
Heim >Betrieb und Instandhaltung >Sicherheit >Aus CTO-Perspektive: Wie man Betriebs- und Wartungs-/SRE-Fähigkeiten aufbaut
Aus CTO-Perspektive: Wie man Betriebs- und Wartungs-/SRE-Fähigkeiten aufbaut

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-09 12:37:08910Durchsuche

In letzter Zeit gab es viele Artikel, in denen die Frage diskutiert wurde, ob Betriebs- und Wartungspositionen beibehalten werden sollen oder nicht. Der von mir gehostete offizielle SRETalk-Account hat auch die Meinungen vieler Betriebs- und Wartungsleiter veröffentlicht Ich habe auch mit vielen Leuten in der Branche gesprochen und sie als Referenz für CTOs/CIOs aufgezeichnet. Wenn Sie verwirrt sind, empfehle ich Ihnen auch, diesen Artikel sorgfältig zu lesen .
Ich denke, das ist eine gründliche Überlegung, es mag langweilig sein, aber es wird für die Berufswahl und den Teamaufbau hilfreich sein. Dieser Artikel begrüßt fundierte Diskussionen, aber keine Arroganz. Darüber hinaus ist es großartig, wenn der Inhalt des Artikels Sie inspirieren und neues Denken in die Entscheidungsfindung einbringen kann.
Darüber hinaus wird das Interview von SRETalk mit dem Betriebs- und Wartungsdirektor fortgesetzt und es werden weiterhin weitere unterschiedliche Meinungen zu Ihrer Information ausgegeben. Meine Meinung ist nicht unbedingt korrekt und dient nur als Referenz.
Über den Titel
Lassen Sie mich zunächst über den Titel „Wie man Betriebs- und Wartungs-/SRE-Fähigkeiten aufbaut“ sprechen. Hier schreibe ich nicht über den Aufbau eines Teams, sondern über den Aufbau von Fähigkeiten, denn die Leistung einiger Ziele erfordern nicht unbedingt den Aufbau eines selbst zusammengestellten Teams. Aus der Perspektive der Vorhersehbarkeit und langfristigen Investitionen in die Wartung ist eine sorgfältige Entscheidungsfindung erforderlich Chaos. Dies wird später besprochen.
Über das Betriebs- und Wartungs-/SRE-Team
Ein weiterer Punkt sollte im Voraus geklärt werden. Das im Artikel erwähnte Betriebs- und Wartungs-/SRE-Team dient alle dem Unternehmen, und der Erfolg des Unternehmens steht an erster Stelle. Einige Betriebs- und Wartungsteams haben einige Produkte hergestellt und zur externen Vermarktung exportiert, was zu einem eigenständigen Geschäft geworden ist. Basierend auf meiner Erfahrung bei meinem alten Arbeitgeber ist der Ansatz des Betriebs- und Wartungs-/SRE-Teams (extern) eine andere Sache Kommerzialisierungs-Output) ist nicht ratsam, insbesondere in einem Unternehmen, das nicht über ToB-Gene und keine entsprechende ToB-Organisationskonstruktion verfügt.
Wo bekommt man Betriebs- und Wartungs-/SRE-Fähigkeiten
Da alles auf den Geschäftserfolg ausgerichtet ist (unabhängig vom Geschäft, ist nur die Frage, ob man befördert werden kann oder ob man seinen Chef täuschen kann, eine andere Sache), konzentrieren wir uns auf Betrieb und Wartung Die für das Unternehmen benötigten Fähigkeiten (wird später ausführlich erläutert). Wo benötigen Sie diese Betriebs- und Wartungsfunktionen? Es gibt drei typische Beschaffungsmethoden.
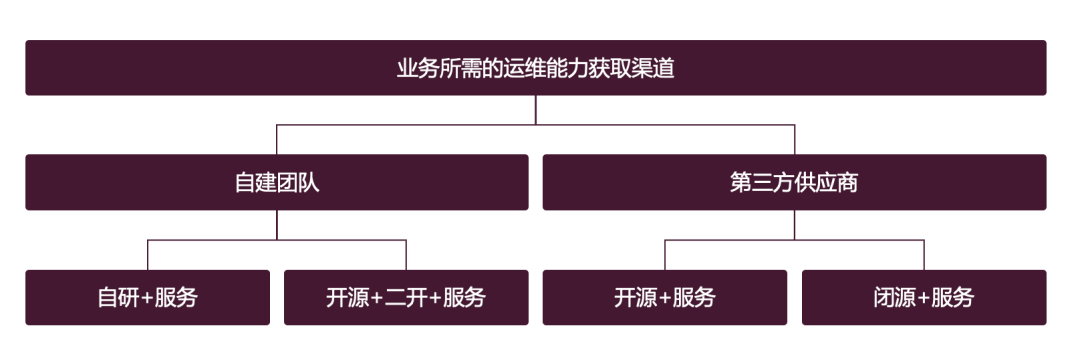
Selbst zusammengestelltes Team
Die erste Methode besteht darin, relevante Fähigkeiten durch ein selbst zusammengestelltes Team bereitzustellen. Die Geschäftsergebnisse des selbst zusammengestellten Teams umfassen normalerweise zwei Teile Dienstleistungen. Lassen Sie uns zunächst über das Produkt sprechen:
- Wenn es sich bei den Produktanforderungen um allgemeine Anforderungen handelt, handelt es sich höchstwahrscheinlich um ein Open-Source-Projekt, das direkt verwendet werden kann. Es ist notwendig, die Dauerhaftigkeit des Open-Source-Projekts zu berücksichtigen (ob die Entwickler des Open-Source-Projekts Einkommensunterstützung von kommerziellen Unternehmen erhalten, die meisten persönlichen Open-Source-Projekte werden ohne Einkommen sterben), die Aktivität (wurde das Projekt seit vielen Jahren nicht aktualisiert). ? Werden die Probleme und PRs angesprochen? Normalerweise kann die Bearbeitung innerhalb einer Woche als aktiv angesehen werden, ökologischer Wohlstand (beteiligen sich viele Personen an Beiträgen? Viele Unternehmen nutzen sie?)
