
Heim >Betrieb und Instandhaltung >Betrieb und Wartung von Linux >Ideen zur Fehlerbehebung bei Linux-Betrieb und -Wartung, dieser Artikel reicht aus ~
Ideen zur Fehlerbehebung bei Linux-Betrieb und -Wartung, dieser Artikel reicht aus ~
- Linux中文社区nach vorne
- 2023-08-02 15:29:061240Durchsuche
1. Hintergrund
Manchmal stoßen Sie auf einige schwierige und komplizierte Krankheiten, und das Überwachungs-Plug-in kann die Grundursache des Problems nicht sofort auf einen Blick finden. Zu diesem Zeitpunkt müssen Sie sich beim Server anmelden, um die Grundursache des Problems weiter zu analysieren. Dann erfordert die Analyse von Problemen ein gewisses Maß an technischer Erfahrung, und einige Probleme umfassen sehr große Bereiche, um das Problem zu lokalisieren. Daher ist das Analysieren von Problemen und das Betreten von Fallstricken eine großartige Übung für das eigene Wachstum und die Selbstverbesserung. Wenn wir über gute Analysetools verfügen, erzielen wir mit halbem Aufwand das Doppelte des Ergebnisses. Das hilft allen, Probleme schnell zu lokalisieren, und spart allen viel Zeit für tiefergehende Arbeit.

2. Beschreibung
In diesem Artikel werden hauptsächlich verschiedene Tools zur Problemlokalisierung vorgestellt und Probleme anhand von Fällen analysiert.
3. Methodik zur Problemanalyse
-
Was ist das Phänomen? -
Warum – warum ist es passiert? – Wo – wo das Problem aufgetreten ist? Wie viel – wie viele Ressourcen verbraucht wurden? zu tun – wie zu lösen das Problem 4. CPU - 4.1 Beschreibung
Bei Anwendungen konzentrieren wir uns normalerweise auf die Kernel-CPU-Schedulerfunktion und -leistung. -
Die Thread-Statusanalyse analysiert hauptsächlich, wo Thread-Zeit verwendet wird, und die Klassifizierung des Thread-Status ist im Allgemeinen unterteilt in:
on-CPU: Ausführung, und die Zeit während der Ausführung wird normalerweise in Benutzermoduszeit und Benutzermodus unterteilt Systemstatus Zeitsystem.
Off-CPU: Warten auf die nächste CPU-Runde oder Warten auf E/A, Sperre, Seitenwechsel usw. Der Status kann in ausführbar, anonymer Seitenwechsel, Ruhezustand, Sperre, Leerlauf usw. unterteilt werden. usw. .
