
Heim >Backend-Entwicklung >Golang >Für die Golang-Leistungsdiagnose reicht es aus, diesen Artikel zu lesen
Für die Golang-Leistungsdiagnose reicht es aus, diesen Artikel zu lesen
- Go语言进阶学习nach vorne
- 2023-07-24 16:18:331908Durchsuche
 angezeigt werden. Die Szenarien, in denen Kontextwechsel stattfinden, sind wie folgt:
angezeigt werden. Die Szenarien, in denen Kontextwechsel stattfinden, sind wie folgt:
Die Zeitscheibe ist aufgebraucht und die CPU plant die nächste Aufgabe normal Wird von anderen Aufgaben mit höherer Priorität überholt
Die Ausführungsaufgabe stößt auf eine E/A-Blockierung, unterbricht die aktuelle Aufgabe und wechselt zur nächsten Aufgabe.
Benutzercode hängt aktiv Die aktuelle Aufgabe beansprucht die CPU
Multitasking beansprucht Ressourcen und wird ausgesetzt, da es nicht verfügbar ist
Hardware-Interrupt
Aus Sicht des Betriebssystems ist es wichtig, dass der Speicher ausreicht, um sicherzustellen, dass der Anwendungsprozess ausreichend ist. Sie können den Befehl free –m verwenden um die Speichernutzung zu überprüfen.
