
Heim >Betrieb und Instandhaltung >Sicherheit >Uber-Praxis: Einige Erfahrungen im Betrieb und der Wartung großer verteilter Systeme
Uber-Praxis: Einige Erfahrungen im Betrieb und der Wartung großer verteilter Systeme

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-09 16:53:49890Durchsuche
Dieser Artikel wurde von Gergely Orosz, einem Ingenieur bei Uber, verfasst. Die ursprüngliche Adresse lautet: https://blog.pragmaticengineer.com/operating-a-high-scale-distributed-system/
In den letzten Jahren Ich habe ein großes verteiltes System aufgebaut und betrieben: das Zahlungssystem von Uber. In dieser Zeit habe ich viel über verteilte Architekturkonzepte gelernt und die Herausforderungen beim Betrieb von Hochlast- und Hochverfügbarkeitssystemen aus erster Hand miterlebt (ein System ist noch lange nicht fertig, wenn es entwickelt wird, und die Herausforderungen beim Online-Betrieb sind es tatsächlich). noch größer). Der Aufbau des Systems selbst ist ein interessantes Unterfangen. Die Planung, wie das System mit einem 10- bzw. 100-fachen Anstieg des Datenverkehrs umgehen kann, die Sicherstellung der Datenhaltbarkeit, der Umgang mit Hardwareausfällen usw. erfordert Weisheit. Unabhängig davon war der Betrieb großer verteilter Systeme für mich eine augenöffnende Erfahrung.
Je größer das System, desto deutlicher wird Murphys Gesetz „Was schief gehen kann, wird auch schief gehen“. Je mehr Entwickler häufig Code bereitstellen und bereitstellen, mehrere Rechenzentren beteiligt sind und das System von einer großen Anzahl globaler Benutzer verwendet wird, desto größer ist die Wahrscheinlichkeit solcher Fehler. In den letzten Jahren habe ich eine Reihe von Systemausfällen erlebt, von denen mich viele überrascht haben. Einige sind auf vorhersehbare Dinge zurückzuführen, wie etwa Hardwareausfälle oder scheinbar harmlose Fehler, aber auch auf das Ausgraben von Rechenzentrumskabeln und das gleichzeitige Auftreten mehrerer kaskadierender Ausfälle. Ich habe Dutzende von Geschäftsausfällen erlebt, bei denen ein Teil des Systems nicht richtig funktionierte, was zu enormen geschäftlichen Auswirkungen führte.
Dieser Artikel ist eine Sammlung von Praktiken, die ich während meiner Arbeit bei Uber zusammengefasst habe und mit denen große Systeme effektiv betrieben und gewartet werden können. Meine Erfahrung ist nicht einzigartig – Menschen, die an Systemen ähnlicher Größe arbeiten, haben ähnliche Reisen hinter sich. Ich habe mit Ingenieuren bei Google, Facebook und Netflix gesprochen und sie haben ähnliche Erfahrungen und Lösungen geteilt. Viele der hier beschriebenen Ideen und Prozesse sollten für Systeme ähnlicher Größe gelten, unabhängig davon, ob sie in eigenen Rechenzentren laufen (wie es Uber in den meisten Fällen tut) oder in der Cloud (Uber stellt manchmal Teile seiner Dienste elastisch in der Cloud bereit). Allerdings können diese Praktiken für kleinere oder weniger geschäftskritische Systeme zu hart sein.
Es gibt viel zu besprechen – ich werde die folgenden Themen behandeln:
- Überwachung
- Bereitschaft, Anomalieerkennung und -warnung
- Fehler- und Störungsmanagementprozess
- Postmortems, Störungsüberprüfungen und kontinuierliche Verbesserungskultur
- Fehlerübungen, Kapazitätsplanung und Black-Box-Tests
- SLOs, SLAs und ihre Berichte
- SRE als unabhängiges Team
- Zuverlässigkeit als laufende Investition
- Weitere empfohlene Lektüre
Überwachung
Um zu wissen, ob das System gesund ist, Wir müssen antworten: „Funktioniert das System ordnungsgemäß?“ Dazu ist die Erfassung von Daten zu wichtigen Teilen des Systems von entscheidender Bedeutung. Bei verteilten Systemen mit mehreren Diensten, die auf mehreren Computern und Rechenzentren ausgeführt werden, kann es schwierig sein, die wichtigsten zu überwachenden Dinge zu bestimmen.
Überwachung des Infrastrukturzustands Wenn ein oder mehrere Computer/virtuelle Maschinen überlastet sind, können einige Teile des verteilten Systems beeinträchtigt werden. Der Gesundheitszustand der Maschine, die CPU-Auslastung und die Speichernutzung sind grundlegende Inhalte, die es zu überwachen gilt. Einige Plattformen können diese Art der Überwachung und automatischen Skalierung von Instanzen sofort verarbeiten. Bei Uber verfügen wir über ein hervorragendes Kern-Infrastrukturteam, das sofort Infrastrukturüberwachung und -warnungen bereitstellt. Ganz gleich, wie es auf technischer Ebene umgesetzt wird: Wenn es ein Problem mit der Instanz oder der Infrastruktur gibt, muss die Überwachungsplattform die notwendigen Informationen bereitstellen.