- Erfordern Open-Source-Projekte eine sekundäre Entwicklung? ? Wenn der sekundäre Entwicklungscode wieder mit dem Hauptstamm zusammengeführt werden kann, bedeutet dies normalerweise, dass der sekundäre Entwicklungscode universell ist und vom Open-Source-Projektteam erkannt wurde. Wenn es nicht wieder mit dem Hauptstamm zusammengeführt werden kann, ist die anschließende Wartung problematisch, insbesondere nach einem Talentwechsel. Normalerweise ist es möglich, einen Klebercode basierend auf der API des Open-Source-Projekts zu erstellen und ihn in das interne System zu integrieren. Schließlich wurde der Open-Source-Code nicht geändert und die nachfolgenden Upgrades des Open-Source-Projekts können weiterhin beibehalten werden Natürlich gibt es auch vollständig selbst entwickelte, die kein Open Source verwenden (einige Open-Source-Bibliotheken und die Kernproduktlogik sind selbst entwickelt, wenn die Open-Source-Community dies tut). Wenn Sie keine verwandten Produkte haben, können Sie diese nur selbst entwickeln. Wenn die Dinge jedoch von 0 auf 1 gehen, müssen Sie das Problem der langfristigen Wartung berücksichtigen Die Leistungen werden gering sein und Beförderungen und Gehaltserhöhungen werden nicht möglich sein, so dass ein Wechsel leicht möglich sein wird. Was den Betriebs- und Wartungsbereich betrifft, verfügt die Open-Source-Community über eine schillernde Produktpalette, und möglicherweise gibt es nur eine Handvoll Produkte, die eine Eigenentwicklung erfordern. Denken Sie also zweimal darüber nach.
- Der zweite Punkt ist Service. Der sogenannte Service bezieht sich hier auf die Expertenerfahrung, die auf die Geschäftsseite übertragen wird. Wenn beispielsweise ein selbst zusammengestelltes Team ein Überwachungsprodukt erstellt, muss dieses Team die besten Überwachungspraktiken an die internen „Kunden“ des Unternehmens weitergeben. Wenn Probleme mit dem Überwachungsprodukt auftreten, muss dieses Team diese schnell lösen. Tatsächlich müssen die Middle- und Back-End-Teams im Unternehmen ein starkes Gespür für Service haben und die Best Practices der Branche verstehen. Andernfalls lassen sie sich leicht vom Unternehmen leiten und gehen in die entgegengesetzte Richtung zu den Best Practices in der Branche ist alles ein Problem.
Der Kern des Service besteht darin, sich auf Menschen zu verlassen (natürlich ist es großartig, wenn Sie Best Practices in Produkte umwandeln können). Wenn Sie als Manager möchten, dass dieses Team gute Dienstleistungen erbringt, müssen Sie die Probleme vieler Menschen berücksichtigen. Zum Beispiel: ob relevante Talente rekrutiert werden können, ob relevante Talente gehalten werden können (Entwicklungsraum, Gehalt usw.), sich mindestens zwei Personen in jeder Richtung des selbst zusammengestellten Teams gegenseitig ergänzen können und ob die Kosten gesenkt werden können gewährt.
Drittanbieter
Die Beschaffung von Betriebs- und Wartungskapazitäten durch Drittanbieter ist eine weitere Möglichkeit. Die Leistungen des Anbieters umfassen natürlich zwei Teile: Produkte + Dienstleistungen. Produkte werden in zwei Typen unterteilt: Open Source und Closed Source. Was sind die Überlegungen?
- Open-Source-Produkte haben normalerweise mehr Benutzer und mehr Szenarien, die es zu polieren gilt, aber einige Long-Tail-Anforderungen sind normalerweise keine Open-Source-Anforderungen. Aus diesem Grund behandelt das Open-Source-Team diese Long-Tail-Anforderungen entweder als kostenpflichtige Elemente, oder die Das Open-Source-Team ist der Ansicht, dass diese Long-Tail-Anforderungen nicht allgemein genug sind und es nicht wert sind, in das Produkt aufgenommen zu werden.
- Closed-Source-Produkte haben normalerweise ein kleines Publikum, und es gibt nicht viele Open-Source-Benutzer, die beim Polieren der Produkte helfen können. Daher müssen sie lange Zeit von kommerziellen Kunden poliert werden, oder die Anbieter von Closed-Source-Produkten sind sehr stark Qualitätsmanagementsystem, das für sie nicht gut ist, Sie müssen Lieferanten mit großen Unternehmen finden. Darüber hinaus sind Tester und Endbenutzer schließlich unverzichtbar. Wenn der Lieferant über ein starkes Qualitätssicherungsteam verfügt, wird dieser Polierprozess kürzer.
