
Heim >häufiges Problem >Vier verteilte Strombegrenzungsalgorithmen und Codeimplementierung
Vier verteilte Strombegrenzungsalgorithmen und Codeimplementierung
- Java后端技术全栈nach vorne
- 2023-08-15 15:54:211408Durchsuche
Mit Fragen an die Stromgrenze herangehen
Warum sollten wir den Strom begrenzen?
Wie ich oben sagte, ist mehr Verkehr zwar eine gute Sache, aber wenn er überlastet ist und das System hängt, werden alle darunter leiden.

Vor verschiedenen größeren Werbemaßnahmen ist es daher notwendig, das System einem Stresstest zu unterziehen, die Spitzen-QPS des gesamten Systems zu bewerten und einige aktuelle Begrenzungseinstellungen vorzunehmen, wenn diese einen bestimmten Schwellenwert überschreiten , wird die Verarbeitung verweigert oder die Verarbeitung verzögert, um einen Systemabsturz zu vermeiden.
Was ist der Unterschied zwischen Strombegrenzung und Absicherung?
Die Verkehrsbegrenzung erfolgt, bevor der Verkehr eintrifft, und der überschüssige Verkehr wird begrenzt.
Leistungsschalter ist ein Mechanismus zur Behebung von Fehlern. Er tritt auf, nachdem Datenverkehr eintrifft. Wenn das System ausfällt oder abnormal ist, unterbricht die Sicherung automatisch die Anforderung, um zu verhindern, dass sich der Fehler weiter ausbreitet und eine Servicelawine verursacht.
Was ist der Unterschied zwischen Strombegrenzung und Spitzenbegrenzung?
Peak Shaving ist ein Glättungsprozess für den Datenverkehr, der eine sofortige Überlastung des Systems vermeidet, indem er die Verarbeitungsrate von Anfragen langsam erhöht.
Peak Cutting ist wahrscheinlich ein Reservoir, das den Durchfluss speichert und langsam fließt. Die Durchflussbegrenzung ist wahrscheinlich ein Tor, das überschüssigen Durchfluss abweist.
Allgemeiner Prozess der Strombegrenzung
Wie implementiert man also eine spezifische Strombegrenzung? Es kann in die folgenden Schritte zusammengefasst werden:
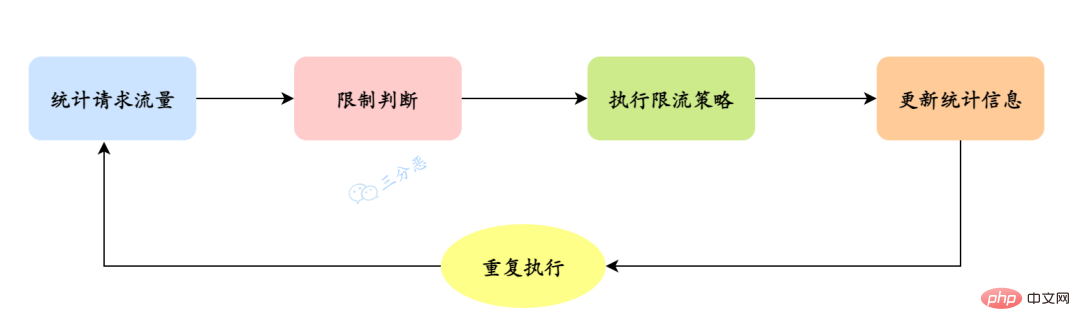
Statistischer Anfrageverkehr: Erfassen Sie die Anzahl oder Rate der Anfragen, die über Zähler, Schiebefenster usw. gezählt werden können. Bestimmen Sie, ob das Limit überschritten wird: Stellen Sie anhand der festgelegten Einschränkungsbedingungen fest, ob der aktuelle Anforderungsverkehr das Limit überschreitet. Aktuelle Begrenzungsstrategie ausführen: Wenn der Anforderungsverkehr das Limit überschreitet, implementieren Sie die aktuelle Begrenzungsstrategie, z. B. Ablehnung der Anforderung, Verzögerung der Verarbeitung, Rückgabe von Fehlerinformationen usw. Statistische Informationen aktualisieren: Aktualisieren Sie statistische Informationen basierend auf den Verarbeitungsergebnissen der Anforderung, z. B. Erhöhen des Zählerwerts, Aktualisieren der Daten des Schiebefensters usw. Wiederholen Sie die obigen Schritte: Zählen Sie kontinuierlich den Anforderungsverkehr, stellen Sie fest, ob das Limit überschritten wird, implementieren Sie die aktuelle Begrenzungsrichtlinie und aktualisieren Sie die statistischen Informationen
Es ist zu beachten, dass die spezifische Implementierung des aktuellen Begrenzungsalgorithmus erfolgt kann je nach Szenario und Bedarf variieren. Passen Sie es an und optimieren Sie es, z. B. mithilfe des Token-Bucket-Algorithmus, des Leaky-Bucket-Algorithmus usw.