Wenn viel Zeit mit der CPU verbracht wird, kann die Profilierung der CPU schnell die Ursache erklären; wenn das System viel Zeit im Off-CPU-Zustand verbringt, wird die Lokalisierung des Problems viel Zeit in Anspruch nehmen. Aber es gibt noch einige Konzepte, die klar sein müssen: Prozessor Kern Hardware-Threads -
Cache Uhr Häufigkeit CPI und Anweisungen pro Zyklus IPC CPU-Anweisungen Nutzung -
Benutzerzeit/Kernel Planer Run Queue Preemption Multi-Prozess Multi-Threading -
Wortlänge
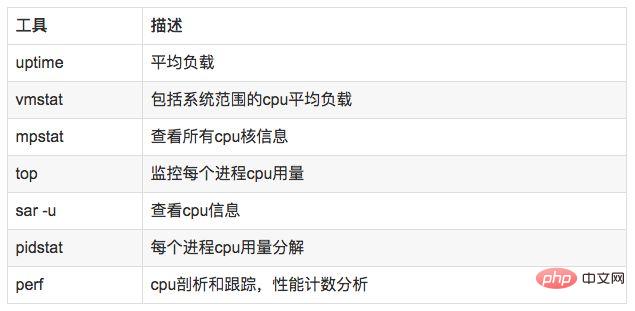
4.2 Analysetools

Hinweis: uptime, vmstat, mpstat, top, pidstat können nur die CPU-Nutzung und Last abfragen. -
perf kann den zeitaufwändigen Status bestimmter Funktionen innerhalb des Prozesses verfolgen, Kernelfunktionen für Statistiken angeben und diese entsprechend ausrichten. ... , es wirkt sich auf Dienste aus oder verursacht andere Probleme.同样对于内存有些概念需要清楚:牛逼啊!接私活必备的 N 个开源项目!赶快收藏
主存 虚拟内存 常驻内存 地址空间 OOM 页缓存 缺页 换页 交换空间 交换 用户分配器libc、glibc、libmalloc和mtmalloc LINUX内核级SLUB分配器
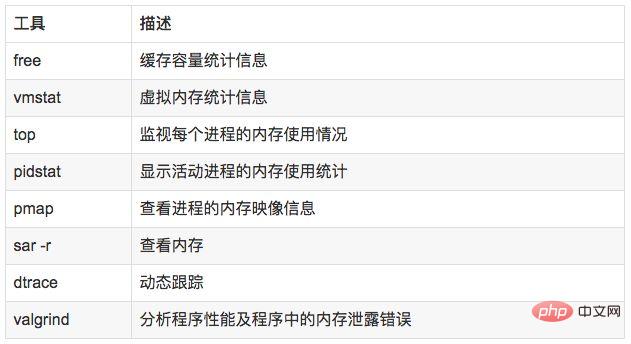
5.2 分析工具
说明:
free,vmstat,top,pidstat,pmap只能统计内存信息以及进程的内存使用情况。
valgrind 可以分析内存泄漏问题。
dtrace 动态跟踪。需要对内核函数有很深入的了解,通过D语言编写脚本完成跟踪。
5.3 使用方式
//查看系统内存使用情况free -m//虚拟内存统计信息vmstat 1//查看系统内存情况top//1s采集周期,获取内存的统计信息pidstat -p pid -r 1//查看进程的内存映像信息pmap -d pid//检测程序内存问题valgrind --tool=memcheck --leak-check=full --log-file=./log.txt ./程序名
6. 磁盘IO
6.1 说明
磁盘通常是计算机最慢的子系统,也是最容易出现性能瓶颈的地方,因为磁盘离 CPU 距离最远而且 CPU 访问磁盘要涉及到机械操作,比如转轴、寻轨等。访问硬盘和访问内存之间的速度差别是以数量级来计算的,就像1天和1分钟的差别一样。要监测 IO 性能,有必要了解一下基本原理和 Linux 是如何处理硬盘和内存之间的 IO 的。 在理解磁盘IO之前,同样我们需要理解一些概念,例如:
Dateisystem VFS Dateisystem-Cache Seiten-Cache-Seite. Cache Puffer-Cache-Puffer-Cache Verzeichnis-Cache ??
6.3 使用方式
//查看系统io信息iotop//统计io详细信息iostat -d -x -k 1 10//查看进程级io的信息pidstat -d 1 -p pid//查看系统IO的请求,比如可以在发现系统IO异常时,可以使用该命令进行调查,就能指定到底是什么原因导致的IO异常perf record -e block:block_rq_issue -ag^Cperf report
7. 网络
7.1 说明
网络的监测是所有 Linux 子系统里面最复杂的,有太多的因素在里面,比如:延迟、阻塞、冲突、丢包等,更糟的是与 Linux 主机相连的路由器、交换机、无线信号都会影响到整体网络并且很难判断是因为 Linux 网络子系统的问题还是别的设备的问题,增加了监测和判断的复杂度。现在我们使用的所有网卡都称为自适应网卡,意思是说能根据网络上的不同网络设备导致的不同网络速度和工作模式进行自动调整。 7.2 分析工具
7.3 使用方式
//显示网络统计信息netstat -s//显示当前UDP连接状况netstat -nu//显示UDP端口号的使用情况netstat -apu//统计机器中网络连接各个状态个数netstat -a | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'//显示TCP连接ss -t -a//显示sockets摘要信息ss -s//显示所有udp socketsss -u -a//tcp,etcp状态sar -n TCP,ETCP 1//查看网络IOsar -n DEV 1//抓包以包为单位进行输出tcpdump -i eth1 host 192.168.1.1 and port 80 //抓包以流为单位显示数据内容tcpflow -cp host 192.168.1.18. 系统负载
