Der Kern des Leistungsproblems besteht darin, dass die Systemressourcen den Engpass erreicht haben, die Anforderungsverarbeitung jedoch nicht schnell genug ist, um weitere Anforderungen zu unterstützen. Bei der Leistungsanalyse geht es eigentlich darum, die Engpässe der Anwendung oder des Systems zu finden und zu versuchen, diese zu vermeiden oder zu lindern.
Wählen Sie Metriken zur Bewertung der Anwendungs- und Systemleistung.
Legen Sie Leistungsziele für Anwendungen und Systeme fest
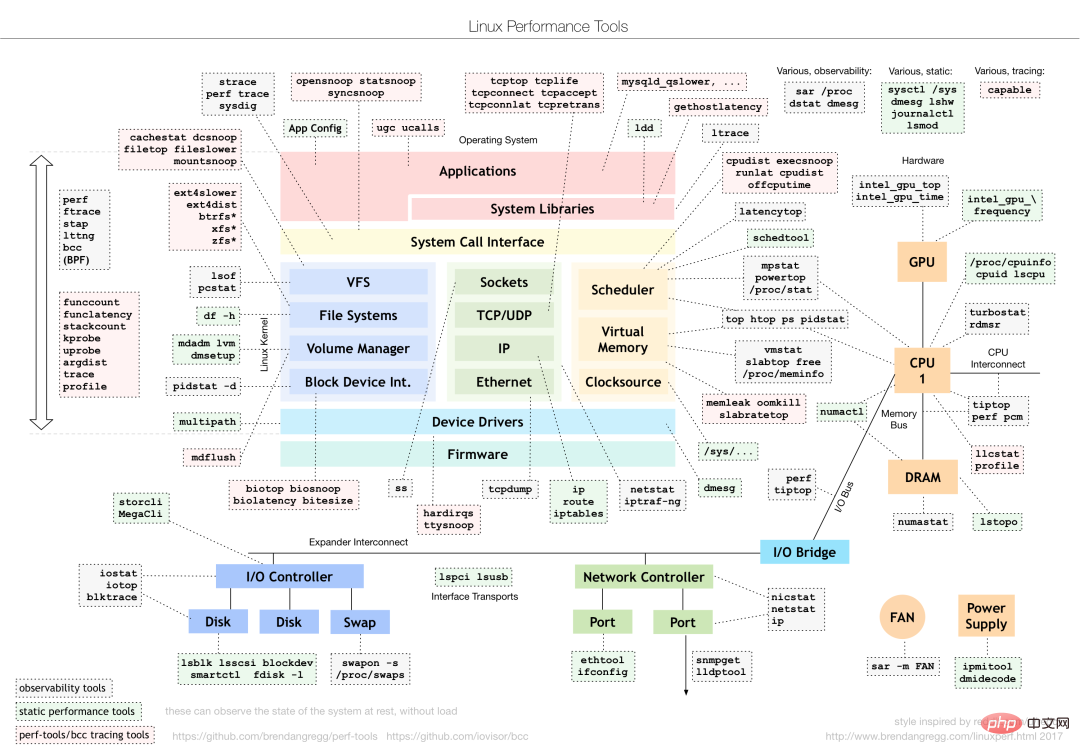
Wählen Sie unterschiedliche Leistungsanalysetools für unterschiedliche Leistungsprobleme. Im Folgenden werden häufig verwendete Linux-Leistungstools und die entsprechenden Arten von Leistungsproblemen analysiert.
Bild von: www.ctq6.cn
Wie sollen wir „durchschnittliche Last“ verstehen? ist die durchschnittliche Anzahl aktiver Prozesse. Es steht nicht in direktem Zusammenhang mit der CPU-Auslastung, wie wir es traditionell verstehen.
Der unterbrechungsfreie Prozess ist ein Prozess, der sich im Kernelstatus in einem kritischen Prozess befindet (z. B. eine allgemeine E/A-Antwort, die auf ein Gerät wartet).
Der unterbrechungsfreie Zustand ist eigentlich ein Schutzmechanismus des Systems für Prozesse und Hardwaregeräte.
Was ist die angemessene durchschnittliche Auslastung? Überwachen Sie in der tatsächlichen Produktionsumgebung die durchschnittliche Auslastung des Systems und beurteilen Sie den Laständerungstrend anhand historischer Daten. Wenn es einen offensichtlichen Aufwärtstrend bei der Auslastung gibt, führen Sie rechtzeitig eine Analyse und Untersuchung durch. Natürlich können Sie auch einen Schwellenwert festlegen (z. B. wenn die durchschnittliche Auslastung mehr als 70 % der CPU-Anzahl beträgt).
In der Praxis verwechseln wir häufig die Konzepte der durchschnittlichen Auslastung und der CPU-Auslastung sind nicht völlig gleichwertig:
CPU-intensive Prozesse führen zu einem Anstieg der durchschnittlichen Auslastung Zu diesem Zeitpunkt ist die CPU-Auslastung nicht unbedingt hoch. Eine große Anzahl von Prozessen, die auf die CPU-Planung warten, führt zu einem Anstieg der durchschnittlichen Last Mit der Zeit wird auch die CPU-Auslastung relativ hoch sein
Wenn die durchschnittliche Auslastung hoch ist, kann dies an CPU-intensiven Prozessen liegen oder daran liegen, dass /O ausgelastet ist. Während einer spezifischen Analyse können Sie das Tool mpstat/pidstat kombinieren, um die Analyse der Lastquelle zu unterstützen
2 Der Kontext der neuen Aufgabe wird an diese Register und den Programmzähler übertragen und schließlich wird an die Stelle gesprungen, auf die der Programmzähler zeigt, um die neue Aufgabe auszuführen. Unter anderem wird der gespeicherte Kontext im Systemkernel gespeichert und bei einer Neuplanung der Aufgabe erneut geladen, um sicherzustellen, dass der ursprüngliche Aufgabenstatus nicht beeinträchtigt wird. Folgen Sie der chinesischen Linux-CommunityJe nach Aufgabentyp ist die CPU-Kontextumschaltung unterteilt in:
Prozesskontextwechsel
Thread-Kontextwechsel
Interrupt-Kontextwechsel
Prozesskontextwechsel
Der Linux-Prozess unterteilt den laufenden Bereich des Prozesses entsprechend in Kernelraum und Benutzerraum Berechtigungsstufe. Der Übergang vom Benutzermodus zum Kernelmodus muss durch Systemaufrufe abgeschlossen werden.
