
Heim >häufiges Problem >30 Bilder mit detaillierter Zusammenfassung des Betriebssystems!
30 Bilder mit detaillierter Zusammenfassung des Betriebssystems!
- Linux中文社区nach vorne
- 2023-08-02 17:56:011676Durchsuche
?? zum Möglichkeit, mehrere Programme gleichzeitig auszuführen.
2. Teilen
Teilen bedeutet, dass die Ressourcen im System von mehreren gleichzeitigen Prozessen genutzt werden können.Es gibt zwei Freigabemethoden: sich gegenseitig ausschließendes Teilen und gleichzeitiges Teilen.
Sich gegenseitig ausschließende gemeinsam genutzte Ressourcen werden als kritische Ressourcen wie Drucker usw. bezeichnet. Es darf nur ein Prozess gleichzeitig darauf zugreifen, und es ist ein Synchronisierungsmechanismus erforderlich, um einen sich gegenseitig ausschließenden Zugriff zu erreichen.3. Virtuell
Virtuelle Technologie wandelt eine physische Einheit in mehrere logische Einheiten um. Es gibt hauptsächlich zwei virtuelle Technologien: Zeitmultiplex-Technologie (Zeitmultiplex) und Raummultiplex-Technologie (Raummultiplex).Mehrere Prozesse können mithilfe der Zeitmultiplex-Technologie gleichzeitig auf demselben Prozessor ausgeführt werden. Dadurch kann jeder Prozess abwechselnd den Prozessor belegen, jedes Mal nur eine kleine Zeitscheibe ausführen und schnell wechseln.
Der virtuelle Speicher nutzt die Space-Division-Multiplexing-Technologie, die den physischen Speicher in den Adressraum abstrahiert, und jeder Prozess verfügt über seinen eigenen Adressraum. Seiten im Adressraum werden dem physischen Speicher zugeordnet. Nicht alle Seiten im Adressraum müssen sich im physischen Speicher befinden. Wenn eine Seite verwendet wird, die sich nicht im physischen Speicher befindet, wird der Seitenersetzungsalgorithmus ausgeführt, um die Seite im Speicher zu ersetzen.
4. Asynchron
Asynchron bedeutet, dass der Prozess nicht auf einmal ausgeführt wird, sondern anhält und mit einer unbekannten Geschwindigkeit fortschreitet.
Grundfunktionen
1. Prozessmanagement
Prozesssteuerung, Prozesssynchronisation, Prozesskommunikation, Deadlock-Behandlung, Prozessorplanung usw.
2. Speicherverwaltung
Speicherzuweisung, Adresszuordnung, Speicherschutz und -freigabe, virtueller Speicher usw.
3. Dateiverwaltung
Dateispeicherplatzverwaltung, Verzeichnisverwaltung, Dateilese- und -schreibverwaltung und -schutz usw.
4. Geräteverwaltung
Vervollständigen Sie die E/A-Anfragen der Benutzer, erleichtern Sie Benutzern die Verwendung verschiedener Geräte und verbessern Sie die Gerätenutzung.
Beinhaltet hauptsächlich Pufferverwaltung, Gerätezuweisung, Geräteverarbeitung, virtuelle Geräte usw.
Systemaufruf
Wenn ein Prozess Kernel-Statusfunktionen im Benutzermodus verwenden muss, führt er einen Systemaufruf durch und fällt in den Kernel, und das Betriebssystem führt ihn in seinem Namen aus.
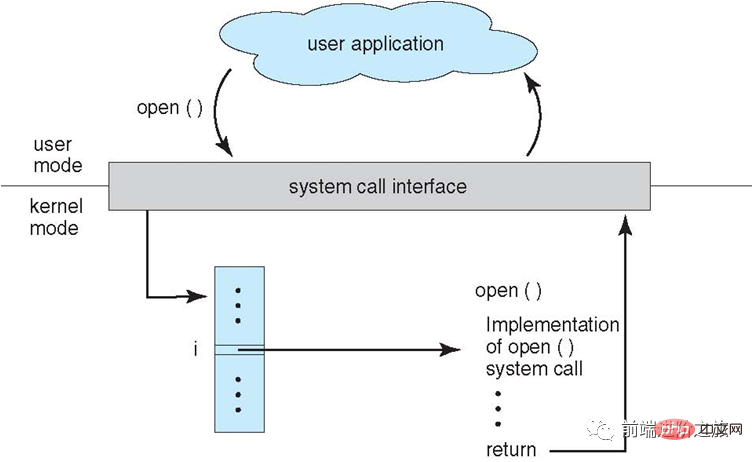
Die Systemaufrufe von Linux umfassen hauptsächlich Folgendes:

Großer Kernel und Mikrokernel
1. Großer Kernel
Der große Kernel behandelt die Betriebssystemfunktionen als schließen Das vereinte Ganze wird in den Kernel eingefügt.
Da jedes Modul Informationen austauscht, weist es eine hohe Leistung auf.
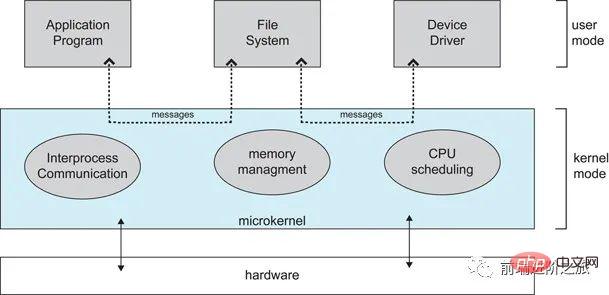
2. Mikrokernel
Da Betriebssysteme immer komplexer werden, werden einige Betriebssystemfunktionen aus dem Kernel verschoben, wodurch die Komplexität des Kernels verringert wird. Der entnommene Teil wird nach dem Layering-Prinzip in mehrere voneinander unabhängige Dienste aufgeteilt.
Unter der Mikrokernel-Struktur ist das Betriebssystem in kleine, klar definierte Module unterteilt. Nur das Mikrokernel-Modul läuft im Kernel-Modus und die anderen Module laufen im Benutzermodus.
Da Sie häufig zwischen Benutzermodus und Kernmodus wechseln müssen, kommt es zu einem gewissen Leistungsverlust.
Interrupt-Klassifizierung
1. Externer Interrupt
wird durch andere Ereignisse als die CPU-Ausführungsanweisungen verursacht, wie z abgeschlossen ist und der Prozessor die nächste Ein-/Ausgabeanforderung senden kann. Darüber hinaus gibt es Clock-Interrupts, Konsolen-Interrupts usw.

2. Ausnahmen
werden durch interne Ereignisse verursacht, wenn die CPU Anweisungen ausführt, wie z. B. illegale Opcodes, Adressüberschreitungen, arithmetischer Überlauf usw.
3. Verfallen in
Systemaufrufe in Benutzerprogrammen verwenden.
2. Prozessmanagement
Prozesse und Threads
1. Prozess
Prozess ist die Grundeinheit der Ressourcenallokation.
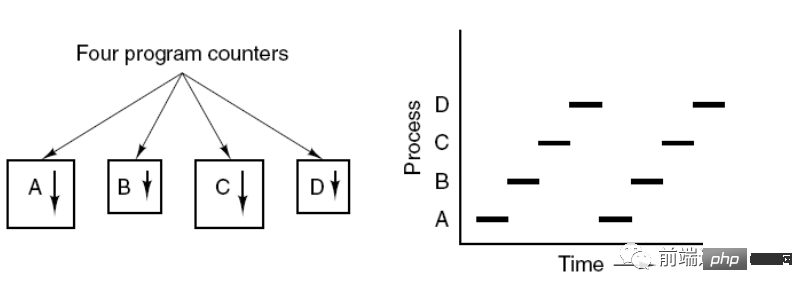
Prozesskontrollblock (PCB) beschreibt die grundlegenden Informationen und den laufenden Status des Prozesses. Die sogenannten Prozesserstellung und -abbruch beziehen sich auf Vorgänge auf der Leiterplatte.
Das Bild unten zeigt, dass 4 Programme 4 Prozesse erstellen und diese 4 Prozesse gleichzeitig ausgeführt werden können.
2. Thread
Thread ist die Grundeinheit der unabhängigen Planung.
Ein Prozess kann mehrere Threads enthalten, die sich Prozessressourcen teilen.
