
Heim >Java >javaLernprogramm >Dies ist möglicherweise der ausführlichste Artikel über Microservice-Architektur, den Sie je gelesen haben.
Dies ist möglicherweise der ausführlichste Artikel über Microservice-Architektur, den Sie je gelesen haben.
- Java学习指南nach vorne
- 2023-07-26 15:42:28899Durchsuche
In diesem Artikel werden die Microservice-Architektur und verwandte Komponenten vorgestellt, erläutert, was sie sind und warum die Microservice-Architektur und diese Komponenten verwendet werden sollten. Dieser Artikel konzentriert sich darauf, das Gesamtbild der Microservice-Architektur prägnant auszudrücken, sodass er nicht auf Details wie die Verwendung von Komponenten eingeht.
Um Microservices zu verstehen, müssen Sie zunächst diejenigen verstehen, die keine Microservices sind. Normalerweise ist das Gegenteil von Microservices eine monolithische Anwendung, also eine Anwendung, die alle Funktionen in einer unabhängigen Einheit bündelt. Der Übergang von einer monolithischen Anwendung zu Microservices geschieht nicht über Nacht, sondern ist ein schrittweiser Evolutionsprozess. In diesem Artikel wird dieser Prozess am Beispiel einer Online-Supermarktanwendung veranschaulicht.
Erste Nachfrage
Vor einigen Jahren gründeten Xiao Ming und Xiao Pi gemeinsam ein Unternehmen als Online-Supermarkt. Xiao Ming ist für die Programmentwicklung verantwortlich und Xiao Pi ist für andere Angelegenheiten verantwortlich. Damals war das Internet noch nicht entwickelt und Online-Supermärkte waren noch ein blauer Ozean. Solange die Funktion implementiert ist, können Sie nach Belieben Geld verdienen. Ihre Anforderungen sind also sehr einfach. Sie benötigen lediglich eine Website im öffentlichen Netzwerk, auf der Benutzer Produkte durchsuchen und kaufen können. Außerdem benötigen sie ein Verwaltungs-Backend, das Produkte, Benutzer und Bestelldaten verwalten kann.
Lassen Sie uns die Liste der Funktionen sortieren:
Website Benutzerregistrierungs- und Anmeldefunktionen Produktanzeige Bestellung -
Verwaltungshintergrund -
Benutzerverwaltung Produktmanagement Auftragsmanagement
Aufgrund einfacher Bedürfnisse bewegte Xiao Ming einfach seine linke und rechte Hand in Zeitlupe und schon war die Website fertig. Aus Sicherheitsgründen befindet sich das Management-Backend nicht neben der Website. Die rechte Hand und die linke Hand von Xiao Ming werden in Zeitlupe wiedergegeben, und die Management-Website ist bereit. Das Gesamtarchitekturdiagramm sieht wie folgt aus:
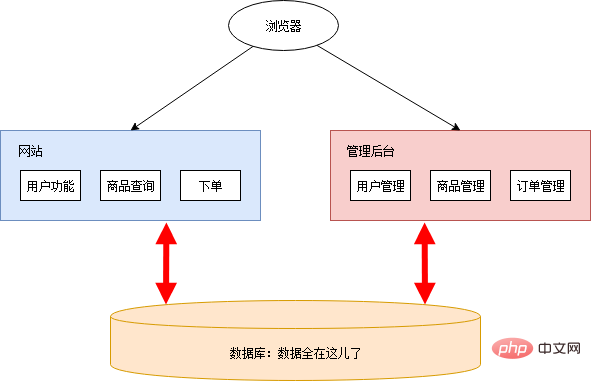
Xiao Ming winkte mit der Hand, fand einen Cloud-Dienst zum Bereitstellen und die Website war online. Nachdem es online veröffentlicht wurde, erhielt es begeisterte Kritiken und wurde von allen möglichen fetten Häusern geliebt. Xiao Ming und Xiao Pi begannen sich glücklich hinzulegen und das Geld einzusammeln.
Mit der Geschäftsentwicklung...
Die guten Zeiten hielten nicht lange an. Innerhalb weniger Tage entstanden verschiedene Online-Supermärkte, die einen starken Einfluss auf Xiao Ming Xiaopi hatten.
Unter dem Druck des Wettbewerbs beschloss Xiao Ming Xiaopi, einige Marketingmethoden anzuwenden:
Werbeaktivitäten durchführen. Zum Beispiel Rabatte für Neujahr auf der gesamten Website, Frühlingsfest-Rabatte: Kaufen Sie zwei, erhalten Sie einen gratis, Gutscheine für Hundefutter zum Valentinstag usw. Erweitern Sie Kanäle und fügen Sie mobiles Marketing hinzu. Neben der Website müssen auch mobile APPs, WeChat-Applets usw. entwickelt werden. Präzisionsmarketing. Nutzen Sie historische Daten, um Benutzer zu analysieren und personalisierte Dienste bereitzustellen. ...
Diese Aktivitäten erfordern die Unterstützung der Programmentwicklung. Xiao Ming holte seinen Klassenkameraden Xiao Hong dazu, sich dem Team anzuschließen. Xiaohong ist für die Datenanalyse und die Entwicklung mobiler Endgeräte verantwortlich. Xiao Ming ist für die Entwicklung von Funktionen im Zusammenhang mit Werbeaktivitäten verantwortlich.