Ein Systemaufrufprozess führt tatsächlich zwei CPU-Kontextwechsel durch:
Die Position der Benutzermodusanweisung im CPU-Register wird zuerst gespeichert, das CPU-Register wird auf die Position der Kernelmodusanweisung aktualisiert und in den Kernelmodus gesprungen, um die Kernelaufgabe auszuführen
Nach dem Systemaufruf Nach Abschluss stellt das CPU-Register die ursprünglich gespeicherten Benutzerstatusdaten wieder her und wechselt dann zum Benutzerbereich, um mit der Ausführung fortzufahren.
Der Systemaufrufprozess umfasst keine Prozessbenutzermodusressourcen wie virtuellen Speicher und wechselt auch nicht den Prozess. Es unterscheidet sich vom Prozesskontextwechsel im herkömmlichen Sinne. Daher wird der Systemaufruf oft als privilegierter Moduswechsel bezeichnet .
Prozesse werden vom Kernel verwaltet und geplant, und der Prozesskontextwechsel kann nur im Kernelmodus erfolgen. Daher müssen im Vergleich zu Systemaufrufen vor dem Speichern des Kernelstatus und der CPU-Register des aktuellen Prozesses zunächst der virtuelle Speicher und der Stapel des Prozesses gespeichert werden. Nach dem Laden des Kernelstatus des neuen Prozesses müssen der virtuelle Speicher und der Benutzerstapel des Prozesses aktualisiert werden.
Der Prozess muss nur dann den Kontext wechseln, wenn die Ausführung auf der CPU geplant ist. Es gibt die folgenden Szenarien: CPU-Zeitscheiben werden abwechselnd zugewiesen, unzureichende Systemressourcen führen dazu, dass der Prozess hängt, der Prozess bleibt aktiv während der Ruhezustandsfunktion hängen und Vorlaufzeit für Prozesse mit hoher Priorität. Wenn ein Hardware-Interrupt auftritt, wird der Prozess auf der CPU angehalten und führt stattdessen den Interrupt-Dienst im Kernel aus.
Thread-Kontextwechsel
Thread-Kontextwechsel ist in zwei Typen unterteilt:
Der vordere und hintere Thread gehören zum selben Prozess, und die virtuellen Speicherressourcen bleiben während des Wechsels unverändert. Sie müssen nur die privaten Daten, Register usw. des Threads wechseln.
Der vordere und hintere Thread gehören dazu zu verschiedenen Prozessen, was dem Wechsel des Prozesskontexts entspricht.
Thread-Wechsel im selben Prozess verbraucht weniger Ressourcen, was auch der Vorteil von Multithreading ist.
Interrupt-Kontextwechsel
Der Interrupt-Kontextwechsel betrifft nicht den Benutzerstatus des Prozesses, sodass der Interrupt-Kontext nur den Status enthält, der für die Ausführung des Kernel-Status-Interrupt-Dienstprogramms erforderlich ist (CPU-Register, Kernel-Stack, Hardware-Interrupt). Parameter usw.).
Die Priorität der Interrupt-Verarbeitung ist höher als die des Prozesses, sodass Interrupt-Kontextwechsel und Prozesskontextwechsel nicht gleichzeitig stattfinden
CPU-Kontextwechsel (Teil 2)
Sie können die allgemeine Kontextwechselsituation des Systems über vmstat überprüfen
Die CPU-Auslastung einer Anwendung erreicht 100 %, was soll ich tun?
Linux, als Multitasking-Betriebssystem, teilt die CPU-Zeit in kurze Zeitscheiben auf und weist diese über den Scheduler der Reihe nach jeder Aufgabe zu. Um die CPU-Zeit aufrechtzuerhalten, löst Linux Zeitunterbrechungen durch vordefinierte Beat-Raten aus und verwendet globale Jiffies, um die Anzahl der Beats seit dem Booten aufzuzeichnen. Die Zeitunterbrechung erfolgt, sobald dieser Wert + 1.
CPU-Auslastung , der Prozentsatz der gesamten CPU-Zeit außer der Leerlaufzeit. Die CPU-Auslastung kann anhand der Daten in /proc/stat berechnet werden. Denn der kumulative Wert der Anzahl der Beats seit dem Booten in /proc/stat wird als durchschnittliche CPU-Auslastung seit dem Booten berechnet, was im Allgemeinen von geringer Aussagekraft ist. Sie können die durchschnittliche CPU-Auslastung während dieses Zeitraums berechnen, indem Sie die Differenz zwischen zwei Werten ermitteln, die in Abständen eines Zeitraums ermittelt wurden. Das Leistungsanalysetool gibt die durchschnittliche CPU-Auslastung über einen bestimmten Zeitraum an. Achten Sie auf die Einstellung des Intervalls.
Die CPU-Auslastung kann über top oder ps angezeigt werden. Sie können die CPU-Probleme des Prozesses mithilfe von Perf analysieren, das auf der Stichprobenerhebung von Leistungsereignissen basiert. Es kann nicht nur verschiedene Ereignisse des Systems und der Kernelleistung analysieren, sondern auch zur Analyse der Leistungsprobleme bestimmter Anwendungen verwendet werden.
Perf Top / Perf Record / Perf Report (-g aktiviert die Stichprobe von Anrufbeziehungen)
sudo docker run --name nginx -p 10000:80 -itd feisky/nginx
sudo docker run --name phpfpm -itd --network container:nginx feisky/php-fpm
ab -c 10 -n 100 http://XXX.XXX.XXX.XXX:10000/ #测试Nginx服务性能
Dies ist immer noch nur eine Vermutung. Der nächste Schritt besteht darin, die Analyse mit dem Perf-Tool fortzusetzen. Der Leistungsbericht zeigt, dass Stress tatsächlich viel CPU beansprucht, was durch die Behebung des Berechtigungsproblems gelöst werden kann.
