
Heim >Java >JavaInterview Fragen >Interviewer: So lösen Sie Redis-Datenverzerrungen, Hotspots und andere Probleme
Interviewer: So lösen Sie Redis-Datenverzerrungen, Hotspots und andere Probleme
- Java后端技术全栈nach vorne
- 2023-08-15 16:43:081706Durchsuche
Redis hat als Mainstream-Technologie viele Anwendungsszenarien. In vielen Interviews mit großen, mittleren und kleinen Fabriken wurde es als wichtiger Inspektionsinhalt aufgeführt Ich habe die folgenden Fragen gestellt und bin gekommen, um Tom zu konsultieren : Ich habe einige Fragen bei der Überprüfung von Redis. Schauen Sie sich bitte Folgendes an:
Wenn der Redis-Cluster einen Datenversatz und eine ungleichmäßige Datenverteilung aufweist, wie kann das gelöst werden?Erstellen Sie bei der Verarbeitung von HotKey mehrere Kopien des Schlüssels, z. B. k-1, k-2 ..., Wie kann man diese Kopien gleichmäßig schreiben lassen? Wie gleichmäßig zugreifen?
redis verwendet einen Hash-Slot, um den Cluster zu verwalten. Ähnlich wie beim konsistenten Hashing kann eine vollständige Migration vermieden werden. Warum nicht einfach konsistentes Hashing verwenden?
Antwort:
Natürlich treten bei einer großen Datenmenge verschiedene Probleme auf, wie zum Beispiel: Datenversatz, Daten-Hotspots usw.Als Leistungsbeschleuniger spielt der verteilte Cache eine sehr wichtige Rolle bei der Systemoptimierung. Obwohl es eine Netzwerkübertragung hinzufügt und weniger als 1 Millisekunde dauert, bietet es im Vergleich zum lokalen Cache den Vorteil einer zentralen Verwaltung und unterstützt eine sehr große Speicherkapazität.
Im Bereich des verteilten Caches ist Redis derzeit weit verbreitet. Dieses Framework ist eine reine Speicherspeicherung, Single-Thread-Ausführung von Befehlen, umfangreiche zugrunde liegende Datenstrukturen und Unterstützung für die Datenspeicherung und Suche in mehreren Dimensionen.
Was ist Datenversatz?
Die Hardwarekonfiguration einer einzelnen Maschine hat eine Obergrenze. Im Allgemeinen verwenden wir eine verteilte Architektur, um einen Cluster aus mehreren Maschinen zu bilden. Der Client leitet Lese- und Schreibanfragen über eine bestimmte Routing-Strategie an bestimmte Instanzen weiter.
Aufgrund der Besonderheiten von Geschäftsdaten können die Daten auf verschiedenen Instanzen gemäß den angegebenen Sharding-Regeln ungleichmäßig verteilt sein. Eine große Datenmenge wird zur Berechnung auf einen oder mehrere Maschinenknoten konzentriert, was zu einer hohen Belastung führt Diese Knoten sind untätig und warten, was zu einer geringen Gesamteffizienz führt.
Was sind die Gründe für Datenverzerrungen?
1. Es gibt einen großen Schlüssel
Zum Beispiel nimmt das Speichern einer oder mehrerer großer Schlüsseldaten vom Typ String viel Speicher in Anspruch.
Bruder Tom hat dieses Problem bereits untersucht. Um Ärger während der Entwicklung zu vermeiden, hat ein Kollege das JSON-Format verwendet, um mehrere Geschäftsdaten zu einem Wert zusammenzuführen und nur einen Schlüsselwert zuzuordnen Paar erreichte Hunderte M.
Das häufige Lesen und Schreiben großer Schlüssel verbraucht große Speicherressourcen und setzt die Netzwerkübertragung stark unter Druck, was wiederum zu einer Verlangsamung der Anforderungsantwort führt, einen Lawineneffekt auslöst und schließlich verschiedene System-Timeout-Alarme auslöst.