- Ob Open Source oder Closed Source, der Lieferant kommt mit dem Produkt. Als Partei A können Sie es direkt testen, um zu sehen, wie das Produkt übereinstimmt, und schnell Feedback erhalten Die Entwicklung kann mehrere Monate oder sogar ein oder zwei Jahre dauern, und das Unternehmen kann möglicherweise nicht warten, bis es nach der Entwicklung den Erwartungen entspricht, und die Ergebnisse sind unvorhersehbar.
Der zweite Punkt ist der Service, der in der Regel Vorteile gegenüber selbst zusammengestellten Teams hat. Die Gründe sind wie folgt:
- Weil Lieferanten mehr Kundenszenarien gesehen haben, und ToB-Unternehmen, ist die langfristige Anhäufung von Branchen-Know-how die zentrale Wettbewerbsfähigkeit dieses Unternehmens. Lieferanten werden weiterhin von hervorragenden Kunden lernen und profitieren Für die weniger fortgeschrittenen Kunden ein positiver Kreislauf und eine Win-Win-Situation für alle Parteien.
- Das liegt auch daran, dass Lieferanten mehr Szenarien gesehen haben und bessere Abstraktionen für Produkte erstellen können, wodurch die Produkte vielseitiger werden und einem Produkt ähneln, das von selbst erstellten Teams hergestellt wird. Nichts für ungut, meine ich normalerweise.
- Der Grund, warum Lieferanten Unternehmen im Bereich Betrieb und Wartung gründen, liegt höchstwahrscheinlich darin, dass sie im Vergleich zu selbst zusammengestellten Teams über bessere Kenntnisse auf höchstem Niveau verfügen werden feststellen, dass die mächtigste Gruppe von Menschen entweder ein Unternehmen gegründet hat, es zu teuer ist oder sie nicht bereit sind, zu kommen.
Lassen Sie uns außerdem über die Kostenfrage sprechen. Die Gebühren des Lieferanten sind höchstwahrscheinlich kostengünstiger als die Rekrutierung von Mitarbeitern selbst (vorausgesetzt, dass die richtigen Leute rekrutiert werden). Dieses Prinzip ist offensichtlich und wird nicht noch einmal wiederholt.
Die Beschaffung von Betriebs- und Wartungskapazitäten von Drittanbietern scheint für selbst zusammengestellte Teams überwältigend zu sein. Müssen Sie die folgenden Artikel trotzdem lesen? Tatsächlich ist dies nicht immer der Fall. Wichtiger ist die Produktfähigkeit oder Servicefähigkeit. Das muss von Fall zu Fall geprüft werden. Im Folgenden werde ich es aus geschäftlicher Sicht betrachten. Alle Aspekte der Betriebs- und Wartungsfunktionen werden separat abgebaut.
Welche technischen Supportfunktionen werden für das Unternehmen benötigt?
Betrieb und Wartung sind im Wesentlichen eine Art technischer Supportfunktionen, die dem Infrastrukturteam sehr ähnlich sind Es ist kein großes Problem, sie in das Infrastrukturteam aufzunehmen. Das Unternehmen stellt solche Leute sogar direkt in das Forschungs- und Entwicklungsteam des Unternehmens. Lassen Sie uns zunächst die Arbeitsteilung ignorieren und klären, welche Art von technischem Support das Unternehmen bietet erfordert.
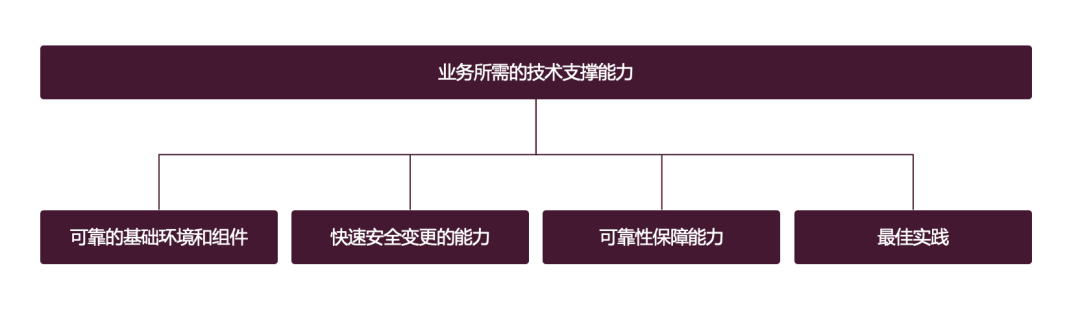
Dieses Bild erklärt das Problem tatsächlich sehr gut:
- Zuverlässige Basisumgebung und Komponenten: Um Geschäftsprogramme auszuführen, benötigen Sie grundlegende Netzwerke, Hardware, Betriebssysteme, Datenbanken, Middleware usw. Diese Umgebungen und Komponenten müssen stabil und zuverlässig sein
- Die Fähigkeit, sich schnell und sicher zu ändern: Die Die Fähigkeit, sich schnell zu ändern, ist für alle leicht zu verstehen. Wenn Sie als Entwickler eine Funktion schreiben oder einen Bugfix vornehmen, möchten Sie diese auf jeden Fall schnell bereitstellen, aber Änderungen können leicht zu Fehlern führen, Änderungen müssen kontrolliert werden und Sicherheitsanforderungen bestehen um so viel wie möglich sicherzustellen
- Funktionen zur Zuverlässigkeitssicherung: Nach der Produktionsumgebung können verschiedene Probleme auftreten, wie Sie Probleme schnell erkennen, Probleme lokalisieren und Verluste schnell stoppen können die wichtigste Anforderung von der Geschäftsseite an die Betriebs- und Wartungsseite sein
- Die wichtigste Best Practice: Das Unternehmen ist auf viele grundlegende unterstützende Fähigkeiten angewiesen. Wie werden diese Fähigkeiten genutzt? Handelt es sich dabei um die Best Practice der Branche? Ist es eine Best Practice für die meisten anderen Abläufe im Unternehmen? Es ist ein grundlegendes Support-Team erforderlich, das Rückmeldungen an das Unternehmen liefert.