Überwachung des Dienstzustands: Datenverkehr, Fehler, Latenz. Wir müssen oft die Frage beantworten: „Ist dieser Backend-Dienst fehlerfrei?“ Die Beobachtung von Dingen wie Anforderungsverkehr, Fehlerraten und Endpunktlatenz beim Zugriff auf Endpunkte kann wertvolle Informationen über den Zustand Ihres Dienstes liefern. Ich bevorzuge es, wenn das alles auf dem Dashboard angezeigt wird. Wenn Sie einen neuen Dienst erstellen, können Sie viel über das System lernen, indem Sie die richtige HTTP-Antwortzuordnung verwenden und den relevanten Code überwachen. Daher ist die Sicherstellung, dass 4XX bei Clientfehlern und 5xx bei Serverfehlern zurückgegeben wird, einfach zu erstellen und leicht zu interpretieren.
Die Überwachung der Latenz ist einen zweiten Gedanken wert. Bei Produktionsdienstleistungen besteht das Ziel darin, dass die Mehrheit der Endbenutzer eine gute Erfahrung macht. Es stellt sich heraus, dass die Messung der durchschnittlichen Latenz keine sehr gute Messgröße ist, da dieser Durchschnitt einen kleinen Prozentsatz der Anfragen mit hoher Latenz verbergen kann. Die Messung von p95, p99 oder p999 – der Latenz, die bei Anfragen im 95., 99. oder 99,9. Perzentil auftritt – ist ein besserer Messwert. Diese Zahlen helfen bei der Beantwortung von Fragen wie „Wie schnell werden 99 % der Anfragen bearbeitet?“ (S. 99). oder „Wie langsam erlebt mindestens eine von 1.000 Personen eine Verzögerung?“ (S. 999). Für diejenigen, die sich mehr für dieses Thema interessieren, bietet dieser verzögerte Einführungsartikel weitere Lektüre.
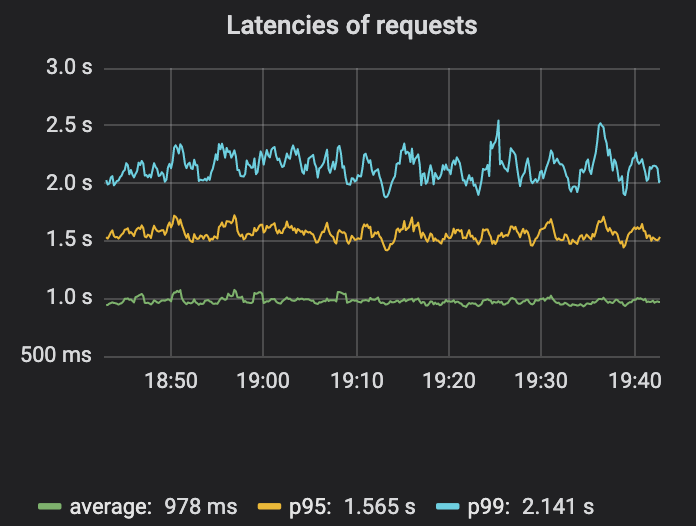
Aus der Abbildung ist deutlich zu erkennen, dass die Unterschiede in der durchschnittlichen Latenz, p95 und p99 recht groß sind. Daher kann die durchschnittliche Latenz einige Probleme verschleiern.
Es gibt viel ausführlichere Inhalte zum Thema Überwachung und Beobachtbarkeit. Zwei lesenswerte Ressourcen sind das SRE-Buch von Google und der Abschnitt über die vier goldenen Metriken der Überwachung verteilter Systeme. Sie empfehlen, dass Sie sich auf Datenverkehr, Fehler, Latenz und Sättigung konzentrieren sollten, wenn Sie für Ihr benutzerorientiertes System nur vier Metriken messen können. Für kürzeres Material empfehle ich das E-Book „Distributed Systems Observability“ von Cindy Sridharan, das andere nützliche Tools wie Ereignisprotokollierung, Metriken und Best Practices für die Ablaufverfolgung behandelt.
Überwachung von Geschäftsindikatoren. Die Überwachung des Servicemoduls kann uns Aufschluss darüber geben, wie das Servicemodul normal läuft, aber sie kann uns nicht sagen, ob das Geschäft wie erwartet funktioniert und ob es „Business as Usual“ ist. In Zahlungssystemen ist eine zentrale Frage: „Können Menschen eine bestimmte Zahlungsmethode verwenden, um Zahlungen zu tätigen?“ Das Erkennen und Überwachen von Geschäftsereignissen ist einer der wichtigsten Überwachungsschritte.