QQ und der Browser sind zwei Prozesse im Browserprozess, z. B. HTTP-Anforderungsthread, Ereignisantwortthread, Rendering-Thread usw. Die gleichzeitige Ausführung von Threads ermöglicht das Klicken auf einen neuen Link im Browser, um einen zu initiieren HTTP-Anfrage. Der Browser kann auch auf andere Ereignisse des Benutzers reagieren. 3. Unterschied: Besitz von Ressourcen
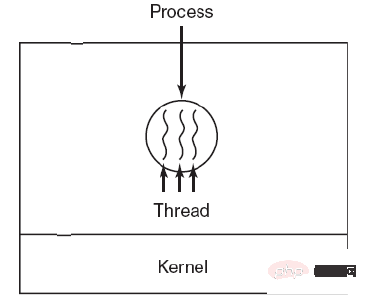 Thread ist die Grundeinheit der unabhängigen Planung. Im selben Prozess führt der Wechsel von einem Thread zu einem Thread in einem anderen Prozess nicht zu einem Prozesswechsel.
Thread ist die Grundeinheit der unabhängigen Planung. Im selben Prozess führt der Wechsel von einem Thread zu einem Thread in einem anderen Prozess nicht zu einem Prozesswechsel.
Da das System beim Erstellen oder Abbrechen eines Prozesses Ressourcen wie Speicherplatz, E/A-Geräte usw. zuweisen oder wiederverwenden muss, ist der entstehende Overhead viel größer als der Overhead beim Erstellen oder Abbrechen eines Threads. In ähnlicher Weise geht es beim Wechseln von Prozessen darum, die CPU-Umgebung des aktuell ausgeführten Prozesses zu speichern und die CPU-Umgebung des neuen geplanten Prozesses festzulegen. Beim Wechseln von Threads muss jedoch nur eine kleine Anzahl von Registerinhalten gespeichert und festgelegt werden Der Overhead ist sehr gering.
Ⅳ In Bezug auf die Kommunikation
Threads können durch direktes Lesen und Schreiben von Daten im selben Prozess kommunizieren, aber die Prozesskommunikation erfordert die Verwendung von IPC.
Umschalten des Prozessstatus
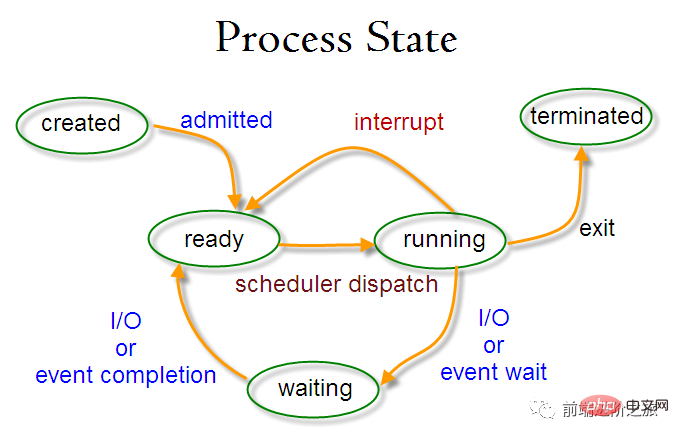
Bereitschaftsstatus (bereit): Wartet auf Planung
Laufstatus (läuft)
-
Blockierungszustand (wartend) : Beim Warten auf Ressourcen
sollten Sie Folgendes beachten:
Nur der Bereitschaftszustand und der Betriebszustand können ineinander umgewandelt werden, die anderen sind Einwegkonvertierungen. Der Prozess im Bereitschaftszustand erhält über den Planungsalgorithmus CPU-Zeit und wechselt in den Ausführungszustand, während der Prozess im Ausführungszustand in den Bereitschaftszustand wechselt, nachdem die ihm zugewiesene CPU-Zeitscheibe aufgebraucht ist, und auf die nächste Planung wartet .
Der Blockierungszustand ist der Mangel an erforderlichen Ressourcen und wird vom Betriebszustand umgewandelt, aber diese Ressource beinhaltet nicht die CPU-Zeit. Der Mangel an CPU-Zeit wird vom Betriebszustand in den Bereitschaftszustand umgewandelt.
Prozessplanungsalgorithmus
Planungsalgorithmen in verschiedenen Umgebungen haben unterschiedliche Ziele, daher müssen Planungsalgorithmen für unterschiedliche Umgebungen diskutiert werden.
1. Stapelverarbeitungssystem
Das Stapelverarbeitungssystem hat nicht zu viele Benutzeroperationen. In diesem System besteht das Ziel des Planungsalgorithmus darin, den Durchsatz und die Bearbeitungszeit (Zeit von der Übermittlung bis zur Beendigung) sicherzustellen.
1.1 „Wer zuerst kommt, mahlt zuerst“ (FCFS)
Ein nicht präemptiver Planungsalgorithmus, der in der Reihenfolge der Anfragen plant.
Es ist gut für lange Jobs, aber nicht gut für kurze Jobs, da kurze Jobs warten müssen, bis die vorherigen langen Jobs abgeschlossen sind, bevor sie ausgeführt werden können, und lange Jobs müssen lange ausgeführt werden, was zu kurzen Jobs führt Jobs warten zu lange.
1.2 Kürzester Job zuerst (SJF)
Ein nicht präemptiver Planungsalgorithmus, der in der Reihenfolge der kürzesten geschätzten Laufzeit plant.
Lange Jobs verhungern möglicherweise und warten darauf, dass kurze Jobs erledigt werden. Denn wenn es immer kurze Aufträge gibt, werden lange Aufträge nie eingeplant.
1.3 Kürzeste verbleibende Zeit als nächstes (SRTN)
Eine präventive Version des kürzesten Jobs zuerst, geplant in der Reihenfolge der verbleibenden Laufzeit. Beim Eintreffen eines neuen Jobs wird dessen gesamte Laufzeit mit der verbleibenden Zeit des aktuellen Prozesses verglichen. Wenn der neue Prozess weniger Zeit benötigt, wird der aktuelle Prozess angehalten und der neue Prozess ausgeführt. Ansonsten wartet der neue Prozess.
2. Interaktives System
Interaktive Systeme weisen eine große Anzahl von Benutzerinteraktionen auf, und das Ziel des Planungsalgorithmus in diesem System besteht darin, schnell zu reagieren.
2.1 Zeitscheibenrotation
Ordnen Sie alle bereiten Prozesse nach dem FCFS-Prinzip in einer Warteschlange an. Bei jeder Planung wird dem Warteschlangenleiterprozess CPU-Zeit zugewiesen, der eine Zeitscheibe ausführen kann. Wenn die Zeitscheibe aufgebraucht ist, gibt der Timer eine Taktunterbrechung aus, und der Scheduler stoppt die Ausführung des Prozesses und sendet ihn an das Ende der Bereitschaftswarteschlange, während er dem Prozess an der Spitze weiterhin CPU-Zeit zuweist die Warteschlange.
Die Effizienz des Zeitscheibenrotationsalgorithmus steht in engem Zusammenhang mit der Größe der Zeitscheibe:
Weil die Prozessumschaltung die Prozessinformationen speichern und die neuen Prozessinformationen laden muss, wenn die Zeitscheibe zu klein ist, Dies führt zu einem Prozesswechsel. Es wird zu oft und zu viel Zeit damit verbracht, Prozesse zu wechseln.
Und wenn die Zeitscheibe zu lang ist, kann die Echtzeitleistung nicht garantiert werden.
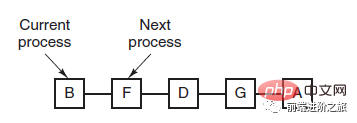
2.2 Prioritätsplanung
Weisen Sie jedem Prozess eine Priorität zu und planen Sie ihn entsprechend der Priorität.
Um zu verhindern, dass Prozesse mit niedriger Priorität nie auf die Planung warten, können Sie die Priorität wartender Prozesse im Laufe der Zeit erhöhen.
2.3 Mehrstufige Feedback-Warteschlange
Ein Prozess muss 100 Zeitscheiben ausführen. Wenn der Zeitscheiben-Rotationsplanungsalgorithmus verwendet wird, sind 100 Austausche erforderlich.
Mehrstufige Warteschlangen werden für Prozesse in Betracht gezogen, die mehrere Zeitscheiben kontinuierlich ausführen müssen. Sie richtet mehrere Warteschlangen ein, und jede Warteschlange hat eine andere Zeitscheibengröße, z. B. 1,2,4,8, .... Wenn die Ausführung des Prozesses in der ersten Warteschlange nicht abgeschlossen ist, wird er in die nächste Warteschlange verschoben. Auf diese Weise muss der vorherige Prozess nur 7 Mal ausgetauscht werden.
Jede Warteschlange hat unterschiedliche Prioritäten und die oberste hat die höchste Priorität. Daher kann der Prozess in der aktuellen Warteschlange nur dann geplant werden, wenn sich in der vorherigen Warteschlange kein Prozess befindet.