Was soll ich tun, wenn im System eine große Anzahl unterbrechungsfreier Prozesse und Zombie-Prozesse vorhanden sind?
Prozessstatus
R Wird ausgeführt/ausführbar, was darauf hinweist, dass sich der Prozess in der Bereitschaftswarteschlange der CPU befindet, ausgeführt wird oder auf die Ausführung wartet; kommuniziert mit der Hardware und darf während der Interaktion nicht durch andere Prozesse unterbrochen werden.
Z Zombie, ein Zombie-Prozess, was bedeutet, dass der Prozess tatsächlich beendet wurde, der übergeordnete Prozess jedoch seine Ressourcen nicht zurückgefordert hat ;
S Unterbrechbarer Ruhezustand, der unterbrochen werden kann, bedeutet, dass der Prozess vom System angehalten wird, weil es auf ein Ereignis wartet, und in den R-Zustand übergeht
I Leerlauf, Ruhezustand, wird für Kernel-Threads verwendet, die den Ruhezustand nicht unterbrechen können. Dieser Zustand führt nicht zu einem Anstieg der durchschnittlichen Last nicht oben/ps gesehen werden.
Nach einer schichtweisen Analyse liegt die Hauptursache im direkten Festplatten-I/O innerhalb der App. Suchen Sie dann den spezifischen Codespeicherort zur Optimierung.
Zombie-Prozesse
Nach der oben genannten Optimierung ist Iowait deutlich zurückgegangen, aber die Anzahl der Zombie-Prozesse nimmt immer noch zu. Suchen Sie zunächst den übergeordneten Prozess des Zombie-Prozesses. Drucken Sie mit pstree -aps XXX den Aufrufbaum des Zombie-Prozesses aus und stellen Sie fest, dass der übergeordnete Prozess der App-Prozess ist.
Überprüfen Sie den App-Code, um zu sehen, ob das Ende des untergeordneten Prozesses korrekt behandelt wird (ob wait()/waitpid() aufgerufen wird, ob eine SIGCHILD-Signalverarbeitungsfunktion registriert ist usw.).
Wenn Sie auf einen Anstieg von Iowait stoßen, verwenden Sie zunächst Tools wie dstat und pidstat, um zu bestätigen, ob ein Festplatten-E/A-Problem vorliegt, und finden Sie dann heraus, welche Prozesse das E/A verursachen. Wenn Sie strace nicht verwenden können Analysieren Sie den Prozessaufruf direkt. Sie können ihn mit dem Perf-Tool analysieren.
Für das Zombie-Problem verwenden Sie pstree, um den übergeordneten Prozess zu finden, und sehen Sie sich dann den Quellcode an, um die Verarbeitungslogik für das Ende des untergeordneten Prozesses zu überprüfen.
CPU-Leistungsindikator
CPU-Auslastung
Benutzer-CPU-Auslastung, einschließlich Benutzermodus (Benutzer) und Benutzermodus mit niedriger Priorität (schön). Wenn dieser Indikator zu hoch ist, wird dies angezeigt dass die Anwendung relativ ausgelastet ist.
System-CPU-Auslastung, der Prozentsatz der Zeit, die die CPU im Kernel-Modus läuft (ohne Interrupts). Ein hoher Indikator zeigt an, dass der Kernel relativ ausgelastet ist.
CPU-Auslastung wartet auf I /O, iowait, ein hoher Indikator zeigt an, dass die E/A-Interaktionszeit zwischen dem System und dem Hardwaregerät relativ lang ist im System.
CPU/Gast-CPU stehlen, was den Prozentsatz der belegten CPU der virtuellen Maschine angibt.
Durchschnittliche Auslastung