Wie erhält man die einzelnen Fähigkeiten?
Wie sollen die vier oben genannten Fähigkeiten erworben werden? Lassen Sie es uns jetzt aufschlüsseln und aufschlüsseln und darüber reden.
Zuverlässige Basisumgebung und Komponenten
Lassen Sie uns zunächst über die grundlegende Hardwareumgebung sprechen: Cloud oder selbst erstellt. Wenn die Richtlinie erfordert, dass Sie dies selbst tun müssen, gibt es keine Möglichkeit. Die Richtlinie hat Vorrang. Wenn Sie selbst entscheiden können, ist es in dieser Zeit wahrscheinlich besser, in die Cloud zu wechseln. Sofern das Unternehmen nicht sehr groß ist und über eine große Anzahl von Maschinen verfügt, kann es von Vorteil sein, es selbst zu erstellen. Beachten Sie, dass das, was ich hier sage, „möglich“ ist. Denken Sie bei der Kostenberechnung daran, die Arbeitskosten einzubeziehen, nicht nur die Hardwarekosten.
Zur Berufswahl: Es scheint keine gute Nachricht für Systembetriebs- und -wartungsingenieure zu sein. Das Aufkommen der Cloud hat tatsächlich Platz für einige dieser Positionen beansprucht Die Räder der Zeit rollen vorwärts, jeder. Es ist der ganze Staub der Geschichte. Lassen Sie uns über Komponenten wie MySQL, Redis, MongoDB, Kafka, ElasticSearch, Nginx, Kubernetes usw. sprechen. Es gibt offensichtlich drei Optionen: Verwenden Sie Cloud-PaaS-Produkte oder machen Sie es selbst oder stellen Sie Ihre eigene Hardware + Lieferanten zur Verfügung Lösungen und Dienstleistungen. Für jede Auswahl werden wir jeweils eine Bewertung vornehmen:
Cloud-PaaS-Produkte: Wenn der Umfang klein ist und keine relevanten Talentreserven vorhanden sind, ist es angemessener, Cloud-PaaS-Produkte zu verwenden. Sie können schnell Funktionen aufbauen und sich für die Verwendung entscheiden Cloud-Partei A, die PaaS-Produkte kauft, nutzt in der Regel bereits virtuelle Maschinen in der Cloud und Kubernetes-ähnliche Laufzeitumgebungen. Der Kauf von PaaS-Produkten ist übrigens auch relativ reibungslos und es ist nicht erforderlich, sich mit neuen Lieferanten zu verbinden.- Machen Sie es selbst: Wenn eine bestimmte Komponente sehr groß ist, müssen Sie sie möglicherweise selbst erstellen, z. B. bei Kafka. Stellen Sie zwei Personen ein, einen Master und ein Backup Seien Sie sich über alles sicher, wenn etwas schief geht. Die jährlichen Kosten betragen etwa 1 Million. In welchem Umfang können wir dieses Geld für Hardware und Komponenten einsparen? Natürlich können Sie auch einige kostengünstige Betriebs- und Wartungsingenieure einstellen (
- Hervorhebung hinzugefügt, hier sind möglicherweise Betriebs- und Wartungsingenieure erforderlich, aber der Rang ist nicht hoch), die tägliche Probleme lösen können, aber keine hohen Probleme lösen können Bei Problemen auf hoher Ebene können Sie externe Hilfe von Experten anfordern. Eigene Hardware produzieren + Lieferanten bieten Lösungen und Services: Im Vergleich zu PaaS-Produkten von Cloud-Anbietern sind Drittanbieter in der Regel kostengünstiger und reagieren schneller. Bei so vielen Komponenten dürfte jedoch jeder Anbieter dazu in der Lage sein Um nur eine begrenzte Anzahl von Produkten abzuwickeln, müssen Sie als Partei A möglicherweise gleichzeitig mit mehreren Lieferanten zusammenarbeiten, was etwas mühsam ist. Bei Produkten, die eine cloudübergreifende Zusammenarbeit erfordern, wie z. B. einheitliche Überwachung, Fehlerortung und FinOps-bezogene Produkte, ist die Wahrscheinlichkeit hoch, dass ein Drittanbieter besser geeignet ist, wenn das Unternehmen mehrere Clouds oder eine Hybrid-Cloud-Architektur nutzt.
Über die Berufswahl: Für erfahrene Experten in verschiedenen Komponenten besteht die erste Wahl darin, für einen Cloud-Hersteller zu arbeiten oder ein Unternehmen zu gründen, um Erfahrungen zu exportieren, und die zweite Wahl besteht darin, zu einer großen Fabrik zu gehen, die ihre eigenen Komponenten herstellt Für gewöhnliche kleine und mittlere Fabriken ist es schwierig, hohe Gehälter zu erhalten, da die Dienstleistungen von Drittanbietern sehr kostengünstig sind. Die Fähigkeit, schnell und sicher Änderungen vorzunehmen
Die häufigsten von der Unternehmensforschung und -entwicklung vorgenommenen Änderungen sind Binär- und Konfigurationsänderungen, und natürlich gibt es auch Änderungen an der Basisumgebung und den Komponenten.