Lösung:
Die Methode ist sehr einfach, verwenden Sie <code style='font-family: SFMono-Regular, Consolas, "Liberation Mono", Menlo, Courier, monospace;background-color: rgba(0, 0, 0, 0.06);border-width: 1px;border-style: solid;border-color: rgba(0, 0, 0, 0.08);border-radius: 2px;padding-right: 2px;padding-left: 2px;'><span style="font-size: 16px;">化整为零</span>的策略,将一个bigKey拆分为多个小key,独立维护,成本会降低很多。当然这个拆也讲究些原则,既要考虑业务场景也要考虑访问场景,将关联紧密的放到一起。
比如:有个RPC接口内部对 Redis 有依赖,之前访问一次就可以拿到全部数据,拆分将要控制单值的大小,也要控制访问的次数,毕竟调用次数增多了,会拉大整体的接口响应时间。
浙江的政府机构都在提倡优化流程,最多跑一次,都是一个道理。

2、HashTag 使用不当
Redis 采用单线程执行命令,从而保证了原子性。当采用集群部署后,为了解决mset、lua 脚本等对多key 批量操作,为了保证不同的 key 能路由到同一个 Redis 实例上,引入了 HashTag 机制。
用法也很简单,使用<span style="font-size: 16px;">{}</span>in Teile zerlegenDie Strategie besteht darin, einen großen Schlüssel in mehrere kleine Schlüssel aufzuteilen und diese unabhängig voneinander zu verwalten, was die Kosten erheblich senkt. Natürlich sind bei dieser Demontage auch einige Prinzipien zu beachten. Es ist notwendig, sowohl Geschäftsszenarien als auch Zugriffsszenarien zu berücksichtigen und diese eng zusammenzuführen.
Zum Beispiel gibt es eine RPC-Schnittstelle, die eine interne Abhängigkeit von Redis aufweist. Schließlich konnten alle Daten durch einmaliges Aufteilen gesteuert werden , führt die Erhöhung der Anzahl der Anrufe zu einem Problem. Große Gesamtantwortzeit der Schnittstelle.
Regierungsbehörden in Zhejiang plädieren dafür, den Prozess zu optimieren, und es gilt nach dem gleichen Prinzip, ihn höchstens einmal durchzuführen.
2. Unsachgemäße Verwendung von HashTag
🎜🎜🎜🎜Redis verwendet einen einzelnen Thread zum Ausführen von Befehlen und stellt so sicher Atomizität. Wenn die Clusterbereitstellung übernommen wird, wird HashTag 🎜 Mechanismus. 🎜🎜🎜🎜Die Verwendung ist ebenfalls sehr einfach, verwenden Sie 🎜 🎜 {}🎜🎜Klammern, geben Sie den Schlüssel an, um nur den Hash der Zeichenfolge innerhalb der geschweiften Klammern zu berechnen, wodurch Schlüssel-Wert-Paare verschiedener Schlüssel in denselben Hash-Slot eingefügt werden. 🎜🎜🎜🎜🎜Zum Beispiel: 🎜🎜🎜🎜192.168.0.1:6380> CLUSTER KEYSLOT testtag
(integer) 764
192.168.0.1:6380> CLUSTER KEYSLOT {testtag}
(integer) 764
192.168.0.1:6380> CLUSTER KEYSLOT mykey1{testtag}
(integer) 764
192.168.0.1:6380> CLUSTER KEYSLOT mykey2{testtag}
(integer) 764🎜🎜🎜Überprüfen Sie den Geschäftscode, um zu sehen, ob HashTag eingeführt wurde und zu viele Schlüssel an eine Instanz weitergeleitet werden. Überlegen Sie, wie Sie die Aufteilung basierend auf bestimmten Szenarien durchführen können. 🎜🎜🎜🎜Genau wie bei RocketMQ können unsere Geschäftsanforderungen in vielen Fällen erfüllt werden, solange die Partitionen in Ordnung gehalten werden. In der Praxis müssen wir diesen Gleichgewichtspunkt finden, anstatt Probleme zu lösen, um sie zu lösen. 🎜🎜3. Ungleichmäßige Verteilung der Slots
Wenn die Redis-Cluster-Bereitstellungsmethode übernommen wird, ist die Datenbank im Cluster in 16384 Slots (Slots) unterteilt, und jeder Schlüssel in der Datenbank gehört zu diesen 16384 Slots Jeder Knoten im Cluster kann 0 oder maximal 16384 Slots verarbeiten.