Einzelmaschinen-Strombegrenzung und verteilte Strombegrenzung
Wir haben festgestellt, dass es im allgemeinen Prozess der Strombegrenzung erforderlich ist, das Anforderungsvolumen zu zählen und die Statistiken zu aktualisieren, daher müssen die Statistiken und Aktualisierungen des Anforderungsvolumens erfolgen in einem Lager aufbewahrt.
Wenn es sich nur um eine eigenständige Umgebung handelt, ist es einfach, sie direkt vor Ort zu handhaben und zu speichern.

Aber im Allgemeinen werden unsere Dienste in Clustern bereitgestellt. Wie erreicht man eine Gesamtstrombegrenzung zwischen mehreren Maschinen?
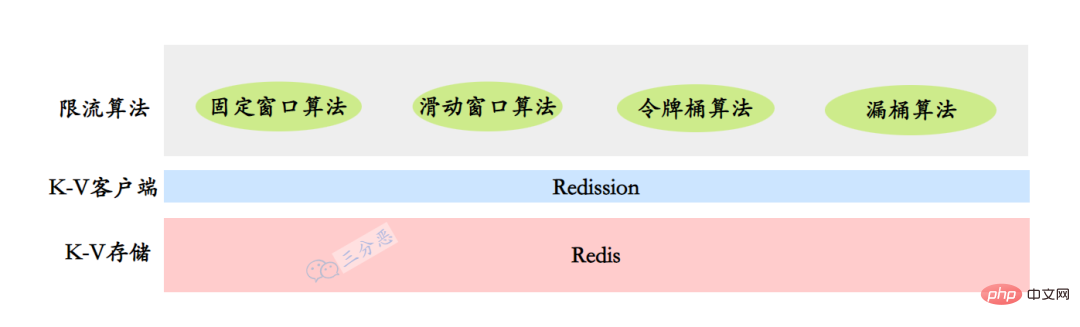
Zu diesem Zeitpunkt können wir unsere statistischen Informationen in einem verteilten K-V-Speicher wie Tair oder Redis ablegen.
Vier Strombegrenzungsalgorithmen und verteilte Implementierung
Als Nächstes beginnen wir mit der Implementierung einiger gängiger Strombegrenzungsalgorithmen. Hier verwenden wir Redis als verteilten Cache-Datenbank. Redission wird einfach für verteilte Sperren verwendet, was etwas „unerfahren“ ist. Tatsächlich ist es auch als Redis-Client sehr einfach zu verwenden.
Bevor wir beginnen, bereiten wir kurz die Umgebung vor. Wir werden nicht auf Details zur Redis-Installation und Projekterstellung eingehen.
Abhängigkeit hinzufügen
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.16.2</version>
</dependency>Verwenden Sie den Singleton-Modus, um RedissonClient zu erhalten. Es wird hier nicht als Bean registriert. Das Ausführen eines Einzeltests ist zu langsam ithm Prinzip Der Algorithmus mit festem Fenster wird in vielen Referenzmaterialien auch als Zähleralgorithmus bezeichnet. Natürlich verstehe ich persönlich, dass der Algorithmus mit festem Fenster ein Sonderfall des Algorithmus mit festem Fenster ist .