I/O umfasst Festplatten-I/O und Netzwerk-I/O. Im Allgemeinen sind Festplatten anfälliger für I/O-Engpässe. Sie können den Lese- und Schreibstatus der Festplatte über
überprüfen und anhand der E/A-Wartezeit der CPU sehen, ob die Festplatten-E/A normal ist. Wenn sich die Festplatten-E/A immer in einem hohen Zustand befindet, bedeutet dies, dass die Festplatte zu langsam oder fehlerhaft ist und zu einem Leistungsengpass geworden ist. Eine Anwendungsoptimierung oder ein Festplattenaustausch ist erforderlich.
Zusätzlich zu den häufig verwendeten Befehlen wie top, ps, vmstat, iostat usw. gibt es andere Linux-Tools, die Systemprobleme diagnostizieren können, wie mpstat, tcpdump, netstat, pidstat, sar und andere Linux-Leistungsdiagnosetools wie unten gezeigt: 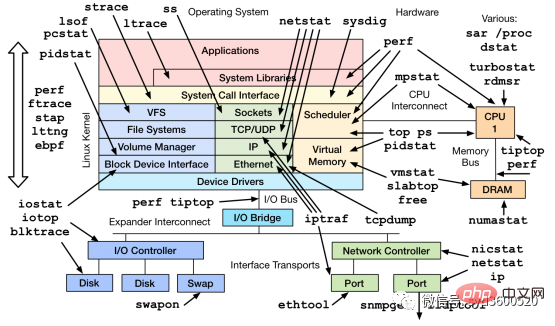
- Tracing ist eine Methode zur Codeerkennung, die zur Analyse verwendet wird Anrufe oder Benutzer Verzögerungen während der gesamten Lebensdauer der Anfrage und können sich über mehrere Go-Prozesse erstrecken.
2.1 Profilierung
1. Der erste Profiling-Code ist in