Dieser Planungsalgorithmus kann als eine Kombination aus dem Zeitscheibenrotations-Planungsalgorithmus und dem Prioritäts-Planungsalgorithmus betrachtet werden.
3. Echtzeitsystem
Ein Echtzeitsystem erfordert, dass eine Anfrage innerhalb einer bestimmten Zeit beantwortet wird.
牛逼啊!接私活必备的 N 个开源项目!赶快收藏吧...
ist in harte Echtzeit und weiche Echtzeit unterteilt. Ersteres muss die absolute Frist einhalten, und letzteres kann eine bestimmte Zeitüberschreitung tolerieren.
Prozesssynchronisierung
1. Kritischer Abschnitt
Der Code, der auf kritische Ressourcen zugreift, wird als kritischer Abschnitt bezeichnet.
Um gegenseitigen Zugriff auf kritische Ressourcen zu haben, muss jeder Prozess überprüft werden, bevor er in den kritischen Abschnitt gelangt.
// entry section // critical section; // exit section
2. Synchronisation und gegenseitiger Ausschluss
Synchronisation: Aufgrund der durch die Zusammenarbeit verursachten direkten Einschränkungsbeziehung haben mehrere Prozesse eine bestimmte sequentielle Ausführungsbeziehung.
Gegenseitiger Ausschluss: Nur ein Prozess mehrerer Prozesse kann gleichzeitig in den kritischen Abschnitt gelangen.
3. Semaphor
信号量(Semaphore)是一个整型变量,可以对其执行 down 和 up 操作,也就是常见的 P 和 V 操作。
down : 如果信号量大于 0 ,执行 -1 操作;如果信号量等于 0,进程睡眠,等待信号量大于 0;
up :对信号量执行 +1 操作,唤醒睡眠的进程让其完成 down 操作。
down 和 up 操作需要被设计成原语,不可分割,通常的做法是在执行这些操作的时候屏蔽中断。
如果信号量的取值只能为 0 或者 1,那么就成为了 互斥量(Mutex) ,0 表示临界区已经加锁,1 表示临界区解锁。
typedef int semaphore;
semaphore mutex = 1;
void P1() {
down(&mutex);
// 临界区
up(&mutex);
}
void P2() {
down(&mutex);
// 临界区
up(&mutex);
}使用信号量实现生产者-消费者问题
问题描述:使用一个缓冲区来保存物品,只有缓冲区没有满,生产者才可以放入物品;只有缓冲区不为空,消费者才可以拿走物品。
因为缓冲区属于临界资源,因此需要使用一个互斥量 mutex 来控制对缓冲区的互斥访问。
为了同步生产者和消费者的行为,需要记录缓冲区中物品的数量。数量可以使用信号量来进行统计,这里需要使用两个信号量:empty 记录空缓冲区的数量,full 记录满缓冲区的数量。其中,empty 信号量是在生产者进程中使用,当 empty 不为 0 时,生产者才可以放入物品;full 信号量是在消费者进程中使用,当 full 信号量不为 0 时,消费者才可以取走物品。
注意,不能先对缓冲区进行加锁,再测试信号量。也就是说,不能先执行 down(mutex) 再执行 down(empty)。如果这么做了,那么可能会出现这种情况:生产者对缓冲区加锁后,执行 down(empty) 操作,发现 empty = 0,此时生产者睡眠。消费者不能进入临界区,因为生产者对缓冲区加锁了,消费者就无法执行 up(empty) 操作,empty 永远都为 0,导致生产者永远等待下,不会释放锁,消费者因此也会永远等待下去。
#define N 100
typedef int semaphore;
semaphore mutex = 1;
semaphore empty = N;
semaphore full = 0;
void producer() {
while(TRUE) {
int item = produce_item();
down(&empty);
down(&mutex);
insert_item(item);
up(&mutex);
up(&full);
}
}
void consumer() {
while(TRUE) {
down(&full);
down(&mutex);
int item = remove_item();
consume_item(item);
up(&mutex);
up(&empty);
}
}4. 管程
使用信号量机制实现的生产者消费者问题需要客户端代码做很多控制,而管程把控制的代码独立出来,不仅不容易出错,也使得客户端代码调用更容易。
c 语言不支持管程,下面的示例代码使用了类 Pascal 语言来描述管程。示例代码的管程提供了 insert() 和 remove() 方法,客户端代码通过调用这两个方法来解决生产者-消费者问题。
monitor ProducerConsumer
integer i;
condition c;
procedure insert();
begin
// ...
end;
procedure remove();
begin
// ...
end;
end monitor;管程有一个重要特性:在一个时刻只能有一个进程使用管程。进程在无法继续执行的时候不能一直占用管程,否则其它进程永远不能使用管程。
管程引入了 条件变量 以及相关的操作:wait() 和 signal() 来实现同步操作。对条件变量执行 wait() 操作会导致调用进程阻塞,把管程让出来给另一个进程持有。signal() 操作用于唤醒被阻塞的进程。
使用管程实现生产者-消费者问题
// 管程
monitor ProducerConsumer
condition full, empty;
integer count := 0;
condition c;
procedure insert(item: integer);
begin
if count = N then wait(full);
insert_item(item);
count := count + 1;
if count = 1 then signal(empty);
end;
function remove: integer;
begin
if count = 0 then wait(empty);
remove = remove_item;
count := count - 1;
if count = N -1 then signal(full);
end;
end monitor;
// 生产者客户端
procedure producer
begin
while true do
begin
item = produce_item;
ProducerConsumer.insert(item);
end
end;
// 消费者客户端
procedure consumer
begin
while true do
begin
item = ProducerConsumer.remove;
consume_item(item);
end
end;经典同步问题
生产者和消费者问题前面已经讨论过了。
1. 哲学家进餐问题
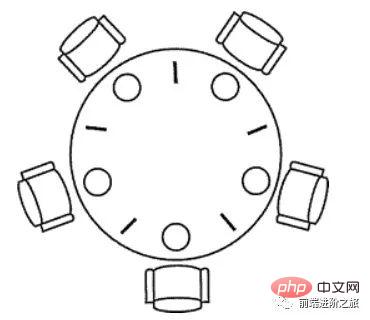
五个哲学家围着一张圆桌,每个哲学家面前放着食物。哲学家的生活有两种交替活动:吃饭以及思考。当一个哲学家吃饭时,需要先拿起自己左右两边的两根筷子,并且一次只能拿起一根筷子。
下面是一种错误的解法,如果所有哲学家同时拿起左手边的筷子,那么所有哲学家都在等待其它哲学家吃完并释放自己手中的筷子,导致死锁。
#define N 5
void philosopher(int i) {
while(TRUE) {
think();
take(i); // 拿起左边的筷子
take((i+1)%N); // 拿起右边的筷子
eat();
put(i);
put((i+1)%N);
}
}为了防止死锁的发生,可以设置两个条件:
必须同时拿起左右两根筷子;
只有在两个邻居都没有进餐的情况下才允许进餐。
#define N 5
#define LEFT (i + N - 1) % N // 左邻居
#define RIGHT (i + 1) % N // 右邻居
#define THINKING 0
#define HUNGRY 1
#define EATING 2
typedef int semaphore;
int state[N]; // 跟踪每个哲学家的状态
semaphore mutex = 1; // 临界区的互斥,临界区是 state 数组,对其修改需要互斥
semaphore s[N]; // 每个哲学家一个信号量
void philosopher(int i) {
while(TRUE) {
think(i);
take_two(i);
eat(i);
put_two(i);
}
}
void take_two(int i) {
down(&mutex);
state[i] = HUNGRY;
check(i);
up(&mutex);
down(&s[i]); // 只有收到通知之后才可以开始吃,否则会一直等下去
}
void put_two(i) {
down(&mutex);
state[i] = THINKING;
check(LEFT); // 尝试通知左右邻居,自己吃完了,你们可以开始吃了
check(RIGHT);
up(&mutex);
}
void eat(int i) {
down(&mutex);
state[i] = EATING;
up(&mutex);
}
// 检查两个邻居是否都没有用餐,如果是的话,就 up(&s[i]),使得 down(&s[i]) 能够得到通知并继续执行
void check(i) {
if(state[i] == HUNGRY && state[LEFT] != EATING && state[RIGHT] !=EATING) {
state[i] = EATING;
up(&s[i]);
}
}2. 读者-写者问题
允许多个进程同时对数据进行读操作,但是不允许读和写以及写和写操作同时发生。另外,搜索公众号顶级算法后台回复“算法”,获取一份惊喜礼包。
一个整型变量 count 记录在对数据进行读操作的进程数量,一个互斥量 count_mutex 用于对 count 加锁,一个互斥量 data_mutex 用于对读写的数据加锁。
typedef int semaphore;
semaphore count_mutex = 1;
semaphore data_mutex = 1;
int count = 0;
void reader() {
while(TRUE) {
down(&count_mutex);
count++;
if(count == 1) down(&data_mutex); // 第一个读者需要对数据进行加锁,防止写进程访问
up(&count_mutex);
read();
down(&count_mutex);
count--;
if(count == 0) up(&data_mutex);
up(&count_mutex);
}
}
void writer() {
while(TRUE) {
down(&data_mutex);
write();
up(&data_mutex);
}
}以下内容由 @Bandi Yugandhar 提供。
The first case may result Writer to starve. This case favous Writers i.e no writer, once added to the queue, shall be kept waiting longer than absolutely necessary(only when there are readers that entered the queue before the writer).