Der Festfensteralgorithmus ist ein relativ einfacher Strombegrenzungsalgorithmus. Er unterteilt die Zeit in feste Zeitfenster und legt ein Limit für die Anzahl der in jedem Fenster zulässigen Anforderungen fest. Überschreitet die Anzahl der Anfragen innerhalb eines Zeitfensters die Obergrenze, wird eine Strombegrenzung ausgelöst.
Hier Bildbeschreibung einfügen
AlgorithmusimplementierungDie Implementierung eines festen Fensters auf Basis von Redisson ist recht einfach. Innerhalb jedes Fensterzeitraums können wir die Anzahl der Anfragen durch den
public class RedissonConfig {
private static final String REDIS_ADDRESS = "redis://127.0.0.1:6379";
private static volatile RedissonClient redissonClient;
public static RedissonClient getInstance(){
if (redissonClient==null){
synchronized (RedissonConfig.class){
if (redissonClient==null){
Config config = new Config();
config.useSingleServer().setAddress(REDIS_ADDRESS);
redissonClient = Redisson.create(config);
return redissonClient;
}
}
}
return redissonClient;
}
}incrementAndGetEine zusätzliche verteilte Sperre wird hier verwendet, um das Problem der Fensterinitialisierung in gleichzeitigen Situationen zu lösen.
Lass es uns noch einmal testen
public class FixedWindowRateLimiter {
public static final String KEY = "fixedWindowRateLimiter:";
/**
* 请求限制数量
*/
private Long limit;
/**
* 窗口大小(单位:S)
*/
private Long windowSize;
public FixedWindowRateLimiter(Long limit, Long windowSize) {
this.limit = limit;
this.windowSize = windowSize;
}
/**
* 固定窗口限流
*/
public boolean triggerLimit(String path) {
RedissonClient redissonClient = RedissonConfig.getInstance();
//加分布式锁,防止并发情况下窗口初始化时间不一致问题
RLock rLock = redissonClient.getLock(KEY + "LOCK:" + path);
try {
rLock.lock(100, TimeUnit.MILLISECONDS);
String redisKey = KEY + path;
RAtomicLong counter = redissonClient.getAtomicLong(redisKey);
//计数
long count = counter.incrementAndGet();
//如果为1的话,就说明窗口刚初始化
if (count == 1) {
//直接设置过期时间,作为窗口
counter.expire(windowSize, TimeUnit.SECONDS);
}
//触发限流
if (count > limit) {
//触发限流的不记在请求数量中
counter.decrementAndGet();
return true;
}
return false;
} finally {
rLock.unlock();
}
}
}Natürlich können Sie auch eine Schnittstelle schreiben und zum Testen Stresstest-Tools wie Jmeter verwenden.
- Der Vorteil des Festfensteralgorithmus besteht darin, dass er einfach zu implementieren ist und wenig Platz beansprucht, aber er weist kritische Probleme auf, da die Fensterumschaltung sofort erfolgt, die Anforderungsverarbeitung nicht reibungslos verläuft und es zu starken Verkehrsschwankungen kommen kann im Moment des Fensterwechsels.
-
Wenn in diesem Beispiel beispielsweise um 00:02 Uhr plötzlich eine große Anzahl von Anfragen eingeht, wir den Zähler aber zu diesem Zeitpunkt zurücksetzen, können wir den plötzlichen Datenverkehr nicht begrenzen. 
Problem kritischer Werte Schiebefensteralgorithmus
Um das plötzliche Verkehrsproblem eines festen Fensters zu lindern, kann der Schiebefensteralgorithmus verwendet werden. Die TCP-Flusskontrolle in Computernetzwerken verwendet den Schiebefensteralgorithmus.