import _ "net/http/pprof"
func main() {
go func() {
log.Println(http.ListenAndServe("0.0.0.0:9090", nil))
}()
...
} vergraben. 2. Speichern Sie das Profil zu einem bestimmten Zeitpunkt, z. B. zum Speichern von Heap-Informationen 3. Verwenden Sie das Go-Tool pprof, um den gespeicherten Profil-Snapshot zu analysieren, z. B. die Analyse der oben genannten Heap-Informationen Funktionsausführungsproblem
Das Problem der übermäßigen PU-Nutzung
curl http://localhost:6060/debug/pprof/heap --output heap.tar.gz
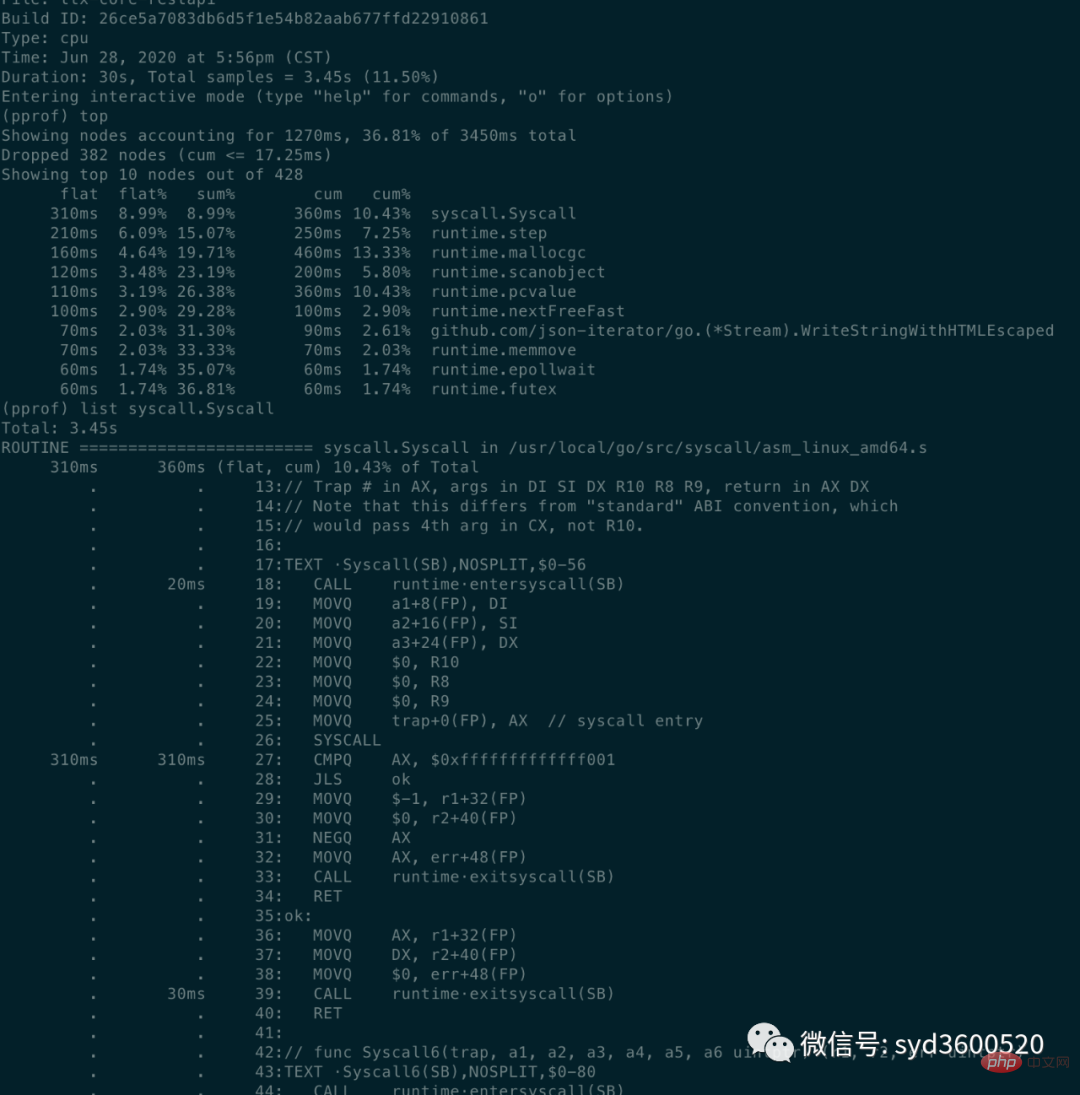
Befehlszeilenmethode: Häufige Befehls-Top-Listenspurentop: Zeigen Sie die Top-10-Funktionsinformationen sortiert nach der Menge an Speicher oder CPU an, die sie belegen
flat: Die aktuelle Funktion belegt CPU-Zeit ( umfasst keine anderen aufgerufenen Funktionen
flat%: Der Prozentsatz der von der aktuellen Funktion verwendeten CPU an der gesamten CPU-Zeit
cum: kumulativer Betrag, wie lange die aktuelle Funktion und ihre Unterfunktionen die CPU belegen