8.1 说明
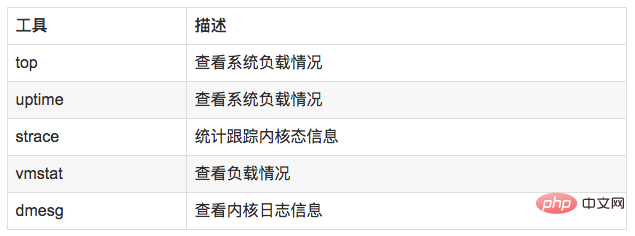
Load 就是对计算机干活多少的度量(WikiPedia:the system Load is a measure of the amount of work that a compute system is doing)简单的说是进程队列的长度。Load Average 就是一段时间(1分钟、5分钟、15分钟)内平均Load。 8.2 分析工具
8.3 使用方式
//查看负载情况uptimetopvmstat//统计系统调用耗时情况strace -c -p pid//跟踪指定的系统操作例如epoll_waitstrace -T -e epoll_wait -p pid//查看内核日志信息dmesg
9. 火焰图
9.1 说明
火焰图(Flame Graph是 Bredan Gregg 创建的一种性能分析图表,因为它的样子近似 ?而得名。 火焰图主要是用来展示 CPU的调用栈。 y 轴表示调用栈,每一层都是一个函数。调用栈越深,火焰就越高,顶部就是正在执行的函数,下方都是它的父函数。 x 轴表示抽样数,如果一个函数在 x 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长。注意,x 轴不代表时间,而是所有的调用栈合并后,按字母顺序排列的。 火焰图就是看顶层的哪个函数占据的宽度最大。只要有”平顶”(plateaus),就表示该函数可能存在性能问题。颜色没有特殊含义,因为火焰图表示的是 CPU 的繁忙程度,所以一般选择暖色调。 常见的火焰图类型有 On-CPU、Off-CPU、Memory、Hot/Cold、Differential等等。
9.2 安装依赖库
//安装systemtap,默认系统已安装yum install systemtap systemtap-runtime//内核调试库必须跟内核版本对应,例如:uname -r 2.6.18-308.el5kernel-debuginfo-2.6.18-308.el5.x86_64.rpmkernel-devel-2.6.18-308.el5.x86_64.rpmkernel-debuginfo-common-2.6.18-308.el5.x86_64.rpm//安装内核调试库debuginfo-install --enablerepo=debuginfo search kerneldebuginfo-install --enablerepo=debuginfo search glibc
9.3 安装
git clone https://github.com/lidaohang/quick_location.gitcd quick_location
9.4 CPU级别火焰图
cpu占用过高,或者使用率提不上来,你能快速定位到代码的哪块有问题吗?
一般的做法可能就是通过日志等方式去确定问题。现在我们有了火焰图,能够非常清晰的发现哪个函数占用cpu过高,或者过低导致的问题。另外,搜索公众号Linux就该这样学后台回复“猴子”,获取一份惊喜礼包。
9.4.1 on-CPU
cpu占用过高,执行中的时间通常又分为用户态时间user和系统态时间sys。 使用方式: //on-CPU usersh ngx_on_cpu_u.sh pid//进入结果目录 cd ngx_on_cpu_u//on-CPU kernelsh ngx_on_cpu_k.sh pid//进入结果目录 cd ngx_on_cpu_k//开一个临时端口 8088 python -m SimpleHTTPServer 8088//打开浏览器输入地址127.0.0.1:8088/pid.svg
DEMO:
#include <stdio.h>#include <stdlib.h> void foo3(){ } void foo2(){ int i; for(i=0 ; i < 10; i++) foo3();} void foo1(){ int i; for(i = 0; i< 1000; i++) foo3();} int main(void){ int i; for( i =0; i< 1000000000; i++) { foo1(); foo2(); }}DEMO火焰图:
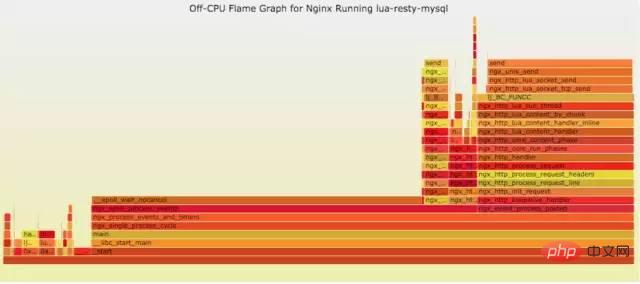
9.4.2 off-CPU
cpu过低,利用率不高。等待下一轮CPU,或者等待I/O、锁、换页等等,其状态可以细分为可执行、匿名换页、睡眠、锁、空闲等状态。
使用方式:
// off-CPU usersh ngx_off_cpu_u.sh pid//进入结果目录cd ngx_off_cpu_u//off-CPU kernelsh ngx_off_cpu_k.sh pid//进入结果目录cd ngx_off_cpu_k//开一个临时端口8088python -m SimpleHTTPServer 8088//打开浏览器输入地址127.0.0.1:8088/pid.svg
