
Heim >Backend-Entwicklung >Python-Tutorial >Bringen Sie Ihnen Schritt für Schritt bei, wie Sie mit dem Python-Webcrawler Fondsinformationen abrufen
Bringen Sie Ihnen Schritt für Schritt bei, wie Sie mit dem Python-Webcrawler Fondsinformationen abrufen
- Go语言进阶学习nach vorne
- 2023-07-24 14:53:20944Durchsuche
1. Einleitung
Vor ein paar Tagen kam ein Fan zu mir, um sich über den Fonds zu informieren. Ich werde es hier auch teilen.
2. Datenerfassung
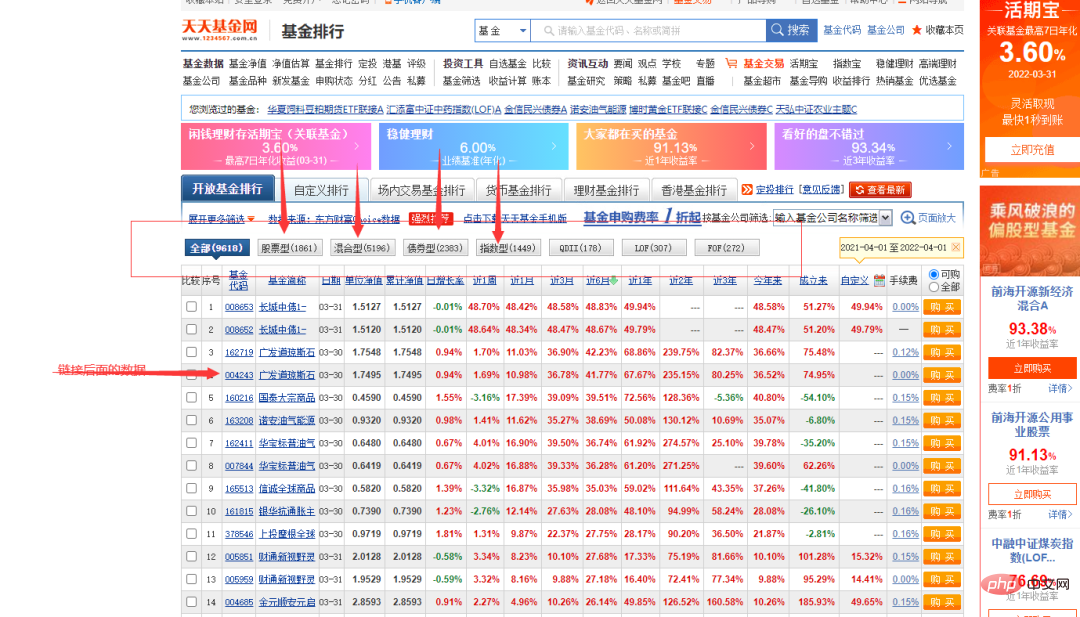
Hier ist unsere Zielwebsite die offizielle Website eines Fonds, und die Daten, die erfasst werden müssen, sind in der folgenden Abbildung dargestellt.
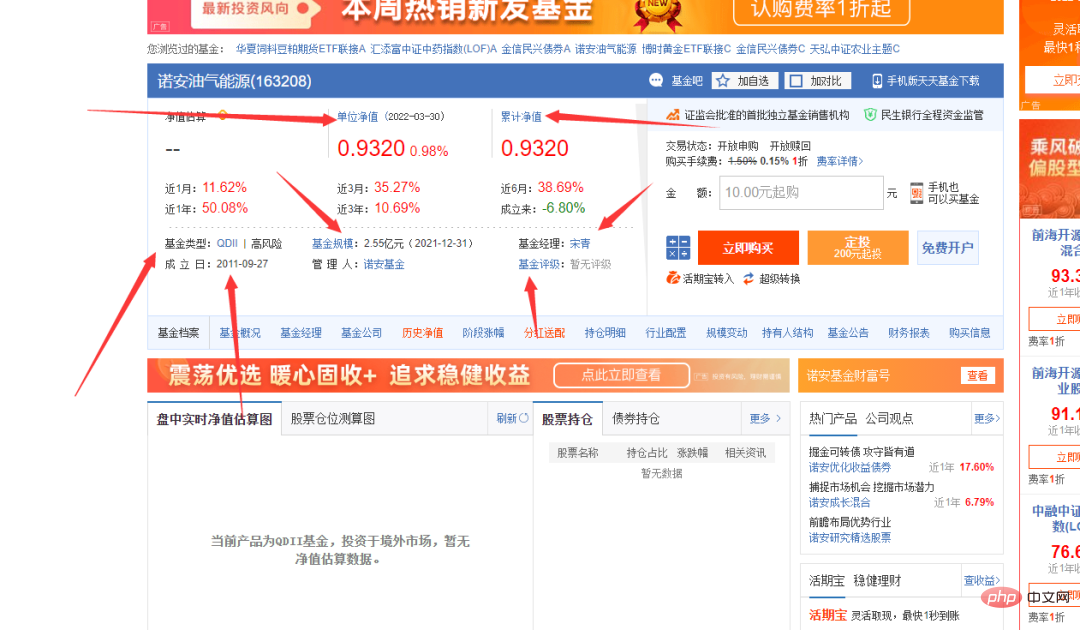 Sie können sehen, dass die Fondscode-Spalte im Bild oben unterschiedliche Nummern enthält. Klicken Sie zufällig auf eine, um zur Fondsdetailseite zu gelangen. Die Links sind ebenfalls sehr regelmäßig, mit dem Fondscode als Symbol.
