
Heim >Backend-Entwicklung >Python-Tutorial >Eine Einführung in reguläre Ausdrücke und ihre allgemeinen Matching-Funktionen in Python
Eine Einführung in reguläre Ausdrücke und ihre allgemeinen Matching-Funktionen in Python
- Go语言进阶学习nach vorne
- 2023-07-25 17:17:081737Durchsuche
/Einführung/
Python hat seit Version 1.5 das re-Modul hinzugefügt, das Muster für reguläre Ausdrücke im Perl-Stil bereitstellt. Das re-Modul ermöglicht es der Python-Sprache, über alle regulären Ausdrucksfunktionen zu verfügen.
Die Kompilierungsfunktion generiert ein reguläres Ausdrucksobjekt basierend auf einer Musterzeichenfolge und optionalen Flag-Parametern. Dieses Objekt verfügt über eine Reihe von Methoden zum Abgleichen und Ersetzen regulärer Ausdrücke.
Das re-Modul bietet auch Funktionen, die genau mit diesen Methoden identisch sind. Diese Funktionen verwenden eine Musterzeichenfolge als ersten Parameter.
/re.match function/
re.match versucht, ein Muster von der Startposition der Zeichenfolge abzugleichen, wenn die Startposition nicht erfolgreich abgeglichen wird, gibt match() zurück keiner. Die Syntax lautet wie folgt:
re.match(pattern, string, flags=0)
„pattern“ stimmt mit dem regulären Ausdruck „string“ überein und die Zeichenfolge „flags“ markiert die Übereinstimmung.
Wenn die Übereinstimmung erfolgreich ist, gibt die re.match-Methode ein passendes Objekt zurück, andernfalls gibt sie None zurück.
Wir können die Matching-Objektfunktion „group(num)“ oder „groups()“ verwenden, um den passenden Ausdruck zu erhalten.
group(num=0) 匹配的整个表达式的字符串,“group()”可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。
下图是个实际例子:

输出结果如下图所示:

/检索和替换/
Python 的re模块提供了re.sub用于替换字符串中的匹配项。语法如下所示:
re.sub(pattern, repl, string, count=0, flags=0)
参数:
pattern : 正则中的模式字符串。
repl : 替换的字符串,也可为一个函数。
string : 要被查找替换的原始字符串。
count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
flags : 编译时用的匹配模式,数字形式。
前三个为必参数,后两个为可选参数。
下图是个实际例子:
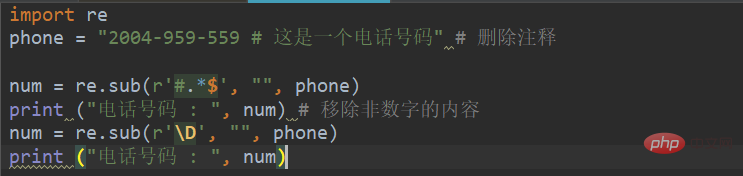
输出结果如下图所示:

/compile函数/
compile 函数用于编译正则表达式,供match() 和 search() 这两个函数使用。语法格式为:
re.compile(pattern[, flags])
参数:
pattern : 一个字符串形式的正则表达式
flags 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
re.I 忽略大小写
re.L stellt den Sonderzeichensatz w, W, b, B, s, S dar, abhängig von der aktuellen Umgebung
re.M Mehrzeilenmodus
re.S ist „ das Newline-Zeichen Jedes Zeichen einschließlich (' . 'ohne Zeilenumbrüche)
re.U stellt den Sonderzeichensatz w, W, b, B, d, D, s, S dar und basiert auf der Unicode-Zeichenattributdatenbank
re.