Idealerweise entspricht die durchschnittliche Auslastung der Anzahl der logischen CPUs, was bedeutet, dass jede Wenn die CPU vollständig ausgelastet ist, bedeutet dies, dass die Systemlast höher ist. Prozesskontextwechsel
Einschließlich freiwilliger Umschaltung, wenn Ressourcen nicht abgerufen werden können, und unfreiwilliger Umschaltung, wenn das System die Planung selbst erzwingt, ist eine Kernfunktion, um den normalen Betrieb von Linux sicherzustellen. Übermäßiges Umschalten verbraucht die CPU-Zeit des ursprünglich laufenden Prozesses im Register und im Kernel In Bezug auf das Speichern und Wiederherstellen von Daten wie dem virtuellen Speicher (CPU-Cache-Trefferrate) ist die Leistung umso besser, je höher die Trefferrate ist Kern, und L3 wird in Multi-Core verwendet
Performance -Tools
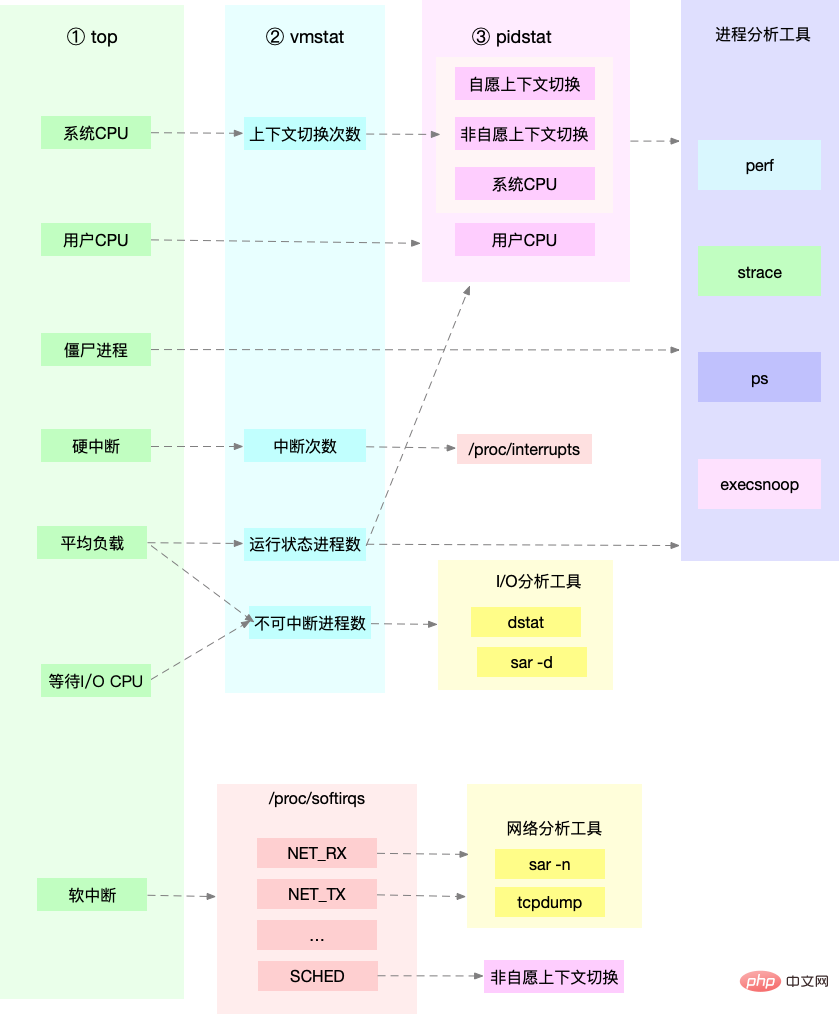
Durchschnittlastfall. CPU bzw. CPU-Auslastung jedes Prozesses. Durchsuchen Sie außerdem das öffentliche Linux-Konto und antworten Sie auf „Git Books“, um ein Überraschungsgeschenkpaket zu erhalten.
Kontextwechselfall
Verwenden Sie zunächst vmstat, um die Kontextwechsel- und Unterbrechungszeiten des Systems zu überprüfen
Dann verwenden Sie pidstat, um den freiwilligen und unfreiwilligen Kontextwechsel des Prozesses zu beobachten
Verwenden Sie abschließend pidstat Um den Thread zu beobachten Kontextwechselsituation
Bei hoher Prozess-CPU-Auslastung
Verwenden Sie zuerst top, um die CPU-Auslastung des Systems und des Prozesses zu überprüfen, suchen Sie den Prozess
Beobachten Sie dann mit perf top die Prozessaufrufkette und suchen Sie die spezifische Prozessfunktion
Bei hoher System-CPU-Auslastung
Verwenden Sie zunächst top, um die CPU-Auslastung des Systems zu überprüfen und weder top noch pidstat können den Prozess finden hohe CPU-Auslastung
Überprüfen Sie die Top-Ausgabe noch einmal
Beginnen Sie mit Prozessen, die eine geringe CPU-Auslastung haben, sich aber im Status „Laufen“ befinden
Perf-Aufzeichnung/Bericht über gefundene kurzfristige Prozessursachen (Execsnoop-Tool)
Unterbrechungsfreie und Zombie-Prozessfälle
Verwenden Sie zunächst top, um den Anstieg von Iowait zu beobachten und festzustellen, dass eine große Anzahl unterbrechungsfreier und Zombie-Prozesse
strace Prozesssystemaufrufe nicht verfolgen kann
perf analysierte die Aufrufkette und stellte fest, dass die Grundursache im direkten Festplatten-I/O lag
Soft-Interrupt-Fall
top stellte fest, dass die CPU-Auslastung des System-Soft-Interrupts hoch war
Ansicht / proc/softirqs und stellte fest, dass die Änderungsrate schnell war. Es wurde festgestellt, dass der Befehl
sar ein Netzwerkpaketproblem darstellt
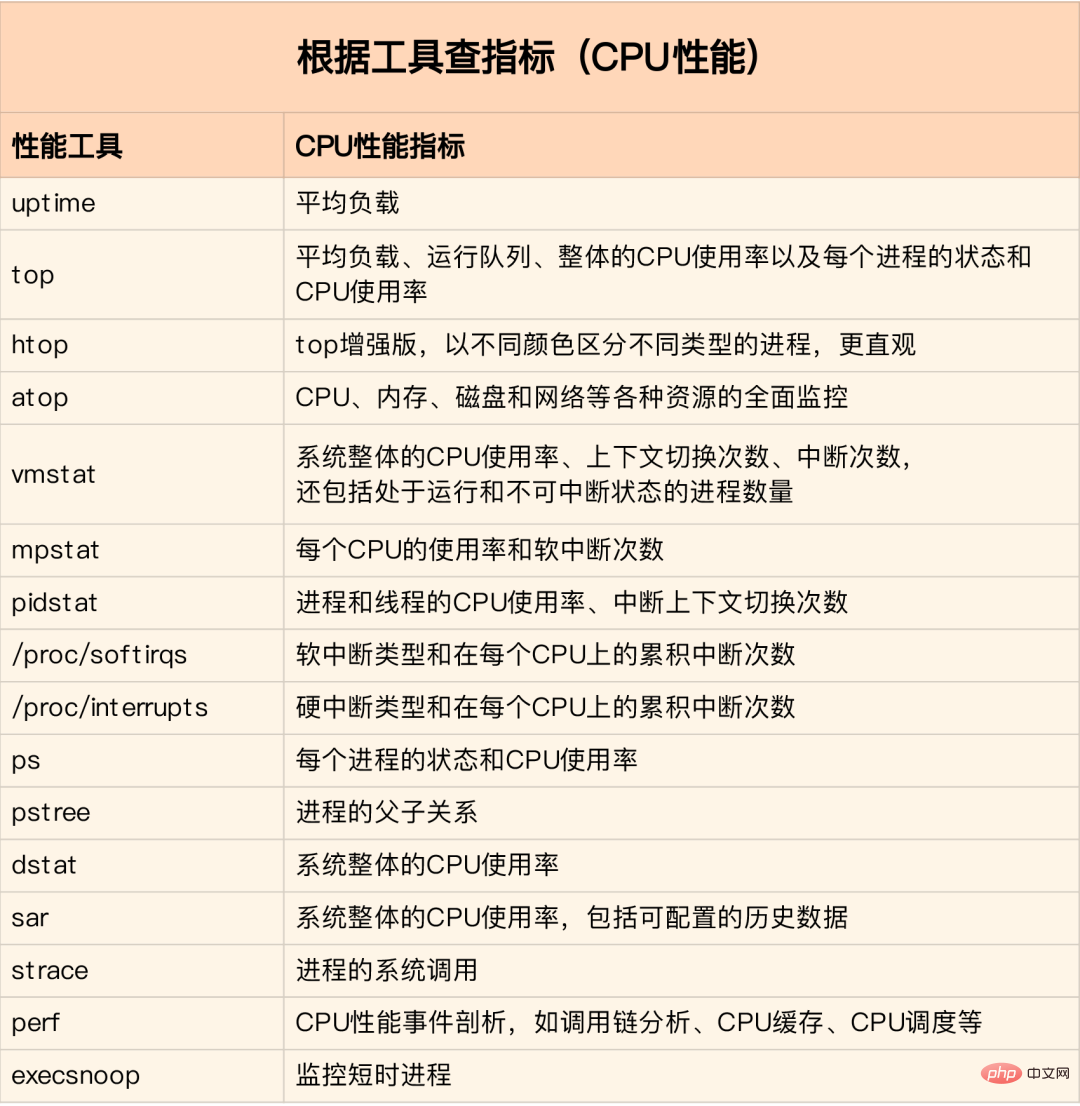
tcpdump, um den Typ und die Quelle von Netzwerkrahmen herauszufinden und die Ursache von SYN zu ermitteln FLOOD-Angriff: Finden Sie das passende Tool anhand verschiedener Leistungsindikatoren: Maximieren Sie nur die Nutzung der bereits im System installierten Tools. Daher ist es notwendig, einige Mainstream-Indikatoren zu verstehen. Welche Indikatoren kann das Tool liefern?Bild von: www.ctq6.cn
