt tatsächlich mit GAN neu geschrieben, und der Originalsatz muss nicht a priori auf Bildbearbeitungsaufgaben angewendet werden, die auf dem Diffusionsmodell basieren.
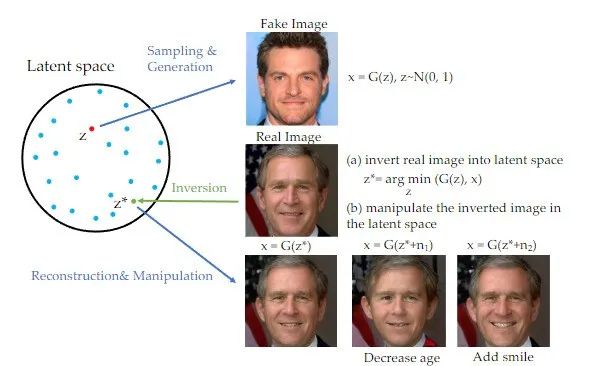 Beim Umschreiben des Inhalts muss der Originaltext ins Chinesische umgeschrieben werden und der Originalsatz muss nicht erscheinen
Beim Umschreiben des Inhalts muss der Originaltext ins Chinesische umgeschrieben werden und der Originalsatz muss nicht erscheinen
Einführung in die Methode
Basierend auf der Idee der Umkehrung, VCT hat einen Diffusionsprozess mit zwei Zweigen entworfen, der einen Zweig B* für die Inhaltsrekonstruktion und einen Hauptzweig B für die Bearbeitung umfasst. Sie beginnen mit demselben Rauschen xT, das von DDIM Inversion
【2】 erhalten wird, einem Algorithmus, der Diffusionsmodelle verwendet, um Rauschen aus Bildern für die Inhaltsrekonstruktion bzw. Inhaltsbearbeitung zu berechnen. Das in diesem Artikel verwendete Vortrainingsmodell ist Latent Diffusion Models (kurz LDM). Der Diffusionsprozess findet im latenten Vektorraum z-Raum statt. Der Doppelzweigprozess kann wie folgt ausgedrückt werden:
Doppelzweig-Diffusionsprozess
Der Inhaltsrekonstruktionszweig B* lernt T-Inhaltsmerkmalsvektoren 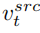 , der verwendet wird, um die Strukturinformationen des Originalbilds wiederherzustellen, und durch das Soft-Attention-Control-Schema die Struktur der Informationen wird an den Editor des Hauptzweigs B übergeben. Das Soft-Attention-Control-Schema basiert auf der Arbeit von prompt2prompt [3]:
, der verwendet wird, um die Strukturinformationen des Originalbilds wiederherzustellen, und durch das Soft-Attention-Control-Schema die Struktur der Informationen wird an den Editor des Hauptzweigs B übergeben. Das Soft-Attention-Control-Schema basiert auf der Arbeit von prompt2prompt [3]:
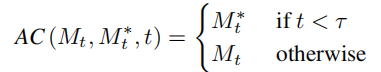
Das heißt, wenn die Anzahl der laufenden Schritte des Diffusionsmodells innerhalb eines bestimmten Bereichs liegt, wird die Aufmerksamkeitsmerkmalskarte des Der Bearbeitungshauptzweig wird durch den Inhaltsrekonstruktionszweig Feature Map ersetzt, um eine strukturelle Kontrolle über das generierte Bild zu erreichen. Der Bearbeitungshauptzweig B kombiniert den aus dem Originalbild gelernten Inhaltsmerkmalsvektor 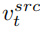 und den aus dem Referenzbild gelernten Konzeptmerkmalsvektor
und den aus dem Referenzbild gelernten Konzeptmerkmalsvektor 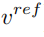 , um das bearbeitete Bild zu generieren.
, um das bearbeitete Bild zu generieren.