官网DEMO:
9.5 内存级别火焰图
如果线上程序出现了内存泄漏,并且只在特定的场景才会出现。这个时候我们怎么办呢?有什么好的方式和工具能快速的发现代码的问题呢?同样内存级别火焰图帮你快速分析问题的根源。
使用方式:
sh ngx_on_memory.sh pid//进入结果目录cd ngx_on_memory//开一个临时端口8088python -m SimpleHTTPServer 8088//打开浏览器输入地址127.0.0.1:8088/pid.svg
官网DEMO:
9.6 性能回退-红蓝差分火焰图
你能快速定位CPU性能回退的问题么?如果你的工作环境非常复杂且变化快速,那么使用现有的工具是来定位这类问题是很具有挑战性的。当你花掉数周时间把根因找到时,代码已经又变更了好几轮,新的性能问题又冒了出来。主要可以用到每次构建中,每次上线做对比看,如果损失严重可以立马解决修复。
通过抓取了两张普通的火焰图,然后进行对比,并对差异部分进行标色:红色表示上升,蓝色表示下降。差分火焰图是以当前(“修改后”)的profile文件作为基准,形状和大小都保持不变。因此你通过色彩的差异就能够很直观的找到差异部分,且可以看出为什么会有这样的差异。
使用方式:
cd quick_location//抓取代码修改前的profile 1文件perf record -F 99 -p pid -g -- sleep 30perf script > out.stacks1//抓取代码修改后的profile 2文件perf record -F 99 -p pid -g -- sleep 30perf script > out.stacks2//生成差分火焰图:./FlameGraph/stackcollapse-perf.pl ../out.stacks1 > out.folded1./FlameGraph/stackcollapse-perf.pl ../out.stacks2 > out.folded2./FlameGraph/difffolded.pl out.folded1 out.folded2 | ./FlameGraph/flamegraph.pl > diff2.svg
DEMO:
//test.c#include <stdio.h>#include <stdlib.h> void foo3(){ } void foo2(){ int i; for(i=0 ; i < 10; i++) foo3();} void foo1(){ int i; for(i = 0; i< 1000; i++) foo3();} int main(void){ int i; for( i =0; i< 1000000000; i++) { foo1(); foo2(); }} //test1.c#include <stdio.h>#include <stdlib.h> void foo3(){ } void foo2(){ int i; for(i=0 ; i < 10; i++) foo3();} void foo1(){ int i; for(i = 0; i< 1000; i++) foo3();} void add(){ int i; for(i = 0; i< 10000; i++) foo3();} int main(void){ int i; for( i =0; i< 1000000000; i++) { foo1(); foo2(); add(); }}DEMO红蓝差分火焰图:
10. Fallanalyse
10.1 Anomalien im Nginx-Cluster auf der Zugriffsebene
Durch das Überwachungs-Plug-in wurde festgestellt, dass um 19:00 Uhr eine große Anzahl von 499- und 5xx-Statuscodes im Nginx-Cluster-Anfrageverkehr auftrat am 25. September 2017. Und es wurde festgestellt, dass die CPU-Auslastung der Maschine zugenommen hat, und das geht weiter. Durchsuchen Sie außerdem den Top-Algorithmus-Hintergrund des offiziellen Kontos und antworten Sie mit „Algorithmus“, um ein Überraschungsgeschenkpaket zu erhalten. 10.2 Analysieren Sie Nginx-bezogene Indikatoren plötzlich ansteigen, aber stattdessen verringert, folgen Es spielt keine Rolle, ob der Anforderungsverkehr plötzlich zunimmt.