int readcount, writecount; //(initial value = 0)
semaphore rmutex, wmutex, readLock, resource; //(initial value = 1)
//READER
void reader() {
<ENTRY Section>
down(&readLock); // reader is trying to enter
down(&rmutex); // lock to increase readcount
readcount++;
if (readcount == 1)
down(&resource); //if you are the first reader then lock the resource
up(&rmutex); //release for other readers
up(&readLock); //Done with trying to access the resource
<CRITICAL Section>
//reading is performed
<EXIT Section>
down(&rmutex); //reserve exit section - avoids race condition with readers
readcount--; //indicate you're leaving
if (readcount == 0) //checks if you are last reader leaving
up(&resource); //if last, you must release the locked resource
up(&rmutex); //release exit section for other readers
}
//WRITER
void writer() {
<ENTRY Section>
down(&wmutex); //reserve entry section for writers - avoids race conditions
writecount++; //report yourself as a writer entering
if (writecount == 1) //checks if you're first writer
down(&readLock); //if you're first, then you must lock the readers out. Prevent them from trying to enter CS
up(&wmutex); //release entry section
<CRITICAL Section>
down(&resource); //reserve the resource for yourself - prevents other writers from simultaneously editing the shared resource
//writing is performed
up(&resource); //release file
<EXIT Section>
down(&wmutex); //reserve exit section
writecount--; //indicate you're leaving
if (writecount == 0) //checks if you're the last writer
up(&readLock); //if you're last writer, you must unlock the readers. Allows them to try enter CS for reading
up(&wmutex); //release exit section
}We can observe that every reader is forced to acquire ReadLock. On the otherhand, writers doesn’t need to lock individually. Once the first writer locks the ReadLock, it will be released only when there is no writer left in the queue.
From the both cases we observed that either reader or writer has to starve. Below solutionadds the constraint that no thread shall be allowed to starve; that is, the operation of obtaining a lock on the shared data will always terminate in a bounded amount of time.
int readCount; // init to 0; number of readers currently accessing resource
// all semaphores initialised to 1
Semaphore resourceAccess; // controls access (read/write) to the resource
Semaphore readCountAccess; // for syncing changes to shared variable readCount
Semaphore serviceQueue; // FAIRNESS: preserves ordering of requests (signaling must be FIFO)
void writer()
{
down(&serviceQueue); // wait in line to be servicexs
// <ENTER>
down(&resourceAccess); // request exclusive access to resource
// </ENTER>
up(&serviceQueue); // let next in line be serviced
// <WRITE>
writeResource(); // writing is performed
// </WRITE>
// <EXIT>
up(&resourceAccess); // release resource access for next reader/writer
// </EXIT>
}
void reader()
{
down(&serviceQueue); // wait in line to be serviced
down(&readCountAccess); // request exclusive access to readCount
// <ENTER>
if (readCount == 0) // if there are no readers already reading:
down(&resourceAccess); // request resource access for readers (writers blocked)
readCount++; // update count of active readers
// </ENTER>
up(&serviceQueue); // let next in line be serviced
up(&readCountAccess); // release access to readCount
// <READ>
readResource(); // reading is performed
// </READ>
down(&readCountAccess); // request exclusive access to readCount
// <EXIT>
readCount--; // update count of active readers
if (readCount == 0) // if there are no readers left:
up(&resourceAccess); // release resource access for all
// </EXIT>
up(&readCountAccess); // release access to readCount
}进程通信
进程同步与进程通信很容易混淆,它们的区别在于:
进程同步:控制多个进程按一定顺序执行;
进程通信:进程间传输信息。
进程通信是一种手段,而进程同步是一种目的。也可以说,为了能够达到进程同步的目的,需要让进程进行通信,传输一些进程同步所需要的信息。
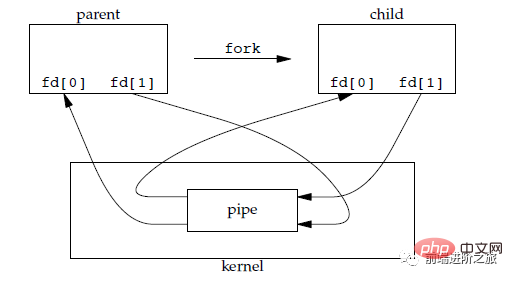
1. 管道
管道是通过调用 pipe 函数创建的,fd[0] 用于读,fd[1] 用于写。
#include <unistd.h> int pipe(int fd[2]);
它具有以下限制:
只支持半双工通信(单向交替传输);
只能在父子进程或者兄弟进程中使用。
2. FIFO
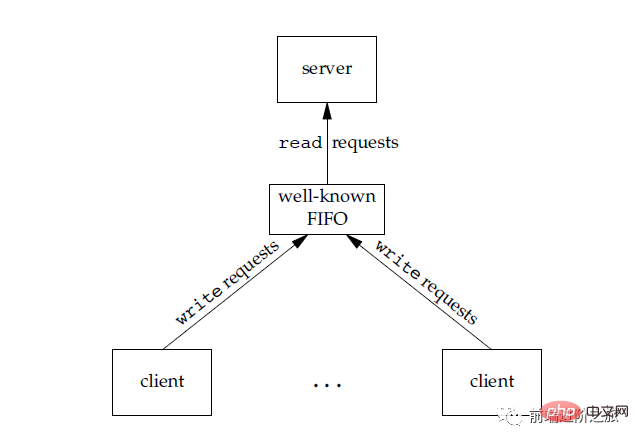
也称为命名管道,去除了管道只能在父子进程中使用的限制。
#include <sys/stat.h> int mkfifo(const char *path, mode_t mode); int mkfifoat(int fd, const char *path, mode_t mode);
FIFO 常用于客户-服务器应用程序中,FIFO 用作汇聚点,在客户进程和服务器进程之间传递数据。
3. Nachrichtenwarteschlange
Im Vergleich zu FIFO hat die Nachrichtenwarteschlange die folgenden Vorteile:
Nachrichtenwarteschlange kann unabhängig von den Lese- und Schreibvorgängen existieren, wodurch das Öffnen und Schließen der Synchronisierung vermieden wird Pipes im FIFO Mögliche Schwierigkeiten beim Schließen;
vermeidet das Synchronisationsblockierungsproblem von FIFO und erfordert nicht, dass der Prozess selbst Synchronisationsmethoden bereitstellt;
Der Leseprozess kann selektiv Nachrichten entsprechend der Nachricht empfangen Im Gegensatz zu FIFO kann der Typ standardmäßig nur empfangen.
4. Semaphor
Es ist ein Zähler, der mehreren Prozessen den Zugriff auf gemeinsam genutzte Datenobjekte ermöglicht.
5. Gemeinsamer Speicher
ermöglicht mehreren Prozessen die gemeinsame Nutzung eines bestimmten Speicherbereichs. Da Daten nicht zwischen Prozessen kopiert werden müssen, ist dies der schnellste IPC-Typ.
Sie müssen ein Semaphor verwenden, um den Zugriff auf den gemeinsam genutzten Speicher zu synchronisieren.
Mehrere Prozesse können dieselbe Datei ihrem Adressraum zuordnen, um einen gemeinsamen Speicher zu erreichen. Darüber hinaus verwendet der gemeinsam genutzte XSI-Speicher keine Dateien, sondern anonyme Speichersegmente.
6. Sockel
Im Gegensatz zu anderen Kommunikationsmechanismen kann es für die Prozesskommunikation zwischen verschiedenen Maschinen verwendet werden.
3. Speicherverwaltung
Virtueller Speicher
Der Zweck des virtuellen Speichers besteht darin, den physischen Speicher in einen größeren logischen Speicher zu erweitern, damit das Programm mehr verfügbaren Speicher erhalten kann.