Lassen Sie uns zunächst über Binär- und Konfigurationsänderungen sprechen. Wie können wir schnell und sicher iterieren? Wenn das Unternehmen noch relativ klein ist, muss man sich nicht allzu sehr auf die Konstruktion der Werkzeuge konzentrieren, sondern nur die Spezifikationen und Prozesse festlegen. Zu den Spezifikationen gehören: welches Konto unter welchem Verzeichnis bereitgestellt wird, wie Protokolle gespeichert werden, wie Prozesse gehostet werden, alle Änderungen müssen rollbar sein usw. Zu den Prozessaspekten gehören: Änderungsbenachrichtigungsmechanismus, kollaborativer Online-Mechanismus für mehrere Module und Nicht-Rollback Es muss ein Genehmigungsmechanismus usw. vorhanden sein.
Dann benötigen Sie quantitative Daten zu historischen Änderungen, z. B. wie viele Änderungen ein bestimmtes Team im letzten Quartal vorgenommen hat, wie hoch die Rollback-Rate ist und wie hoch die Fehlerquote ist. Jedes Team hat einen Vergleich Wenn es Ihnen nicht gut geht, wird es im nächsten Quartal scheitern.
Wenn das Unternehmen weiter wächst, kann es Arbeitskräfte investieren, um eine Änderungsplattform aufzubauen, standardisierte Systeme auf der Plattform zu implementieren und quantitative Daten zu erstellen. Da verschiedene Unternehmen unterschiedliche Situationen haben, ist dies im Zeitalter traditioneller physischer Maschinen und virtueller Maschinen der Fall selten gesehen Ein kommerzielles Wechselsystem zu haben. Natürlich wurden nach dem Aufstieg von Kubernetes viele der zugrunde liegenden Unterschiede abgeschirmt. Die auf Kubernetes basierende Plattform für Änderungen ist viel vielseitiger geworden, und verwandte Produkte sind auf den Markt gekommen.
Änderungen an der Produktionsumgebung sind nicht dasselbe wie Änderungen an der Testumgebung und der gemeinsamen Debugging-Umgebung. Für die Produktionsumgebung gelten strengere Stabilitätsanforderungen, während für die Testumgebung und die gemeinsame Debugging-Umgebung relativ niedrige Anforderungen gelten. Die sogenannten CI/CD-Systeme sind meist für Testumgebungen und gemeinsame Debugging-Umgebungen konzipiert. Es gibt nur eine Handvoll Unternehmen, die CD für Produktionsumgebungen implementieren können.
Fokus: Beim CI/CD-System für Test- und gemeinsame Debugging-Umgebungen geht es eher um die Beschleunigung der F&E-Effizienz; beim Änderungssystem für die Produktionsumgebung geht es eher um die Gewährleistung der Stabilität und die Implementierung standardisierter Systeme. Das Unternehmen ist in der Anfangsphase klein, daher reicht es aus, sich auf Regeln und Vorschriften zu verlassen. Später benötigt es Regeln und Vorschriften + eine Änderungsplattform, um zusammenzuarbeiten.
Wer wird dieses Regulierungssystem bestimmen? Wer wird die Change-Plattform entwickeln?
Die Formulierung der Spezifikationen befindet sich tatsächlich in einem frühen Stadium. Die Spezifikationen wurden möglicherweise entwickelt, bevor das Betriebs- und Wartungsteam überhaupt existierte. Daher ist es höchstwahrscheinlich, dass der CTO und das untergeordnete Kernteam sie formulieren werden. Wenn es noch nicht formuliert wurde, kann der Betriebs- und Wartungsdirektor (Betriebs- und Wartungsdirektor ist hier) die Führung bei der Formulierung übernehmen, und das Kernteam unter dem CTO wird es überprüfen (jeder hat Mitwirkung) und Schließlich trifft der CTO die Entscheidung (von oben nach unten) und gibt sie frei. Jeder führt sie aus.
Es ist angemessener, dass die Entwicklung der Änderungsplattform vom Betriebs- und Wartungsteam entwickelt wird. Später werden wir einige andere Plattformen einführen und ein dediziertes Betriebs- und Wartungsteam einrichten (es gibt keinen Unterschied zwischen Betrieb und Wartung). Ich spreche hier von SRE, Sie können es auch verwalten. Es ist angemessen, dass dieses Team SRE-Team genannt wird. Der Wechsel der Plattform erfordert die Umsetzung der Unternehmensspezifikationen, sodass es relativ wenige Fälle von Outsourcing gibt. Nachdem das Unternehmen eine bestimmte Größe erreicht hat, ist die Selbstforschung und Akkumulation auf der Grundlage von Open-Source-Dingen eine hohe Wahrscheinlichkeit.
Zur Berufswahl: Change Management ist ein wichtiger Teil des Unternehmens und dient auch dem Stabilitätssystem. Dies ist eine typische DevOps-Position und die Obergrenze liegt wahrscheinlich bei P7+ (rein persönliche Meinung, nur als Referenz).
Das andere sind Änderungen an grundlegenden Komponenten und Umgebungen, typischerweise wie MySQL-Tabellenstruktur, Nginx-Konfiguration, DNS, VIP usw. Solche Änderungen können in die Komponentenverwaltungs- und -steuerungsplattform internalisiert werden, sodass Komponentenfähigkeitsanbieter Änderungen bereitstellen können Eingänge sowie Verwaltungs- und Kontrollfunktionen.