Da die Entwicklungsaufgaben relativ dringend waren, planten Xiao Ming und Xiao Hong die Architektur des gesamten Systems nicht richtig. Er klopfte sich einfach auf den Kopf und beschloss, Werbemanagement und Datenanalyse in den Managementhintergrund zu integrieren, sowie WeChat und mobile APP wurden separat gebaut. Nach einigen Tagen nächtelanger Arbeit sind die neuen Funktionen und neuen Anwendungen im Grunde genommen fertig. Das Architekturdiagramm lautet zu diesem Zeitpunkt wie folgt:
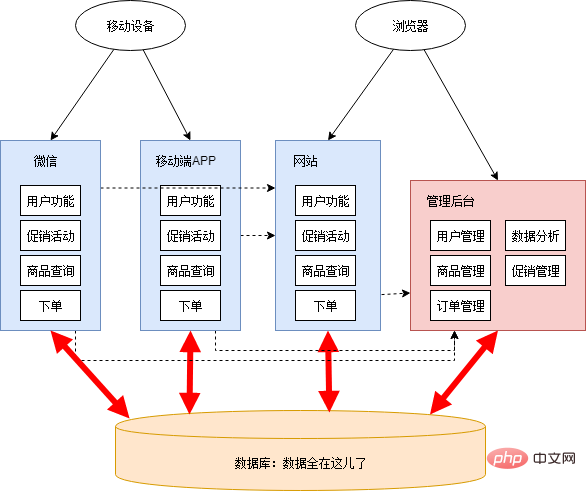
Zu diesem Zeitpunkt gibt es viele unvernünftige Dinge:
Websites und mobile Anwendungen enthalten viel doppelten Code mit derselben Geschäftslogik. Daten werden manchmal über die Datenbank geteilt und manchmal über Schnittstellenaufrufe übertragen. Die Schnittstellenaufrufbeziehung ist chaotisch. Um Schnittstellen für andere Anwendungen bereitzustellen, verändert sich eine einzelne Anwendung nach und nach immer mehr, inklusive einer Menge Logik, die gar nicht erst dazugehört. Die Anwendungsgrenzen verschwimmen und die Funktionszuordnung ist verwirrend. Das Management-Backend wurde ursprünglich mit einem geringen Sicherheitsniveau konzipiert. Nach dem Hinzufügen von Funktionen zur Datenanalyse und Promotion-Verwaltung traten Leistungsengpässe auf, die sich auf andere Anwendungen auswirkten. Die Datenbanktabellenstruktur ist von mehreren Anwendungen abhängig und kann nicht rekonstruiert und optimiert werden. Alle Anwendungen basieren auf einer Datenbank und es besteht ein Leistungsengpass in der Datenbank. Insbesondere bei laufender Datenanalyse sinkt die Datenbankleistung stark. Entwicklung, Test, Bereitstellung und Wartung werden immer schwieriger. Selbst wenn nur eine kleine Funktion geändert wird, muss die gesamte Anwendung gemeinsam veröffentlicht werden. Manchmal wird versehentlich ungetesteter Code in die Pressekonferenz eingefügt, oder nach der Änderung einer Funktion tritt ein weiterer unerwarteter Fehler auf. Um die Auswirkungen möglicher Probleme durch die Veröffentlichung und die Auswirkungen der Aussetzung des Online-Geschäfts zu verringern, müssen alle Anträge um drei oder vier Uhr morgens freigegeben werden. Um nach der Veröffentlichung zu überprüfen, ob die Anwendung normal läuft, müssen wir die Spitzenbenutzerzeit am nächsten Tag im Auge behalten ... Es gibt ein Push-and-Pull-Phänomen im Team . Es gibt oft eine lange Debatte darüber, auf welcher Anwendung einige öffentliche Funktionen aufbauen sollten, und am Ende machen sie entweder einfach ihr eigenes Ding oder sie platzieren es einfach an einem beliebigen Ort, ohne es zu warten.
Obwohl es viele Probleme gibt, können wir die Ergebnisse dieser Phase nicht leugnen: Das System wurde schnell entsprechend den geschäftlichen Veränderungen aufgebaut. Allerdings können dringende und schwere Aufgaben leicht dazu führen, dass Menschen in parteiisches und kurzfristiges Denken verfallen und Kompromissentscheidungen treffen. Bei einer solchen Struktur konzentriert sich jeder nur auf sein eigenes Drittel Hektar, es fehlt eine umfassende und langfristige Planung. Wenn die Dinge so weitergehen, wird der Systemaufbau immer schwieriger und könnte sogar in einen Kreislauf ständigen Umsturzes und Wiederaufbaus geraten.
Es ist Zeit, etwas zu verändern
Glücklicherweise sind Xiao Ming und Xiao Hong gute junge Menschen mit Zielen und Idealen. Nachdem Xiao Ming und Xiao Hong das Problem erkannt hatten, befreiten sie sich von trivialen Geschäftsanforderungen, begannen mit der Klärung der Gesamtstruktur und bereiteten sich auf die Transformation des Problems vor.
Um eine Transformation durchzuführen, müssen Sie zunächst über genügend Energie und Ressourcen verfügen. Wenn Ihre Nachfrageseite (Geschäftsmitarbeiter, Projektmanager, Chef usw.) so stark auf den Fortschritt der Nachfrage ausgerichtet ist, dass Sie keine zusätzliche Energie und Ressourcen bereitstellen können, können Sie möglicherweise nichts tun ...
In der Welt des Programmierens ist das Wichtigste die Abstraktionsfähigkeit. Der Prozess der Microservice-Transformation ist eigentlich ein abstrakter Prozess. Xiao Ming und Xiao Hong organisierten die Geschäftslogik des Online-Supermarkts, abstrahierten allgemeine Geschäftsfunktionen und erstellten mehrere öffentliche Dienste:
Benutzerservice Warenservice Werbeservice -
Bestellservice Datenanalysedienst
Jedes Anwendungs-Backend muss nur die erforderlichen Daten von diesen Diensten abrufen, wodurch eine große Menge redundanten Codes gelöscht wird und nur eine dünne Kontrollschicht und ein Frontend übrig bleiben. Die Architektur dieser Phase ist wie folgt:
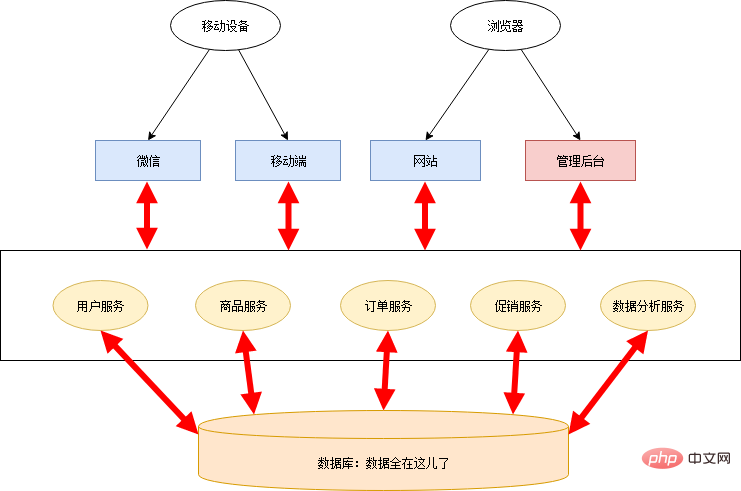
Diese Phase trennt nur die Dienste und die Datenbank wird weiterhin gemeinsam genutzt, sodass einige Mängel des Schornsteinsystems weiterhin bestehen:
Die Datenbank wird zu einem Leistungsengpass. und es besteht ein einziges Risiko des Scheiterns. Datenmanagement neigt dazu, chaotisch zu sein. Auch wenn am Anfang ein guter modularer Aufbau vorhanden ist, wird es mit der Zeit immer wieder das Phänomen geben, dass ein Dienst die Daten eines anderen Dienstes direkt aus der Datenbank übernimmt. Die Datenbanktabellenstruktur kann von mehreren Diensten abhängig sein, was sich auf das gesamte System auswirkt und schwierig anzupassen ist.