Führen Sie zunächst einige Tools aus, die weitere Indikatoren unterstützen, z. B. top/vmstat/pidstat. Anhand ihrer Ausgabe können Sie feststellen, um welche Art von Leistungsproblem es sich handelt Prozess Verwenden Sie dann strace/perf, um die Aufrufsituation zur weiteren Analyse zu analysieren. Wenn sie durch einen Soft-Interrupt verursacht wird, verwenden Sie /proc/softirqs. Bild von: www.ctq6.cn
Anwendung optimieren
Compiler-Optimierung: Aktivieren Sie Optimierungsoptionen während der Kompilierungsphase, z. B. gcc -O2 Funktionen. (Abfragen durch Ereignisbenachrichtigung ersetzen)
Multi-Threading statt Multi-Prozess: Reduzieren Sie die Kosten für den Kontextwechsel
CPU-Bindung: Binden Sie den Prozess an 1/mehrere CPUs, um die CPU-Cache-Trefferrate zu verbessern und den durch CPU-Planung verursachten Kontextwechsel zu reduzieren.
CPU-exklusiv: CPU-Affinitätsmechanismus zur Zuweisung von Prozessen
Anpassung der Prioritätsebene: Verwenden Sie „Nice“, um die Priorität von Anwendungen, die nicht zum Kerngeschäft gehören, entsprechend zu senken. CPU-Zugriff auf so viel wie möglich Lokaler Speicher
Interrupt-Lastausgleich: irpbalance, automatischer Lastausgleich des Interrupt-Verarbeitungsprozesses auf jede CPU
Der Unterschied und das Verständnis von TPS, QPS und Systemdurchsatz
QPS ähnelt TPS, aber ein Besuch einer Seite bildet einen TPS, aber eine Seitenanforderung kann mehrere Anfragen an den Server umfassen, die als mehrere QPS gezählt werden können
QPS (Abfragen pro Sekunde) Abfragerate pro Sekunde, die Anzahl der Abfragen, auf die ein Server pro Sekunde antworten kann.
TPS (Transaktionen pro Sekunde) Anzahl der Transaktionen pro Sekunde, das Ergebnis von Softwaretests
Der von den meisten Computern verwendete Hauptspeicher ist dynamisch Nur Ally-Random-Access-Speicher (DRAM). Der Kernel kann direkt auf den physischen Speicher zugreifen. Der Linux-Kernel stellt für jeden Prozess einen unabhängigen virtuellen Adressraum bereit, und dieser Adressraum ist kontinuierlich. Auf diese Weise kann der Prozess problemlos auf den Speicher (virtuellen Speicher) zugreifen.
Das Innere des virtuellen Adressraums ist in zwei Teile unterteilt: Kernelraum und Benutzerraum. Der Adressraumbereich von Prozessoren mit unterschiedlichen Wortlängen ist unterschiedlich. Der 32-Bit-Systemkernel-Speicherplatz belegt 1 GB und der Benutzerspeicherplatz belegt 3 GB. Der Kernelraum und der Benutzerraum von 64-Bit-Systemen sind beide 128T groß und belegen den höchsten bzw. niedrigsten Teil des Speicherraums, und der mittlere Teil ist undefiniert.
Nicht dem gesamten virtuellen Speicher wird physischer Speicher zugewiesen, sondern nur dem tatsächlich genutzten. Der zugewiesene physische Speicher wird durch Speicherzuordnung verwaltet. Um die Speicherzuordnung abzuschließen, verwaltet der Kernel für jeden Prozess eine Seitentabelle, um die Zuordnungsbeziehung zwischen virtuellen Adressen und physischen Adressen aufzuzeichnen. Die Seitentabelle wird tatsächlich in der Speicherverwaltungseinheit MMU der CPU gespeichert, und der Prozessor kann direkt über die Hardware den Speicher ermitteln, auf den zugegriffen werden soll.