Obwohl wir verschiedene Überwachungen eingerichtet haben, blieben einige Geschäftsprobleme unentdeckt, was uns große Schmerzen bereitete und schließlich eine Überwachung der Geschäftsindikatoren einführte. Manchmal scheinen alle unsere Dienste normal zu laufen, wichtige Produktfunktionen sind jedoch nicht verfügbar! Diese Art der Überwachung ist für unsere Organisation und unseren Bereich sehr nützlich. Daher mussten wir uns viele Gedanken und Mühen machen, um diese Art der Überwachung auf der Grundlage des Observability-Technologie-Stacks von Uber selbst anzupassen.
Anmerkung des Übersetzers: Wir sehen die Überwachung von Geschäftsindikatoren wirklich genauso. In der Vergangenheit stellten wir bei Didi manchmal fest, dass alle Dienste normal waren, das Geschäft jedoch nicht richtig funktionierte. Das Polaris-System, das wir derzeit zur Unternehmensgründung aufbauen, ist speziell für die Bewältigung dieses Problems konzipiert. Interessierte Freunde können mir im Hintergrund des offiziellen Kontos eine Nachricht hinterlassen oder das Picobyte meines Freundes hinzufügen, um zu kommunizieren und es auszuprobieren.
Rufbereitschaft, Anomalieerkennung und Warnungen
Überwachung ist ein großartiges Tool, um Einblicke in den aktuellen Zustand Ihres Systems zu gewinnen. Dies ist jedoch nur ein Sprungbrett zur automatischen Erkennung von Problemen und zur Auslösung von Warnmeldungen, damit die Mitarbeiter Maßnahmen ergreifen können.
Oncall selbst ist ein weites Thema – das Increment Magazine deckt in seiner „On-Call-Ausgabe“ viele Aspekte ab. Ich bin der festen Überzeugung, dass OnCall folgen wird, wenn Sie die Mentalität „Sie bauen es, Sie besitzen es“ haben. Das Team, das die Dienste aufbaut, ist deren Eigentümer und für deren Bereitschaft verantwortlich. Unser Team ist für den Zahlungsverkehr zuständig. Wenn also ein Alarm auftritt, reagiert der diensthabende Techniker und überprüft die Details. Doch wie kommt man von der Überwachung zur Alarmierung?
Das Erkennen von Anomalien aus Überwachungsdaten ist eine schwierige Herausforderung und ein Bereich, in dem maschinelles Lernen glänzen kann. Es gibt viele Dienste von Drittanbietern, die eine Anomalieerkennung ermöglichen. Zum Glück hatte unser Team wiederum ein internes Team für maschinelles Lernen, mit dem es zusammenarbeiten konnte und das die Lösung auf die Nutzung von Uber zugeschnitten hat. Das in New York ansässige Observability-Team hat einen hilfreichen Artikel geschrieben, in dem erklärt wird, wie die Anomalieerkennung von Uber funktioniert. Aus der Sicht meines Teams leiten wir Überwachungsdaten an die Pipeline dieses Teams weiter und erhalten Warnungen mit entsprechenden Konfidenzniveaus. Wir entscheiden dann, ob wir einen Techniker rufen sollen.
Wann ein Alarm ausgelöst werden soll, ist eine interessante Frage. Zu wenige Warnungen können dazu führen, dass ein schwerwiegender Ausfall übersehen wird. Zu viel kann zu schlaflosen Nächten und Erschöpfung führen. Die Verfolgung und Klassifizierung von Alarmen sowie die Messung des Signal-Rausch-Verhältnisses sind für die Optimierung von Alarmsystemen von entscheidender Bedeutung. Warnungen zu überprüfen und als umsetzbar zu kennzeichnen und dann Maßnahmen zu ergreifen, um nicht umsetzbare Warnungen zu reduzieren, ist ein guter Schritt hin zu einer nachhaltigen Bereitschaftsrotation.
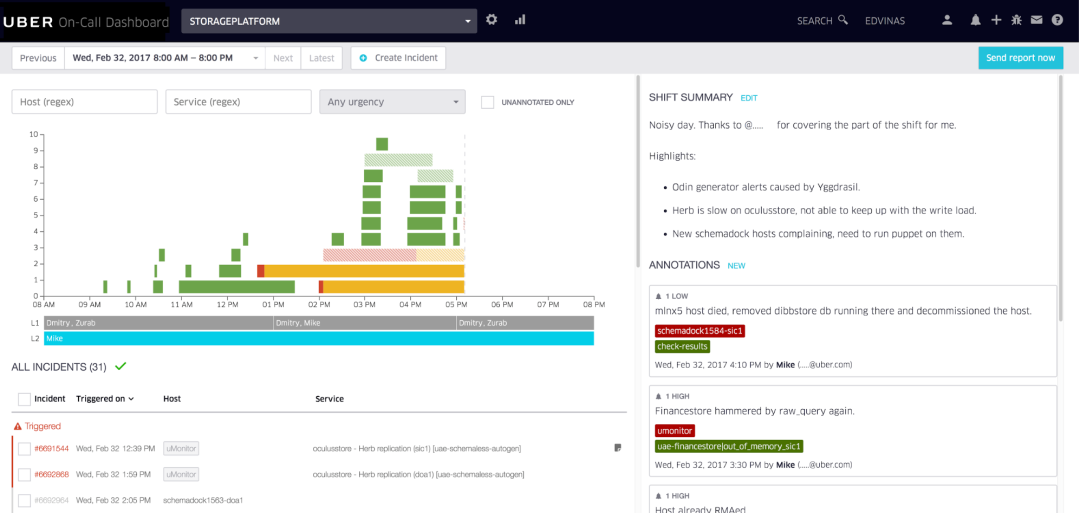
Beispiel für ein internes Bereitschafts-Dashboard, das von Uber verwendet wird und vom Uber Developer Experience-Team in Vilnius erstellt wurde.
