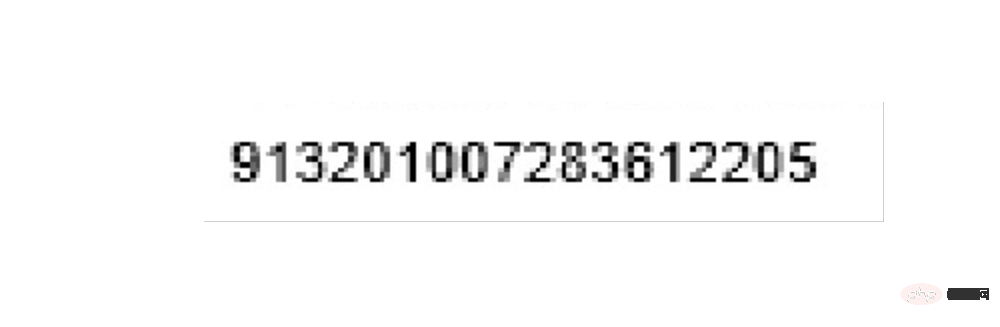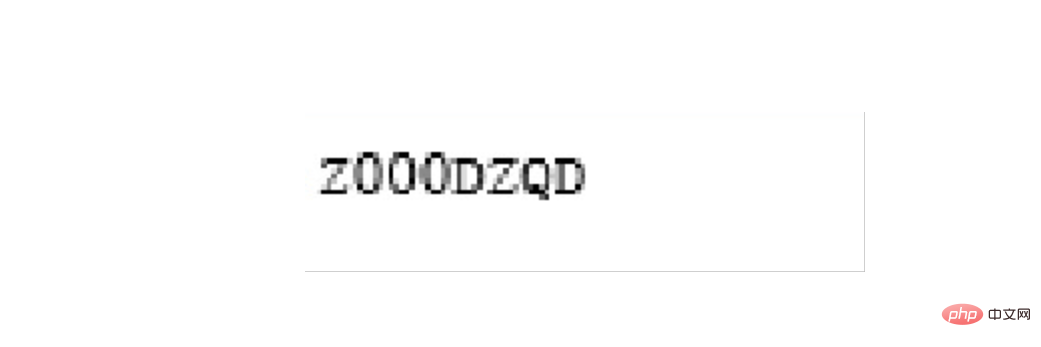In diesem Artikel wird eine PDF-basierte Python-Büroautomatisierungslösung vorgestellt, die ebenfalls eine echte Nachfrage einer Finanzdame darstellt. Werfen wir zunächst einen Blick auf die Nachfrage.
Anforderungsbeschreibung
In einem bestimmten Ordner befinden sich mehrere Rechnungen vom Typ PDF
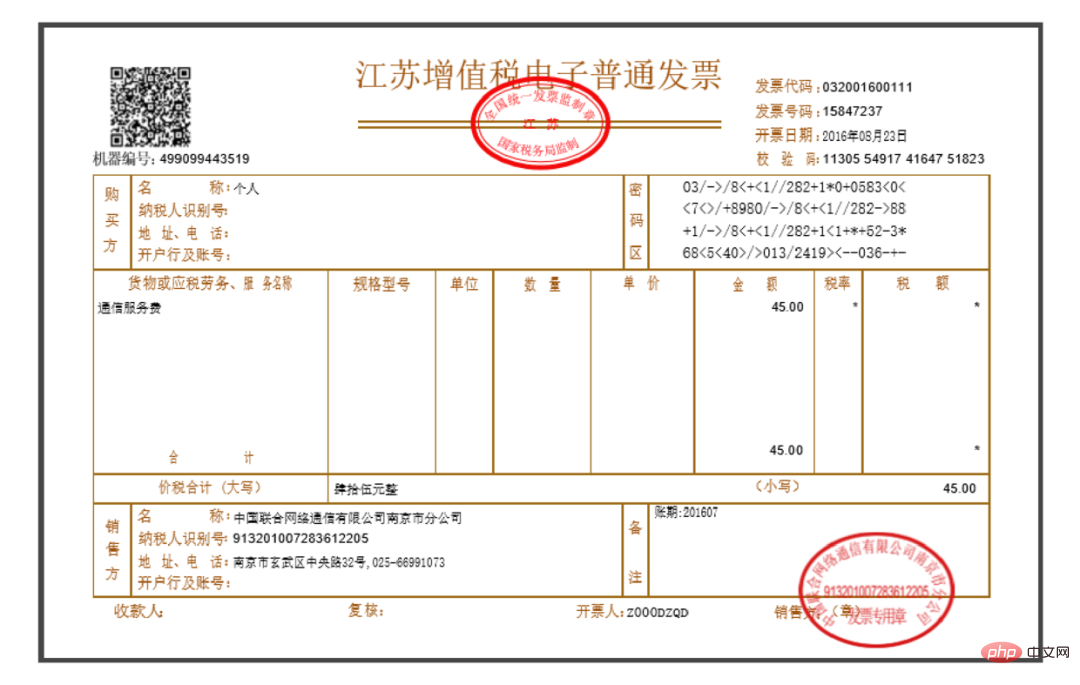
Jedes Rechnungs-PDF ist vom Typ Reines Bild. Die darin enthaltenen Textinformationen können nicht manuell kopiert werden (tatsächlich können Sie die meisten Rechnungen kopieren). Teil des Textes, aber wir werden es in Form von Bildern erklären), ungefähr wie in der folgenden Abbildung dargestellt:
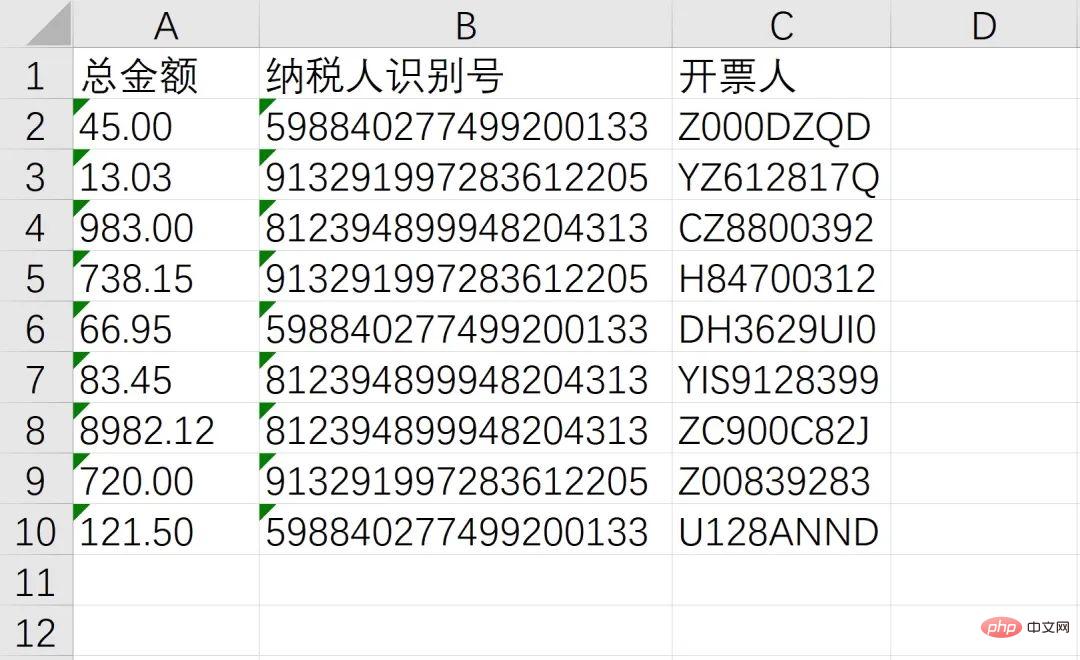
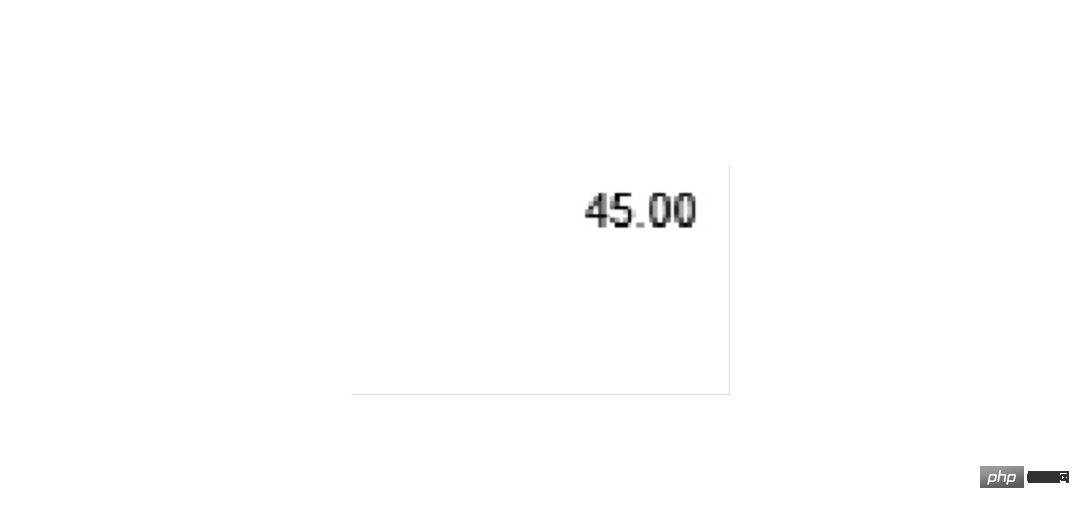
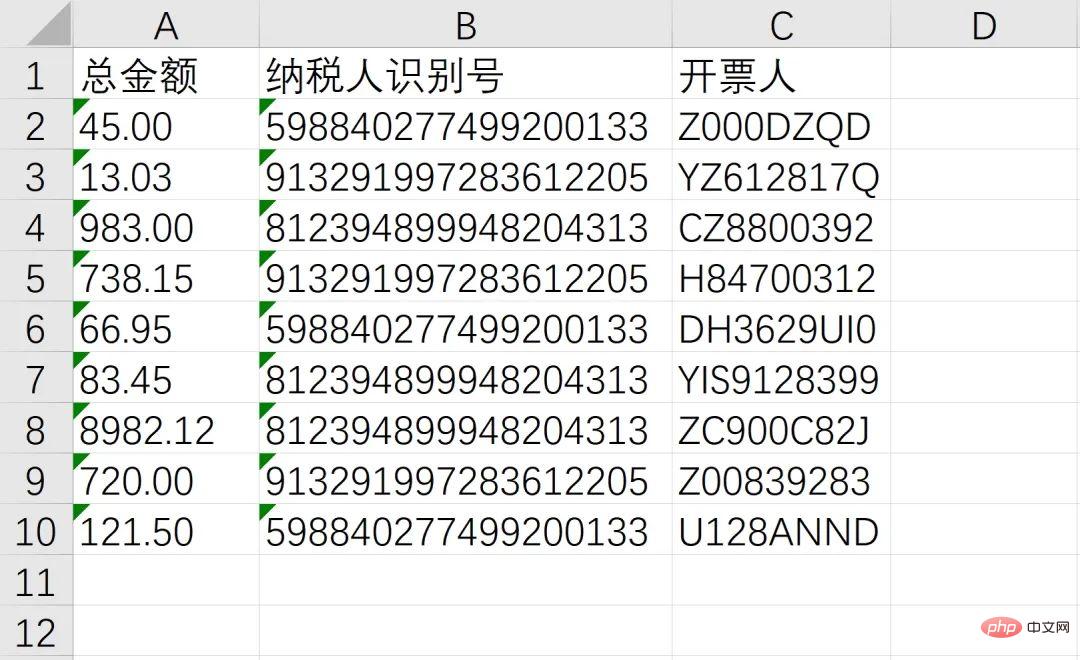
Die Anforderungen, die erfüllt werden müssen, sind: Erhalten Sie den Gesamtbetrag, die Steueridentifikationsnummer und den Emittenten , das heißt, die folgenden drei Kästchen Position:
Abschließend mit Batch-Vorgängen kombiniert, nach Erhalt der oben genannten Informationen in Excel speichern!
Ideen und Code-Implementierung
Die Anforderung ist im Wesentlichen ein Bilderkennungsproblem, da der Inhalt in PDF vom Bildtyp ist und der Text mit herkömmlichen Methoden nicht direkt extrahiert werden kann. Die Lösung besteht darin, mithilfe der optischen Zeichenerkennung (OCR) den Text im Bild zu erkennen. Gleichzeitig ist jedoch zu beachten, dass es sich bei PDF nicht um ein Bild handelt. Um die OCR abzuschließen, müssen Sie zusätzlich zur OCR selbst Folgendes herunterladen. Ghostscript 和 ImageMagick 用来完成类型转换。已 Windows Am Beispiel des Systems müssen Sie Folgendes installieren drei Software auf Ihrem Computer:
Das obige ist der detaillierte Inhalt vonTipps |. Python extrahiert und organisiert PDF-Rechnungen automatisch in Stapeln. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Stellungnahme:
Dieser Artikel ist reproduziert unter:Python当打之年. Bei Verstößen wenden Sie sich bitte an admin@php.cn löschen