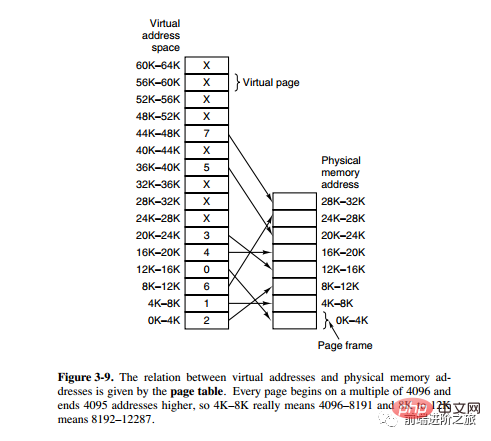
Um den Speicher besser verwalten zu können, abstrahiert das Betriebssystem Speicher in einen Adressraum. Jedes Programm verfügt über einen eigenen Adressraum, der in mehrere Blöcke unterteilt ist. Jeder Block wird als Seite bezeichnet. Die Seiten werden im physischen Speicher abgebildet, müssen aber nicht in zusammenhängenden physischen Speicher abgebildet werden, noch müssen sich alle Seiten im physischen Speicher befinden. Wenn ein Programm auf eine Seite verweist, die sich nicht im physischen Speicher befindet, führt die Hardware die erforderliche Zuordnung durch, lädt den fehlenden Teil in den physischen Speicher und führt die fehlgeschlagene Anweisung erneut aus.
Wie aus der obigen Beschreibung ersichtlich ist, ermöglicht der virtuelle Speicher dem Programm, nicht jede Seite im Adressraum dem physischen Speicher zuzuordnen, was bedeutet, dass ein Programm zum Ausführen nicht in den Speicher geladen werden muss, was die Einschränkung zur Folge hat Speicher Es ist möglich, große Programme auszuführen. Wenn ein Computer beispielsweise 16-Bit-Adressen generieren kann, beträgt der Adressraumbereich eines Programms 0 bis 64 KB. Der Computer verfügt nur über 32 KB physischen Speicher und die virtuelle Speichertechnologie ermöglicht es dem Computer, ein 64 KB großes Programm auszuführen.
Paging-System-Adresszuordnung
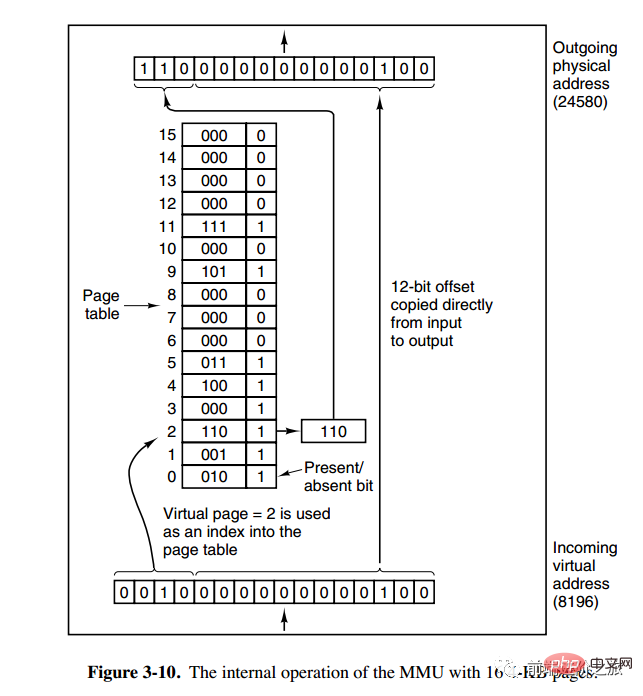
Die Speicherverwaltungseinheit (MMU) verwaltet die Konvertierung von Adressraum und physischem Speicher, und die Seitentabelle (Seitentabelle) speichert Seiten (Programmadressraum) und Seitenrahmen (physischer Speicherplatz) Zuordnungstabelle.
Eine virtuelle Adresse ist in zwei Teile unterteilt, ein Teil speichert die Seitennummer und der andere Teil speichert den Offset.
下图的页表存放着 16 个页,这 16 个页需要用 4 个比特位来进行索引定位。例如对于虚拟地址(0010 000000000100),前 4 位是存储页面号 2,读取表项内容为(110 1),页表项最后一位表示是否存在于内存中,1 表示存在。后 12 位存储偏移量。这个页对应的页框的地址为 (110 000000000100)。
页面置换算法
在程序运行过程中,如果要访问的页面不在内存中,就发生缺页中断从而将该页调入内存中。此时如果内存已无空闲空间,系统必须从内存中调出一个页面到磁盘对换区中来腾出空间。
页面置换算法和缓存淘汰策略类似,可以将内存看成磁盘的缓存。在缓存系统中,缓存的大小有限,当有新的缓存到达时,需要淘汰一部分已经存在的缓存,这样才有空间存放新的缓存数据。
页面置换算法的主要目标是使页面置换频率最低(也可以说缺页率最低)。
1. 最佳
OPT, Optimal replacement algorithm
所选择的被换出的页面将是最长时间内不再被访问,通常可以保证获得最低的缺页率。
是一种理论上的算法,因为无法知道一个页面多长时间不再被访问。
举例:一个系统为某进程分配了三个物理块,并有如下页面引用序列:
7,0,1,2,0,3,0,4,2,3,0,3,2,1,2,0,1,7,0,1
开始运行时,先将 7, 0, 1 三个页面装入内存。当进程要访问页面 2 时,产生缺页中断,会将页面 7 换出,因为页面 7 再次被访问的时间最长。
2. 最近最久未使用
LRU, Least Recently Used
虽然无法知道将来要使用的页面情况,但是可以知道过去使用页面的情况。LRU 将最近最久未使用的页面换出。
为了实现 LRU,需要在内存中维护一个所有页面的链表。当一个页面被访问时,将这个页面移到链表表头。这样就能保证链表表尾的页面是最近最久未访问的。
因为每次访问都需要更新链表,因此这种方式实现的 LRU 代价很高。
4,7,0,7,1,0,1,2,1,2,6
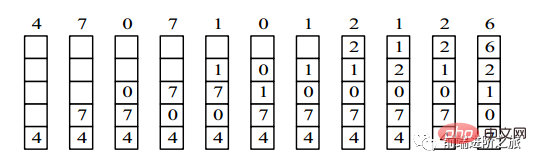
3. 最近未使用
NRU, Not Recently Used
每个页面都有两个状态位:R 与 M,当页面被访问时设置页面的 R=1,当页面被修改时设置 M=1。其中 R 位会定时被清零。可以将页面分成以下四类:
R=0,M=0 R=0,M=1 R=1,M=0 R=1,M=1
当发生缺页中断时,NRU 算法随机地从类编号最小的非空类中挑选一个页面将它换出。
NRU 优先换出已经被修改的脏页面(R=0,M=1),而不是被频繁使用的干净页面(R=1,M=0)。
4. First in, first out
FIFO, First In First Out
Die zum Austausch ausgewählte Seite ist die zuerst eingegebene Seite.
Dieser Algorithmus tauscht häufig aufgerufene Seiten aus, was zu einem Anstieg der Seitenfehlerrate führt.
5. Der Algorithmus der zweiten Chance
Der FIFO-Algorithmus kann häufig verwendete Seiten ersetzen. Um dieses Problem zu vermeiden, nehmen Sie eine einfache Änderung am Algorithmus vor:
Wenn auf die Seite zugegriffen wird (gelesen oder geschrieben), legen Sie fest R-Bit der Seite auf 1. Wenn ein Austausch erforderlich ist, überprüfen Sie das R-Bit der ältesten Seite. Wenn das R-Bit 0 ist, ist die Seite alt und unbenutzt und kann sofort ersetzt werden. Wenn es 1 ist, setzen Sie das R-Bit auf 0, setzen Sie die Seite an das Ende der verknüpften Liste und ändern Sie ihre Ladezeit so Es verhält sich so, als wäre es gerade erst geladen worden, und setzt die Suche vom Kopf der Liste aus fort.

6. Uhr
Uhr
Der Algorithmus der zweiten Chance muss Seiten in der verknüpften Liste verschieben, was die Effizienz verringert. Der Uhralgorithmus verwendet eine zirkulär verknüpfte Liste, um Seiten zu verbinden, und verwendet dann einen Zeiger, um auf die älteste Seite zu zeigen.