Das Uber Dev Tools-Team in Vilnius hat ein praktisches Anruftool entwickelt, mit dem wir Warnungen mit Anmerkungen versehen und Anrufschichten visualisieren. Unser Team führt wöchentliche Überprüfungen der letzten Bereitschaftsschicht durch, analysiert Schwachstellen und verbringt Woche für Woche Zeit damit, die Bereitschaftserfahrung zu verbessern.
Anmerkung des Übersetzers: Alarmereignisaggregation, Rauschunterdrückung, Planung, Inanspruchnahme, Aktualisierung, Zusammenarbeit, flexible Push-Strategie, Multi-Channel-Push und IM-Verbindung sind sehr häufige Anforderungen. Sie können sich auf das Produkt FlashDuty beziehen, um es zu erleben : https://console.flashcat.cloud/
Fehler- und Incident-Management-Prozess
Stellen Sie sich Folgendes vor: Sie sind diese Woche der Ingenieur im Dienst. Mitten in der Nacht weckt Sie ein Wecker. Sie untersuchen, ob ein Produktionsausfall aufgetreten ist. Hoppla, es scheint, als ob mit einem Teil des Systems etwas nicht stimmt. Was nun? Überwachung und Alarmierung finden tatsächlich statt.
Bei kleinen Systemen sind Ausfälle möglicherweise kein großes Problem und der diensthabende Techniker kann verstehen, was passiert und warum. Sie sind in der Regel leicht zu verstehen und leicht zu lindern. Bei komplexen Systemen mit mehreren (Mikro-)Diensten und vielen Ingenieuren, die den Code in die Produktion bringen, kann es schon schwierig genug sein, herauszufinden, wo potenzielle Probleme auftreten. Einige Standardprozesse zur Lösung dieses Problems können einen großen Unterschied machen.
Ein der Warnung beigefügtes Runbook, in dem einfache Abhilfemaßnahmen als erste Verteidigungslinie beschrieben werden. Für Teams mit guten Runbooks stellt dies selten ein Problem dar, selbst wenn der diensthabende Ingenieur kein tiefes Verständnis des Systems hat. Runbooks müssen aktuell und aktualisiert gehalten werden und neuartige Abhilfemaßnahmen nutzen, um auftretende Fehler zu beheben.
Anmerkung des Übersetzers: Die Alarmregelkonfiguration von Nightingale und Grafana kann benutzerdefinierte Felder unterstützen, es werden jedoch standardmäßig einige zusätzliche Felder bereitgestellt, z. B. RunbookUrl. Der Kern besteht darin, die Bedeutung des SOP-Handbuchs zu vermitteln. Darüber hinaus ist es im Stabilitätsmanagementsystem ein sehr wichtiger Indikator für den Alarmzustand, ob die Alarmregeln RunbookUrl voreingestellt haben.
Sobald mehr als nur ein paar Teams Dienste bereitstellen, wird die Fehlerkommunikation im gesamten Unternehmen von entscheidender Bedeutung. Ich arbeite in einer Umgebung, in der Tausende von Ingenieuren Dienste bereitstellen, die sie nach eigenem Ermessen zur Produktion entwickeln, möglicherweise Hunderte von Bereitstellungen pro Stunde. Eine scheinbar unabhängige Dienstbereitstellung kann Auswirkungen auf einen anderen Dienst haben. In diesem Fall können standardisierte Fehlerübertragungs- und Kommunikationskanäle viel bewirken. Ich war auf verschiedene seltene Warnmeldungen gestoßen – und stellte fest, dass Leute in anderen Teams ähnliche seltsame Phänomene beobachteten. Durch den Beitritt zu einer zentralen Chat-Gruppe zur Behebung von Ausfällen konnten wir den Dienst, der den Ausfall verursachte, schnell identifizieren und das Problem beheben. Wir haben es schneller erledigt, als es einer einzelnen Person möglich wäre.