re.MatchObject: group() gibt die von RE übereinstimmende Zeichenfolge zurück. Start () Rückkehr zur Position des übereinstimmenden Starts
END () Gibt die Position der übereinstimmenden Position zurück – optionale Flags/
Reguläre Ausdrücke können einige optionale Flag-Modifikatoren enthalten, um die passenden Muster zu steuern. Der Modifikator wird als optionales Flag angegeben. Mehrere Flags können durch bitweises ODER(|) angegeben werden. Beispielsweise ist re.I |. re.M auf die I- und M-Flags gesetzt:
re.I |
macht die Übereinstimmung unabhängig von der Groß- und Kleinschreibung |
|
re. L |
führt eine Lokalisierungserkennung (gebietsbezogene) durch, die |
|
re abgleicht |
re. re.U Analysieren Sie Zeichen gemäß dem |
|
| -Zeichensatz. Dieses Zeichen betrifft w, W, b, B. | ||
re. |
/Muster für reguläre Ausdrücke/ Musterzeichenfolgen verwenden eine spezielle Syntax, um einen regulären Ausdruck darzustellen: Buchstaben und Zahlen repräsentieren sich selbst. Buchstaben und Zahlen in einem regulären Ausdrucksmuster stimmen mit derselben Zeichenfolge überein. Die meisten Buchstaben und Zahlen haben unterschiedliche Bedeutungen, wenn ihnen ein Backslash vorangestellt ist. Satzzeichen stimmen nur dann mit sich selbst überein, wenn sie maskiert sind, andernfalls stellen sie eine besondere Bedeutung dar. Der Backslash selbst muss mit einem Backslash maskiert werden. Da reguläre Ausdrücke normalerweise Backslashes enthalten, verwenden Sie für deren Darstellung besser rohe Zeichenfolgen. Musterelemente (z. B. r't', äquivalent zu \t) stimmen mit den entsprechenden Sonderzeichen überein. In der folgenden Tabelle sind die speziellen Elemente in der Mustersyntax für reguläre Ausdrücke aufgeführt. Wenn Sie ein Muster verwenden und optionale Flag-Argumente bereitstellen, ändert sich die Bedeutung einiger Musterelemente. ?? Python |