Sie können einen größeren Steckplatz manuell auf einen leicht inaktiven Computer migrieren, um die Einheitlichkeit von Speicherung und Zugriff sicherzustellen.
Was sind Cache-Hotspots?
Cache-Hotspot bedeutet, dass die meisten oder sogar alle Geschäftsanfragen auf dieselben zwischengespeicherten Daten treffen, was den Cache-Server enorm belastet und sogar die Auslastungsgrenze einer einzelnen Maschine überschreitet, was zum Ausfall des Servers führt.
Lösung:
1. Erstellen Sie mehrere Kopien
Wir können die fortlaufende Nummer hinter dem Schlüssel buchstabieren, z. . . Mehrere Kopien von Schlüssel Nr. 10. Diese verarbeiteten Schlüssel befinden sich auf mehreren Cache-Knoten.
Jedes Mal, wenn der Client zugreift, muss er lediglich eine Zufallszahl mit der Obergrenze der Anzahl der Shards basierend auf dem Originalschlüssel verbinden und die Anforderung an Instanzknoten weiterleiten, die nicht weitergeleitet werden können.
Hinweis: Der Cache legt im Allgemeinen die Ablaufzeit fest. Um einen zentralen Cache-Ausfall zu vermeiden, versuchen wir, nicht die gleiche Cache-Ablaufzeit zu haben. Wir können eine Zufallszahl basierend auf der Voreinstellung hinzufügen.
Die Einheitlichkeit der Datenweiterleitung wird durch den Hash-Algorithmus gewährleistet.
2. Lokaler Speicher-Cache
Hotspot-Daten im lokalen Speicher des Clients zwischenspeichern und eine Ablaufzeit festlegen. Bei jeder Leseanforderung wird zunächst geprüft, ob die Daten im lokalen Cache vorhanden sind. Wenn sie vorhanden sind, werden sie direkt zurückgegeben. Wenn sie nicht vorhanden sind, wird auf den verteilten Cache-Server zugegriffen.
Der lokale Speicher-Cache „befreit“ den Cache-Server vollständig und übt keinen Druck auf den Cache-Server aus.
Nachteile: Es ist etwas mühsam, die neuesten zwischengespeicherten Daten in Echtzeit zu erkennen, und es kann zu Dateninkonsistenzen kommen. Wir können eine relativ kurze Ablaufzeit festlegen und passive Updates verwenden. Natürlich können Sie auch einen Überwachungsmechanismus nutzen, um den lokalen Cache zeitnah zu aktualisieren, wenn dieser feststellt, dass sich die Daten geändert haben.