Jetzt entlasten, morgen nachforschen. Bei einer Panne verspüre ich oft einen „Adrenalinschub“, weil ich den Fehler beheben möchte. Die Hauptursache ist häufig eine schlechte Codebereitstellung mit offensichtlichen Fehlern in den Codeänderungen. In der Vergangenheit bin ich direkt eingestiegen und habe den Fehler behoben, den Fix vorangetrieben und den Fehler geschlossen, anstatt die Codeänderungen rückgängig zu machen. Allerdings ist die Behebung der Grundursache bei einem Ausfall eine schreckliche Idee. Der Nutzen der Vorwärtswiederherstellung ist gering, der Verlust jedoch groß. Da neue Korrekturen schnell durchgeführt werden müssen, müssen sie in der Produktion getestet werden. Aus diesem Grund wird ein zweiter Fehler – oder ein Glitch zusätzlich zu einem bestehenden Fehler – eingeführt. Ich habe gesehen, dass solche Störungen immer schlimmer wurden. Konzentrieren Sie sich einfach zunächst auf die Schadensbegrenzung und widerstehen Sie dem Drang, die Grundursache zu beheben oder zu untersuchen. Eine ordnungsgemäße Untersuchung kann bis zum nächsten Werktag warten.
Anmerkung des Übersetzers: Auch erfahrene Fahrer sollten sich dessen bewusst sein. Führen Sie kein Online-Debugging durch, sondern führen Sie sofort einen Rollback durch, anstatt zu versuchen, eine Hotfix-Version zu veröffentlichen, um das Problem zu beheben.
Post-Mortem-Analyse, Überprüfung von Vorfällen und Kultur der kontinuierlichen Verbesserung
Hier geht es darum, wie ein Team mit den Folgen eines Fehlers umgeht. Werden sie weiterhin arbeiten? Werden sie eine kleine Umfrage durchführen? Werden sie später überraschend viel Aufwand betreiben und die Produktarbeit stoppen, um eine Lösung auf Systemebene vorzunehmen?
Eine ordnungsgemäß durchgeführte Post-Mortem-Analyse ist der Grundstein für den Aufbau eines starken Systems. Eine gute Obduktion ist sowohl nicht anklagend als auch gründlich. Die Post-Mortem-Vorlage von Uber wird mit technischer Technologie weiterentwickelt und umfasst Abschnitte wie eine Vorfallübersicht, eine Übersicht über die Auswirkungen, einen Zeitplan, eine Ursachenanalyse, gewonnene Erkenntnisse und eine detaillierte Checkliste für die Nachverfolgung.
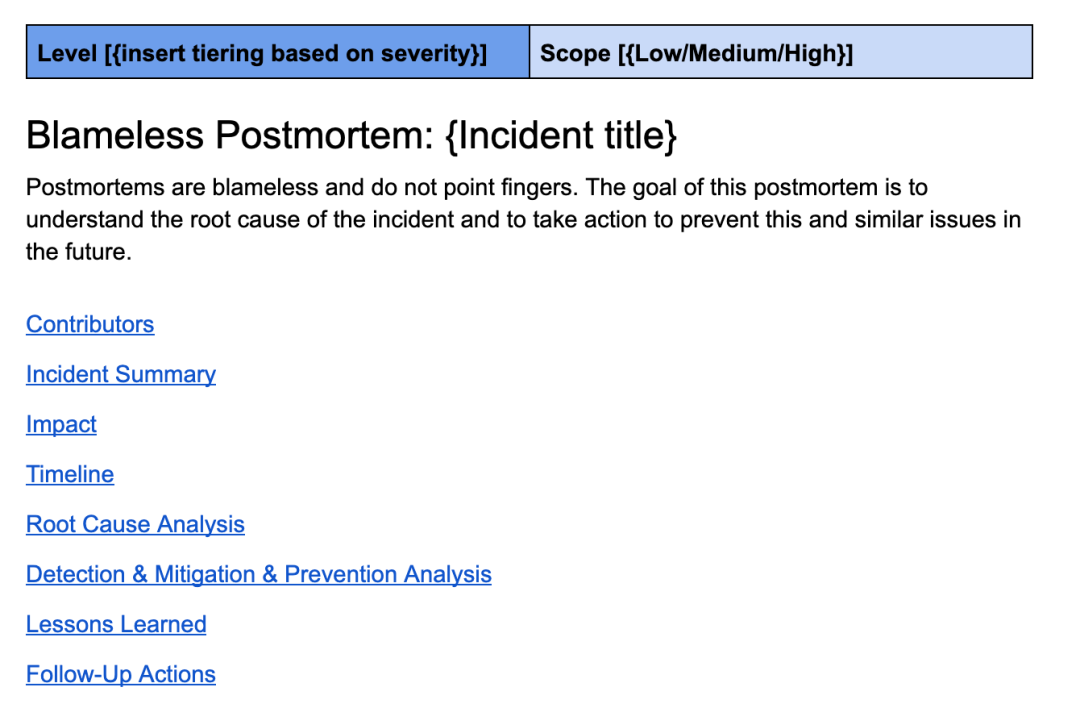
Dies ist eine Bewertungsvorlage ähnlich der, die ich bei Uber verwende.
Eine gute Obduktion geht tief in die Ursachen ein und schlägt Verbesserungen vor, um alle ähnlichen Fehler schneller zu verhindern, zu erkennen oder abzumildern. Wenn ich sage, tiefer graben, meine ich, dass sie nicht bei der Grundursache Halt machen, nämlich der falschen Codeänderung und dem Nichterkennen des Fehlers durch den Codeprüfer.