Algorithmusprinzip
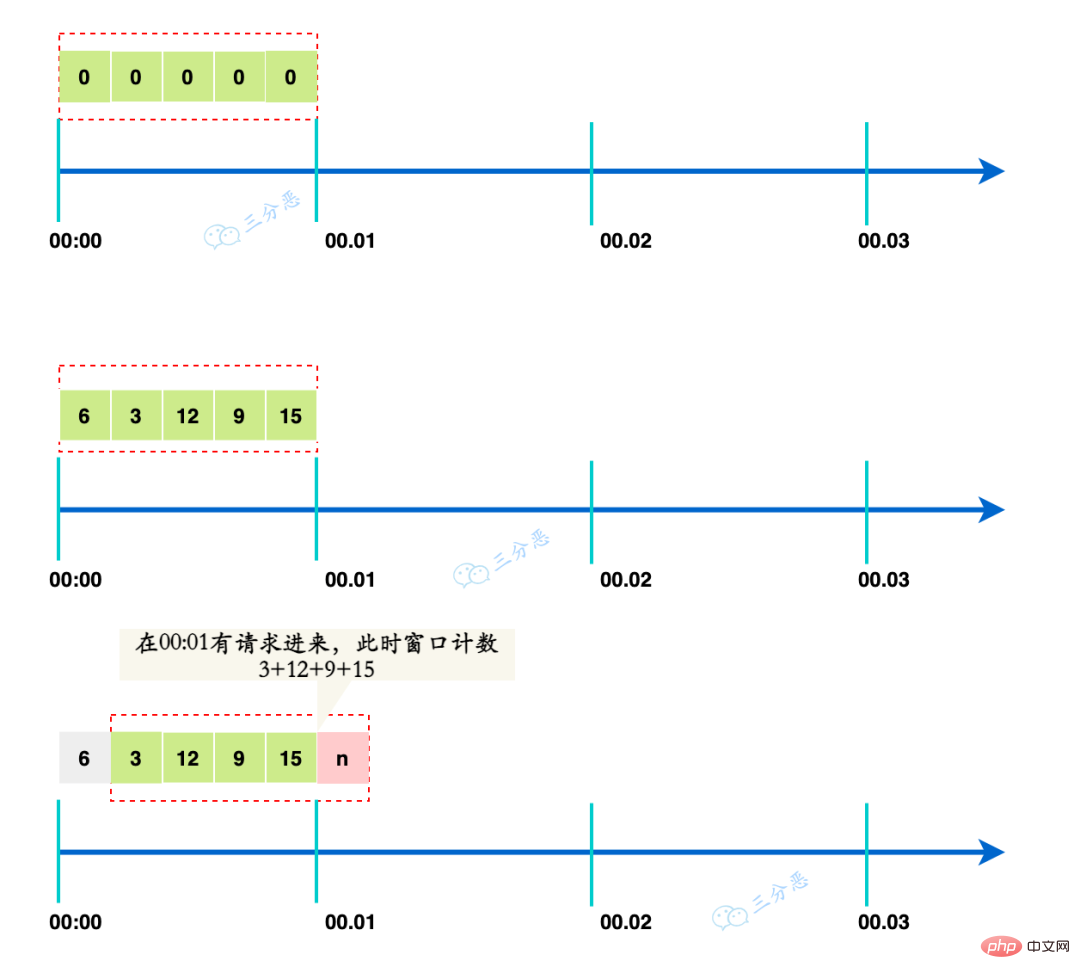
Das Prinzip des Schiebefenster-Strombegrenzungsalgorithmus besteht darin, ein großes Zeitfenster in mehrere kleine Zeitfenster zu unterteilen, und jedes kleine Fenster hat eine unabhängige Zählung.