Fähigkeit zur Zuverlässigkeitsgarantie
Diese Fähigkeit ist sehr wichtig. SRE ist die Abkürzung für Site Reliability Engineering, also Site Reliability Engineering. Aus Sicht des CTO können in Zukunft verschiedene Probleme auftreten, wenn Software in der Produktionsumgebung bereitgestellt wird. Wir hoffen, über ein Engineering-System zu verfügen, das die Zuverlässigkeit gewährleistet. Das ist ein riesiges Thema, und dieser Artikel wird nicht ins Detail gehen, sondern nur klären, was es ist und wer dafür verantwortlich ist.
Die sogenannte Zuverlässigkeit ist der Prozess der Bekämpfung von Fehlern. Daher betrachten wir immer noch den Lebenszyklus von Fehlern und beginnen bei jedem Glied des Lebenszyklus, um Fehler zu besiegen oder sie sogar in der Wiege zu ersticken.
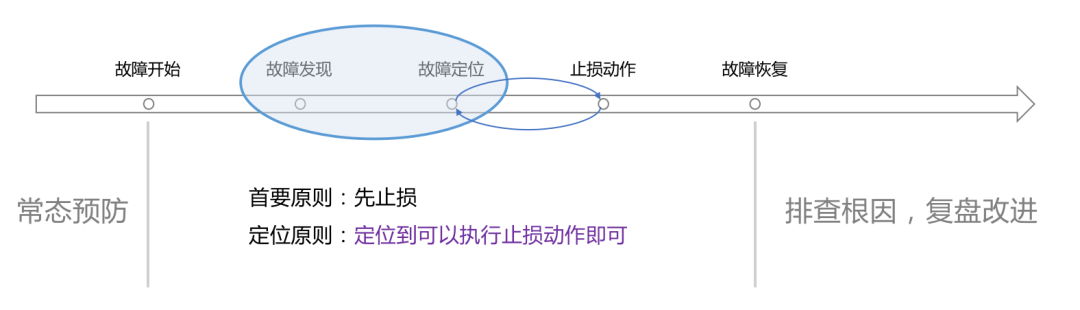
Bevor der Ausfall beginnt
Im Vorfeld steckt viel Arbeit in der Prävention und Risikokontrolle. Zum Beispiel: Alarmvollständigkeitsstandards formulieren und quantitative Bewertungen für jeden Geschäftsbereich vornehmen; Positionierungsprinzipien und -prozesse sowie Standards für die Fehlereinstufung und -verantwortung formulieren, die Entsprechung zwischen den Kernfunktionen und Servicemodulen jedes Geschäftsbereichs klären und festlegen eine globale Stabilitätsansicht oder der War Room wird verwendet, um fehlerhafte Module oder Schnittstellen zu optimieren und regelmäßige Übungen durchzuführen, um sie auf dem neuesten Stand zu halten;
Hier gibt es einige Dinge, die gelöst werden müssen, beispielsweise die Optimierung der Architektur. Im Übrigen lautet mein Vorschlag: Lassen Sie das Betriebs- und Wartungsteam die Führung übernehmen und die Forschung und Entwicklung zusammenarbeiten. Beispielsweise wird das Kernteam unter dem CTO höchstwahrscheinlich sowohl eine Betriebs- und Wartungsposition als auch eine technische Position für jedes Unternehmen haben. Im Namen wird der CTO die Entscheidung treffen und die Betriebs- und Wartungsposition ermächtigen, die Führung zu übernehmen Wenn es um den tatsächlichen Betrieb geht, kann es sein, dass die Position Nr. 1 im Bereich Betrieb und Wartung in der Zukunft eine fähige Person findet, die den eigentlichen Betrieb übernimmt, und jeder Geschäftsbereich verfügt möglicherweise auch über Personen, die sich darauf verlassen können auf der technischen Nr. 1-Position bei der Bereitstellung von Schnittstellenunterstützung.
Mit Ausnahme der Architekturoptimierung sind diese anderen Dinge alles horizontale Angelegenheiten. Es kann einige Methoden und Best Practices geben, um alle zusammenzubringen und dabei zu helfen, diese Methoden und Best Practices auszutauschen. Natürlich werden einige Leute Fragen haben: Können wir direkt jemanden aus dem Forschungs- und Entwicklungsteam finden, der eine so stabile virtuelle Organisation aufbaut und diese Angelegenheit gemeinsam vorantreibt? Tatsächlich können Sie es versuchen. Aber es gibt ein paar Probleme:
- Jeder Geschäftsbereich hat normalerweise nur ein oder zwei Schnittstellenpersonen. Wenn diese Person weniger Leute und mehr Arbeit hat, wird sie höchstwahrscheinlich Schwierigkeiten haben, die Entwicklung von Geschäftscodes und die Stabilitätsarbeit in Einklang zu bringen ein SRE
- Wenn es sich um SRE handelt, unterscheidet sich das Bewertungssystem tatsächlich von dem des F&E-Personals in Unternehmen. Wie ermittelt man den KPI? Und diese Person hat möglicherweise kein gutes Zugehörigkeitsgefühl
- Wenn sich diese Person gleichzeitig um Stabilität und Unternehmensforschung und -entwicklung kümmert, kann dies zu Trägheit bei den Menschen führen. Wenn die Stabilitätsarbeit auf Probleme stößt, werden sie dies natürlich tun wollen Machen Sie einige geschäftliche Forschungs- und Entwicklungsarbeiten. Wenn die geschäftliche Forschung und Entwicklung auf Probleme stößt, möchten Sie faul sein und Stabilitätsarbeit leisten. Fokus: Prävention und Risikokontrolle im Voraus. Bitte fragen Sie CXO nach dem Betriebs- und Wartungsleiter Ergebnisse, aber es muss eine großartige Zusammenarbeit geben und von oben nach unten vorantreiben. Damit die Rolle des SRE-Ingenieurs dieses Problem lösen kann, ist eine sehr professionelle, hochqualifizierte Person erforderlich. Es besteht eine hohe Wahrscheinlichkeit, dass die kognitiven Fähigkeiten innerhalb von 5 Jahren nach der Einstellung von SRE aus dem leitenden F&E-Team nicht mithalten können ist eine gute Wahl. Probieren Sie es aus.
