
Heim >Backend-Entwicklung >Python-Tutorial >Crawler |. Batch-Download von HD-Hintergrundbildern (Quellcode + Tools enthalten)
Crawler |. Batch-Download von HD-Hintergrundbildern (Quellcode + Tools enthalten)

- Python当打之年nach vorne
- 2023-08-10 15:46:011588Durchsuche
Unsplash ist eine kostenlose, hochwertige Foto-Website , alle sind echte Fotografiefotos, die Fotoauflösung ist auch sehr groß, für Designerfreunde ist ein sehr gutes Material für jedermann und auch für einige Freunde des Illustrationstextens sehr praktisch. Es eignet sich auch gut als Hintergrundbild. Der entsprechende Funktionscode wurde in ein Exe-Tool gepackt. Die Code- und Tool-Erfassungsmethode ist am Ende des Artikels angehängt.
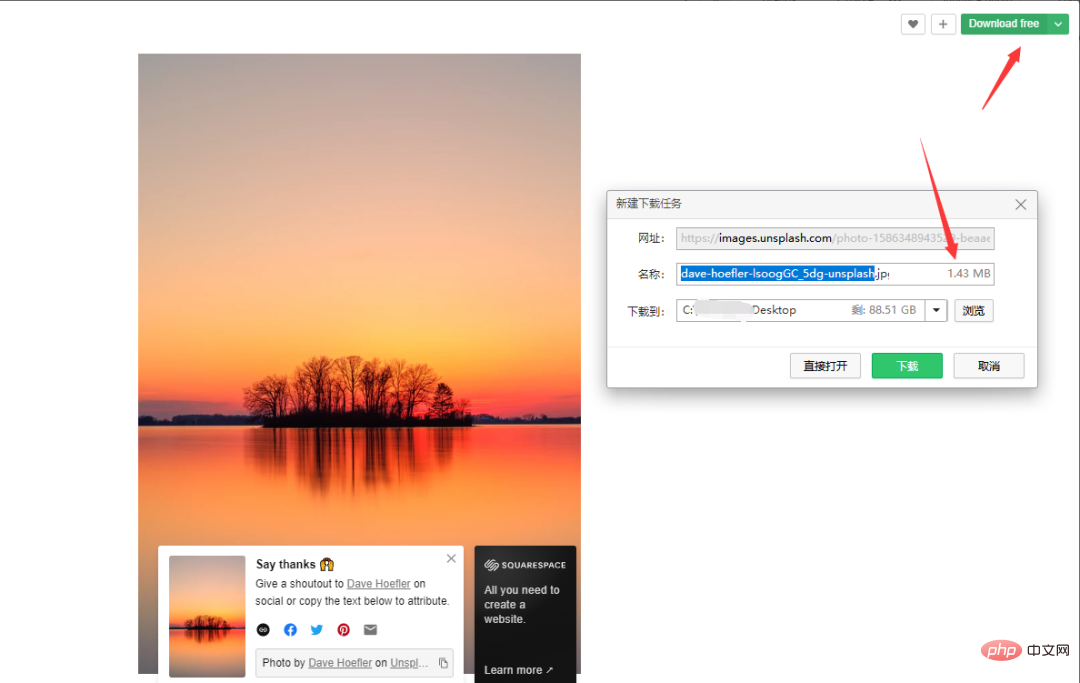
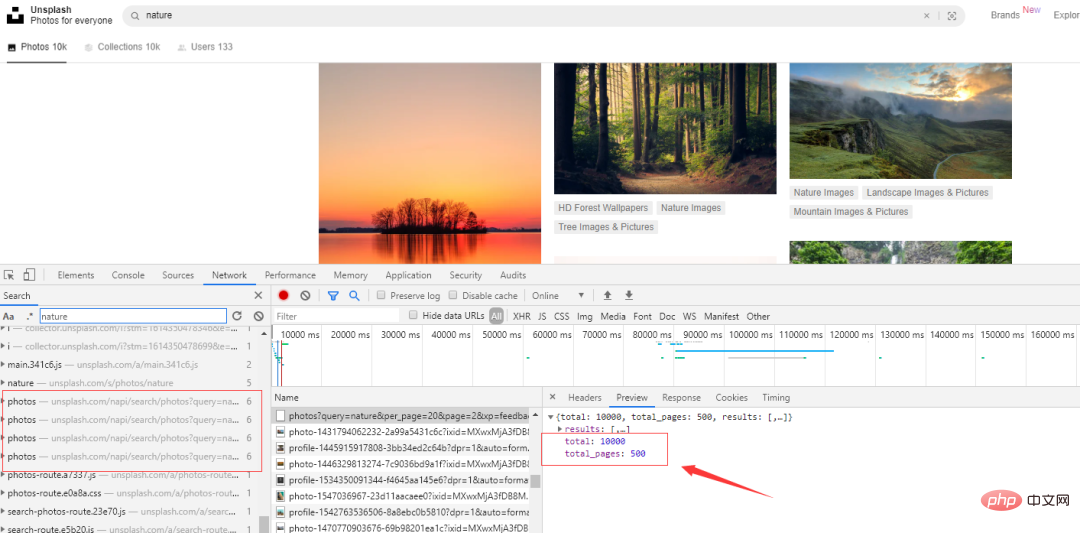
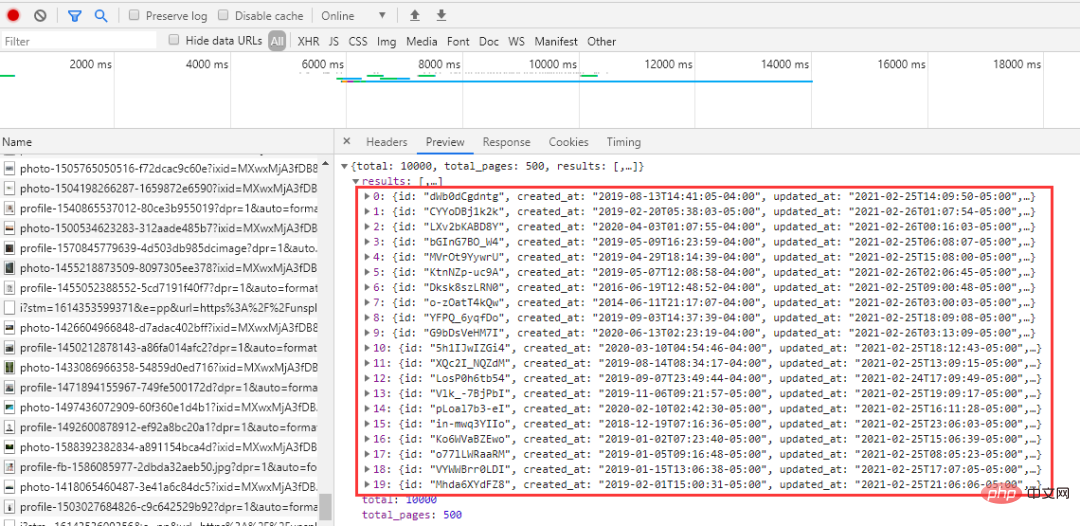
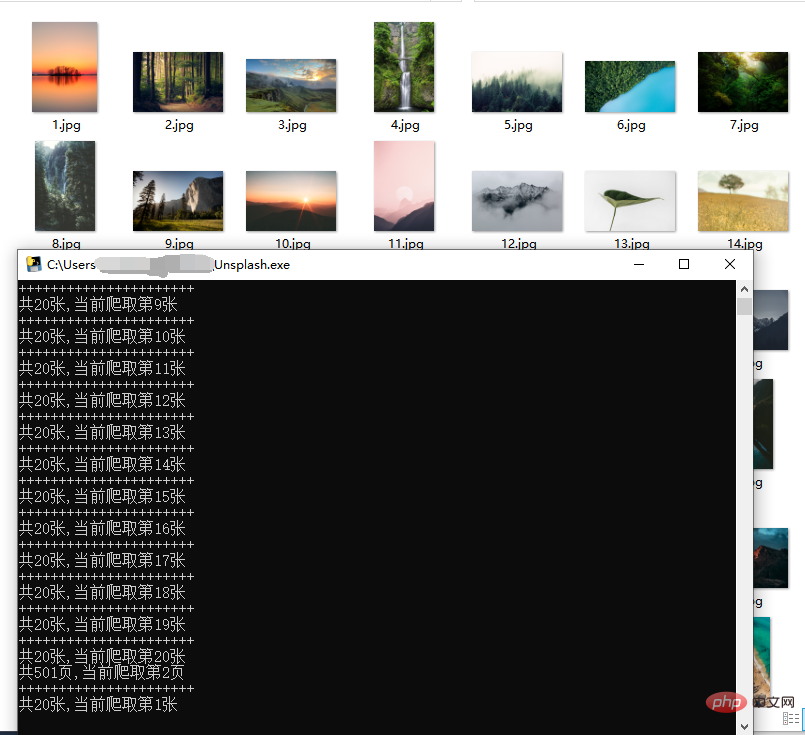
Code: Werfen wir zunächst einen Blick auf den manuellen Download-Vorgang. Beachten Sie, dass das durch Klicken mit der rechten Maustaste erhaltene Bild um ein bestimmtes Verhältnis komprimiert wird, anstatt mit der rechten Maustaste auf das Bild zu klicken und es zu speichern stark