Wenn eine Anfrage eingeht, stellen Sie fest, ob die Anzahl der Anfragen das Limit des gesamten Fensters überschreitet. Das Fenster bewegt sich jedes Mal vorwärts
滑动一个小的单元窗口。例如下面这个滑动窗口,将大时间窗口1min分成了5个小窗口,每个小窗口的时间是12s。
每个单元格有自己独立的计数器,每过12s就会向前移动一格。
假如有请求在00:01的时候过来,这时候窗口的计数就是3+12+9+15=39,也能起到限流的作用。
滑动窗口算法示意图 这就是为什么滑动窗口能解决临界问题,滑的格子越多,那么整体的滑动就会越
Zum Beispiel unterteilt das Schiebefenster unten das große Zeitfenster von 1 Minute in 5 kleine Fenster, und die Zeit jedes kleinen Fensters beträgt 12 Sekunden. Jede Zelle verfügt über einen eigenen unabhängigen Zähler, der alle 12 Sekunden um eine Zelle vorwärts geht. Wenn eine Anfrage um 00:01 Uhr eintrifft, beträgt die Fensteranzahl zu diesem Zeitpunkt 3+12+9+15=39, was auch bei der Strombegrenzung eine Rolle spielen kann.平滑🎜Schematische Darstellung des Schiebefensteralgorithmus🎜🎜🎜Deshalb Schiebefenster Kann ein kritisches Problem lösen: Je mehr Schiebegitter vorhanden sind, desto größer ist das Gesamtgleiten<img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/001/273/727/677f62b858839b392d242dedd2dafb30-7.png" class="lazy" alt="Vier verteilte Strombegrenzungsalgorithmen und Codeimplementierung" ><figcaption style="max-width:90%">zset实现滑动窗口</figcaption><ul class="list-paddingleft-1" data-tool="mdnice编辑器" style="margin-top: 8px;margin-bottom: 8px;padding-left: 25px;list-style-type: square;"><li><section style="margin-top: 5px;margin-bottom: 5px;line-height: 26px;color: rgb(1, 1, 1);">代码实现</section></li></ul><pre class="brush:php;toolbar:false;">public class SlidingWindowRateLimiter { public static final String KEY = "slidingWindowRateLimiter:"; /** * 请求次数限制 */ private Long limit; /** * 窗口大小(单位:S) */ private Long windowSize; public SlidingWindowRateLimiter(Long limit, Long windowSize) { this.limit = limit; this.windowSize = windowSize; } public boolean triggerLimit(String path) { RedissonClient redissonClient = RedissonConfig.getInstance(); //窗口计数 RScoredSortedSet<Long> counter = redissonClient.getScoredSortedSet(KEY + path); //使用分布式锁,避免并发设置初始值的时候,导致窗口计数被覆盖 RLock rLock = redissonClient.getLock(KEY + "LOCK:" + path); try { rLock.lock(200, TimeUnit.MILLISECONDS); // 当前时间戳 long currentTimestamp = System.currentTimeMillis(); // 窗口起始时间戳 long windowStartTimestamp = currentTimestamp - windowSize * 1000; // 移除窗口外的时间戳,左闭右开 