
Heim >Backend-Entwicklung >Python-Tutorial >Verwenden Sie einen Python-Webcrawler, um zu sehen, welche Filme derzeit in den Kinos laufen
Verwenden Sie einen Python-Webcrawler, um zu sehen, welche Filme derzeit in den Kinos laufen
- Go语言进阶学习nach vorne
- 2023-07-25 17:21:572065Durchsuche
/1 Vorwort/

/2 Projektziel/
Erhalten Sie Details zu kommenden Filmen von Maoyan Movies.
/3 Projektvorbereitung/
Software: PyCharm
Erforderliche Bibliotheken: re quests、lxml、zufällig、 Zeit
Plug-in: https://maoyan.com/films?showType=2&offset={}
Wenn Sie auf die nächste Seite klicken, erhöht sich der Offset=() für jede weitere Seite um 30, sodass Sie {} verwenden können, um die transformierte Variable zu ersetzen. Verwenden Sie dann eine for-Schleife, um die URL zu durchlaufen und mehrere URL-Anfragen zu implementieren.
1. Definieren Sie eine Klasse, um das Objekt zu erben, definieren Sie die Init-Methode, um sich selbst zu erben, und Hauptfunktion main sich selbst erben. Importieren Sie die erforderlichen Bibliotheken und URLs. Der Code lautet wie folgt.
import requests
from lxml import etree
import time
import random
class MaoyanSpider(object):
def __init__(self):
self.url = "https://maoyan.com/films?showType=2&offset={}"
def main(self):
pass
if __name__ == '__main__':
spider = MaoyanSpider()
spider.main()2、随机产生UserAgent。
for i in range(1, 50):
# ua.random,一定要写在这里,每次请求都会随机选择。
self.headers = {
'User-Agent': ua.random,
}3、发送请求,获取页面响应。
def get_page(self, url): # random.choice一定要写在这里,每次请求都会随机选择 res = requests.get(url, headers=self.headers) res.encoding = 'utf-8' html = res.text self.parse_page(html)
4、xpath解析一级页面数据,获取页面信息。
1)基准xpath节点对象列表。
# 创建解析对象 parse_html = etree.HTML(html) # 基准xpath节点对象列表 dd_list = parse_html.xpath('//dl[@class="movie-list"]//dd')
2)依次遍历每个节点对象,提取数据。
for dd in dd_list:
name = dd.xpath('.//div[@class="movie-hover-title"]//span[@class="name noscore"]/text()')[0].strip()
star = dd.xpath('.//div[@class="movie-hover-info"]//div[@class="movie-hover-title"][3]/text()')[1].strip()
type = dd.xpath('.//div[@class="movie-hover-info"]//div[@class="movie-hover-title"][2]/text()')[1].strip()
dowld=dd.xpath('.//div[@class="movie-item-hover"]/a/@href')[0].strip()
# print(movie_dict)
movie = '''【即将上映】5、定义movie,保存打印数据。
movie = '''【即将上映】
电影名字: %s
主演:%s
类型:%s
详情链接:https://maoyan.com%s
=========================================================
''' % (name, star, type,dowld)
print( movie)6、random.randint()方法,设置时间延时。
time.sleep(random.randint(1, 3))
7、调用方法,实现功能。
html = self.get_page(url) self.parse_page(html)