cum%: kumulativer Betrag als Prozentsatz der Gesamtsummecum>=flat
list: 查看某个函数的代码 以及该函数每行代码的指标信息
traces:打印所有函数调用栈 以及调用栈的指标信息
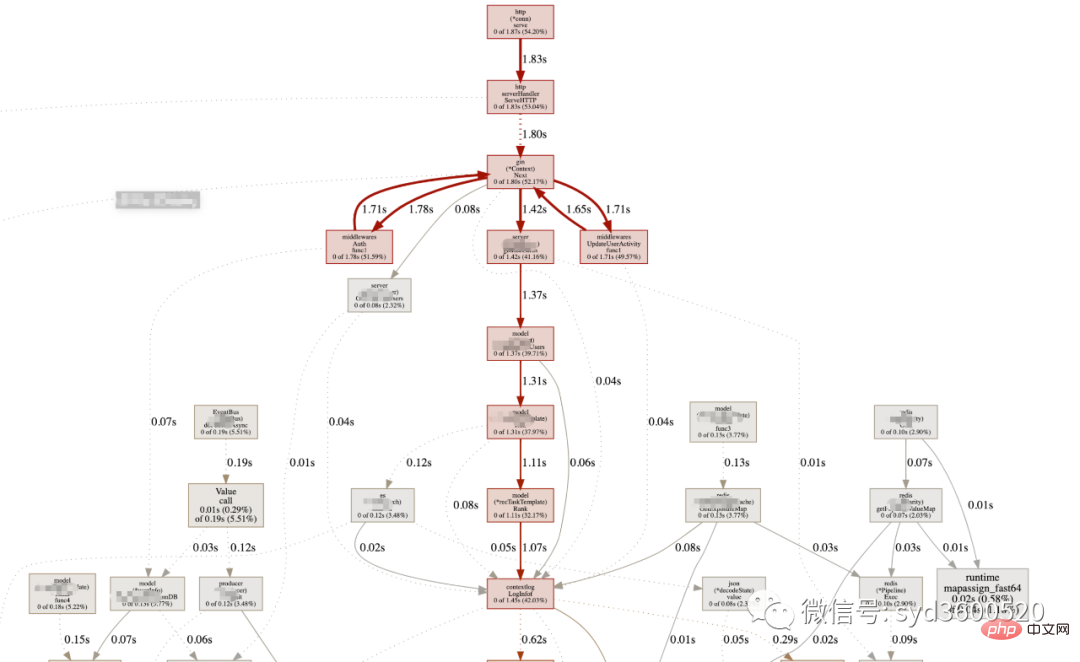
UI界面方式:从服务器download下生成的sample文件
go tool pprof -http=:8080 pprof.xxx.samples.cpu.001.pb.gz
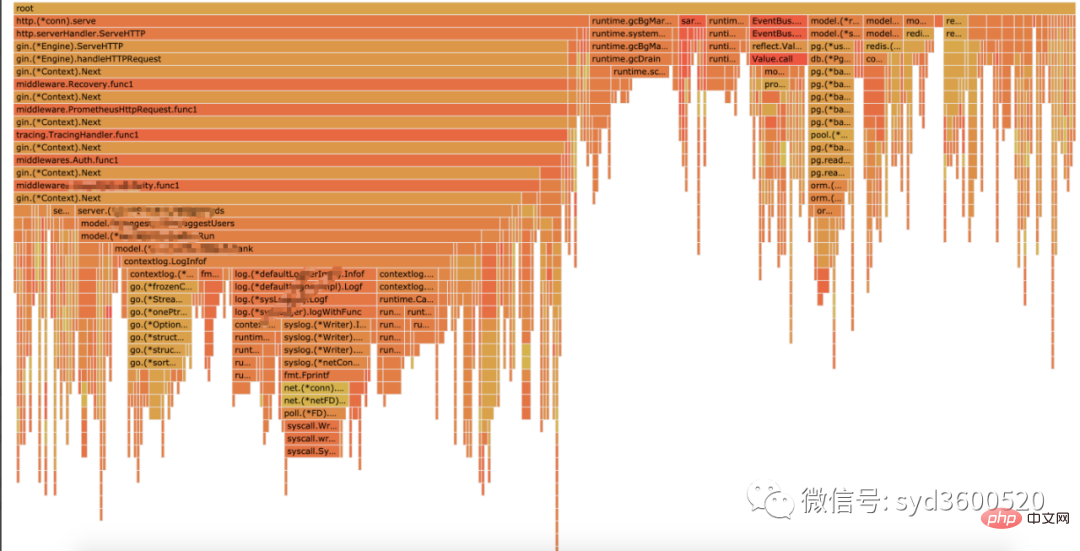
Flame graph很清晰得可以看到当前CPU被哪些函数执行栈占用
1.2 Heap Profiling
go tool pprof http://localhost:6060/debug/pprof/heap?second=10
命令行 UI查看方式 同理
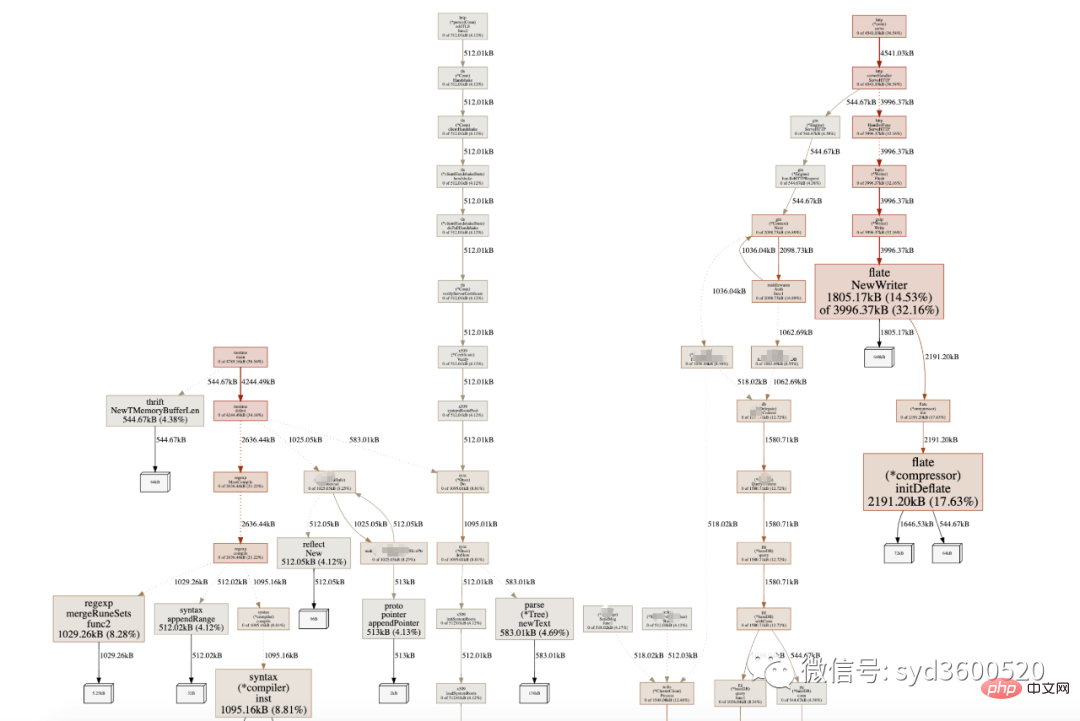

graph中方框越大 占用内存越多 火焰图 宽度越大 占用内存越多
SAMPLE->inuse_objects可以查看当前的对象数量 这个参数对于分析gc线程占用较高cpu时很有用处 它侧重查看对象数量
inuse_space图可以查看具体的内存占用
毕竟对于10个100m的对象和1亿个10字节的对象占用内存几乎一样大,但是回收起来一亿个小对象肯定比10个大对象要慢很多。
go tool pprof -inuse_space http://localhost:6060/debug/pprof/heap : 分析应用程序的常驻内存占用情况 (默认) go tool pprof -alloc_objects http://localhost:6060/debug/pprof/heap: 分析应用程序的内存临时分配情况
1.3 并发请求问题 查看方式跟上面类似。
go tool pprof http://localhost:6060/debug/pprof/goroutine go tool pprof http://localhost:6060/debug/pprof/block go tool pprof http://localhost:6060/debug/pprof/mutex
2.2 tracing
trace并不是万能的,它更侧重于记录分析 采样时间内运行时系统具体干了什么。
收集trace数据的三种方式:
1. 使用runtime/trace包 调用trace.Start()和trace.Stop()
2. 使用go test -trace=28897b20adb25fbae118a3f80f538dec测试标识
3. 使用debug/pprof/trace handler 获取运行时系统最好的方法
例如,通过
go tool pprof http://localhost:6060/debug/pprof/trace?seconds=20 > trace.out
获取运行时服务的trace信息,使用
go tool trace trace.out
会自动打开浏览器展示出UI界面
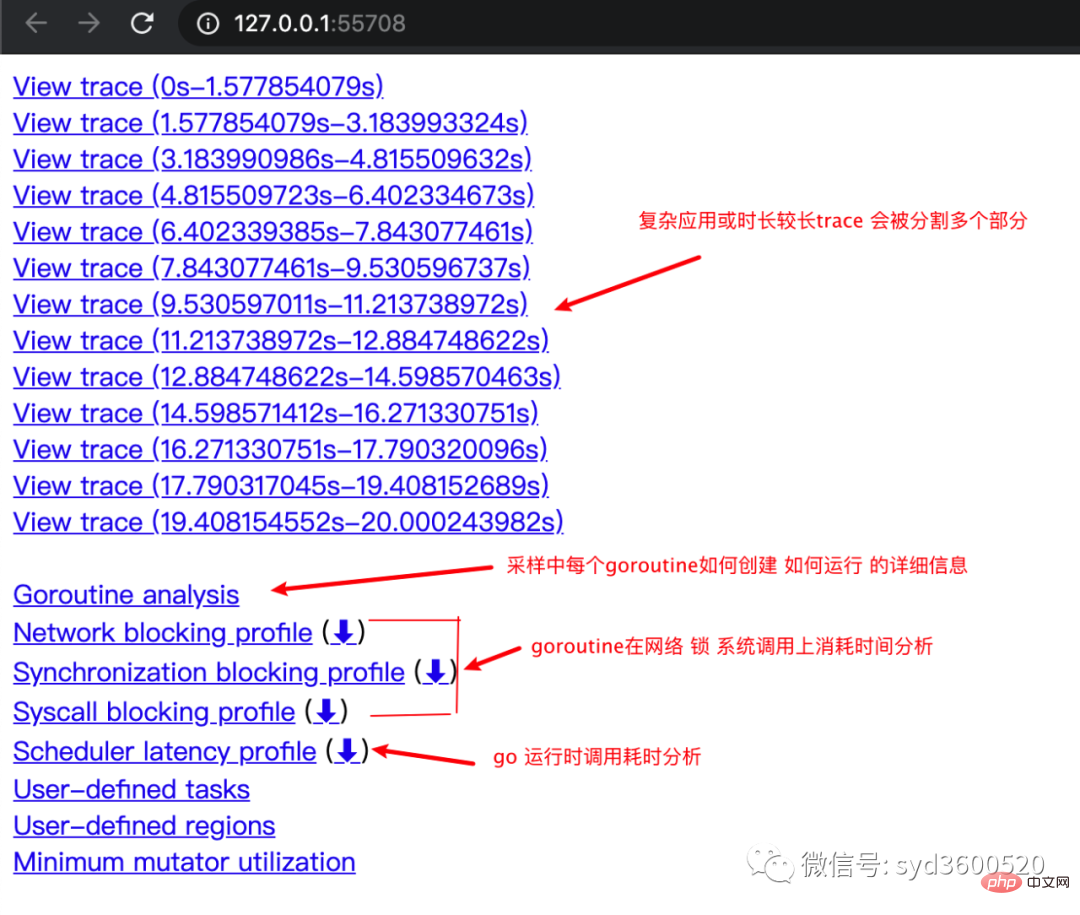
其中trace view 只能使用chrome浏览器查看,这里go截止1.14版本存在一个 bug,解决办法如下:
go tool trace trace.out 无法查看trace view go bug:https://github.com/golang/go/issues/25151 mac 解决版本:安装gotip go get golang.org/dl/gotip gotip download then 使用 gotip tool trace trace.out即可
获取的trace.out 二进制文件也可以转化为pprof格式的文件
go tool trace -pprof=TYPE trace.out > TYPE.pprof Tips:生成的profile文件 支持 network profiling、synchronization profiling、syscall profiling、scheduler profiling go tool pprof TYPE.pprof
使用gotip tool trace trace.out可以查看到trace view的丰富操作界面:
操作技巧:
ctrl + 1 选择信息
ctrl + 2 移动选区
ctrl + 3 放大选区
ctrl + 4 指定选区区间
shift + ? 帮助信息
AWSD跟游戏快捷键类似 玩起来跟顺手
整体的控制台信息 如下图:
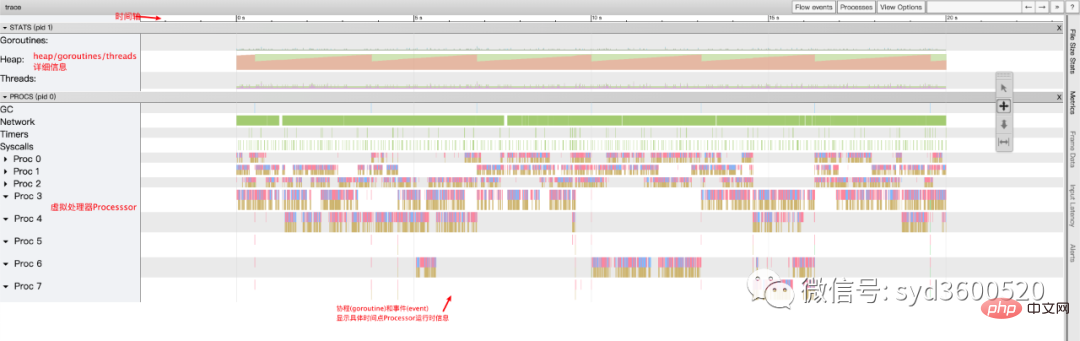
时间线: 显示执行的时间单元 根据时间的纬度不同 可以调整区间
堆: 显示执行期间内存的分配和释放情况