counter.removeRangeByScore(0, true, windowStartTimestamp, false); // 将当前时间戳作为score,也作为member, // TODO:高并发情况下可能没法保证唯一,可以加一个唯一标识 counter.add(currentTimestamp, currentTimestamp); //使用zset的元素个数,作为请求计数 long count = counter.size(); // 判断时间戳数量是否超过限流阈值 if (count > limit) { System.out.println("[triggerLimit] path:" + path + " count:" + count + " over limit:" + limit); return true; } return false; } finally { rLock.unlock(); } } }</pre><p data-tool="mdnice编辑器" style="padding-top: 8px;padding-bottom: 8px;line-height: 26px;">这里还有一个小的可以完善的点,zset在member相同的情况下,是会覆盖的,也就是说高并发情况下,时间戳可能会重复,那么就有可能统计的请求偏少,这里可以用<code style='padding: 2px 4px;border-radius: 4px;margin-right: 2px;margin-left: 2px;background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(255, 100, 65);'>时间戳+随机数来缓解,也可以生成唯一序列来解决,比如UUID、雪花算法等等。还是来测试一下
class SlidingWindowRateLimiterTest { ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(30, 50, 10, TimeUnit.SECONDS, new LinkedBlockingDeque<>(10)); @Test @DisplayName("滑动窗口限流") void triggerLimit() throws InterruptedException { SlidingWindowRateLimiter slidingWindowRateLimiter = new SlidingWindowRateLimiter(10L, 1L); //模拟在不同时间片内的请求 for (int i = 0; i < 8; i++) { CountDownLatch countDownLatch = new CountDownLatch(20); for (int j = 0; j < 20; j++) { threadPoolExecutor.execute(() -> { boolean isLimit = slidingWindowRateLimiter.triggerLimit("/test"); System.out.println(isLimit); countDownLatch.countDown(); }); } countDownLatch.await(); //休眠10s TimeUnit.SECONDS.sleep(10L); } } }用Redis实现了滑动窗口限流,解决了固定窗口限流的边界问题,当然这里也带来了新的问题,因为我们存储了窗口期的所有请求,所以高并发的情况下,可能会比较占内存。
漏桶算法
我们可以看到,计数器类的限流,体现的是一个“戛然而止”,超过限制,立马决绝,但是有时候,我们可能只是希望请求平滑一些,追求的是“波澜不惊”,这时候就可以考虑使用其它的限流算法。
算法原理
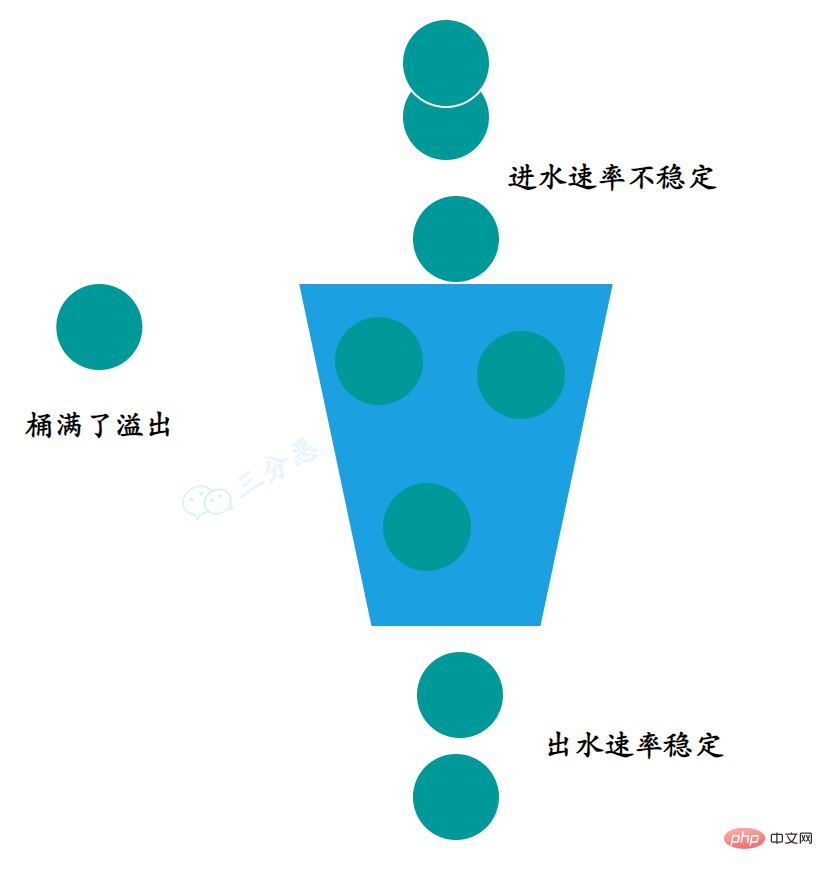
漏桶算法(Leaky Bucket),名副其实,就是请求就像水一样以任意速度注入漏桶,而桶会按照固定的速率将水漏掉。
漏桶算法 当进水速率大于出水速率的时候,漏桶会变满,此时新进入的请求将会被丢弃。
漏桶算法的两大作用是
网络流量整形(Traffic Shaping)和速度限制(Rate Limiting)。算法实现
我们接着看看具体应该怎么实现。
在滑动窗口限流算法里我们用到了
RScoredSortedSet,非常好用对不对,这里也可以用这个结构,直接使用ZREMRANGEBYSCORE命令来删除旧的请求。进水就不用多说了,请求进来,判断桶有没有满,满了就拒绝,没满就往桶里丢请求。
那么出水怎么办呢?得保证稳定速率出水,可以用一个定时任务,来定时去删除旧的请求。
代码实现