Reduzieren Sie die Auswirkungen nach Beginn des Fehlers
Sobald ein Fehler auftritt, besteht unser vorrangiges Ziel darin, die Auswirkungen zu verringern. Die zuständigen Teams arbeiteten sofort zusammen, um schnell die direkte Ursache zu lokalisieren, den Verlust schnell zu stoppen und anschließend langsam die Grundursache zu untersuchen. Dabei geht es um folgende Arbeitsinhalte:Fehler definieren: Normalerweise bedeuten Probleme mit Geschäftsindikatoren, dass Fehler begonnen haben, wie z. B. ein Rückgang des Auftragsvolumens, ein Rückgang des Ride-Hailing-Anrufvolumens und ein Rückgang des Zahlungsvolumens Der Chef wird solchen Indikatoren besondere Aufmerksamkeit schenken. Die CPU einer bestimmten Maschine ist so hoch, dass es sich möglicherweise nur um ein intern verdautes Problem handelt. Sogar Systeme vom Typ K8 können das Driftproblem automatisch lösen. Dies hat normalerweise keine Auswirkungen auf den Hauptprozess des Kunden und der Chef achtet nicht darauf. Um nicht verwirrt zu werden, müssen wir die Definition von Fehlern und Problemen unterscheiden. Verschiedene Geschäftsbereiche haben unterschiedliche Indikatoren, aber die allgemeine Methodik ist dieselbe.
Reaktion auf Störungen: Ist der Empfänger der Störungsmeldung für geschäftliche Forschung und Entwicklung zuständig? Oder SRE? Oder OnCall-Center? Verschiedene Unternehmen haben große Unterschiede in ihren Vorgehensweisen. Meine persönliche Idee ist: Schicken Sie es direkt an diejenigen, die damit umgehen können! Es gibt kein Schwarz und Weiß. Wenn beispielsweise ein Problem mit dem Basisnetzwerk vorliegt, wird es offensichtlich an den Netzwerktechniker gesendet Versuchen Sie, es nicht erneut an Zhang San zu senden, und wenden Sie sich an Li Si, um die Fehlerbehebung durchzuführen gegen die Zeit erfolgen.
- Schnelle Ortung: Ein effektives Fehlerortungssystem ist ein Killer. Fehlerortungssysteme basieren in der Regel auf Beobachtbarkeitsdaten und können als Produkte auf Cockpit-Ebene betrachtet werden. Ohne Sortierung und Nutzung können diese riesigen Daten nicht in wertvolle Informationen umgewandelt werden. Aus Sicht der Positionierung sind normalerweise Folgendes erforderlich: Beobachtbarkeitssystem + Fehlerortung + kontinuierlicher Betrieb. Wenn Sie dies im Detail besprechen möchten, können Sie mich kontaktieren. Sie wissen nicht, wie Sie mich kontaktieren können? Offizielles SRETalk-Konto, erfahren Sie mehr.
- Schneller Verluststopp: Um den Verlust schnell zu stoppen, müssen Sie über einen vollständigen Plan verfügen. Bei der Überprüfung jedes Fehlers wird empfohlen, dass der CTO und der Betriebs- und Wartungsleiter auf die Effizienz des Plans achten, d Um Verluste zu stoppen, ist es immer noch eine Lösung, Geld zu sparen. Wenn es jetzt gespeichert wird, bedeutet das, dass Ihr Plan nicht vollständig genug ist.
- OK, das Obige ist voller Begeisterung, aber zurück zur Frage: Wen sollte der CTO nach den Ergebnissen dieser Arbeit fragen? Mein Vorschlag ist: SRE-Team (die Wörter Betrieb und Wartung und SRE kommen in diesem Artikel oft vor und bedeuten in diesem Artikel im Grunde dasselbe. Betrieb und Wartung sind hier nicht nur Betrieb). Offensichtlich kann SRE nicht alle Fehler beheben. Es sollte gesagt werden, dass die meisten Fehler auf Leute aus anderen Teams angewiesen sind, aber der CTO kann nicht immer zu Team A und Team B gehen. Daher muss
- SRE das Schwert des CTO von Shang Fang tragen und den gesamten Stabilitätsaufbau leiten. Jedes Unternehmen benötigt die beste Zusammenarbeit der Exportschnittstelle. Der sogenannte Stabilitätsaufbau umfasst die vorbeugende Risikokontrolle im Vorfeld, die Gesamtkoordination während der Veranstaltung Die Erholung nach dem Ereignis schreitet voran, was auch den größten Wert von SRE für das Unternehmen darstellt.