Wenn Sie das gemeinsam genutzte Datenbankmodell beibehalten, wird die gesamte Architektur immer starrer und verliert die Bedeutung der Microservice-Architektur. Daher arbeiteten Xiao Ming und Xiao Hong zusammen, um die Datenbank aufzuteilen. Alle Persistenzschichten sind voneinander isoliert und liegen in der Verantwortung jedes einzelnen Dienstes. Um die Echtzeitleistung des Systems zu verbessern, wird außerdem ein Nachrichtenwarteschlangenmechanismus hinzugefügt. Die Architektur ist wie folgt:
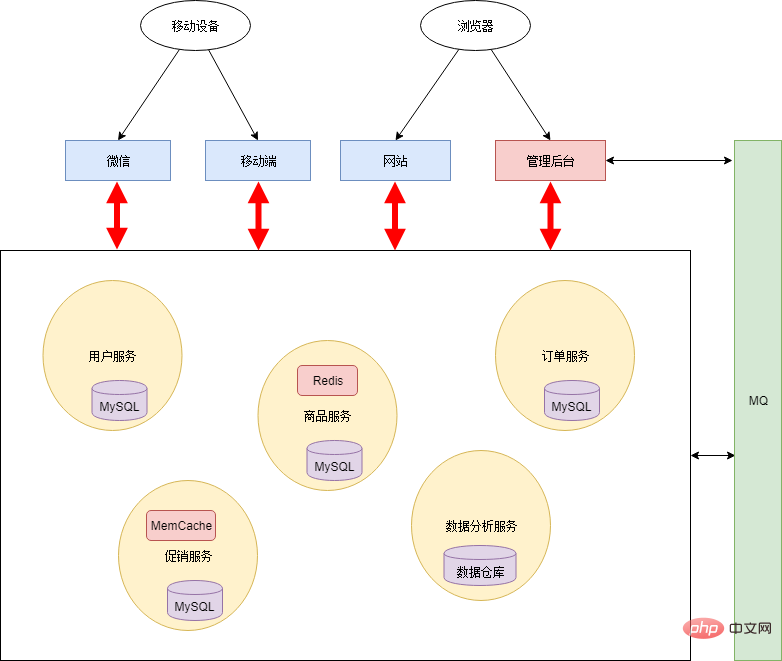
Nach der vollständigen Aufteilung kann jeder Dienst heterogene Technologien nutzen. Datenanalysedienste können beispielsweise Data Warehouses als Persistenzschicht verwenden, um einige statistische Berechnungen effizient durchzuführen; auf Warendienste und Werbedienste wird häufiger zugegriffen, sodass ein Caching-Mechanismus hinzugefügt wird.
Eine andere Möglichkeit, öffentliche Logik zu abstrahieren, besteht darin, diese öffentliche Logik in eine öffentliche Framework-Bibliothek umzuwandeln. Diese Methode kann den Leistungsverlust von Serviceaufrufen reduzieren. Der Verwaltungsaufwand dieser Methode ist jedoch sehr hoch und es ist schwierig, die Konsistenz aller Anwendungsversionen sicherzustellen.
Die Aufteilung der Datenbank bringt auch einige Probleme und Herausforderungen mit sich: z. B. die Notwendigkeit einer datenbankübergreifenden Kaskadierung, die Granularität der Datenabfrage über Dienste usw. Aber diese Probleme können durch vernünftiges Design gelöst werden. Insgesamt hat die Datenbankaufteilung mehr Vor- als Nachteile.
Die Microservice-Architektur hat auch einen nichttechnischen Vorteil: Sie macht die Arbeitsteilung im gesamten System klarer und die Verantwortlichkeiten klarer. Im Zeitalter monolithischer Anwendungen haben öffentliche Geschäftsfunktionen oft keine klare Eigentümerschaft. Am Ende macht entweder jeder sein eigenes Ding und jeder setzt es erneut um, oder eine beliebige Person (normalerweise eine fähigere oder enthusiastischere Person) setzt die Anwendung um, für die er verantwortlich ist. Im letzteren Fall ist diese Person nicht nur für ihre eigene Anwendung verantwortlich, sondern auch für die Bereitstellung dieser öffentlichen Funktionen für andere – und diese Funktion ist ursprünglich für niemanden verantwortlich, nur weil sie aus unerklärlichen Gründen fähiger/enthusiastischer ist Schuldzuweisungen (diese Situation wird auch euphemistisch „die Fähigen leisten die harte Arbeit“) genannt. Am Ende war niemand bereit, öffentliche Aufgaben wahrzunehmen. Mit der Zeit wurden die Leute im Team nach und nach unabhängig und kümmerten sich nicht mehr um den gesamten Architekturentwurf. Folgen Sie dem offiziellen Konto Java Journey, um E-Books zu erhalten.
Aus dieser Perspektive erfordert der Einsatz einer Microservice-Architektur auch entsprechende Anpassungen der Organisationsstruktur. Daher erfordert die Microservice-Transformation die Unterstützung von Managern.
Nachdem die Transformation abgeschlossen war, teilten Xiao Ming und Xiao Hong ihre jeweiligen Rollen klar auf. Die beiden waren sehr zufrieden, alles war so schön und perfekt wie Maxwells Gleichungen.
Allerdings...
Es gibt kein Allheilmittel
Der Frühling ist da, alles erwacht wieder zum Leben und es ist wieder der alljährliche Einkaufskarneval. Als Xiaopi, Xiaoming und Xiaohong sahen, dass die Zahl der täglichen Bestellungen stetig stieg, lächelten sie glücklich. Leider währten die guten Zeiten nicht lange. Plötzlich brach das System zusammen.
In der Vergangenheit umfasste die Fehlerbehebung bei einzelnen Anwendungen normalerweise die Betrachtung von Protokollen, das Studium von Fehlermeldungen und Aufruflisten. In der „Microservice-Architektur“ ist die gesamte Anwendung auf mehrere Dienste verteilt, was es sehr schwierig macht, den Fehlerpunkt zu lokalisieren. Xiao Ming überprüfte die Protokolle einzeln und rief jeden Dienst einzeln manuell auf. Nach mehr als zehn Minuten Suche fand Xiao Ming schließlich den Fehlerpunkt: Der Werbedienst reagierte aufgrund der großen Anzahl eingegangener Anfragen nicht mehr. Andere Dienste rufen den Werbedienst direkt oder indirekt auf, sodass sie ebenfalls