Sie können sehen, dass die Fondscode-Spalte im Bild oben unterschiedliche Nummern enthält. Klicken Sie zufällig auf eine, um zur Fondsdetailseite zu gelangen. Die Links sind ebenfalls sehr regelmäßig, mit dem Fondscode als Symbol.
Tatsächlich ist diese Website nicht verschlüsselt. Die Informationen auf der Webseite sind direkt im Quellcode zu sehen. 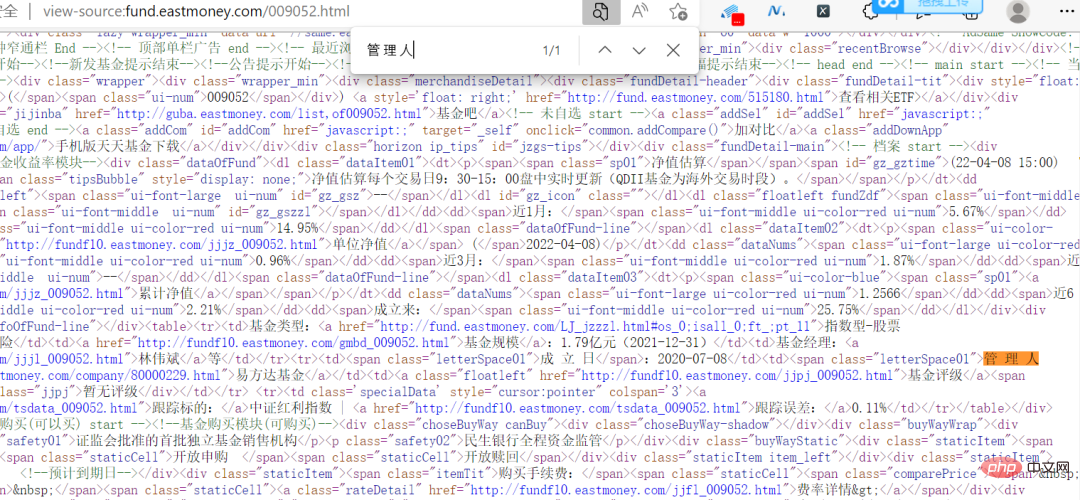
Dies verringert die Schwierigkeit beim Krabbeln. Durch die Browser-Paketerfassungsmethode können Sie die spezifischen Anforderungsparameter anzeigen und sehen, dass sich nur pi in den Anforderungsparametern ändert und dieser Wert zufällig der Seite entspricht, sodass Sie die Anforderungsparameter direkt erstellen können. 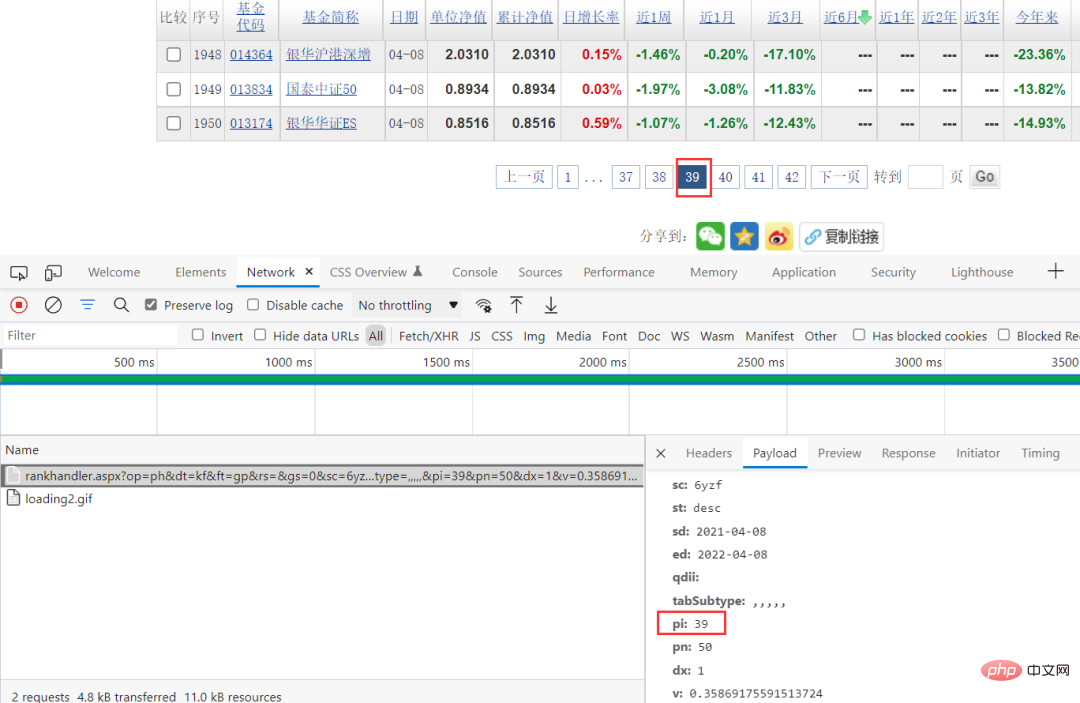
Code-Implementierungsprozess
Nachdem wir die Datenquelle gefunden haben, besteht der nächste Schritt darin, den Code zu implementieren. Hier sind einige Schlüsselcodes.