协程(Goroutine): 显示每个时间点哪些Goroutine在运行 哪些goroutine等待调度 ,其包含 GC 等待(GCWaiting)、可运行(Runnable)、运行中(Running)这三种状态。
goroutine区域选中时间区间
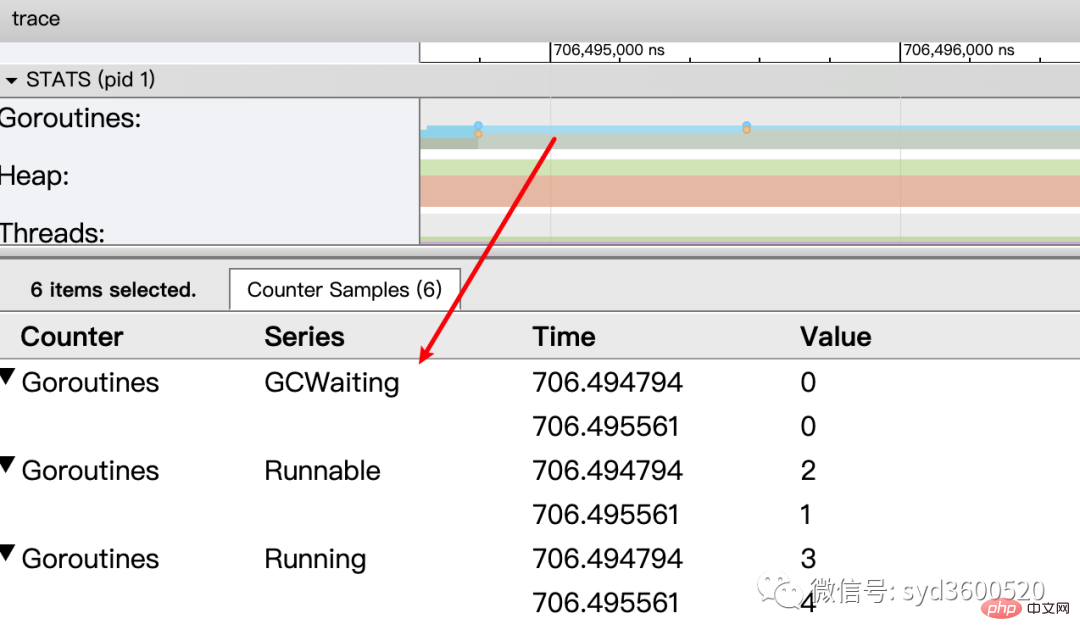
OS线程(Machine): 显示在执行期间有多少个线程在运行,其包含正在调用 Syscall(InSyscall)、运行中(Running)这两种状态。
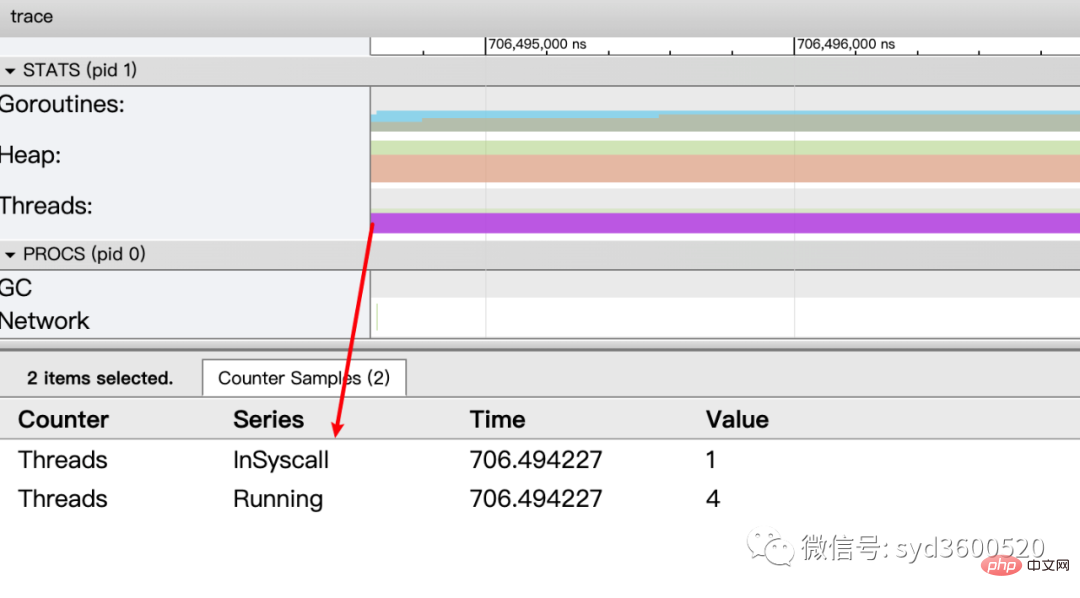
虚拟处理器Processor: 每个虚拟处理器显示一行,虚拟处理器的数量一般默认为系统内核数。数量由环境变量GOMAXPROCS控制
协程和事件: 显示在每个虚拟处理器上有什么 Goroutine 正在运行,而连线行为代表事件关联。
每个Processor分两层,上一层表示Processor上运行的goroutine的信息,下一层表示processor附加的事件比如SysCall 或runtime system events
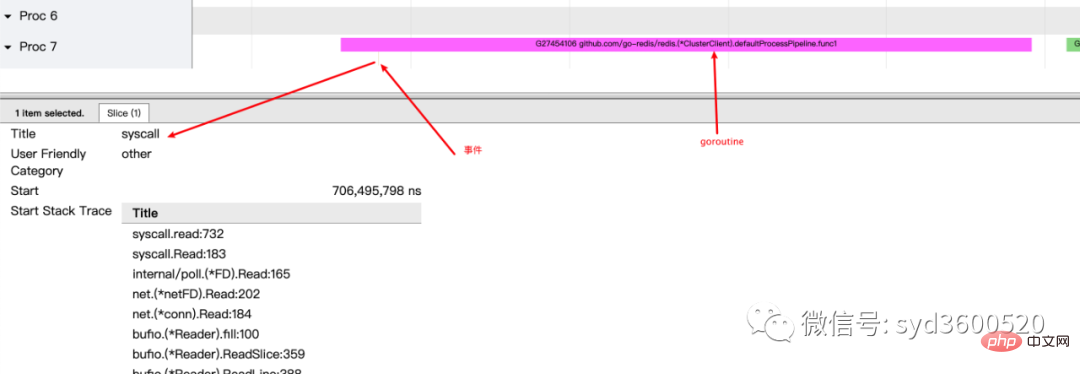
ctrl+3 放大选区,选中goroutine 可以查看,特定时间点 特定goroutine的执行堆栈信息以及关联的事件信息
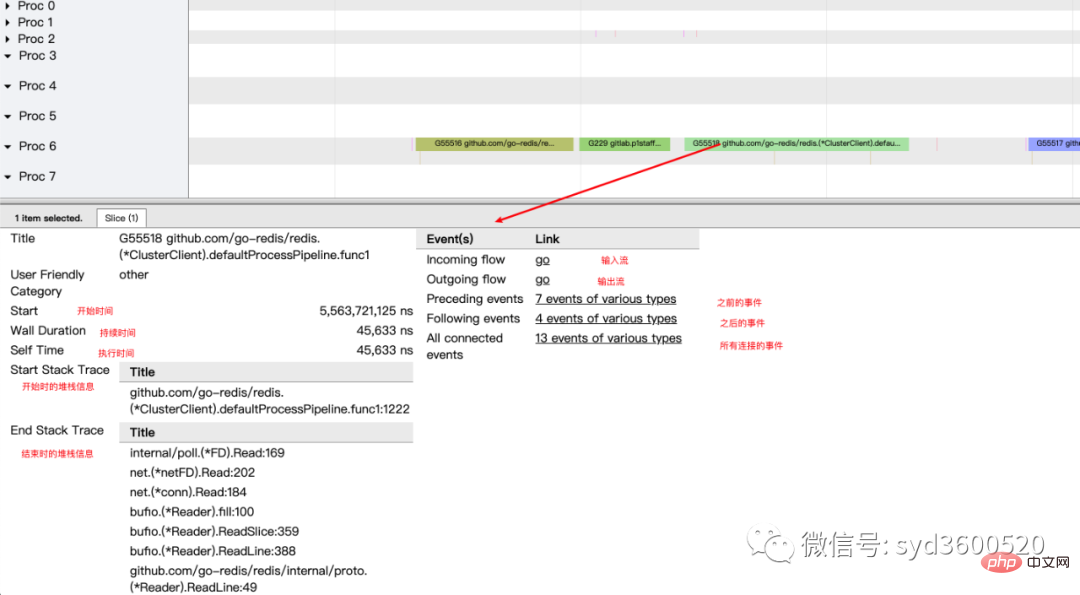
goroutine analysis
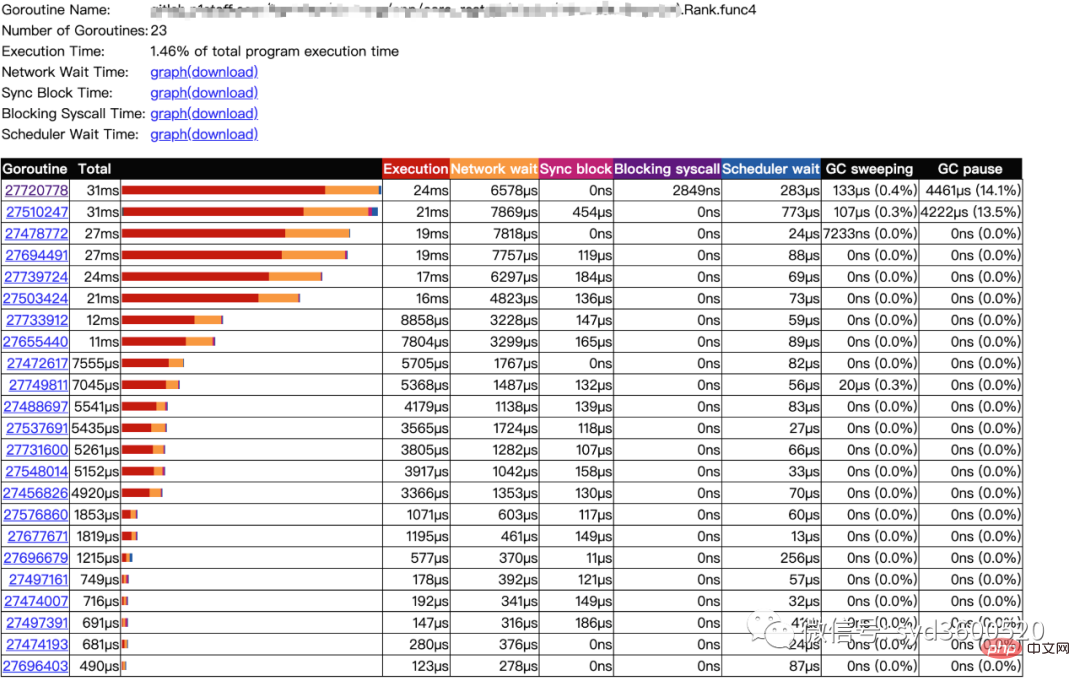
点击goroutine的id 可以跳到trace view 详细查看goroutine具体干了什么
| 名称 |
含义 |
| Execution | 执行时间 |
| Network wait | 网络等待时间 |
| Sync Block | 同步阻塞时间 |
| Blocking syscall | 系统调用阻塞时间 |
| Scheduler wait | 调度等待时间 |
| GC Sweeping | GC清扫时间 |
| GC Pause | GC暂停时间 |
实践 一个延迟问题诊断
当我们一个执行关键任务的协程从运行中被阻塞。这里可能的原因:被syscall阻塞 、阻塞在共享内存(channel/mutex etc)、阻塞在运行时(如 GC)、甚至有可能是运行时调度器不工作导致的。这种问题使用pprof很难排查,