Wenn die virtuelle Adresse, auf die der Prozess zugreift, nicht in der Seitentabelle gefunden werden kann, generiert das System eine Seitenfehlerausnahme, betritt den Kernel-Speicherplatz, um physischen Speicher zuzuweisen, aktualisiert die Prozessseitentabelle und kehrt dann zum Fortfahren in den Benutzerbereich zurück den Ablauf des Prozesses.
MMU verwaltet den Speicher in Seiteneinheiten mit einer Seitengröße von 4 KB. Um das Problem zu vieler Seitentabelleneinträge zu lösen, bietet Linux die Mechanismen „Mehrstufige Seitentabelle“ und „HugePage“. Virtuelle Speicherplatzverteilung
Der Benutzerspeicher ist in fünf verschiedene Speichersegmente von niedrig nach hoch unterteilt:
Schreibgeschütztes Segment Code und Konstanten usw.
Datensegment Globale Variablen usw.
Heap Dynamisch zugewiesener Speicher, beginnend bei einer niedrigen Adresse und nach oben wachsend
Dateizuordnung Aktualisierungen von Bibliotheken, gemeinsam genutztem Speicher usw. beginnen bei hohen Adressen und wachsen nach unten.
Stack Einschließlich lokaler Variablen und Funktionsaufrufkontext usw. Die Größe des Stapels ist festgelegt. Im Allgemeinen entspricht 8 MB Speicherzuweisung und -recycling Malloc dem Systemaufruf auf zwei Arten:
brk() Bei kleinen Speicherblöcken (
**mmap()** Weisen Sie bei großen Speicherblöcken (> 128 KB) direkt die Speicherzuordnung zu, d. h., suchen Sie eine freie Speicherzuordnung im Dateizuordnungssegment.
Der Cache des ersteren kann das Auftreten von Ausnahmen aufgrund fehlender Seiten reduzieren und die Effizienz des Speicherzugriffs verbessern. Da der Speicher jedoch nicht an das System zurückgegeben wird, führt eine häufige Speicherzuweisung/-freigabe zu einer Speicherfragmentierung, wenn der Speicher ausgelastet ist.
Letzteres wird bei der Freigabe direkt an das System zurückgegeben, sodass jedes Mal, wenn mmap auftritt, eine Seitenfehlerausnahme auftritt. Wenn die Speicherarbeit ausgelastet ist, führt die häufige Speicherzuweisung zu einer großen Anzahl von Seitenfehlerausnahmen, was die Belastung durch die Kernelverwaltung erhöht.
Die beiden oben genannten Aufrufe weisen keinen Speicher zu. Dieser Speicher gelangt nur über eine Seitenfehlerausnahme in den Kernel und wird vom Kernel zugewiesen.
Recycling
, das System fordert es auf folgende Weise zurück: Speicher:
VIRT Die Größe des virtuellen Speichers des Prozesses
RES Die Größe des residenten Speichers, d SHR Die Größe des gemeinsam genutzten Speichers, des mit anderen Prozessen geteilten Speichers, geladener dynamischer Linkbibliotheken und Programmcodesegmente
%MEM Der Prozentsatz des vom Prozess verwendeten physischen Speichers am gesamten Systemspeicher
Wie versteht man Puffer und Cache im Speicher?
Puffer ist ein Cache für Festplattendaten, Cache ist ein Cache für Dateidaten, sie werden sowohl in Leseanfragen als auch in Schreibanfragen verwendet
So nutzen Sie den Systemcache, um die Betriebseffizienz des Programms zu optimieren
Cache-Trefferquote
Cache-Trefferquote bezieht sich auf die Anzahl der Anfragen, Daten direkt über den Cache abzurufen Prozentsatz aller Anfragen. Je höher die Trefferquote, desto höher sind die Vorteile des Caches und desto besser ist die Leistung der Anwendung.
Nach der Installation des bcc-Pakets können Sie Cache-Lese- und Schreibtreffer über Cachestat und Cachetop überwachen.
Nach der Installation von pcstat können Sie die Cache-Größe und das Cache-Verhältnis der Dateien im Speicher überprüfen
#首先安装Go
export GOPATH=~/go
export PATH=~/go/bin:$PATH
go get golang.org/x/sys/unix
go ge github.com/tobert/pcstat/pcstat
Der zugewiesene Speicher wurde nicht ordnungsgemäß zurückgefordert, was zu Lecks führte.
Zugriff auf Adressen außerhalb der Grenzen des zugewiesenen Speichers, wodurch das Programm abnormal beendet wurde.
Speicherzuweisung und -recycling niedrig Von oben nach unten gibt es fünf Teile: schreibgeschütztes Segment, Datensegment, Heap, Speicherzuordnungssegment und Stapel. Zu diesen gehören diejenigen, die Speicherlecks verursachen können:
Heap: Von der Anwendung selbst zugewiesen und verwaltet. Diese Heap-Speicher werden vom System nicht automatisch freigegeben, es sei denn, das Programm wird beendet.
Speicherzuordnungssegment: Enthält dynamische Linkbibliotheken und gemeinsam genutzten Speicher, wobei der gemeinsam genutzte Speicher vom Programm automatisch zugewiesen und verwaltet wird. Der Schaden durch Speicherlecks ist relativ groß. Diese vergessen, Speicher freizugeben, können nicht nur auf sie von der Anwendung selbst zugegriffen werden kann. Das System kann sie auch nicht anderen Anwendungen zuordnen. Speicherlecks häufen sich und können sogar den Systemspeicher erschöpfen.
Cache/Puffer, eine wiederverwendbare Ressource, in der Dateiverwaltung normalerweise als Dateiseite bezeichnet
In der Anwendung werden schmutzige Seiten über fsync mit der Festplatte synchronisiert.