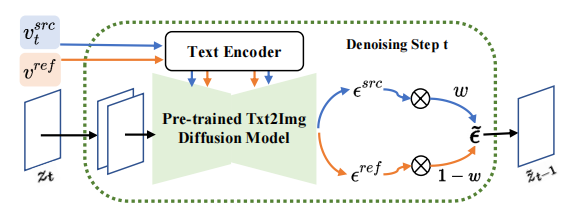
Rauschraumfusion (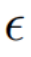 Raum)
Raum)
Bei jedem Schritt des Diffusionsmodells erfolgt die Fusion von Merkmalsvektoren im Rauschraumraum, bei dem es sich um die Gewichtung des nach dem vorhergesagten Rauschens handelt Merkmalsvektoren werden in das Diffusionsmodell eingegeben. Die Merkmalsmischung des Inhaltsrekonstruktionszweigs erfolgt auf dem Inhaltsmerkmalsvektor 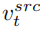 und dem leeren Textvektor, im Einklang mit der Form der klassifikatorfreien Diffusionsführung [4]:
und dem leeren Textvektor, im Einklang mit der Form der klassifikatorfreien Diffusionsführung [4]:
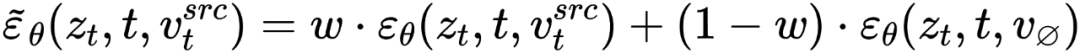
Bearbeitungsmischung Hauptzweig Es ist eine Mischung aus Inhaltsmerkmalsvektor 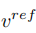 und Konzeptmerkmalsvektor
und Konzeptmerkmalsvektor 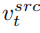 , also
, also
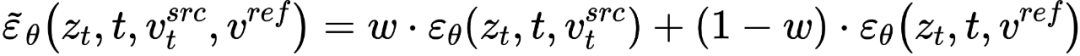
An diesem Punkt liegt der Schlüssel zur Forschung darin, wie man den Merkmalsvektor der Strukturinformationen erhält ein einzelnes Quellbild 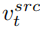 und aus einem einzelnen Quellbild ein Referenzbild, um den Merkmalsvektor der Konzeptinformationen zu erhalten
und aus einem einzelnen Quellbild ein Referenzbild, um den Merkmalsvektor der Konzeptinformationen zu erhalten 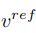 . Dieser Artikel erreicht diesen Zweck durch zwei verschiedene Inversionsschemata.
. Dieser Artikel erreicht diesen Zweck durch zwei verschiedene Inversionsschemata.
Um das Quellbild wiederherzustellen, bezieht sich der Artikel auf das NULL-Text-Optimierungsschema [5] und lernt, die Merkmalsvektoren der T-Stufen so anzupassen, dass sie mit dem Quellbild übereinstimmen und passen. Aber im Gegensatz zu NULL-Text, der den leeren Textvektor so optimiert, dass er in den DDIM-Pfad passt, passt dieser Artikel den geschätzten sauberen Merkmalsvektor direkt an, indem er den Quellbild-Merkmalsvektor optimiert. Die Anpassungsformel lautet:
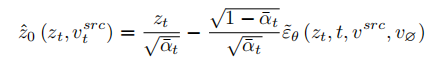
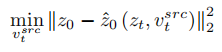
Anders als beim Lernen von Strukturinformationen müssen die Konzeptinformationen im Referenzbild durch einen einzelnen hochverallgemeinerten Merkmalsvektor dargestellt werden. Die T-Stufen des Diffusionsmodells teilen sich einen Konzeptmerkmalsvektor 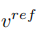 . Der Artikel optimiert die bestehenden Inversionsschemata Textual Inversion [6] und DreamArtist [7]. Es verwendet einen Multikonzept-Merkmalsvektor, um den Inhalt des Referenzbildes darzustellen. Die Verlustfunktion umfasst einen Rauschschätzungsterm des Diffusionsmodells und einen geschätzten Rekonstruktionsverlustterm im latenten Vektorraum:
. Der Artikel optimiert die bestehenden Inversionsschemata Textual Inversion [6] und DreamArtist [7]. Es verwendet einen Multikonzept-Merkmalsvektor, um den Inhalt des Referenzbildes darzustellen. Die Verlustfunktion umfasst einen Rauschschätzungsterm des Diffusionsmodells und einen geschätzten Rekonstruktionsverlustterm im latenten Vektorraum:
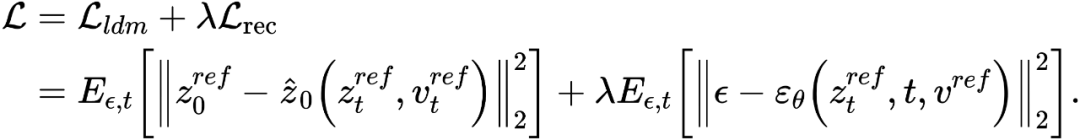
Experimentelle Ergebnisse
Der Artikel führt Experimente zu Themenersetzungs- und Stilisierungsaufgaben durch, die den Inhalt in das Thema oder den Stil des Referenzbilds ändern und gleichzeitig die Strukturinformationen des Quellbilds besser beibehalten können.