使用trace只要我们确定了时间范围就可以在proc区域很容易找到问题的源头

上图可见,GC 的MARK阶段阻塞了主协程的运行
2.3 GC
初始所有对象都是白色
Stack scan阶段:从root出发扫描所有可达对象,标记为灰色并放入待处理队列;root包括全局指针和goroutine栈上的指针
Mark阶段:1.从待处理队列取出灰色对象,将其引用的对象标记为灰色并放入队列,自身标记为黑色 2. re-scan全局指针和栈,因为mark和用户程序并行运行,故过程1的时候可能会有新的对象分配,这时需要通过写屏障(write barrier)记录下来;re-scan再完成检查;
重复步骤Mark阶段,直到灰色对象队列为空,执行清扫工作(白色即为垃圾对象)
GC即将开始时,需要STW 做一些准备工作, 如enable write barrier
re-scan也需要STW,否则上面Mark阶段的re-scan无法终止
通过GODEBUG=gctrace=1可以开启gc日志,查看gc的结果信息
$ GODEBUG=gctrace=1 go run main.go gc 1 @0.001s 19%: 0.014+3.7+0.015 ms clock, 0.11+2.8/5.7/3.2+0.12 ms cpu, 5->6->6 MB, 6 MB goal, 8 P gc 2 @0.024s 6%: 0.004+3.4+0.010 ms clock, 0.032+1.4/4.5/5.3+0.085 ms cpu, 13->14->13 MB, 14 MB goal, 8 P gc 3 @0.093s 3%: 0.004+6.1+0.027 ms clock, 0.032+0.19/11/15+0.22 ms cpu, 24->25->22 MB, 26 MB goal, 8 P scvg: 0 MB released scvg: inuse: 4, idle: 58, sys: 63, released: 58, consumed: 4 (MB) scvg: 0 MB released scvg: inuse: 4, idle: 58, sys: 63, released: 58, consumed: 4 (MB) scvg: 0 MB released scvg: inuse: 4, idle: 58, sys: 63, released: 58, consumed: 4 (MB) scvg: 0 MB released scvg: inuse: 4, idle: 58, sys: 63, released: 58, consumed: 4 (MB)