Überlassen Sie es dem System und dem Kernel-Thread pdflush ist verantwortlich Die Aktualisierung dieser schmutzigen Seiten
Daten (schmutzige Seiten), die von der Anwendung geändert und vorerst nicht auf die Festplatte geschrieben wurden, müssen zuerst auf die Festplatte geschrieben werden, und dann kann der Speicher gelöscht werden freigegeben
Die durch die Speicherzuordnung erhaltene Dateizuordnungsseite kann auch freigegeben und beim nächsten Zugriff erneut aus der Datei gelesen werden
Für den vom Programm automatisch zugewiesenen Heap-Speicher, der unser ist Anonyme Seite in der Speicherverwaltung. Obwohl dieser Speicher nicht direkt freigegeben werden kann, stellt Linux den Swap-Mechanismus bereit. Der Speicher, auf den nicht häufig zugegriffen wird, wird auf die Festplatte geschrieben, um den Speicher freizugeben, und der Speicher kann bei erneutem Zugriff von der Festplatte gelesen werden .
Swap-Prinzip
Die Essenz von Swap besteht darin, einen Teil des Speicherplatzes oder eine lokale Datei als Speicher zu verwenden, einschließlich zweier Prozesse des Ein- und Auslagerns:
Auslagern: Speichern Sie die Speicherdaten, die der Prozess nicht verwendet, vorübergehend auf der Festplatte und geben Sie den Speicher frei
Auslagern: Wenn der Prozess erneut auf den Speicher zugreift, lesen Sie sie von der Festplatte in den Speicher ein
Wie misst Linux, ob die Speicherressourcen knapp sind?
Direkte Speicherrückgewinnung Neue große Blockspeicherzuweisung angefordert, aber nicht genügend Speicher übrig. Zu diesem Zeitpunkt fordert das System einen Teil des Speichers zurück.
kswapd0 Der Kernel-Thread fordert regelmäßig Speicher zurück. Um die Speichernutzung zu messen, werden die drei Schwellenwerte „pages_min“, „pages_low“ und „pages_high“ definiert und darauf basierend Speicherrecyclingvorgänge durchgeführt.
So finden Sie schnell und genau Probleme mit dem Systemspeicher
Verfügbarer Speicher: einschließlich verbleibendem Speicher und zurückgewinnbarem Speicher