untergehen. In einer Microservice-Architektur kann ein Dienstausfall einen Lawineneffekt haben, der zum Ausfall des gesamten Systems führt. Tatsächlich führten Xiao Ming und Xiao Hong vor dem Feiertag eine Bewertung des Anfragevolumens durch. Wie erwartet reichen die Serverressourcen aus, um das Anfragevolumen des Feiertags zu bewältigen, es muss also ein Fehler vorliegen. Da jedoch jede Minute und jede Sekunde, die verging, Geld verschwendet wurde, hatte Xiao Ming keine Zeit, das Problem zu beheben. Er beschloss sofort, mehrere neue virtuelle Maschinen in der Cloud zu erstellen und stellte dann einen neuen Werbedienst bereit um einen. Nach einigen Betriebsminuten kehrte das System endlich wieder in den Normalzustand zurück. Es wird geschätzt, dass während des gesamten Ausfalls Hunderttausende Verkäufe verloren gingen und den dreien das Herz blutete... Danach schrieb Xiao Ming einfach ein Protokollanalysetool (das Volumen war so groß, dass es fast unmöglich war, es mit einem Texteditor zu öffnen und mit bloßem Auge nicht zu erkennen), zählte die Zugriffsprotokolle der Werbedienste und Während des Fehlers wurde festgestellt, dass die Produktdienste ein Codeproblem hatten und in einigen Szenarien eine große Anzahl von Anfragen an den Werbedienst gestellt wurden. Dieses Problem ist nicht kompliziert. Xiao Ming hat diesen Fehler im Wert von Hunderttausenden mit einer Fingerbewegung behoben. Das Problem wurde gelöst, aber niemand kann garantieren, dass ähnliche Probleme nicht erneut auftreten. Obwohl die Microservice-Architektur im logischen Design perfekt zu sein scheint, gleicht sie einem wunderschönen Palast aus Bausteinen und kann Wind und Wellen nicht standhalten. Obwohl die Microservice-Architektur alte Probleme löst, bringt sie auch neue mit sich: Xiao Ming und Xiao Hong haben aus dieser Erfahrung gelernt und sind entschlossen, diese Probleme zu lösen. Die Fehlerbehebung umfasst im Allgemeinen zwei Aspekte: Einerseits versuchen wir, die Wahrscheinlichkeit eines Fehlers zu verringern, und andererseits reduzieren wir die Auswirkungen des Fehlers. In verteilten Szenarien mit hoher Parallelität treten Ausfälle oft plötzlich wie eine Lawine auf. Daher muss ein vollständiges Überwachungssystem eingerichtet werden, um Anzeichen von Ausfällen so weit wie möglich zu erkennen. Es gibt viele Komponenten in der Microservice-Architektur und jede Komponente muss unterschiedliche Indikatoren überwachen. Beispielsweise überwacht der Redis-Cache im Allgemeinen den Wert der Speicherbelegung und den Netzwerkverkehr, die Datenbank überwacht die Anzahl der Verbindungen und den Speicherplatz und der Geschäftsdienst überwacht die Anzahl der Parallelen, Antwortverzögerungen, Fehlerraten usw. Daher ist es unrealistisch, ein großes und umfassendes Überwachungssystem zur Überwachung jeder Komponente aufzubauen, und die Skalierbarkeit wird sehr schlecht sein. Der allgemeine Ansatz besteht darin, dass jede Komponente eine Schnittstelle (Metrikschnittstelle) zur Meldung ihres aktuellen Status bereitstellt. Das von dieser Schnittstelle ausgegebene Datenformat sollte konsistent sein. Stellen Sie dann eine Indikatorkollektorkomponente bereit, um regelmäßig den Komponentenstatus von diesen Schnittstellen abzurufen und zu verwalten und gleichzeitig Abfragedienste bereitzustellen. Schließlich wird eine Benutzeroberfläche benötigt, um verschiedene Indikatoren vom Indikatorsammler abzufragen, eine Überwachungsschnittstelle zu zeichnen oder Alarme basierend auf Schwellenwerten auszugeben. Die meisten Komponenten müssen nicht selbst entwickelt werden, es gibt Open-Source-Komponenten im Internet. Xiao Ming hat RedisExporter und MySQLExporter heruntergeladen. Diese beiden Komponenten bieten Indikatorschnittstellen für den Redis-Cache bzw. die MySQL-Datenbank. Microservices implementieren maßgeschneiderte Indikatorschnittstellen basierend auf der Geschäftslogik jedes Dienstes. Dann verwendet Xiao Ming Prometheus als Indikatorsammler und Grafana konfiguriert die Überwachungsschnittstelle und E-Mail-Benachrichtigungen. Ein solches Microservice-Überwachungssystem ist wie folgt aufgebaut: Unter der Microservice-Architektur umfasst die Anfrage eines