Sie nutzen die „5why“-Explorationsmethode, um tiefer zu graben und aussagekräftigere Schlussfolgerungen zu ziehen. Zum Beispiel:
- Warum tritt dieses Problem auf? –> Weil ein Fehler in den Code eingeführt wurde.
- Warum hat sonst niemand diesen Fehler entdeckt? –> Codeänderungen, die von Codeprüfern nicht bemerkt werden, können solche Probleme verursachen.
- Warum verlassen wir uns nur auf Codeprüfer, um diesen Fehler zu erkennen? –> Weil wir für diesen Anwendungsfall keine automatisierten Tests haben.
- „Warum haben wir für diesen Anwendungsfall keine automatisierten Tests?“ –> Weil es schwierig ist, ohne Testkonto zu testen.
- Warum haben wir kein Testkonto? –> Weil das System sie noch nicht unterstützt
- Fazit: Dieses Problem weist auf ein systemisches Problem mit dem Fehlen von Testkonten hin. Es wird empfohlen, dem System Testkontounterstützung hinzuzufügen. Schreiben Sie als Nächstes automatisierte Tests für alle zukünftigen ähnlichen Codeänderungen.
Der Event-Review ist ein wichtiges unterstützendes Tool für die Post-Event-Analyse. Während viele Teams ihre Obduktionen gründlich durchführen, können andere von zusätzlichem Input und Herausforderungen für präventive Verbesserungen profitieren. Es ist auch wichtig, dass sich die Teams verantwortlich und befugt fühlen, die von ihnen vorgeschlagenen Verbesserungen auf Systemebene umzusetzen.
Für Unternehmen, die Zuverlässigkeit ernst nehmen, werden die schwerwiegendsten Fehler von erfahrenen Ingenieuren überprüft und behoben. Auch das technische Management auf Organisationsebene sollte anwesend sein, um die Befugnis zur Durchführung von Reparaturen zu erteilen – insbesondere, wenn diese Reparaturen zeitaufwändig sind und andere Arbeiten behindern. Robuste Systeme entstehen nicht über Nacht: Sie werden durch ständige Iteration aufgebaut. Wie können wir weiter iterieren? Dies erfordert eine Kultur der kontinuierlichen Verbesserung und des Lernens aus Fehlern auf Organisationsebene.
Fehlerübungen, Kapazitätsplanung und Black-Box-Tests
Es gibt einige Routinetätigkeiten, die erhebliche Investitionen erfordern, aber für den Betrieb großer verteilter Systeme von entscheidender Bedeutung sind. Dies sind Konzepte, mit denen ich zum ersten Mal bei Uber in Kontakt kam – bei früheren Unternehmen mussten wir sie nicht nutzen, weil unsere Größe und Infrastruktur uns nicht dazu drängten.
Eine Übung zum Ausfall eines Rechenzentrums fand ich langweilig, bis ich einige davon in Aktion beobachtete. Mein erster Gedanke war, dass die Entwicklung robuster verteilter Systeme genau dazu dient, im Falle eines Zusammenbruchs eines Rechenzentrums widerstandsfähig zu bleiben. Wenn es theoretisch gut funktioniert, warum sollte man es dann so oft testen? Die Antwort liegt in der Skalierung und der Notwendigkeit, zu testen, ob der Dienst den plötzlichen Anstieg des Datenverkehrs im neuen Rechenzentrum effektiv bewältigen kann.
Das häufigste Fehlerszenario, das ich beobachte, ist, wenn ein Failover auftritt und der Dienst im neuen Rechenzentrum nicht über genügend Ressourcen verfügt, um den globalen Datenverkehr zu bewältigen. Gehen Sie davon aus, dass ServiceA und ServiceB jeweils in zwei Rechenzentren ausgeführt werden. Gehen Sie davon aus, dass die Ressourcenauslastung 60 % beträgt, wobei in jedem Rechenzentrum Dutzende oder Hunderte virtuelle Maschinen laufen, und legen Sie einen Alarm fest, der bei 70 % ausgelöst wird. Führen wir nun ein Failover durch und leiten den gesamten Datenverkehr von DataCenterA zu DataCenterB um. Ohne die Bereitstellung einer neuen Maschine konnte DataCenterB die Last plötzlich nicht mehr bewältigen. Die Bereitstellung einer neuen Maschine kann so lange dauern, dass sich die Anforderungen häufen und verworfen werden. Diese Blockierung kann Auswirkungen auf andere Dienste haben und zu kaskadierenden Ausfällen anderer Systeme führen, die nicht einmal Teil dieses Failovers sind.