格式
gc # @#s #%: #+#+# ms clock, #+#/#/#+# ms cpu, #->#-># MB, # MB goal, # P
含义
gc#:GC 执行次数的编号,每次叠加。
@#s:自程序启动后到当前的具体秒数。
#%:自程序启动以来在GC中花费的时间百分比。
#+...+#:GC 的标记工作共使用的 CPU 时间占总 CPU 时间的百分比。
#->#-># MB:分别表示 GC 启动时, GC 结束时, GC 活动时的堆大小.
#MB goal:下一次触发 GC 的内存占用阈值。
#P:当前使用的处理器 P 的数量。
https://github.com/felixge/fgprof 给出了一个解决方案:
具体用法:
package main
import(
_ "net/http/pprof"
"github.com/felixge/fgprof"
)
func main() {
http.DefaultServeMux.Handle("/debug/fgprof", fgprof.Handler())
go func() {
log.Println(http.ListenAndServe(":6060", nil))
}()
// <code to profile>
}
git clone https://github.com/brendangregg/FlameGraph
cd FlameGraph
curl -s 'localhost:6060/debug/fgprof?seconds=3' > fgprof.fold
./flamegraph.pl fgprof.fold > fgprof.svg如果遇到这种CPU消耗型和非CPU消耗型混合的情况下 可以试试排查下。
Das obige ist der detaillierte Inhalt vonFür die Golang-Leistungsdiagnose reicht es aus, diesen Artikel zu lesen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!