entspricht „Python“. |
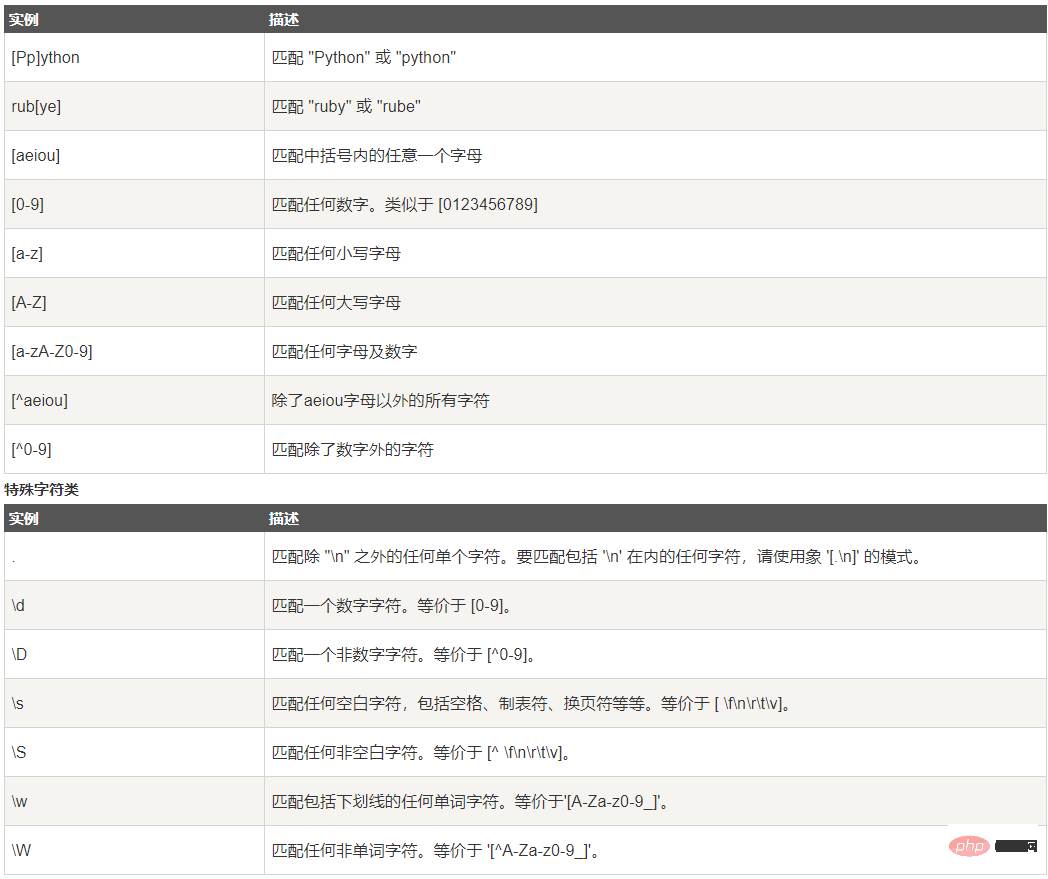
字符类
/实际应用/
以猫眼电影为例。我们需要获取(电影的名字作者,上映时间)等等都可以用正则表达式来解析。
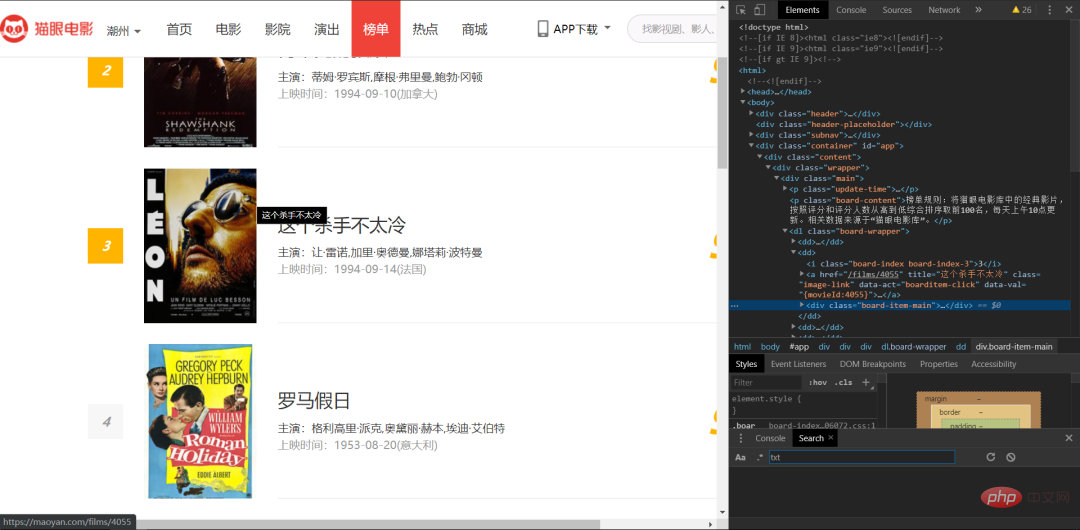
分析一下,利用正则表达式提取。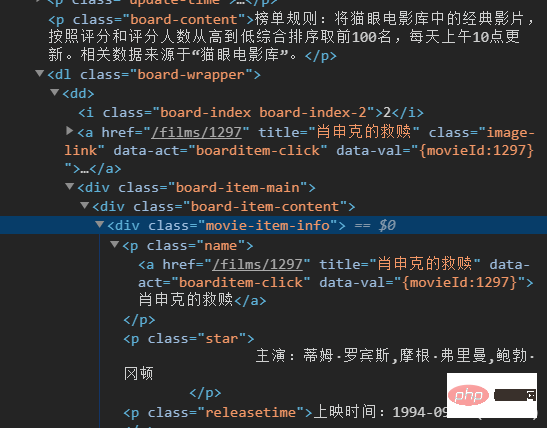
可以看到我们要的名字在一个a里面,而他们被一个div包裹着。
我们把div想象成一个盒子,可以看到div里面还有一个div 我们可以先找他上面一层的div是一个表单0d5affef54b5792b53e66baae815472b再找到它的上一层的盒子div7944fc67b6e5ce9f806e856ae5e703bc一般来说我们找到前两层就可以找到我们要的结果。如果不对就再找几层。
分析完再实际操作一下:
pattern = re.compile('<div>.*?title="(.*?)".*?class="star">(.*?)</p>.*?releasetime">(.*?)</p>',re.S)
(.*?)表示我们要的内容4dd738c46dabb06475883a3c3eaef79a(.*?)94b3e26ee717c64999d7867364b1b4a3里面的主演也是我们要的这样我们就可以得到我们想要得多个数据。
/小结/
1. Reguläre Ausdrücke eignen sich für Szenarien, in denen mehrere Daten abgerufen werden müssen. Es kann die gewünschten Daten schneller abrufen.
In diesem Artikel werden hauptsächlich reguläre Ausdrücke und ihre grundlegende Verwendung vorgestellt. Informationen zur spezifischen Verwendung der einzelnen Zeichen finden Sie in den Artikeln zu regulären Ausdrücken im Vorwort. Ich hoffe, dass sie jedem helfen können, die Verwendung regulärer Ausdrücke besser zu verstehen . .
Das obige ist der detaillierte Inhalt vonEine Einführung in reguläre Ausdrücke und ihre allgemeinen Matching-Funktionen in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Ein Artikel, der Ihnen hilft, das Iterationswissen von Python zu verstehen
- Bestandsaufnahme der Grundkenntnisse zur Definition von Funktionen in Python
- Ein Artikel führt Sie durch die Rückgabefunktionen von Python
- Bestandsaufnahme der häufigsten Verwendungen von dict und set in der Python-Programmierung
- Bestandsaufnahme von drei Methoden zur Python-Listengenerierung