Umgeschriebener Inhalt: Artikel über experimentelle Effekte
Im Vergleich zu früheren Lösungen bietet das in diesem Artikel vorgeschlagene VCT-Framework die folgenden Vorteile:
(1) Anwendung Verallgemeinerung : Im Vergleich zu früheren Bildbearbeitungsaufgaben, die auf Bildführung basieren, erfordert VCT keine große Datenmenge für das Training und weist eine bessere Generierungsqualität und Generalisierung auf. Es basiert auf der Idee der Inversion und basiert auf hochwertigen vinzentinischen Graphenmodellen, die vorab auf Open-World-Daten trainiert wurden. In der tatsächlichen Anwendung sind nur ein Eingabebild und ein Referenzbild erforderlich, um bessere Bildbearbeitungseffekte zu erzielen .
(2) Visuelle Genauigkeit: Im Vergleich zu neueren Textbearbeitungs-Bildlösungen verwendet VCT Bilder als Referenzhilfe. Mit der Bildreferenz können Sie Bilder genauer bearbeiten als mit Textbeschreibungen. Die folgende Abbildung zeigt die Vergleichsergebnisse zwischen VCT und anderen Lösungen:

Vergleich der Wirkung der Subjektersetzungsaufgabe

Vergleich der Stilübertragungsaufgabe
(3) Es sind keine zusätzlichen Informationen erforderlich: Im Vergleich zu einigen neueren Lösungen, die das Hinzufügen zusätzlicher Steuerinformationen (z. B. Maskenkarten oder Tiefenkarten) zur Führungssteuerung erfordern, lernt VCT Strukturinformationen und semantische Informationen direkt aus dem Quellbild und dem Referenzbild Generation zeigt die folgende Abbildung einige Vergleichsergebnisse. Unter anderem ersetzt Paint-by-Example die entsprechenden Objekte durch Objekte im Referenzbild, indem es eine Maskenkarte des Quellbilds bereitstellt; Controlnet steuert die generierten Ergebnisse durch Strichzeichnungen, Tiefenkarten usw.; Bild- und Referenzbilder, wobei Strukturinformationen und Inhaltsinformationen ohne zusätzliche Einschränkungen zu Zielbildern zusammengeführt werden können.

Kontrasteffekt einer Bildbearbeitungslösung basierend auf Bildführung
NetEase Interactive Entertainment AI Lab
NetEase Interactive Entertainment AI Lab wurde 2017 gegründet und ist der NetEase Interactive Entertainment Business Group angegliedert führendes Labor für künstliche Intelligenz in der Gaming-Branche. Der Schwerpunkt des Labors liegt auf der Erforschung und Anwendung von Computer Vision, Sprach- und natürlicher Sprachverarbeitung sowie Reinforcement Learning in Spieleszenarien. Ziel ist es, das technische Niveau der beliebten Spiele und Produkte von NetEase Interactive Entertainment durch KI-Technologie zu verbessern. Derzeit wird diese Technologie in vielen beliebten Spielen verwendet, wie zum Beispiel „Fantasy Westward Journey“, „Harry Potter: Magic Awakening“, „Onmyoji“, „Westward Journey“ usw.
Das obige ist der detaillierte Inhalt vonVerschiedene Arten der VCT-Anleitung, alle mit einem Bild, sodass Sie sie einfach implementieren können. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!