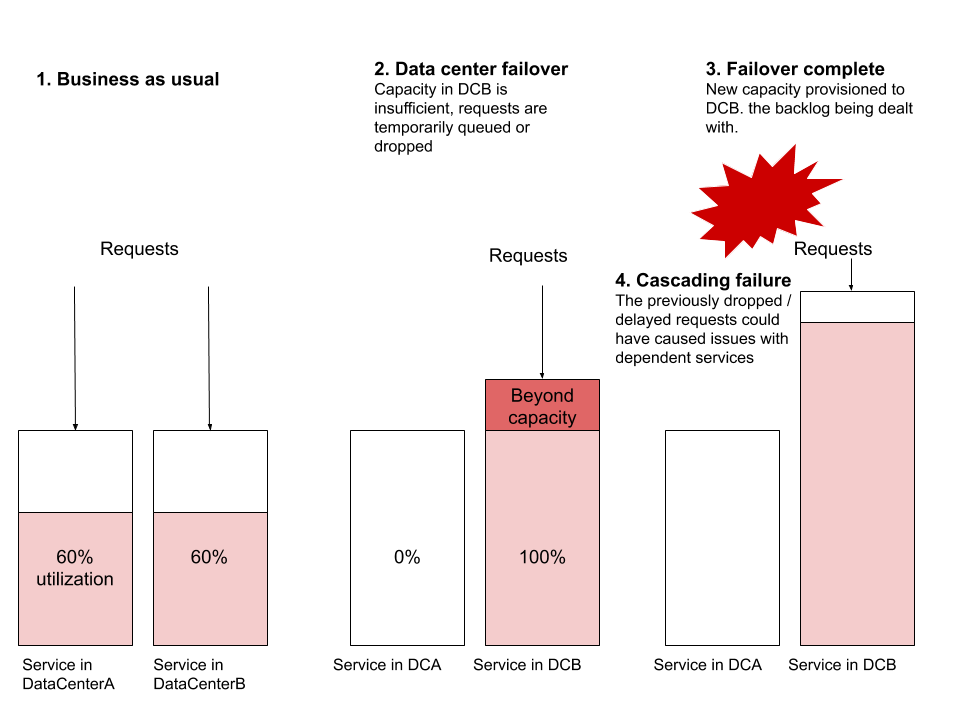
Andere häufige Fehlerszenarien umfassen Probleme auf der Routing-Ebene, Probleme mit der Netzwerkkapazität oder Probleme mit dem Gegendruck. Der Failover im Rechenzentrum ist eine Aufgabe, die jedes zuverlässige verteilte System ohne Auswirkungen auf den Benutzer durchführen kann. Ich betone „sollte“ – diese Übung ist eine der nützlichsten Übungen zum Testen der Zuverlässigkeit verteilter Systeme.
Anmerkung des Übersetzers: Die Reduzierung des Verkehrs ist eine der „drei Achsen“ des Plans. Wenn etwas schief geht, sind Übungen unverzichtbar, um sicherzustellen, dass der Plan verfügbar ist. Passt auf, Leute.
Geplante Service-Downtime-Übungen sind eine hervorragende Möglichkeit, die Ausfallsicherheit Ihres gesamten Systems zu testen. Dies ist auch eine großartige Möglichkeit, versteckte Abhängigkeiten oder unangemessene/unbeabsichtigte Verwendungen eines bestimmten Systems zu entdecken. Während diese Übung für kundenorientierte Dienste mit wenigen Abhängigkeiten relativ einfach durchzuführen ist, ist sie für kritische Systeme, die eine hohe Verfügbarkeit erfordern oder auf die sich viele andere Systeme verlassen, nicht so einfach. Aber was passiert, wenn dieses kritische System eines Tages nicht mehr verfügbar ist? Die Validierung der Antworten erfolgt am besten durch eine kontrollierte Übung, bei der sich alle Teams über unerwartete Störungen im Klaren sind und darauf vorbereitet sind.
Black-Box-Tests sind eine Methode, um die Korrektheit eines Systems so nah wie möglich an den Bedingungen zu messen, die der Endbenutzer sieht. Diese Art von Tests ähnelt End-to-End-Tests, bei den meisten Produkten ist jedoch eine separate Investition für ordnungsgemäße Black-Box-Tests erforderlich. Wichtige Benutzerprozesse und die häufigsten benutzerorientierten Testszenarien sind Beispiele für eine gute Black-Box-Testbarkeit: Sie sind so eingerichtet, dass sie jederzeit ausgelöst werden können, um zu überprüfen, ob das System ordnungsgemäß funktioniert.
Am Beispiel von Uber besteht ein offensichtlicher Black-Box-Test darin, zu überprüfen, ob der Passagier-Fahrer-Prozess auf Stadtebene ordnungsgemäß funktioniert. Das heißt, kann ein Passagier in einer bestimmten Stadt ein Uber anfordern, mit dem Fahrer zusammenarbeiten und die Fahrt abschließen? Sobald diese Situation automatisiert ist, kann dieser Test regelmäßig durchgeführt werden, um verschiedene Städte zu simulieren. Mit einem leistungsstarken Black-Box-Testsystem lässt sich leichter überprüfen, ob ein System oder ein Teil eines Systems ordnungsgemäß funktioniert. Es ist auch sehr hilfreich für Failover-Übungen: Der schnellste Weg, Failover-Feedback zu erhalten, ist die Durchführung von Black-Box-Tests.