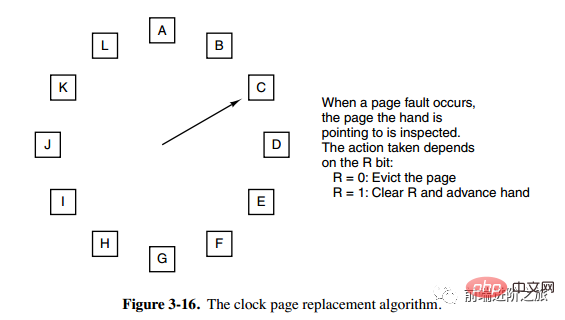
Segmentierung
Der virtuelle Speicher verwendet Paging-Technologie, was bedeutet, dass der Adressraum in Seiten fester Größe unterteilt wird und jede Seite dem Speicher zugeordnet wird.
Das Bild unten zeigt mehrere Tabellen, die von einem Compiler während des Kompilierungsprozesses erstellt wurden. Vier der Tabellen wachsen dynamisch. Wenn der eindimensionale Adressraum des Paging-Systems verwendet wird, führen die dynamischen Wachstumseigenschaften zu Abdeckungsproblemen.
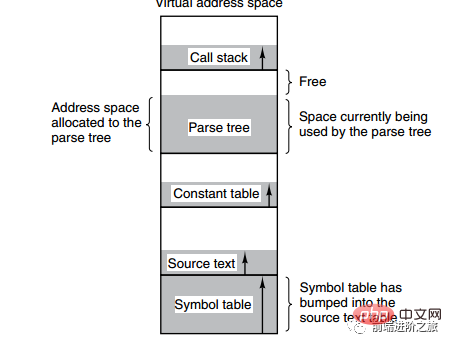
Die Segmentierungsmethode besteht darin, jede Tabelle in Segmente zu unterteilen, und jedes Segment bildet einen unabhängigen Adressraum. Jedes Segment kann unterschiedlich lang sein und dynamisch wachsen.
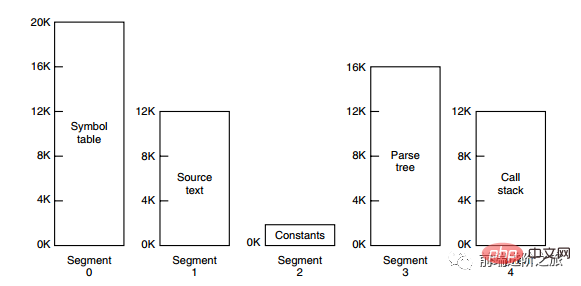
Segment-Paging
Der Adressraum des Programms ist in mehrere Segmente mit unabhängigen Adressräumen unterteilt, und der Adressraum in jedem Segment ist in Seiten gleicher Größe unterteilt. Dies umfasst nicht nur die gemeinsame Nutzung und den Schutz des segmentierten Systems, sondern auch die virtuelle Speicherfunktion des Paging-Systems.
Vergleich von Paging und Segmentierung
Transparenz für Programmierer: Paging ist transparent, aber die Segmentierung erfordert, dass der Programmierer jedes Segment explizit unterteilt.
Abmessungen des Adressraums: Paging ist ein eindimensionaler Adressraum und die Segmentierung ist zweidimensional.
Ob die Größe geändert werden kann: Die Größe der Seite ist unveränderlich und die Größe des Segments kann dynamisch geändert werden.
Gründe für das Erscheinen: Paging wird hauptsächlich zur Implementierung des virtuellen Speichers verwendet, um einen größeren Adressraum zu erhalten. Die Segmentierung dient hauptsächlich dazu, Programme und Daten in logisch unabhängige Adressräume aufzuteilen und die gemeinsame Nutzung und den Schutz zu erleichtern.
4. Geräteverwaltung
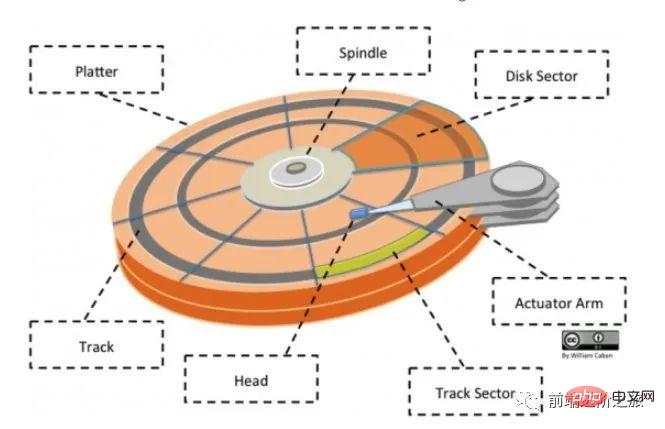
Festplattenstruktur
Platte: Eine Festplatte hat mehrere Festplatten;
Spur: Ein Kreis auf der Festplatte. Ein Streifenbereich, eine Festplatte kann mehrere Spuren haben;
Spursektor: ein Bogensegment auf einer Spur, eine Spur kann mehrere Sektoren haben, es ist die kleinste physische Speichereinheit, derzeit hauptsächlich in zwei Größen erhältlich: 512 Bytes und 4 K;
- Kopf: sehr nahe an der Plattenoberfläche, in der Lage, das Magnetfeld auf der Plattenoberfläche in elektrische Signale umzuwandeln (Lesen) oder elektrische Signale in das Magnetfeld auf der Plattenoberfläche umzuwandeln (Schreiben); Wenn Sie nach dem öffentlichen Konto Linux suchen, sollten Sie auf diese Weise lernen, im Hintergrund auf „Linux“ zu antworten, um ein Überraschungsgeschenkpaket zu erhalten.
- Betätigungsarm: wird verwendet, um den Magnetkopf zwischen den Spuren zu bewegen
Spindel: Lässt die gesamte Scheibe rotieren.
Festplattenplanungsalgorithmus
Die Faktoren, die die Zeit zum Lesen und Schreiben eines Plattenblocks beeinflussen, sind:
Rotationszeit (die Spindel dreht die Plattenoberfläche, um den Kopf zu bewegen zum entsprechenden Sektor) )
Suchzeit (Bremsarmbewegung, wodurch sich der Kopf auf die entsprechende Spur bewegt)
Tatsächliche Datenübertragungszeit
Unter ihnen ist die Suchzeit Das Hauptziel der Festplattenplanung besteht darin, die durchschnittliche Festplattensuchzeit zu minimieren.
1. Wer zuerst kommt, mahlt zuerst
FCFS, First Come First Served
Die Planung erfolgt in der Reihenfolge der Festplattenanforderungen.
Die Vorteile sind Fairness und Einfachheit. Der Nachteil liegt ebenfalls auf der Hand, da die Suche nicht optimiert wurde und die durchschnittliche Suchzeit daher möglicherweise länger ist.
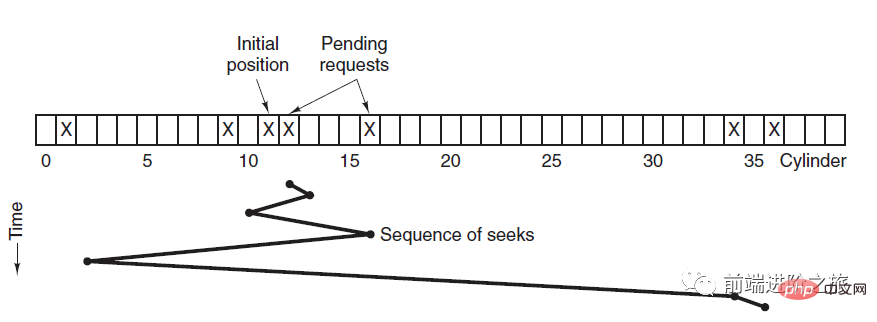
2. Kürzeste Suchzeit zuerst
SSTF, kürzeste Suchzeit zuerst
priorisiert die Planung der Spur, die der Spur am nächsten liegt, auf der sich der aktuelle Kopf befindet.
Obwohl die durchschnittliche Suchzeit relativ gering ist, ist sie nicht fair genug. Wenn eine neu eingetroffene Track-Anfrage immer näher ist als eine wartende Track-Anfrage, dann wird die wartende Track-Anfrage ewig warten, d. h. es kommt zu einer Hungersnot. Insbesondere sind Track-Anfragen an beiden Enden anfälliger für Hunger. Sehen Sie sich dieses Fernbedienungssystem an, es ist so elegant (Quellcode beigefügt)!