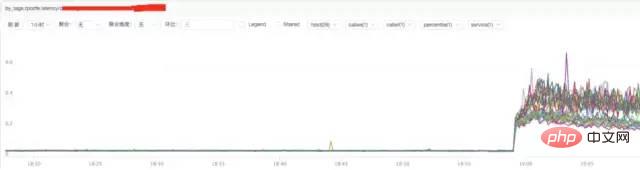
b) **Analyse der Nginx-Reaktionszeit
Fazit:
Aus der obigen Abbildung geht hervor, dass der Anstieg der Nginx-Reaktionszeit möglicherweise mit Nginx selbst oder dem Backend zusammenhängt Upstream-Antwortzeit.
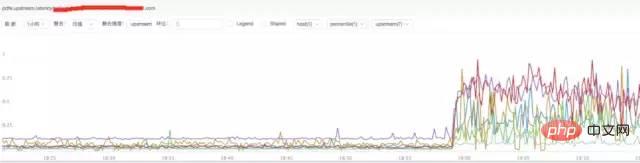
c) **Analyse der Upstream-Reaktionszeit von Nginx
Schlussfolgerung:
Aus der obigen Abbildung geht hervor, dass sich die Upstream-Reaktionszeit von Nginx erhöht hat Die Back-End-Upstream-Antwortzeit kann Nginx zurückhalten, was dazu führt, dass bei Nginx ein abnormaler Anforderungsverkehr auftritt.
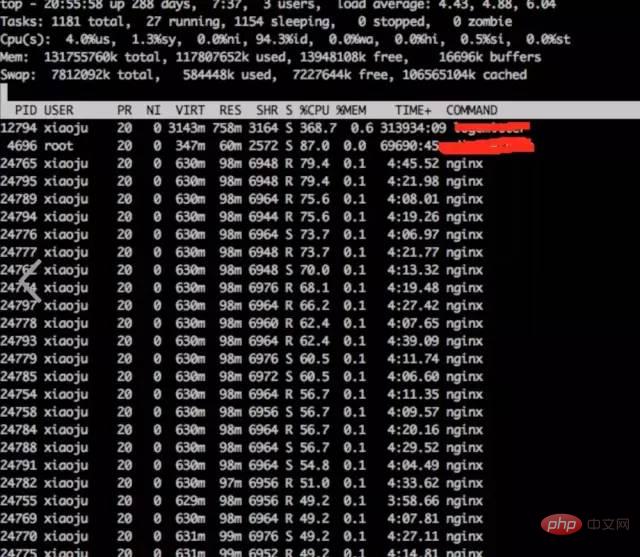
10.3 Analysieren Sie die CPU-Situation des Systems ;padding-left: 0.3em;outline: 0px;font-size: 0.85em;font-family: Consolas, Inconsolata, Courier, monospace;white-space: pre-wrap;border-width: 1px;border-style: solid ;Rahmenfarbe: RGB(234, 234, 234);Hintergrundfarbe: RGB(248, 248, 248);Rahmenradius: 3px;Anzeige: inline;">top
Fazit:
hat festgestellt, dass die Nginx-Worker-CPU relativ hoch ist
top结论:
发现nginx worker cpu比较高
b) **分析nginx进程内部cpu情况
🎜 🎜 b) 🎜**🎜Analysieren Sie die interne CPU-Situation des Nginx-Prozesses🎜🎜🎜perf top -p pidperf top -p pid🎜结论:
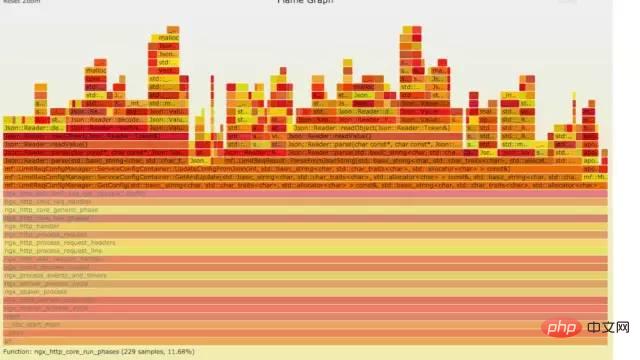
发现主要开销在free,malloc,json解析上面
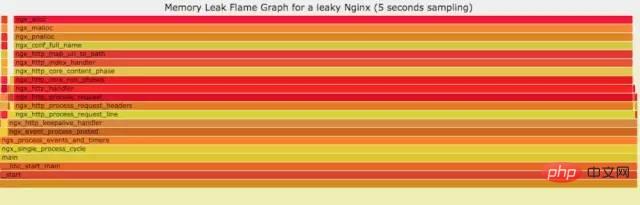
10.4 火焰图分析cpu
a) **生成用户态cpu火焰图//on-CPU usersh ngx_on_cpu_u.sh pid//进入结果目录cd ngx_on_cpu_u//开一个临时端口8088python -m SimpleHTTPServer 8088//打开浏览器输入地址127.0.0.1:8088/pid.svg
结论:
发现代码里面有频繁的解析json操作,并且发现这个json库性能不高,占用cpu挺高。
10.5 案例总结
a) 分析请求流量异常,得出nginx upstream后端机器响应时间拉长
b) Bei der Analyse der hohen CPU des Nginx-Prozesses kommt man zu dem Schluss, dass der Code des internen Nginx-Moduls zeitaufwändige JSON-Analyse- und Speicherzuweisungs- und Recyclingvorgänge aufweist
10.5.1 Eingehende Analyse
Fazit: Basierend auf der Analyse der beiden oben genannten Punkte analysieren wir sie weiter eingehend.