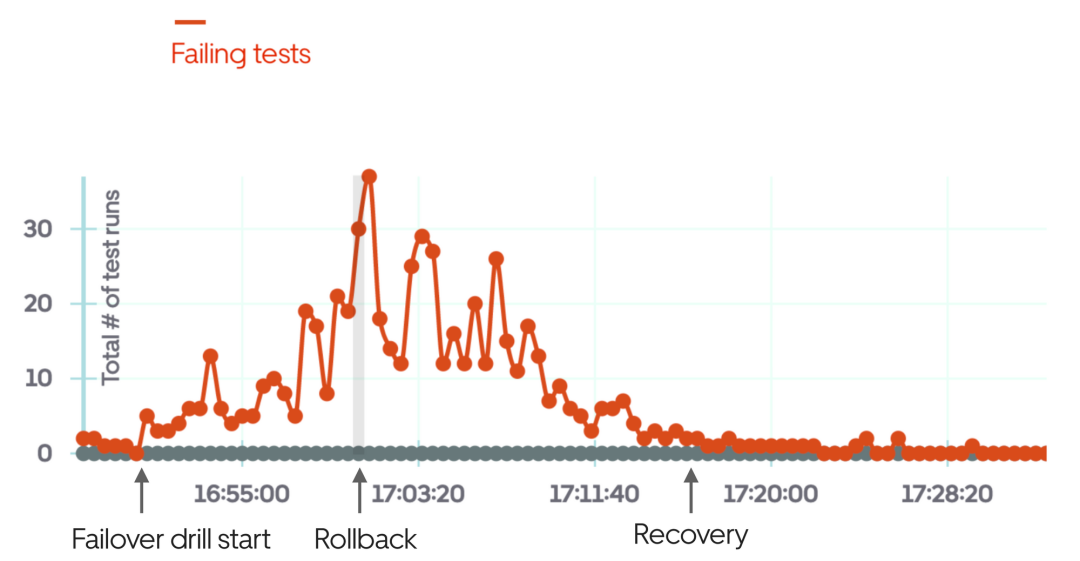
Das Bild oben ist ein Beispiel für die Verwendung von Black-Box-Tests, wenn die Failover-Übung fehlschlägt und nach einigen Minuten der Übung manuell ein Rollback durchgeführt wird.
Die Kapazitätsplanung ist für große verteilte Systeme gleichermaßen wichtig. Im Großen und Ganzen meine ich, dass sich die Rechen- und Speicherkosten auf Zehntausende oder Hunderttausende Dollar pro Monat belaufen. Bei dieser Größenordnung kann die Verwendung einer festen Anzahl von Bereitstellungen günstiger sein als die Verwendung einer automatisch skalierenden Cloud-Lösung. Zumindest sollten feste Bereitstellungen den „Business-as-usual“-Verkehr bewältigen und bei Spitzenlasten automatisch skalieren. Aber wie viele Instanzen müssen Sie im nächsten Monat, in den nächsten drei Monaten und im nächsten Jahr mindestens ausführen?
Die Vorhersage zukünftiger Verkehrsmuster für ein ausgereiftes System mit guten historischen Daten ist nicht schwierig. Dies ist wichtig für die Budgetierung, die Auswahl eines Anbieters oder die Sicherung eines Cloud-Anbieter-Rabatts. Wenn Ihre Dienste teuer sind und Sie nicht über die Kapazitätsplanung nachdenken, verpassen Sie einfache Möglichkeiten zur Kostensenkung und -kontrolle.
SLOs, SLAs und zugehörige Berichte
SLO steht für Service Level Objective – ein numerisches Ziel für die Systemverfügbarkeit. Es empfiehlt sich, Service-Level-SLOs (z. B. Ziele für Kapazität, Latenz, Genauigkeit und Verfügbarkeit) für jeden einzelnen Dienst zu definieren. Diese SLOs können dann als Auslöser für Warnungen dienen. Ein Service-Level-SLO-Beispiel könnte so aussehen:
SLO-Metrik |
Unterkategorie |
Wert für Service | . ||
Kapazität |
Minimaler Durchsatz: 500 Anforderungen/Sek.: 2.500 Anforderungen/Sek |
| 5 00-800 msGenauigkeit |
|
|
|
Verfügbarkeit |
|||
|
|
Das obige ist der detaillierte Inhalt vonUber-Praxis: Einige Erfahrungen im Betrieb und der Wartung großer verteilter Systeme. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So schreiben Sie ein Dreieck in CSS
- Eine neue Ära der Cloud-Sicherheit: aktuelle Situation und Aussichten
- So reproduzieren Sie die RCE-Schwachstelle im Apache Solr JMX-Dienst
- Von der Überwachung bis zur Diagnose: die Macht der Daten
- Richten Sie ein Netzwerksicherheitsmanagementmodell ein, das auf einer Risikobewertung basiert