reduziert. Nehmen Sie die Natur als Beispiel, klicken Sie auf Kostenlos herunterladen und wählen Sie den Download-Pfad. Die Bildgröße beträgt 1,43 MB. Nach mehreren Vorgängen habe ich festgestellt, dass die Webseite beim Herunterfahren die folgenden Anfragen ausgibt. Klicken Sie auf eine davon und Sie können die Bilder sehen Gesamtzahl: 10000, Gesamtzahl der Seiten: 500. Lassen Sie uns ein paar URLs herausnehmen und einen Blick darauf werfen: Die oben genannten Links haben nur unterschiedliche Seitenparameter und sie steigen der Reihe nach an, was relativ freundlich ist . Wenn Sie es anfordern, müssen Sie es einfach durchqueren. Das Problem der Seitenzahl wurde gelöst. Analysieren Sie als Nächstes den Link jedes Bildes Genau 20. Bei demselben per_page-Wert in der Anfrage besteht kein Zweifel daran, dass der Link zu jedem Bild, nach dem wir suchen, hier ist. Webseiten zu analysieren ist oft zeitaufwändig, aber insgesamt läuft es reibungslos. Jetzt crawlen wir offiziell die Bilder. 2. Crawl-Bilder fake_useragent:代理 Versuchen Sie, nicht häufig zu crawlen, um die Netzwerkreihenfolge nicht zu beeinträchtigen! Bei den Bildern handelt es sich um hochauflösende Bilder aus dem Internet. Die Crawling-Geschwindigkeit hängt vom Netzwerk ab und ist im Allgemeinen nicht zu hoch. Sie können einen Proxy-Pool erstellen, um schneller zu crawlen. 

import time
import random
import json
import requests
from fake_useragent import UserAgent
ua = UserAgent(verify_ssl=False)
headers = {'User-Agent': ua.random}def getpicurls(i,headers):
picurls = []
url = 'https://unsplash.com/napi/search/photos?query=nature&per_page=20&page={}&xp=feedback-loop-v2%3Aexperiment'.format(i)
r = requests.get(url, headers=headers, timeout=5)
time.sleep(random.uniform(3.1, 4.5))
r.raise_for_status()
r.encoding = r.apparent_encoding
allinfo = json.loads(r.text)
results = allinfo['results']
for result in results:
href = result['urls']['full']
picurls.append(href)
return picurlsdef getpic(count,url):
r = requests.get(url, headers=headers, timeout=5)
with open('pictures/{}.jpg'.format(count), 'wb') as f:
f.write(r.content)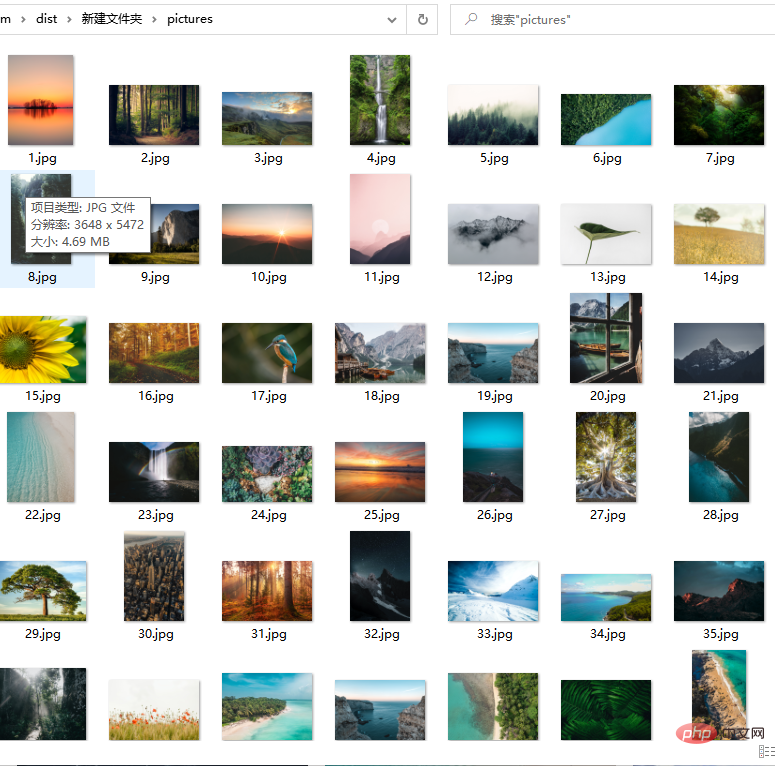
Das obige ist der detaillierte Inhalt vonCrawler |. Batch-Download von HD-Hintergrundbildern (Quellcode + Tools enthalten). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!