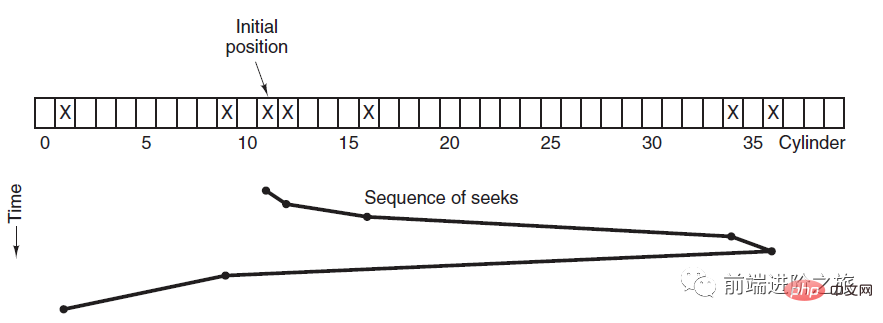
3. Aufzugsalgorithmus
SCAN
Der Aufzug fährt immer in eine Richtung, bis keine Anforderung mehr in diese Richtung vorliegt, und ändert dann die Fahrtrichtung.
Der Aufzugsalgorithmus (Scan-Algorithmus) ähnelt dem Betriebsprozess eines Aufzugs. Er plant immer Festplatten in eine Richtung, bis keine ausstehenden Festplattenanforderungen in diese Richtung vorliegen, und ändert dann die Richtung.
Da die Bewegungsrichtung berücksichtigt wird, werden alle Festplattenanforderungen erfüllt, wodurch das Hungerproblem von SSTF gelöst wird.
五、链接
编译系统
以下是一个 hello.c 程序:
#include <stdio.h>
int main()
{
printf("hello, world\n");
return 0;
}在 Unix 系统上,由编译器把源文件转换为目标文件。
gcc -o hello hello.c
这个过程大致如下:

预处理阶段:处理以 # 开头的预处理命令;
编译阶段:翻译成汇编文件;
汇编阶段:将汇编文件翻译成可重定位目标文件;
链接阶段:将可重定位目标文件和 printf.o 等单独预编译好的目标文件进行合并,得到最终的可执行目标文件。
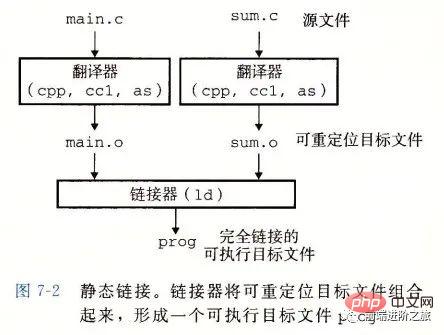
静态链接
静态链接器以一组可重定位目标文件为输入,生成一个完全链接的可执行目标文件作为输出。链接器主要完成以下两个任务:
Symbolauflösung: Jedes Symbol entspricht einer Funktion, einer globalen Variablen oder einer statischen Variablen. Der Zweck der Symbolauflösung besteht darin, jede Symbolreferenz einer Symboldefinition zuzuordnen.
Relocation: Der Linker ordnet jede Symboldefinition einem Speicherort zu und ändert dann alle Verweise auf diese Symbole so, dass sie auf diesen Speicherort verweisen.
Zieldatei
Ausführbare Zieldatei: kann direkt im Speicher ausgeführt werden;
Verschiebbare Zieldatei: kann mit anderen kombiniert werden verschiebbare Ziele Dateien werden zusammengeführt während der Verknüpfungsphase, um eine ausführbare Objektdatei zu erstellen;
Gemeinsam genutzte Objektdatei: Dies ist eine spezielle verschiebbare Objektdatei, die zur Laufzeit dynamisch geladen und verknüpft werden kann;
Dynamische Verknüpfung
Statische Bibliotheken haben die folgenden zwei Probleme:
- Wenn die statische Bibliothek aktualisiert wird, muss das gesamte Programm neu verknüpft werden
Wenn für eine Standardfunktionsbibliothek wie printf jedes Programm Code benötigen würde, wäre das eine enorme Ressourcenverschwendung.
Freigegebene Bibliotheken sollen diese beiden Probleme statischer Bibliotheken lösen. Sie werden auf Linux-Systemen normalerweise durch das Suffix .so dargestellt und auf Windows-Systemen als DLLs bezeichnet. Es weist die folgenden Merkmale auf:
Es gibt nur eine Datei für eine Bibliothek in einem bestimmten Dateisystem. Diese Datei wird von allen ausführbaren Objektdateien gemeinsam genutzt, die auf die Bibliothek verweisen. Sie wird nicht in die ausführbaren Dateien kopiert, auf die verwiesen wird ;
Im Speicher kann eine Kopie des .text-Abschnitts einer gemeinsam genutzten Bibliothek (der Maschinencode des kompilierten Programms) von verschiedenen laufenden Prozessen gemeinsam genutzt werden.
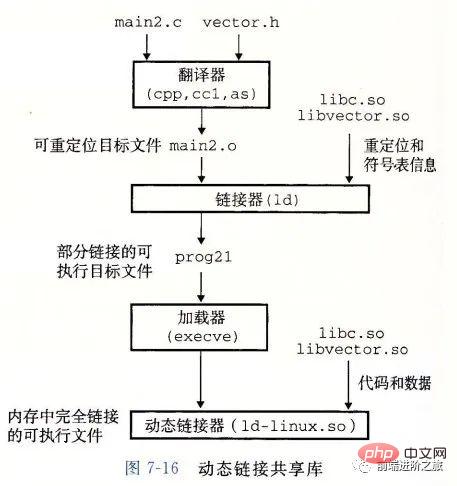
6. Deadlock
Notwendige Bedingungen
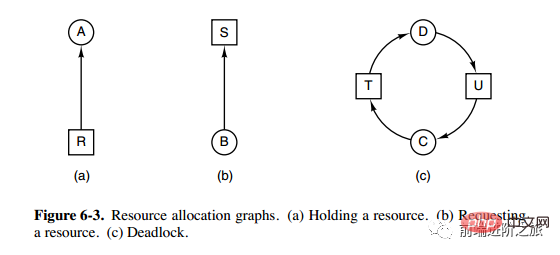
Gegenseitiger Ausschluss: Jede Ressource ist entweder bereits einem Prozess zugeordnet oder steht zur Verfügung.
Besetzen und warten: Ein Prozess, der bereits eine Ressource erhalten hat, kann eine neue Ressource anfordern.
Nicht präemptiv: Eine Ressource, die einem Prozess zugewiesen wurde, kann nicht zwangsweise präemptiviert werden, sie kann nur explizit von dem Prozess freigegeben werden, der sie belegt.
Schleifenwartezeit: Es gibt zwei oder mehr Prozesse, die eine Schleife bilden, und jeder Prozess in der Schleife wartet auf die vom nächsten Prozess belegten Ressourcen.
Verarbeitungsmethoden
Es gibt hauptsächlich vier Methoden:
Straußenstrategie
Deadlock-Erkennung und Deadlock-Wiederherstellung
-
Deadlock-Prävention
Deadlock Vermeidung
Strauß-Strategie
Verstecken Sie Ihren Kopf in den Sand und tun Sie so, als gäbe es überhaupt kein Problem.
Da die Kosten für die Lösung des Deadlock-Problems sehr hoch sind, erzielt die Straußstrategie, bei der keine Aufgabenmaßnahmen ergriffen werden, eine höhere Leistung.
Wenn ein Deadlock auftritt, hat er keine großen Auswirkungen auf die Benutzer oder die Wahrscheinlichkeit eines Deadlocks ist sehr gering. Sie können die Straußstrategie verwenden.
Die meisten Betriebssysteme, einschließlich Unix, Linux und Windows, lösen das Deadlock-Problem einfach dadurch, dass sie es ignorieren.
Deadlock-Erkennung und Deadlock-Wiederherstellung
versucht nicht, Deadlocks zu verhindern, sondern ergreift Maßnahmen zur Wiederherstellung, wenn ein Deadlock erkannt wird.
1. Deadlock-Erkennung einer Ressource jedes Typs
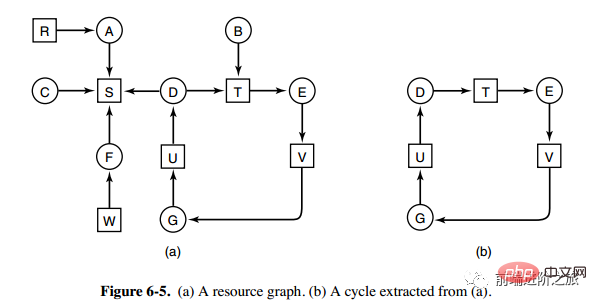
Das obige Bild ist ein Ressourcenzuordnungsdiagramm, in dem die Kästchen Ressourcen und die Kreise Prozesse darstellen. Die Ressource, die auf den Prozess zeigt, bedeutet, dass die Ressource dem Prozess zugewiesen wurde, und der Prozess, der auf die Ressource zeigt, bedeutet, dass der Prozess den Erhalt der Ressource anfordert.