Benutzers häufig mehrere interne Serviceaufrufe. Um die Problemlokalisierung zu erleichtern, ist es notwendig, aufzuzeichnen, wie viele Serviceaufrufe innerhalb des Microservices generiert werden, wenn jeder Benutzer dies anfordert, und welche Aufrufbeziehungen sie haben. Dies wird als Link-Tracking bezeichnet. Wir verwenden ein Link-Tracking-Beispiel im Istio-Dokument, um den Effekt zu sehen: Wie Sie auf dem Bild sehen können, handelt es sich hierbei um eine Aufforderung an einen Benutzer Greifen Sie auf die Produktseite zu. Während des Anfrageprozesses ruft der Produktseitendienst nacheinander die Schnittstellen der Detail- und Bewertungsdienste auf. Der Bewertungsdienst ruft während des Antwortvorgangs die Bewertungsschnittstelle auf. Die Aufzeichnung der gesamten Linkverfolgung ist ein Baum: Darüber hinaus müssen Sie auch Komponenten für die Protokollerfassung und -speicherung sowie UI-Komponenten für die Anzeige von Linkaufrufen aufrufen. Nachdem Xiao Ming die theoretischen Grundlagen verstanden hatte, entschied er sich für Zipkin, eine Open-Source-Implementierung von Dapper. Dann habe ich mit einer Fingerbewegung einen HTTP-Anfrage-Interceptor geschrieben, diese Daten generiert und sie bei jeder HTTP-Anfrage in HEADERS eingefügt und gleichzeitig das Anrufprotokoll asynchron an den Protokollsammler von Zipkin gesendet. Eine weitere Erwähnung hier ist, dass der HTTP-Anforderungs-Interceptor im Code des Mikrodienstes oder mithilfe einer Netzwerk-Proxy-Komponente implementiert werden kann (in diesem Fall muss jedoch jeder Mikrodienst eine Proxy-Ebene hinzufügen). Link-Tracking kann nur feststellen, bei welchem Dienst ein Problem vorliegt, und keine spezifischen Fehlerinformationen bereitstellen. Die Möglichkeit, spezifische Fehlerinformationen zu finden, muss von der Protokollanalysekomponente bereitgestellt werden. Die Protokollanalysekomponente sollte vor dem Aufkommen von Microservices weit verbreitet sein. Selbst bei einer einzelnen Anwendungsarchitektur nimmt die Größe der Protokolldateien zu, wenn die Anzahl der Zugriffe oder die Größe des Servers zunimmt, sodass sie mit einem Texteditor nur noch schwer zugänglich sind. Noch schlimmer ist, dass sie verstreut sind über mehrere Server hinweg. Um ein Problem zu beheben, müssen Sie sich bei jedem Server anmelden, um die Protokolldateien abzurufen, und nacheinander nach den gewünschten Protokollinformationen suchen (und das Öffnen und Suchen ist sehr langsam). Wenn der Anwendungsumfang größer wird, benötigen wir daher ein Protokoll „Suchmaschine“. Damit Sie das gewünschte Protokoll genau finden können. Darüber hinaus benötigt die Datenquellenseite auch Komponenten zum Sammeln von Protokollen und UI-Komponenten zum Anzeigen von Ergebnissen: Die letzte kleine Frage ist, wie man Protokolle an Logstash sendet. Eine Lösung besteht darin, bei der Ausgabe des Protokolls direkt die Logstash-Schnittstelle aufzurufen, um das Protokoll zu senden. Auf diese Weise muss der Code erneut geändert werden (Hey, warum „und“ verwenden) ... Also wählte Xiao Ming eine andere Lösung: Die Protokolle werden weiterhin in Dateien ausgegeben und in jedem Dienst wird ein Agent bereitgestellt, um das Protokoll zu scannen Dateien und geben Sie sie dann an Logstash aus. Werbepause: Folgen Sie dem öffentlichen Konto: Java Learning Guide, um weitere technische Artikel zu erhalten. Nach der Aufteilung in Mikrodienste erschien eine große Anzahl von Diensten und Schnittstellen, was die gesamte Anrufbeziehung chaotisch machte. Während des Entwicklungsprozesses, beim Schreiben und Schreiben, fällt mir oft plötzlich nicht mehr ein, welcher Dienst für bestimmte Daten aufgerufen werden soll. Oder es wurde schief geschrieben und ein Dienst aufgerufen, der nicht aufgerufen werden sollte, und eine schreibgeschützte Funktion hat letztendlich dazu geführt, dass die Daten geändert wurden ... Um mit diesen Situationen umzugehen, benötigt der Aufruf von Microservices einen Prüfer, das heißt , ein Tor. Fügen Sie eine Gateway-Ebene zwischen dem Anrufer und dem Angerufenen hinzu und führen Sie bei jedem Anruf eine Berechtigungsüberprüfung durch. Darüber hinaus kann das Gateway auch als Plattform zur Bereitstellung