/5 Effektanzeige/
1 Klicken Sie auf das grüne Dreieck, um die Eingabe-Startseite und -Endseite auszuführen.
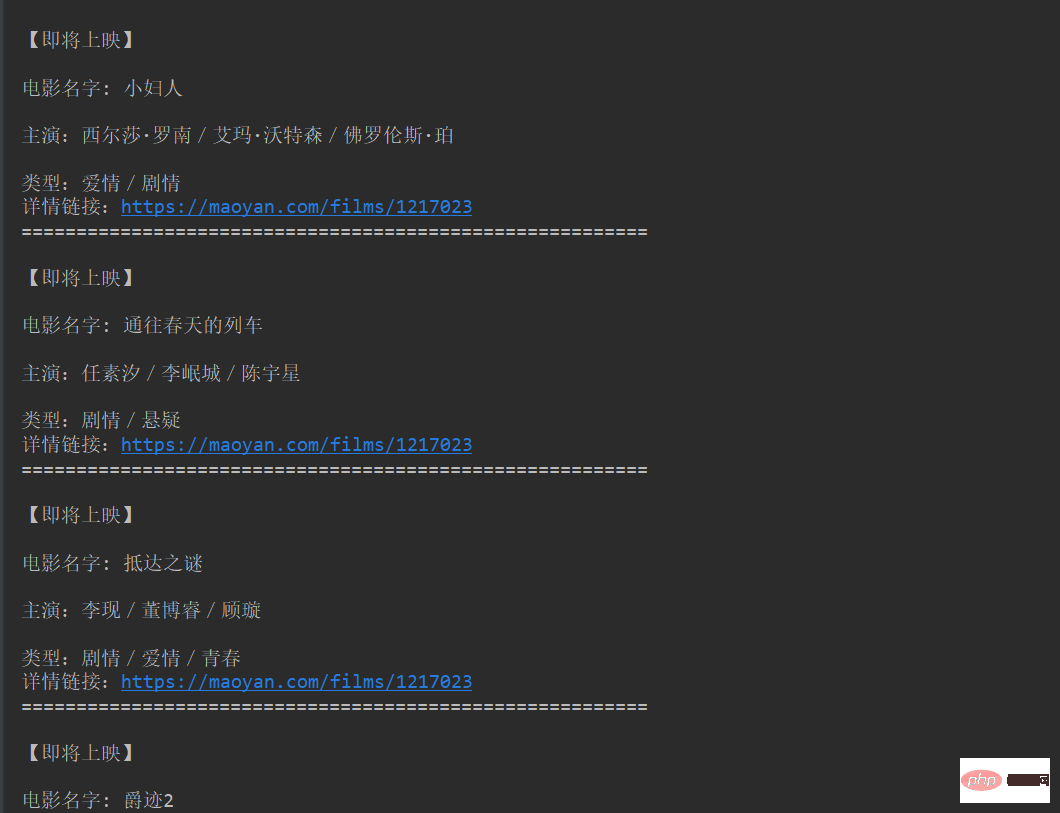
2. Nach dem Ausführen des Programms werden die Ergebnisse auf der Konsole angezeigt, wie in der Abbildung unten dargestellt.
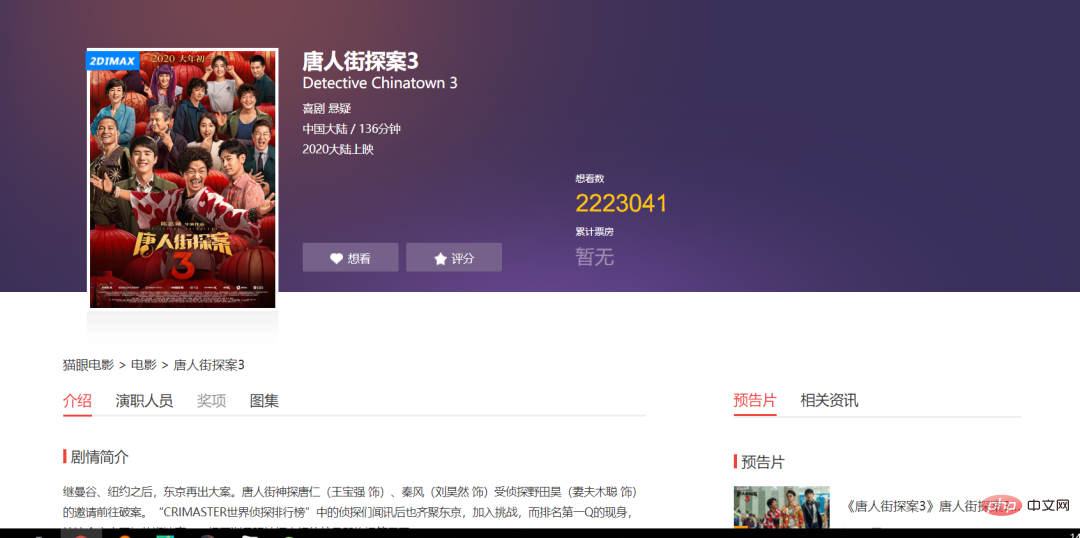
3. Klicken Sie auf den blauen Download-Link, um die Details online anzuzeigen.
/6 Zusammenfassung/
1 Es wird nicht empfohlen, zu viele Daten zu erfassen, da dies leicht zu einer Belastung des Servers führt.
2. Dieser Artikel basiert auf dem Python-Webcrawler und verwendet die Crawler-Bibliothek zum Crawlen von Maoyan-Filmen.
Das obige ist der detaillierte Inhalt vonVerwenden Sie einen Python-Webcrawler, um zu sehen, welche Filme derzeit in den Kinos laufen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Ein Artikel, der Ihnen hilft, rekursive Python-Funktionen zu verstehen
- Ein Artikel, der Ihnen hilft, das Iterationswissen von Python zu verstehen
- Ein Artikel führt Sie durch die Rückgabefunktionen von Python
- Bestandsaufnahme der häufigsten Verwendungen von dict und set in der Python-Programmierung
- Inventar von 7 häufig verwendeten Funktionen in der SYS-Bibliothek der Programmiersprache Python