Die Schleife kann aus Abbildung a extrahiert werden, wie in Abbildung b gezeigt, wodurch die Schleifenwartebedingung erfüllt wird, sodass ein Deadlock auftritt.
Der Deadlock-Erkennungsalgorithmus für jeden Ressourcentyp wird implementiert, indem er erkennt, ob ein Zyklus im gerichteten Diagramm vorhanden ist, ausgehend von einem Knoten, eine Tiefensuche durchführt und die besuchten Knoten markiert. Zeigt an, dass im gerichteten Diagramm ein Zyklus vorhanden ist, d. h. das Auftreten eines Deadlocks wird erkannt.
2. Deadlock-Erkennung für mehrere Ressourcen jedes Typs

Im Bild oben gibt es drei Prozesse und vier Ressourcen. Die Bedeutung der einzelnen Daten ist wie folgt:
E-Vektor: Gesamtmenge an Ressourcen
A-Vektor: verbleibende Menge an Ressourcen
-
C-Matrix: Die Anzahl der Ressourcen, die jeder Prozess besitzt. R-Matrix: Die Anzahl der von jedem Prozess angeforderten Ressourcen Die Ressourcen sind erfüllt. Nur der Prozess P3 kann P3 ausführen lassen und dann die Ressourcen freigeben, die P3 gehören. Zu diesem Zeitpunkt ist A = (2 2 0). P2 kann ausgeführt werden und die Ressourcen von P2 werden nach der Ausführung freigegeben, A = (4 2 2 1). P1 kann auch ausgeführt werden. Alle Prozesse laufen reibungslos und ohne Deadlocks ab.
Der Algorithmus lässt sich wie folgt zusammenfassen: - Jeder Prozess ist zu Beginn nicht markiert, und der Ausführungsprozess kann markiert sein. Wenn der Algorithmus endet, ist jeder Prozess, der nicht markiert ist, ein blockierter Prozess.
Suchen Sie nach einem nicht markierten Prozess Pi, dessen angeforderte Ressource kleiner oder gleich A ist.
Wenn ein solcher Prozess gefunden wird, fügen Sie den i-ten Zeilenvektor der C-Matrix zu A hinzu, markieren Sie den Prozess und wechseln Sie zurück zu 1.
3. Deadlock-Recovery
Preemption-Recovery verwenden
Rollback-Recovery nutzen
Recovery by Killing Process
Deadlock-Prävention
Deadlocks verhindern, bevor das Programm ausgeführt wird.
1. Gegenseitige Ausschlussbedingungen brechen
Zum Beispiel ermöglicht die Spool-Druckertechnologie die gleichzeitige Ausgabe mehrerer Prozesse, und der einzige Prozess, der tatsächlich einen physischen Drucker anfordert, ist der Druckerdämon.
2. Besitzvernichtung und Wartebedingungen
Eine Möglichkeit, dies zu erreichen, besteht darin, festzulegen, dass alle Prozesse alle erforderlichen Ressourcen anfordern, bevor mit der Ausführung begonnen wird.
3. Zerstöre die nicht präventive Bedingung
4. Zerstöre die Warteschleife
Ressourcen einheitlich nummerieren, und Prozesse können Ressourcen nur in numerischer Reihenfolge anfordern.
Vermeidung von Deadlocks
Vermeiden Sie Deadlocks, während das Programm ausgeführt wird.
1. Sicherheitsstatus
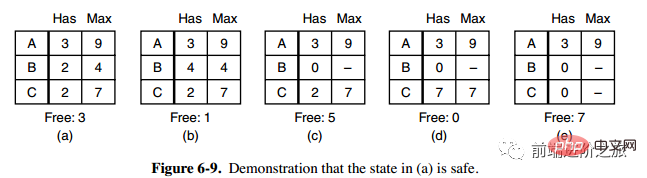
Die zweite Spalte „Has“ in Abbildung a stellt die Anzahl der bereits vorhandenen Ressourcen dar, die dritte Spalte „Max“ stellt die Gesamtzahl der erforderlichen Ressourcen dar und „Frei“ stellt die Anzahl der Ressourcen dar, die verwendet werden können. Beginnen Sie mit Bild a und lassen Sie B zunächst über alle benötigten Ressourcen verfügen (Bild b). Lassen Sie B frei. Zu diesem Zeitpunkt wird Free zu 5 (Bild c). Damit alle Prozesse beide erfolgreich ausgeführt werden können, kann der in Abbildung a gezeigte Zustand als sicher bezeichnet werden.
Definition: Wenn kein Deadlock auftritt und selbst wenn alle Prozesse plötzlich den maximalen Ressourcenbedarf anfordern, es immer noch eine Planungsreihenfolge gibt, die es jedem Prozess ermöglicht, bis zum Abschluss ausgeführt zu werden, wird der Zustand als sicher bezeichnet.
Die Erkennung eines sicheren Zustands ähnelt der Erkennung eines Deadlocks, da der sichere Zustand erfordern muss, dass kein Deadlock auftreten kann. Der folgende Banker-Algorithmus ist dem Deadlock-Erkennungsalgorithmus sehr ähnlich und kann zu Referenz- und Vergleichszwecken kombiniert werden.
2. Banker-Algorithmus für eine einzelne Ressource
Ein Banker in einer Kleinstadt hat einer Gruppe von Kunden jeweils einen bestimmten Betrag versprochen. Der Algorithmus muss ermitteln, ob die Anfrage erfüllt wird Geben Sie einen unsicheren Zustand ein. Wenn ja, lehnen Sie die Anfrage ab.
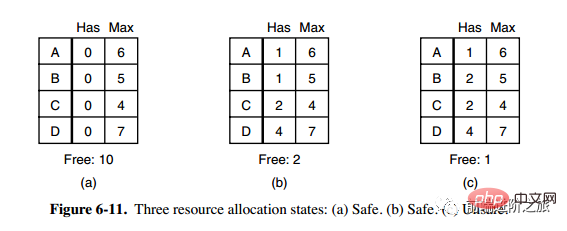
C in der obigen Abbildung ist ein unsicherer Zustand, daher lehnt der Algorithmus die vorherige Anfrage ab, um den Eintritt in den Zustand in Abbildung c zu vermeiden.
3. Banker-Algorithmus für mehrere Ressourcen
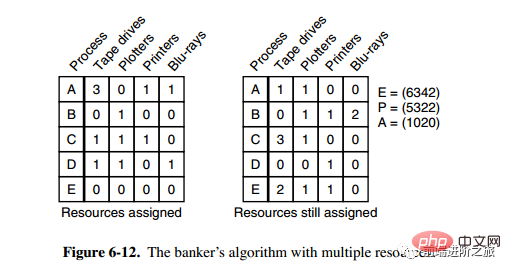
Das obige Bild zeigt fünf Prozesse und vier Ressourcen. Das Bild links stellt die Ressourcen dar, die zugewiesen wurden, und das Bild rechts stellt die Ressourcen dar, die noch zugewiesen werden müssen. Das ganz rechte E, P und A stellen jeweils die Gesamtressourcen, die zugewiesenen Ressourcen und die verfügbaren Ressourcen dar. Beachten Sie, dass es sich bei diesen drei um Vektoren und nicht um spezifische Werte handelt links bzw. 0/2/0.
Der Algorithmus zur Überprüfung, ob ein Zustand sicher ist, lautet wie folgt:
Finden Sie heraus, ob es in der rechten Matrix eine Zeile gibt, die kleiner oder gleich Vektor A ist. Wenn keine solche Zeile vorhanden ist, gerät das System in einen Deadlock und der Zustand ist unsicher.
Wenn eine solche Zeile gefunden wird, markieren Sie den Prozess als beendet und fügen Sie die zugewiesenen Ressourcen zu A hinzu.
Wiederholen Sie die beiden oben genannten Schritte, bis alle Prozesse als beendet markiert sind, dann ist der Status sicher.
Wenn ein Staat nicht sicher ist, müssen Sie die Einreise in diesen Staat verweigern.
Das obige ist der detaillierte Inhalt von30 Bilder mit detaillierter Zusammenfassung des Betriebssystems!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was sind die Hauptfunktionen eines Computer-Betriebssystems?
- Was sind die Grundfunktionen eines Betriebssystems?
- Zu welchem System gehört das Windows-Betriebssystem?
- Auf einem bestimmten Mikrocomputer ist ein 64-Bit-Betriebssystem installiert. Was bedeutet 64-Bit?
- Was ist in einem Computersystem ein Betriebssystem?