public class LeakyBucketRateLimiter { private RedissonClient redissonClient = RedissonConfig.getInstance(); private static final String KEY_PREFIX = "LeakyBucket:"; /** * 桶的大小 */ private Long bucketSize; /** * 漏水速率,单位:个/秒 */ private Long leakRate; public LeakyBucketRateLimiter(Long bucketSize, Long leakRate) { this.bucketSize = bucketSize; this.leakRate = leakRate; //这里启动一个定时任务,每s执行一次 ScheduledExecutorService executorService = Executors.newScheduledThreadPool(1); executorService.scheduleAtFixedRate(this::leakWater, 0, 1, TimeUnit.SECONDS); } /** * 漏水 */ public void leakWater() { RSet<String> pathSet=redissonClient.getSet(KEY_PREFIX+":pathSet"); //遍历所有path,删除旧请求 for(String path:pathSet){ String redisKey = KEY_PREFIX + path; RScoredSortedSet<Long> bucket = redissonClient.getScoredSortedSet(KEY_PREFIX + path); // 获取当前时间 long now = System.currentTimeMillis(); // 删除旧的请求 bucket.removeRangeByScore(0, true,now - 1000 * leakRate,true); } } /** * 限流 */ public boolean triggerLimit(String path) { //加锁,防止并发初始化问题 RLock rLock = redissonClient.getLock(KEY_PREFIX + "LOCK:" + path); try { rLock.lock(100,TimeUnit.MILLISECONDS); String redisKey = KEY_PREFIX + path; RScoredSortedSet<Long> bucket = redissonClient.getScoredSortedSet(redisKey); //这里用一个set,来存储所有path RSet<String> pathSet=redissonClient.getSet(KEY_PREFIX+":pathSet"); pathSet.add(path); // 获取当前时间 long now = System.currentTimeMillis(); // 检查桶是否已满 if (bucket.size() < bucketSize) { // 桶未满,添加一个元素到桶中 bucket.add(now,now); return false; } // 桶已满,触发限流 System.out.println("[triggerLimit] path:"+path+" bucket size:"+bucket.size()); return true; }finally { rLock.unlock(); } } }在代码实现里,我们用了
RSet来存储path,这样一来,一个定时任务,就可以搞定所有path对应的桶的出水,而不用每个桶都创建一个一个定时任务。这里我直接用
ScheduledExecutorService启动了一个定时任务,1s跑一次,当然集群环境下,每台机器都跑一个定时任务,对性能是极大的浪费,而且不好管理,我们可以用分布式定时任务,比如xxl-job去执行leakWater。最后还是大家熟悉的测试
class LeakyBucketRateLimiterTest { ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(30, 50, 10, TimeUnit.SECONDS, new LinkedBlockingDeque<>(10)); @Test @DisplayName("漏桶算法") void triggerLimit() throws InterruptedException { LeakyBucketRateLimiter leakyBucketRateLimiter = new LeakyBucketRateLimiter(10L, 1L); for (int i = 0; i < 8; i++) { CountDownLatch countDownLatch = new CountDownLatch(20); for (int j = 0; j < 20; j++) { threadPoolExecutor.execute(() -> { boolean isLimit = leakyBucketRateLimiter.triggerLimit("/test"); System.out.println(isLimit); countDownLatch.countDown(); }); } countDownLatch.await(); //休眠10s TimeUnit.SECONDS.sleep(10L); } } }漏桶算法能够有效防止网络拥塞,实现也比较简单。
但是,因为漏桶的出水速率是固定的,假如突然来了大量的请求,那么只能丢弃超量的请求,即使下游能处理更大的流量,
没法充分利用系统资源。令牌桶算法
令牌桶算法来了!