von Service-Schnittstellendokumenten genutzt werden. Ein Problem bei der Verwendung eines Gateways besteht darin, zu entscheiden, wie detailliert es verwendet werden soll: Die gröbste Lösung ist ein Gateway für den gesamten Microservice. Die Außenseite des Microservices greift über das Gateway auf den Microservice zu und das Innere des Microservices ruft auf direkt; die feinste Granularität besteht darin, dass alle Anrufe, ob innerhalb des Microservices oder von außerhalb, über das Gateway erfolgen müssen. Eine Kompromisslösung besteht darin, Microservices nach Geschäftsbereichen in mehrere Bereiche aufzuteilen, sie direkt innerhalb des Bereichs aufzurufen und über das Gateway aufzurufen. Da die Anzahl der Dienste im gesamten Online-Supermarkt nicht besonders groß ist, hat Xiao Ming die grobkörnige Lösung übernommen: Die vorherigen Komponenten sind alle darauf ausgelegt Reduzieren Sie die Möglichkeit eines Scheiterns. Es kommt jedoch immer zu Fehlern. Ein weiterer Aspekt, der untersucht werden muss, ist die Frage, wie die Auswirkungen von Fehlern verringert werden können. Die gröbste (und am häufigsten verwendete) Fehlerbehandlungsstrategie ist Redundanz. Im Allgemeinen stellt ein Dienst mehrere Instanzen bereit, sodass er den Druck teilen und die Leistung verbessern kann. Zweitens können andere Instanzen auch dann reagieren, wenn eine Instanz ausfällt. Ein Problem bei Redundanz ist, wie viele Redundanzen verwendet werden? Auf diese Frage gibt es in der Zeitleiste keine eindeutige Antwort. Je nach Dienstfunktion und Zeitraum sind unterschiedliche Anzahlen von Instanzen erforderlich. An Wochentagen können beispielsweise 4 Instanzen ausreichen; bei Werbeaktionen, wenn der Verkehr deutlich zunimmt, sind möglicherweise 40 Instanzen erforderlich. Daher ist das Ausmaß der Redundanz kein fester Wert, sondern kann bei Bedarf in Echtzeit angepasst werden. Im Allgemeinen ist der Vorgang zum Hinzufügen einer neuen Instanz wie folgt: Die Lösung für dieses Problem ist die automatische Registrierung und Erkennung von Diensten. Zunächst müssen Sie einen Diensterkennungsdienst bereitstellen, der Adressinformationen für alle registrierten Dienste bereitstellt. DNS kann auch als Diensterkennungsdienst betrachtet werden. Anschließend registriert sich jeder Anwendungsdienst beim Start automatisch beim Diensterkennungsdienst. Und nachdem der Anwendungsdienst gestartet wurde, wird die Adressliste jedes Anwendungsdienstes in Echtzeit (regelmäßig) vom Diensterkennungsdienst mit dem lokalen synchronisiert. Der Diensterkennungsdienst überprüft außerdem regelmäßig den Integritätsstatus von Anwendungsdiensten und entfernt fehlerhafte Instanzadressen. Auf diese Weise müssen Sie beim Hinzufügen einer Instanz nur die neue Instanz bereitstellen. Wenn die Instanz offline geht, können Sie den Dienst automatisch herunterfahren und prüfen, ob die Anzahl der Dienstinstanzen zunimmt. Wenn ein Dienst aus verschiedenen Gründen nicht mehr reagiert, wartet der Anrufer normalerweise eine gewisse Zeit und tritt dann in eine Zeitüberschreitung ein oder erhält eine Fehlermeldung. Wenn der aufrufende Link relativ lang ist, kann es zu einer Anhäufung von Anforderungen kommen, und der gesamte Link beansprucht viele Ressourcen und wartet auf Downstream-Antworten. Wenn der Zugriff auf einen Dienst mehrmals fehlschlägt, sollte daher der Schutzschalter unterbrochen werden, wodurch der Dienst als nicht mehr funktionsfähig markiert wird und direkt ein Fehler zurückgegeben wird. Warten Sie, bis der Dienst wieder normal ist, bevor Sie die Verbindung erneut herstellen. Bild von „Microservice Design“ wird nicht unterbrochen. Beispielsweise verfügt die Bestellschnittstelle des Online-Supermarkts über eine Funktion zum Sammeln von Bestellungen für empfohlene Produkte. Wenn das Empfehlungsmodul nicht verfügbar ist, kann die Bestellfunktion nicht gleichzeitig deaktiviert werden. Sie müssen lediglich die Empfehlungsfunktion vorübergehend deaktivieren. Nachdem sich ein Dienst aufhängt, versucht der Upstream-Dienst oder Benutzer den Zugriff normalerweise regelmäßig erneut. Das bedeutet, dass der Dienst, sobald er wieder normal ist, wahrscheinlich aufgrund übermäßigen