Redis Cluster T-Familie: SFMono-Regular, Consolas, „Liberation Mono“. ", Menlo, Courier, Monospace;Hintergrundfarbe: rgba(0, 0, 0, 0,06);Rahmenbreite: 1px;Rahmenstil: einfarbig;Rahmenfarbe: rgba(0, 0, 0, 0,08); border-radius: 2px;padding-right: 2px;padding-left: 2px;">key
通过<span style="font-size: 16px;">CRC16</span><span style="font-size: 16px;">key</span>通过<span style="font-size: 16px;">CRC16</span>校验后对<span style="font-size: 16px;">16384</span>取模来决定放置哪个槽。集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么 <span style="font-size: 16px;">node-1</span> 包含 0 到 5460 号哈希槽,<span style="font-size: 16px;">node-2</span> 包含 5461 到 10922 号哈希槽,<span style="font-size: 16px;">node-3</span>校验后对
举个例子,比如当前集群有3个节点,那么 <br> Knoten- 1 , 0, 0, 0,06);Rahmenbreite: 1px;Rahmenstil: einfarbig;Rahmenfarbe: rgba(0, 0, 0, 0,08);Rahmenradius: 2px;Padding-rechts: 2px;Padding-links 2px; ;Hintergrundfarbe: rgba(0, 0, 0, 0,06);Rahmenbreite: 1px;Rahmenstil: einfarbig;Rahmenfarbe: rgba(0, 0, 0, 0,08);Rahmenradius: 2px;Padding -right: 2px;padding-left: 2px;"><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/001/273/727/9c851820ff0859ef8c69d61f0017b563-2.png" class="lazy" alt="Interviewer: So lösen Sie Redis-Datenverzerrungen, Hotspots und andere Probleme" >node-3
包含 10922 到 16383 号哈希槽。
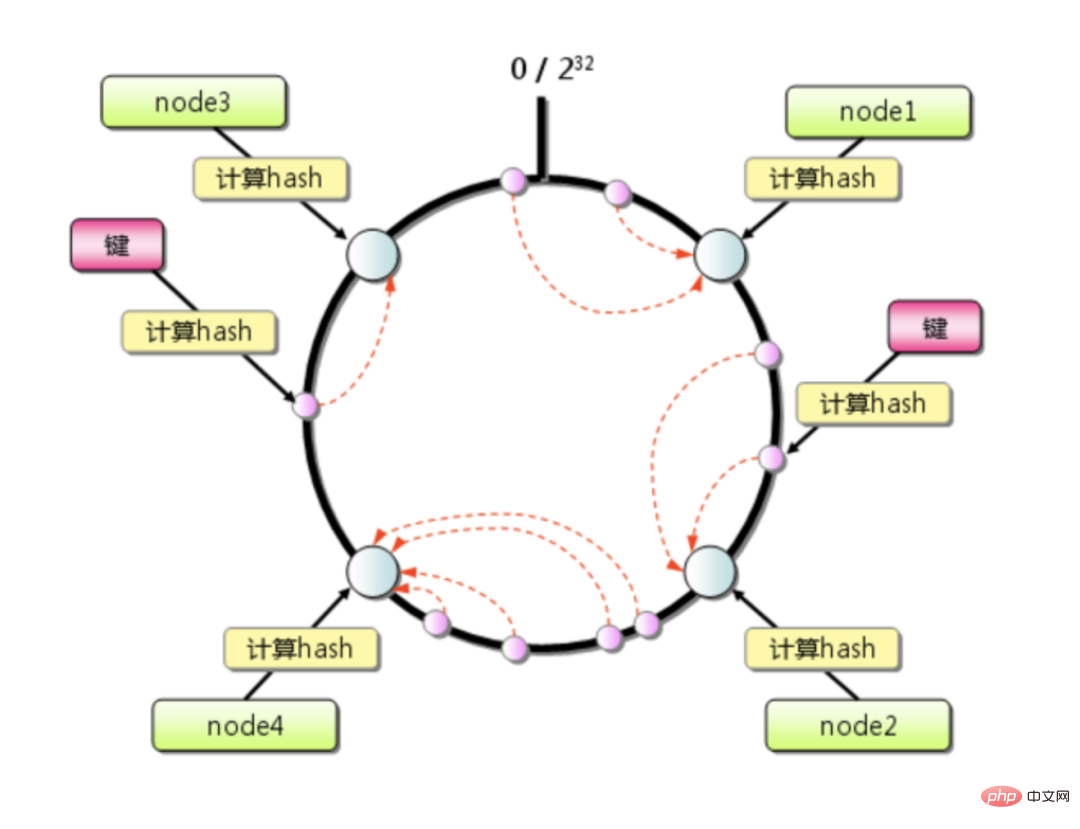
一November 1997年麻省理工学院的 Karger 等人提出了,为的就是解决分布式缓存的问题.
一致性哈希算法本质上也是一种取模算法,不同于按服务器数量取模,一致性哈希是对固定值 2^32 取模...然是在 [0, 2^32-1]这个区间中的整数, 从圆上映射的位置开始顺时针方向找到的第一个节点即为存储key的节点
Der konsistente Hash-Algorithmus lindert das durch Erweiterung oder Schrumpfung verursachte Cache-Fehlerproblem erheblich und betrifft nur das kleine Schlüsselsegment, für das dieser Knoten verantwortlich ist. Wenn im Cluster nicht viele Maschinen vorhanden sind und die Auslastung einer einzelnen Maschine normalerweise sehr hoch ist, kann der durch die Ausfallzeit eines bestimmten Knotens verursachte Druck leicht einen Lawineneffekt auslösen.