Cache: Seitencache von Festplatten-Lesedateien, zurückgewinnbarer Teil im Slab-Allokator
Puffer: temporäre Speicherung der ursprünglichen Festplattenblöcke, Zwischenspeicherung der auf die Festplatte zu schreibenden Daten
Prozessspeicheranzeige
Virtueller Speicher: 5 am meisten
Residenter Speicher: Der physische Speicher, der tatsächlich vom Prozess verwendet wird, ausgenommen Swap und Shared Memory
Shared Memory: Der Speicher, der mit anderen Prozessen sowie dynamischen Linkbibliotheken geteilt wird Programme Das Code-Snippet
Durchsuchen Sie außerdem den offiziellen Hintergrund der technischen Community des Kontos, um auf „Algorithmus“ zu antworten und ein Überraschungsgeschenkpaket zu erhalten. ( B. Swap), fehlt die Hauptseite ungewöhnlich. Zu diesem Zeitpunkt wird der Speicherzugriff viel langsamer sein
Speicherleistungstool
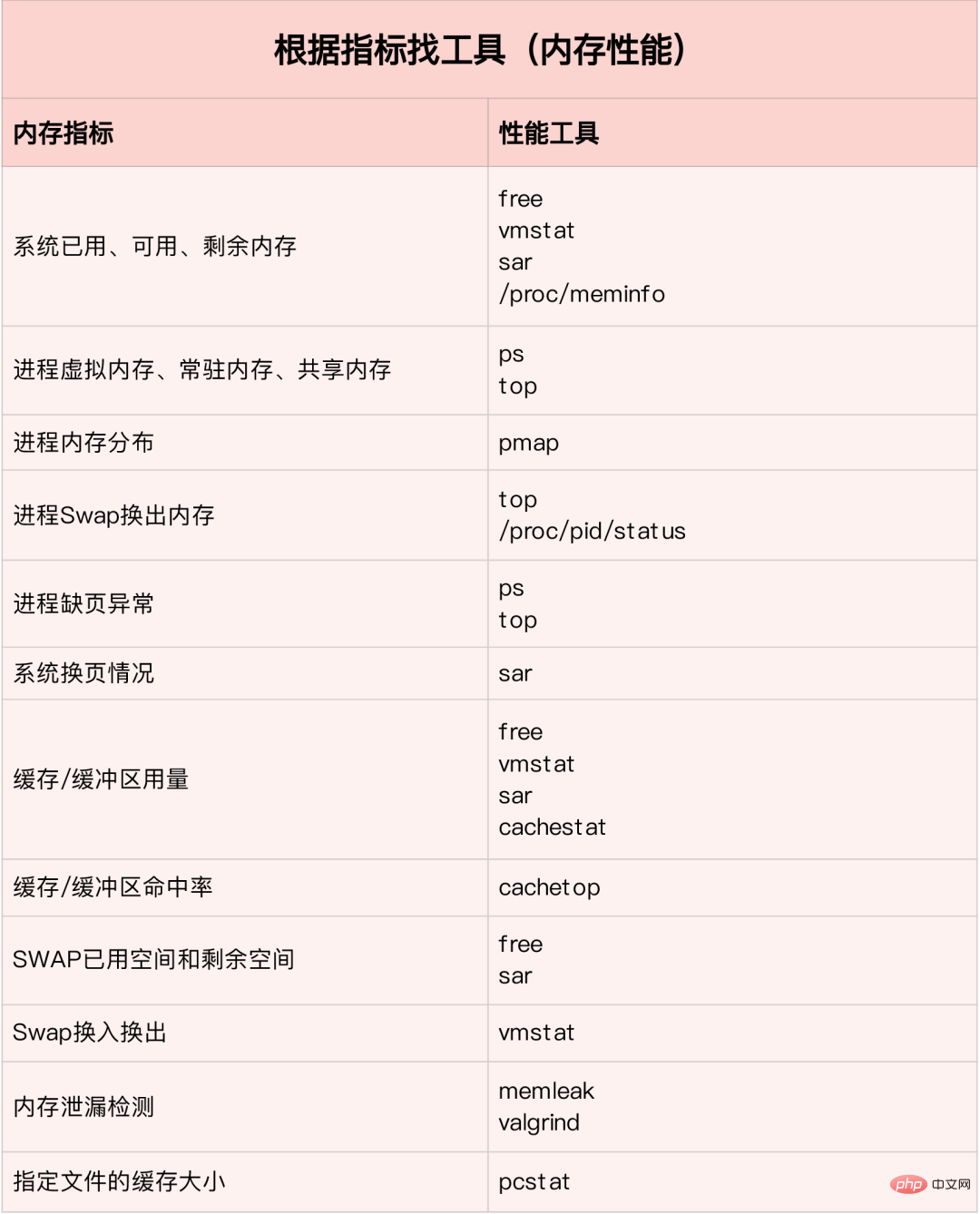
Finden Sie das richtige Tool anhand verschiedener Leistungsindikatoren:
Bilder von: www.ctq6.cn
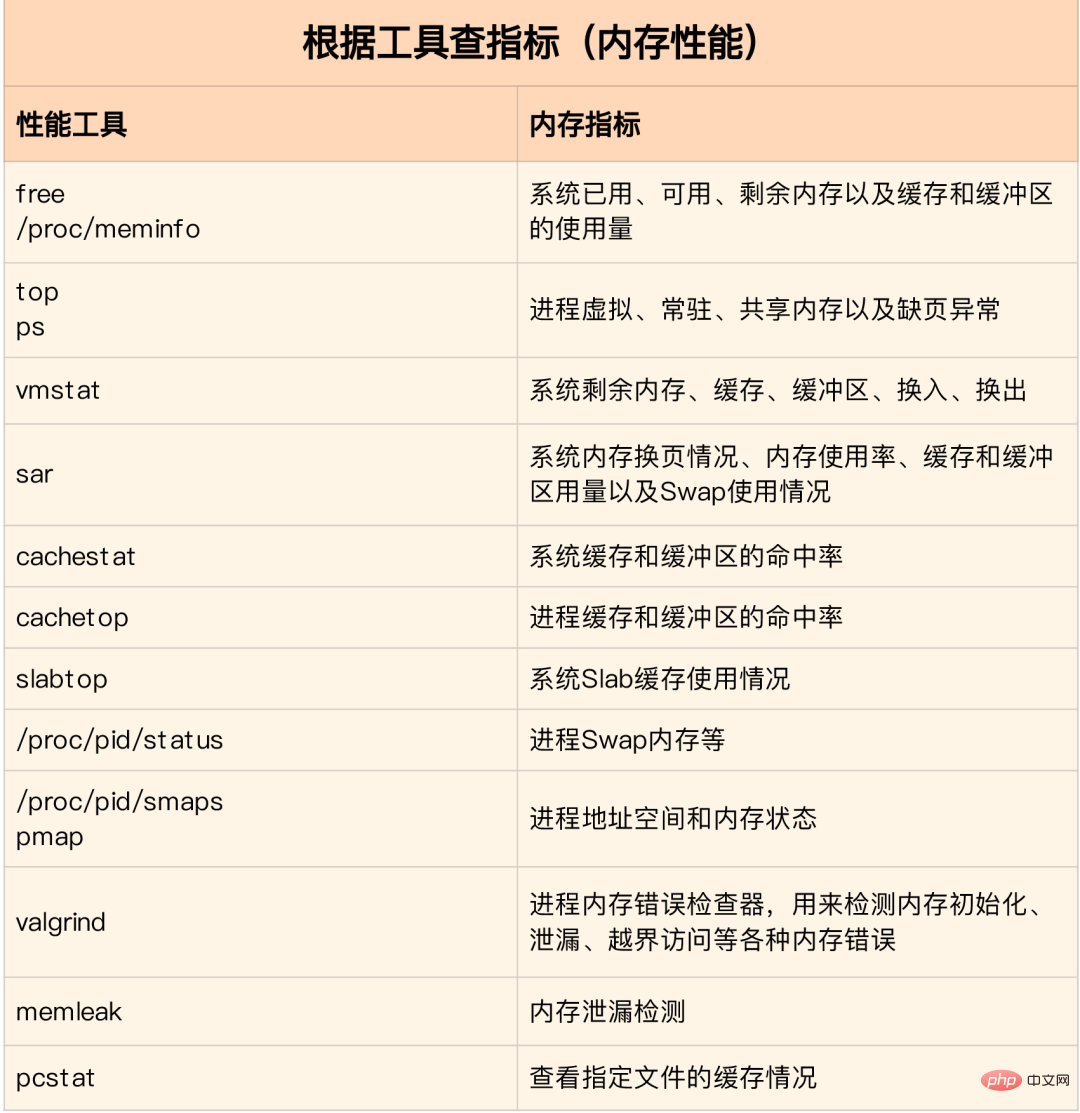
Im Speicheranalysetool enthaltene Leistungsindikatoren:
Bilder von: www.ctq6.cn
So analysieren Sie schnell Speicherleistungsengpässe
Normalerweise Führen Sie zunächst mehrere Leistungstools mit relativ großer Abdeckung aus, z. B. free, top, vmstat, pidstat usw.
Verwenden Sie zuerst free und top, um die Gesamtspeichernutzung des Systems zu überprüfen.
Dann verwenden Sie vmstat und pidstat, um den Trend über einen bestimmten Zeitraum zu überprüfen und die Art des Speicherproblems zu bestimmen Analyse, wie Speicherzuordnungsanalyse, Cache-/Pufferanalyse, Speichernutzungsanalyse bestimmter Prozesse usw.
Das obige ist der detaillierte Inhalt vonZusammenfassung der Wissenspunkte zur Linux-Leistungsoptimierung · Practice + Collection Edition. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Stellungnahme:
Dieser Artikel ist reproduziert unter:Linux中文社区. Bei Verstößen wenden Sie sich bitte an admin@php.cn löschen