Netzwerkverkehrs und wiederholter Sit-Ups im Sarg sofort auflegt. Daher muss der Dienst in der Lage sein, sich selbst zu schützen – den Datenverkehr zu begrenzen. Es gibt viele aktuelle Begrenzungsstrategien. Die einfachste besteht darin, überschüssige Anfragen zu verwerfen, wenn zu viele Anfragen pro Zeiteinheit vorliegen. Darüber hinaus kann auch eine Teilstrombegrenzung in Betracht gezogen werden. Lehnen Sie nur Anfragen von Diensten ab, die eine große Anzahl von Anfragen generieren. Beispielsweise müssen sowohl der Produktservice als auch der Bestellservice auf den Werbedienst zugreifen. Der Produktservice initiiert aufgrund von Codeproblemen nur Anfragen des Produktservices, und Anfragen des Bestellservices werden beantwortet normalerweise. Unter der Microservice-Architektur ist das Testen in drei Ebenen unterteilt: Die Durchführbarkeit der drei Tests nimmt von oben nach unten zu, der Testeffekt nimmt jedoch ab. End-to-End-Tests sind am zeitaufwändigsten und arbeitsintensivsten, aber nachdem wir den Test bestanden haben, haben wir das größte Vertrauen in das System. Unit-Tests sind am einfachsten zu implementieren und am effizientesten, es gibt jedoch keine Garantie dafür, dass das gesamte System nach dem Testen fehlerfrei ist. Die Schwierigkeit beim Testen von Diensten besteht darin, dass der Dienst häufig von anderen Diensten abhängt. Dieses Problem kann durch Mock Server gelöst werden: Indikatorschnittstelle, Link-Tracking-Injektion, Protokollumleitung, Erkennung der Dienstregistrierung, Routing-Regeln und andere Komponenten sowie Funktionen wie Leistungsschalter und Strombegrenzung müssen dem Anwendungsdienst alle Docking-Code hinzufügen . Es wäre sehr zeit- und arbeitsintensiv, jeden Anwendungsdienst einzeln zu implementieren. Basierend auf dem DRY-Prinzip hat Xiao Ming ein Microservice-Framework entwickelt, das den Code, der mit jeder Komponente und anderen öffentlichen Codes interagiert, in das Framework extrahiert und alle Anwendungsdienste mithilfe dieses Frameworks entwickelt. Viele individuelle Funktionen können mit dem Microservice-Framework realisiert werden. Sie können sogar Programmaufrufstapelinformationen in die Linkverfolgung einfügen, um eine Linkverfolgung auf Codeebene zu erreichen. Oder geben Sie die Statusinformationen des Thread-Pools und des Verbindungspools aus, um den zugrunde liegenden Status des Dienstes in Echtzeit zu überwachen. Bei der Verwendung eines einheitlichen Microservice-Frameworks gibt es ein ernstes Problem: Die Kosten für die Aktualisierung des Frameworks sind sehr hoch. Jedes Mal, wenn das Framework aktualisiert wird, müssen alle Anwendungsdienste mit dem Upgrade kooperieren. Natürlich wird im Allgemeinen eine Kompatibilitätslösung verwendet, die es ermöglicht, parallel auf die Aktualisierung aller Anwendungsdienste zu warten. Wenn jedoch viele Anwendungsdienste vorhanden sind, kann die Aktualisierungszeit sehr lang sein. Und es gibt einige sehr stabile Anwendungsdienste, die selten aktualisiert werden, und die verantwortliche Person weigert sich möglicherweise, ein Upgrade durchzuführen ... Daher erfordert die Verwendung eines einheitlichen Microservice-Frameworks vollständige Versionsverwaltungsmethoden und Entwicklungsverwaltungsspezifikationen. Eine andere Möglichkeit, allgemeinen Code zu abstrahieren, besteht darin, diesen Code direkt in eine Reverse-Proxy-Komponente zu abstrahieren. Jeder Dienst stellt zusätzlich diese Proxy-Komponente bereit, und der gesamte ausgehende und eingehende Datenverkehr wird über diese Komponente verarbeitet und weitergeleitet. Diese Komponente wird Sidecar genannt. Sidecar verursacht keine zusätzlichen Netzwerkkosten. Sidecar wird auf demselben Host wie der Microservice-Knoten bereitgestellt und nutzt dieselbe virtuelle Netzwerkkarte. Daher wird die Kommunikation zwischen Sidecar- und Microservice-Knoten tatsächlich nur durch Speicherkopien realisiert. Sidecar ist nur für die Netzwerkkommunikation verantwortlich. Außerdem wird eine Komponente benötigt, um die Konfiguration aller Sidecars einheitlich zu verwalten. In Service Mesh wird der für die Netzwerkkommunikation verantwortliche Teil als Datenebene und der für das