Best PracticesEs gibt viele Inhalte, z. B. welches Modellpaket besser geeignet ist, welche Netzwerkmethode besser geeignet ist und über welche Komponenten das Unternehmen eine bessere Kontrolle hat und besseren Support erhalten kann (ob intern). Teams oder Drittanbieter), welche Programmiersprachen und Frameworks werden vom Unternehmen empfohlen oder sogar benötigt und welche Access-Layer-Lösungen werden von der Branche empfohlen? Was ist der Änderungsplan? Wie macht man Beobachtbarkeit? Warte, warte.
Es ist nicht zu leugnen, dass diese praktischen Methoden eines großartigen Forschungs- und Entwicklungsteams in Unternehmen gut verstanden werden, aber es ist auch nicht zu leugnen, dass das Niveau nach mehr Geschäftsbereichen gemischt wird und ein Team mit einem schlechten Niveau unweigerlich jemanden mit einer Trainerrolle benötigt , und nichts wird passieren. Suchen Sie den CTO. Als horizontales technisches Team ist das SRE-Team besonders geeignet, sich um diese Angelegenheit zu kümmern. Aber offensichtlich handelt es sich hierbei um eine Spitzenposition, die nicht von Neulingen besetzt werden kann. Die Rekrutierung hochrangiger Mitarbeiter für die Geschäftsabwicklung ist ein wirksames Mittel, um die Vereinheitlichung des Technologie-Stacks zu fördern Nun, das Technologiesystem wird florieren. Dahinter verbergen sich verschiedene Governance-Dilemmata.
Die oben genannten vier unterstützenden Fähigkeiten, wie sollte die Geschäftsseite sie erhalten, wie sollte der CTO koordinieren, wie sollten die verschiedenen Teams zusammenarbeiten, das ist alles. Nachfolgend erstellen wir zwei weitere Zusammenfassungen. Zusammenfassung 1: Wie kann der CTO dem Geschäftsbereich helfen, diese unterstützenden Fähigkeiten zu erhalten? Natürlich muss der CTO nicht alles selbst machen, aber der CTO muss die Dinge gut kontrollieren. Der CTO muss Richtlinien erlassen und der Oberbefehlshaber der gesamten Armee sein. Die horizontale Arbeit wird dem SRE-Team überlassen, und das Schnittstellenpersonal jedes Teams arbeitet hart daran, zusammenzuarbeiten. Dies ist höchstwahrscheinlich eine bewährte Vorgehensweise. Wenn die horizontalen Arbeitsziele vollständig in den geschlossenen Kreislauf des Geschäftsteams verstreut sind, können Sie die Fähigkeit zur Erfahrungsverbreitung, die das horizontale Team mit sich bringt, nicht nutzen. Darüber hinaus bestimmt der Hintern den Kopf, und wenn Sie nicht in der richtigen Position sind, können Sie nicht das tun, was Sie wollen. Jedes Unternehmen hat seine eigene kleine Neunundneunzig Ein Mechanismus, um die Vasallen niederzuschlagen. Es tut mir leid, dieses Wort zu stark zu verwenden, die Absicht ist gut, Sie müssen es selbst erleben. Darüber hinaus möchte ich noch etwas zum Thema FinOps hinzufügen. Sollte es auch SRE überlassen bleiben? Dies ist nicht unbedingt der Fall. Ich denke, es ist gut, das Unternehmen selbst für Gewinne und Verluste verantwortlich zu machen. Der Geschäftsführer sollte sich große Sorgen um KPIs machen, die sich auf Umsatz und Nettogewinn beziehen an den Geschäfts-GM. Der Geschäfts-GM kann Der selbstschließende Kreislauf ist ein Kompromiss. Zusammenfassung 2: Vorschläge für die Auswahl einer Laufbahn im operativen Bereich/SREWenn Ihr Jobniveau und Ihre Gehaltsvorstellungen nicht allzu hoch sind, können Sie einige relativ einfache operative Tätigkeiten ausüben. Es besteht eine hohe Wahrscheinlichkeit, dass diese Position nicht verschwinden wird 10 Jahre. Wenn Sie höhere Erwartungen an Rang und Gehalt haben, ist es ein effektiver Weg, zunächst tief in eine bestimmte Nische einzutauchen und ein Branchenexperte zu werden. Danach wird es sich auf die Integration mehrerer technischer Richtungen konzentrieren und sich in der Breite weiterentwickeln. Starten Sie danach ein Unternehmen oder werden Sie leitender Angestellter. Der Autor dieses ArtikelsQin Xiaohui, unternehmerische Forschung und Entwicklung von Open-Falcon und Nightingale, Autor von Geek Time's „Operation and Maintenance Monitoring System Practical Notes“, Manager des öffentlichen Kontos SRETalk und unternehmerischer Partner von Kuaimao-Nebel, Die Richtung des Unternehmertums besteht darin, Stabilität zu gewährleisten. Wenn Sie irgendwelche Bedürfnisse haben, können Sie mich gerne für die Kommunikation kontaktieren.
Das obige ist der detaillierte Inhalt vonAus CTO-Perspektive: Wie man Betriebs- und Wartungs-/SRE-Fähigkeiten aufbaut. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Detaillierte Einführung in die Datenübertragungssicherheit von DSMM
- Zusammenfassung von 40 häufig genutzten Intrusion-Ports für Hacker, die es wert sind, gesammelt zu werden
- Drei Prozessinjektionstechniken in der Mitre ATT&CK-Matrix
- Grundsätze der sicheren Entwicklungspraxis
- So beheben Sie die Sicherheitslücke bei der Remote-Befehlsausführung in der Apache-Achsenkomponente