算法原理
令牌桶算法是对漏桶算法的一种改进。
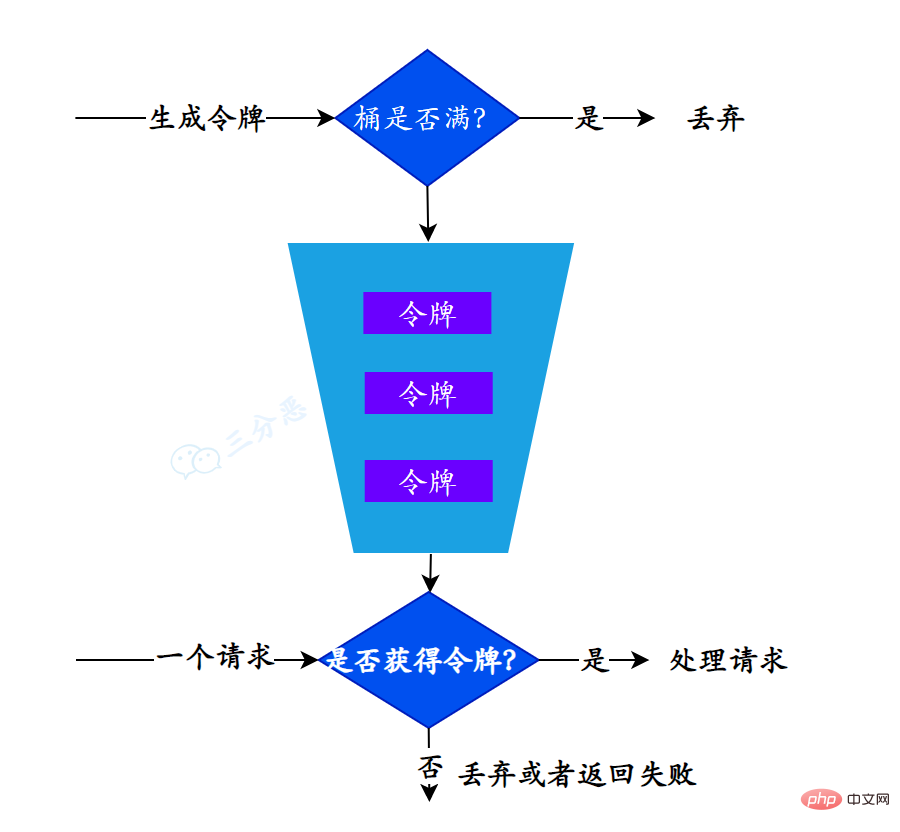
它的主要思想是:系统以一种固定的速率向桶中添加令牌,每个请求在发送前都需要从桶中取出一个令牌,只有取到令牌的请求才被通过。因此,令牌桶算法允许请求以任意速率发送,只要桶中有足够的令牌。
令牌桶算法 算法实现
我们继续看怎么实现,首先是要发放令牌,要固定速率,那我们又得开个线程,定时往桶里投令牌,然后……
——然后Redission提供了令牌桶算法的实现,舒不舒服?
拿来吧你 拿来就用!
代码实现
public class TokenBucketRateLimiter { public static final String KEY = "TokenBucketRateLimiter:"; /** * 阈值 */ private Long limit; /** * 添加令牌的速率,单位:个/秒 */ private Long tokenRate; public TokenBucketRateLimiter(Long limit, Long tokenRate) { this.limit = limit; this.tokenRate = tokenRate; } /** * 限流算法 */ public boolean triggerLimit(String path){ RedissonClient redissonClient=RedissonConfig.getInstance(); RRateLimiter rateLimiter = redissonClient.getRateLimiter(KEY+path); // 初始化,设置速率模式,速率,间隔,间隔单位 rateLimiter.trySetRate(RateType.OVERALL, limit, tokenRate, RateIntervalUnit.SECONDS); // 获取令牌 return rateLimiter.tryAcquire(); } }Redisson实现的,还是比较稳的,这里就不测试了。
关于Redission是怎么实现这个限速器的,大家可以看一下参考[3],还是Redisson家的老传统——Lua脚本,设计相当巧妙。
总结
在这篇文章里,我们对四(三)种限流算法进行了分布式实现,采用了非常好用的Redission客户端,当然我们也有不完善的地方:
并发处理采用了分布式锁,高并发情况下,对性能有一定损耗,逻辑最好还是直接采用Lua脚本实现,来提高性能 可以提供更加优雅的调用方式,比如利用aop实现注解式调用,代码设计也可以更加优雅,继承体系可以完善一下 没有实现限流的拒绝策略,比如抛异常、缓存、丢进MQ打散……限流是一种方法,最终的目的还是尽可能保证系统平稳
如果后面有机会,希望可以继续完善这个简单的Demo,达到工程级的应用。
除此之外,市面上也有很多好用的开源限流工具:
Guava RateLimiter ,基于令牌桶算法限流,当然是单机的; Sentinel ,基于滑动窗口限流,支持单机,也支持集群 网关限流,很多网关自带限流方法,比如 Spring Cloud Gateway、Nginx


Das obige ist der detaillierte Inhalt vonVier verteilte Strombegrenzungsalgorithmen und Codeimplementierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!