Zum Beispiel:
Der Redis-Cluster verfügt über insgesamt 4 Maschinen. Unter der Annahme, dass die Daten gleichmäßig verteilt sind, trägt jede Maschine plötzlich ein Viertel des Datenverkehrs hängt, wird die nächste Maschine im Uhrzeigersinn das zusätzliche Viertel des Verkehrs und schließlich die Hälfte des Verkehrs aushalten, was immer noch ein wenig beängstigend ist.
Aber wenn Sie <span style="font-size: 16px;">CRC16</span>CRC16 Nach der Berechnung muss in Kombination mit der Bindungsbeziehung zwischen Slots und Instanzen, unabhängig davon, ob es sich um eine Erweiterung oder eine Reduzierung handelt, nur der Schlüssel des entsprechenden Knotens reibungslos migriert werden, und die neue Slot-Mapping-Beziehung wird ohne übertragen und gespeichert Generieren einer Cache-Invalidierung, hohe Flexibilität.
Wenn die Serverknotenkonfiguration unterschiedlich ist, können wir außerdem die verschiedenen Knoten zugewiesenen Steckplatznummern anpassen und die Ladekapazität verschiedener Knoten anpassen, was sehr praktisch ist.
<code style='font-family: SFMono-Regular, Consolas, "Liberation Mono", Menlo, Courier, monospace;background-color: rgba(0, 0, 0, 0.06);border-width: 1px;border-style: solid;border-color: rgba(0, 0, 0, 0.08);border-radius: 2px;padding-right: 2px;padding-left: 2px;'><span style="font-size: 16px;">化整为零</span>的策略,将一个bigKey拆分为多个小key,独立维护,成本会降低很多。当然这个拆也讲究些原则,既要考虑业务场景也要考虑访问场景,将关联紧密的放到一起。
<span style="font-size: 16px;">{}</span>in Teile zerlegenDie Strategie besteht darin, einen großen Schlüssel in mehrere kleine Schlüssel aufzuteilen und diese unabhängig voneinander zu verwalten, was die Kosten erheblich senkt. Natürlich sind bei dieser Demontage auch einige Prinzipien zu beachten. Es ist notwendig, sowohl Geschäftsszenarien als auch Zugriffsszenarien zu berücksichtigen und diese eng zusammenzuführen. <span style="font-size: 16px;">CRC16</span><span style="font-size: 16px;">key</span>通过<span style="font-size: 16px;">CRC16</span>校验后对<span style="font-size: 16px;">16384</span>取模来决定放置哪个槽。集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么 <span style="font-size: 16px;">node-1</span> 包含 0 到 5460 号哈希槽,<span style="font-size: 16px;">node-2</span> 包含 5461 到 10922 号哈希槽,<span style="font-size: 16px;">node-3</span>校验后对 <br> Knoten- 1 , 0, 0, 0,06);Rahmenbreite: 1px;Rahmenstil: einfarbig;Rahmenfarbe: rgba(0, 0, 0, 0,08);Rahmenradius: 2px;Padding-rechts: 2px;Padding-links 2px; ;Hintergrundfarbe: rgba(0, 0, 0, 0,06);Rahmenbreite: 1px;Rahmenstil: einfarbig;Rahmenfarbe: rgba(0, 0, 0, 0,08);Rahmenradius: 2px;Padding -right: 2px;padding-left: 2px;"><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/001/273/727/9c851820ff0859ef8c69d61f0017b563-2.png" class="lazy" alt="Interviewer: So lösen Sie Redis-Datenverzerrungen, Hotspots und andere Probleme" >node-3一致性哈希算法本质上也是一种取模算法,不同于按服务器数量取模,一致性哈希是对固定值 2^32 取模...然是在 [0, 2^32-1]这个区间中的整数,
<span style="font-size: 16px;">CRC16</span>CRC16 Nach der Berechnung muss in Kombination mit der Bindungsbeziehung zwischen Slots und Instanzen, unabhängig davon, ob es sich um eine Erweiterung oder eine Reduzierung handelt, nur der Schlüssel des entsprechenden Knotens reibungslos migriert werden, und die neue Slot-Mapping-Beziehung wird ohne übertragen und gespeichert Generieren einer Cache-Invalidierung, hohe Flexibilität. Das obige ist der detaillierte Inhalt vonInterviewer: So lösen Sie Redis-Datenverzerrungen, Hotspots und andere Probleme. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!