Konfigurationsmanagement verantwortliche Teil als Steuerebene bezeichnet. Die Datenebene und die Steuerungsebene bilden die Grundarchitektur von Service Mesh. Der Vorteil von Service Mesh im Vergleich zum Microservice-Framework besteht darin, dass es nicht in den Code eindringt und einfacher zu aktualisieren und zu warten ist. Es wird oft wegen Leistungsproblemen kritisiert. Auch wenn das Loopback-Netzwerk keine tatsächlichen Netzwerkanforderungen generiert, fallen dennoch zusätzliche Kosten für die Speicherkopie an. Darüber hinaus wirkt sich auch eine gewisse zentralisierte Datenverkehrsverarbeitung auf die Leistung aus. Microservices sind nicht das Ende der Architekturentwicklung. Darüber hinaus gibt es Serverless, FaaS und andere Richtungen. Andererseits gibt es auch Leute, die singen, dass die Harmonie im Laufe der Zeit geteilt und die monolithische Architektur wiederentdeckt werden muss... Auf jeden Fall ist die Transformation der Microservice-Architektur vorerst abgeschlossen Sein. Xiao Ming tätschelte zufrieden seinen immer glatter werdenden Kopf und plante, dieses Wochenende eine Pause einzulegen und Xiao Hong auf eine Tasse Kaffee zu treffen.
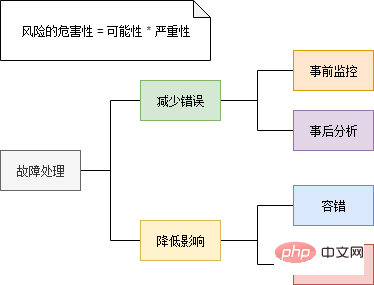
Überwachung – Anzeichen von Ausfällen entdecken 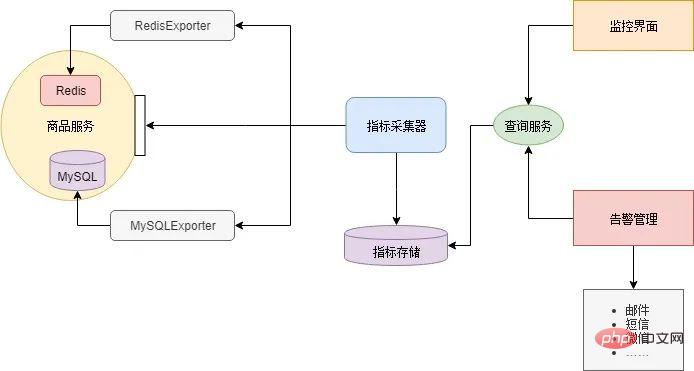
Standortproblem – Linkverfolgung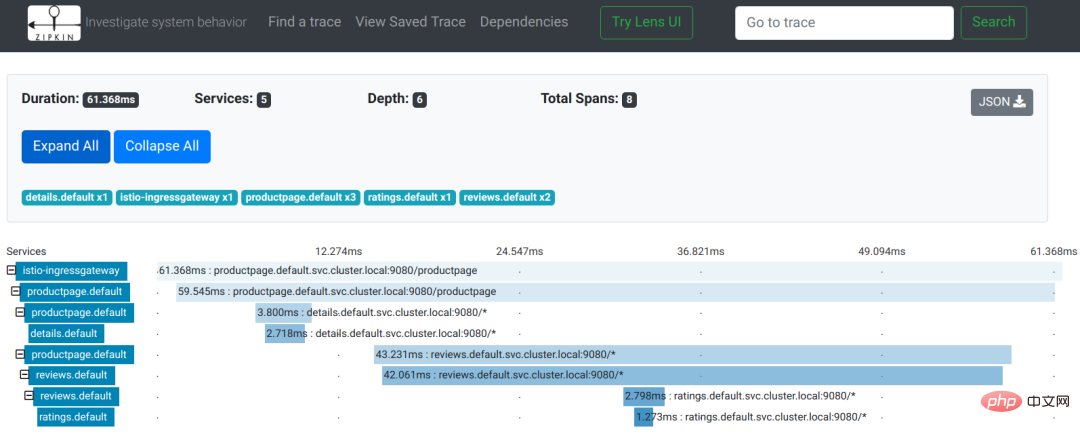
Das Bild stammt aus dem Istio-Dokument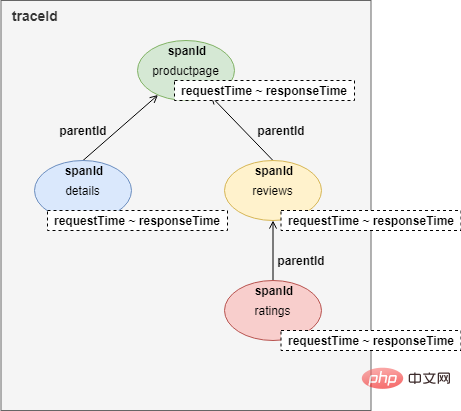
Um die Linkverfolgung zu implementieren, zeichnet jeder Serviceaufruf mindestens vier Datenelemente in HTTP-HEADERN auf:
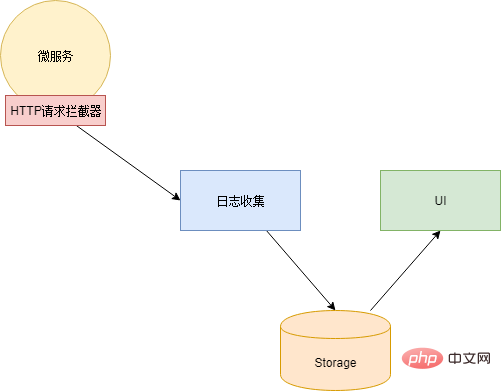
Das Obige ist nur eine minimalistische Erklärung. Die theoretische Grundlage für die Linkverfolgung finden Sie in Googles DapperAnalyseprobleme – Protokollanalyse
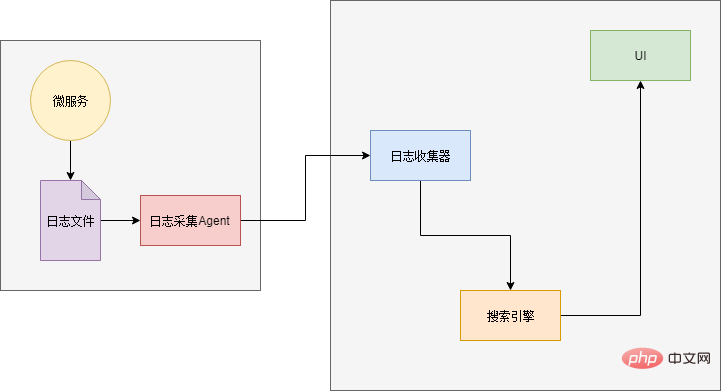
Xiao Ming hat die berühmte ELK-Protokollanalysekomponente untersucht und verwendet. ELK ist die Abkürzung für drei Komponenten: Elasticsearch, Logstash und Kibana.
Gateway – Berechtigungskontrolle, Service-Governance
Dienstregistrierung und -erkennung – dynamische ErweiterungEine neue Instanz bereitstellen
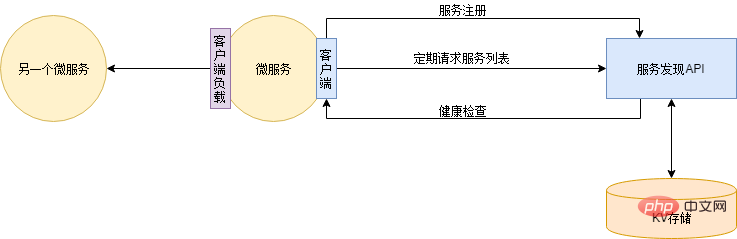
Für die Serviceerkennung stehen viele Komponenten zur Auswahl, z. B. Zookeeper, Eureka, Consul usw. Xiao Ming hatte jedoch das Gefühl, dass er ziemlich gut war und wollte seine Fähigkeiten unter Beweis stellen, also schrieb er eines auf der Grundlage von Redis ... Schaltkreise, Dienstverschlechterung, Strombegrenzung
Schaltkreise
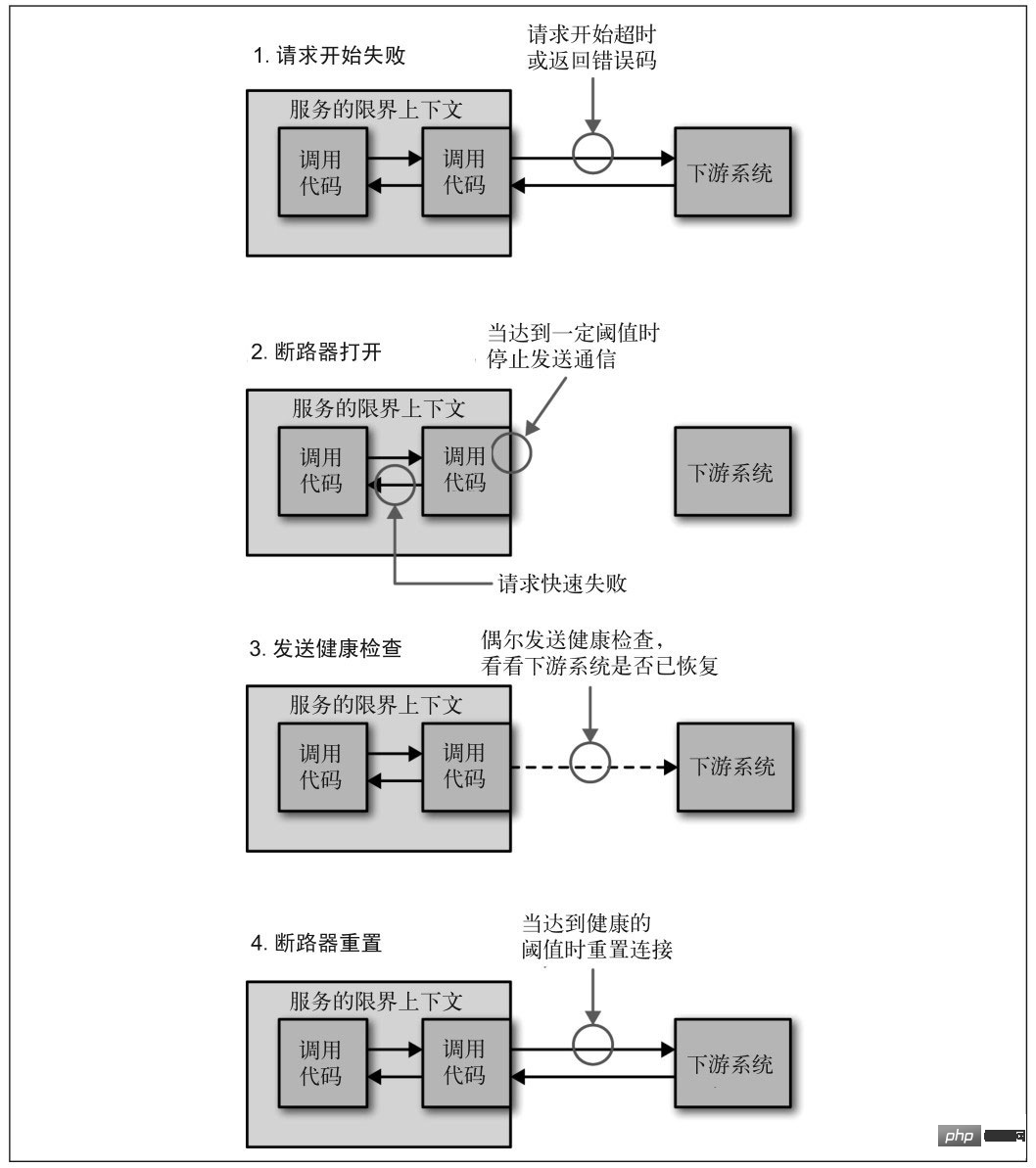 Strombegrenzung
Strombegrenzung
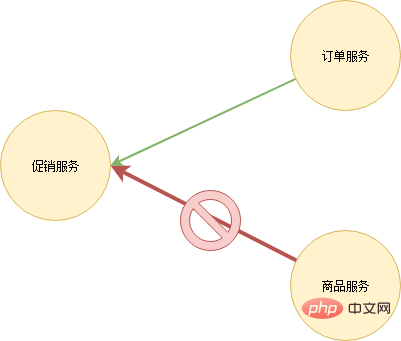
Testen
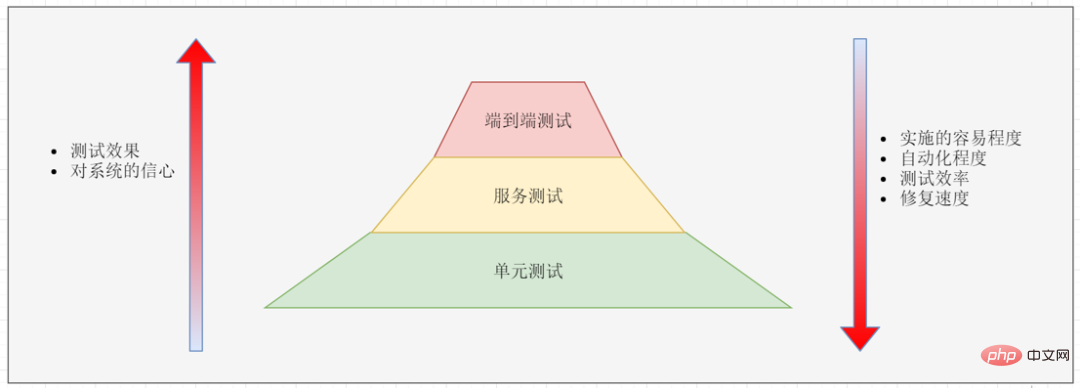
Aufgrund der Schwierigkeit, End-to-End-Tests zu implementieren, werden End-to-End-Tests im Allgemeinen nur für Kernfunktionen durchgeführt. Sobald ein End-to-End-Test fehlschlägt, muss er in Unit-Tests zerlegt werden: Dann wird der Grund für den Fehler analysiert und dann werden Unit-Tests geschrieben, um das Problem zu reproduzieren, damit wir denselben Fehler schneller erkennen können Zukunft. 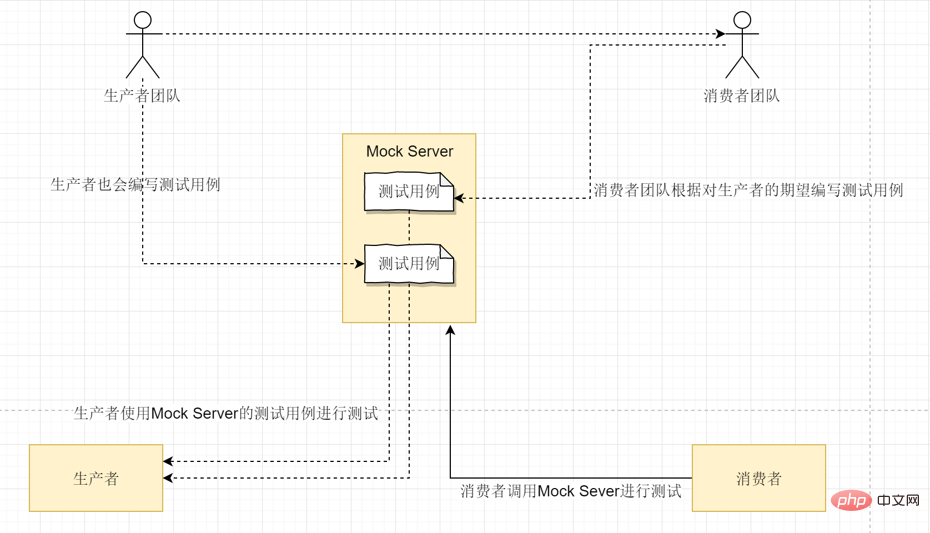
Jeder ist mit Unit-Tests vertraut. Wir schreiben im Allgemeinen eine große Anzahl von Komponententests (einschließlich Regressionstests), um zu versuchen, den gesamten Code abzudecken. Microservice-Framework
Eine andere Möglichkeit – Service Mesh
Bild aus: Muster: Service Mesh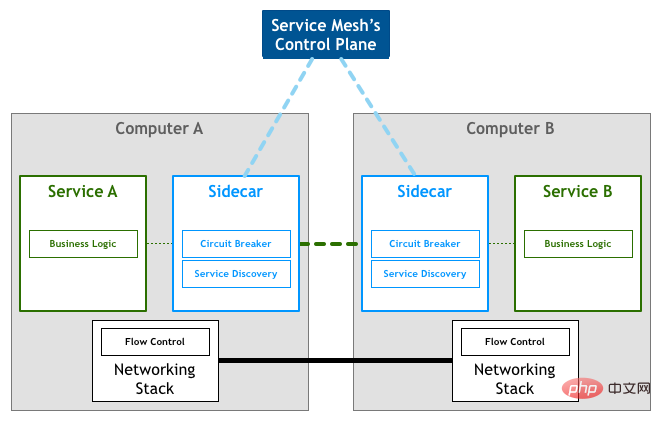
Bild von: Muster: Service MeshDas Ende ist auch der Anfang
Das obige ist der detaillierte Inhalt vonDies ist möglicherweise der ausführlichste Artikel über Microservice-Architektur, den Sie je gelesen haben.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- PHP und Lumen werden integriert, um die Entwicklung einer Microservice-Architektur zu realisieren
- So stellen Sie eine Microservices-Architektur unter Linux bereit
- So stellen Sie eine hochverfügbare Microservices-Architektur unter Linux bereit
- Die Praxis der Kombination von PHP-Nachrichtenwarteschlange und Microservice-Architektur
- Erkundung der Funktionen der Golang-Sprache: verteilte System- und Microservice-Architektur
- Erstellen Sie mit Golang und Vault eine hochsichere Microservices-Architektur