Die Back-End-Upstream-Antwort ist gestreckt, was höchstens die Verarbeitungsfähigkeiten von Nginx beeinträchtigen kann. Es ist jedoch unwahrscheinlich, dass dies Auswirkungen auf interne Nginx-Module hat, die zu viele CPU-Operationen beanspruchen. Und die Module, die damals viel CPU beanspruchten, wurden nur auf Anfrage ausgeführt. Es ist unwahrscheinlich, dass das Upstream-Backend Nginx zurückhält und dadurch den zeitaufwändigen Betrieb dieser CPU auslöst.
10.5.2 Lösung
Wenn wir auf ein Problem dieser Art stoßen, werden wir der Lösung bekannter und sehr klarer Probleme Priorität einräumen. Das ist das Problem bei hoher CPU. Die Lösung besteht darin, das Modul, das zu viel CPU verbraucht, herunterzustufen, zu schließen und dann zu beobachten. Nach dem Downgrade und Herunterfahren des Moduls sank die CPU-Leistung und der Nginx-Anfrageverkehr normalisierte sich. Der Grund für die Verlängerung der Upstream-Zeit liegt darin, dass die vom Upstream-Backend-Dienst aufgerufene Schnittstelle möglicherweise eine Schleife ist und wieder zu Nginx zurückkehrt.
11.参考资料
http://www.brendangregg.com/index.html
http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html
http://www.brendangregg.com/FlameGraphs/memoryflamegraphs.html
http://www.brendangregg.com/FlameGraphs/offcpuflamegraphs.html
http://www.brendangregg. com/blog/2014-11-09/differential-flame-graphs.html
https://github.com/openresty/openresty-systemtap-toolkit
https://github. com/brendangregg/FlameGraph
https://www.slideshare.net/brendangregg/blazing-performance-with-flame-graphs



Das obige ist der detaillierte Inhalt vonIdeen zur Fehlerbehebung bei Linux-Betrieb und -Wartung, dieser Artikel reicht aus ~. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Welche Befehle gibt es zum Dekomprimieren von Dateien unter Linux?
- So verschieben Sie Dateien in ein bestimmtes Verzeichnis unter Linux
- Welche Methoden gibt es, um den Firewall-Status unter Linux zu überprüfen?
- So erstellen Sie einen neuen Benutzer und legen ein Passwort unter Linux fest
- So erstellen Sie Dateien unter Linux