Holen Sie sich die Aktien-ID-Daten
response = requests.get(url, headers=headers, params=params, verify=False)
pattern = re.compile(r'.*?"(?P<items>.*?)".*?', re.S)
result = re.finditer(pattern, response.text)
ids = []
for item in result:
# print(item.group('items'))
gp_id = item.group('items').split(',')[0]Das Ergebnis ist wie in der Abbildung unten dargestellt:
Erstellen Sie dann den Link zur Detailseite, um die Fondsinformationen auf der Detailseite zu erhalten :
response = requests.get(url, headers=headers) response.encoding = response.apparent_encoding selectors = etree.HTML(response.text) danweijingzhi1 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[1]/text()')[0] danweijingzhi2 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[2]/text()')[0] leijijingzhi = selectors.xpath('//dl[@class="dataItem03"]/dd[1]/span/text()')[0] lst = selectors.xpath('//div[@class="infoOfFund"]/table//text()')
Das Ergebnis ist wie in der folgenden Abbildung dargestellt:
 Verarbeiten Sie die spezifischen Informationen in entsprechende Zeichenfolgen und speichern Sie sie dann in der
Verarbeiten Sie die spezifischen Informationen in entsprechende Zeichenfolgen und speichern Sie sie dann in der csv-Datei. Das Ergebnis ist wie folgt:
 Damit können Sie Folgendes tun weitere Statistiken und Datenanalysen.
Damit können Sie Folgendes tun weitere Statistiken und Datenanalysen.
3. Zusammenfassung
Hallo zusammen, ich bin ein fortgeschrittener Python-Mensch. In diesem Artikel wird hauptsächlich die Verwendung des Python-Webcrawlers zum Abrufen von Fondsdateninformationen beschrieben. Dieses Projekt ist nicht allzu schwierig, es gibt jedoch einige Fallstricke. Wenn Sie auf Probleme stoßen, fügen Sie mich bitte als Freund hinzu Ich werde helfen, es zu lösen.
Dieser Artikel erfasst hauptsächlich die Klassifizierung von [Aktientyp]. Sie können es gerne versuchen. Tatsächlich ist die Logik dieselbe, ändern Sie einfach die Parameter. 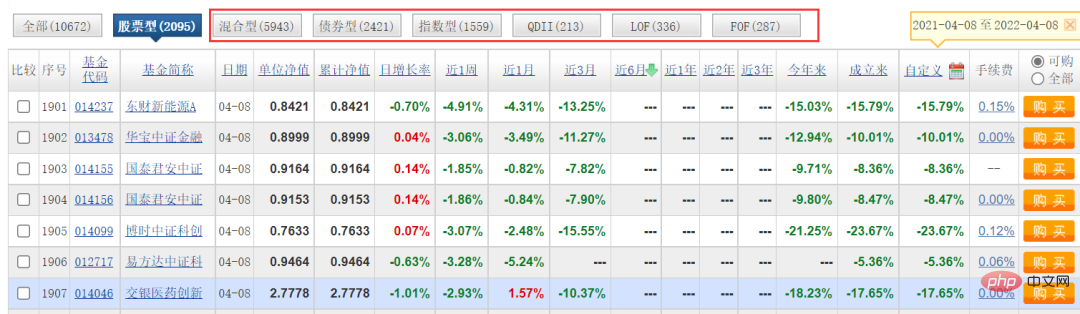
Das obige ist der detaillierte Inhalt vonBringen Sie Ihnen Schritt für Schritt bei, wie Sie mit dem Python-Webcrawler Fondsinformationen abrufen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Verwenden von Python und WebDriver zum Implementieren der Screenshot-Funktion für Webseiten
- Verwenden Sie Python- und WebDriver-Erweiterungen, um Drag-and-Drop-Vorgänge auf Webseiten zu automatisieren
- Gibt es eine Linux-Version von Python?
- Python in ausführbare Datei gepackt
- So packen Sie Python in eine ausführbare Datei