
Heim >Datenbank >MySQL-Tutorial >Beispielanalyse für MySQL-Infrastruktur und Protokollsystem
Beispielanalyse für MySQL-Infrastruktur und Protokollsystem

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-04 16:27:311075Durchsuche

1. MySQL-Infrastruktur
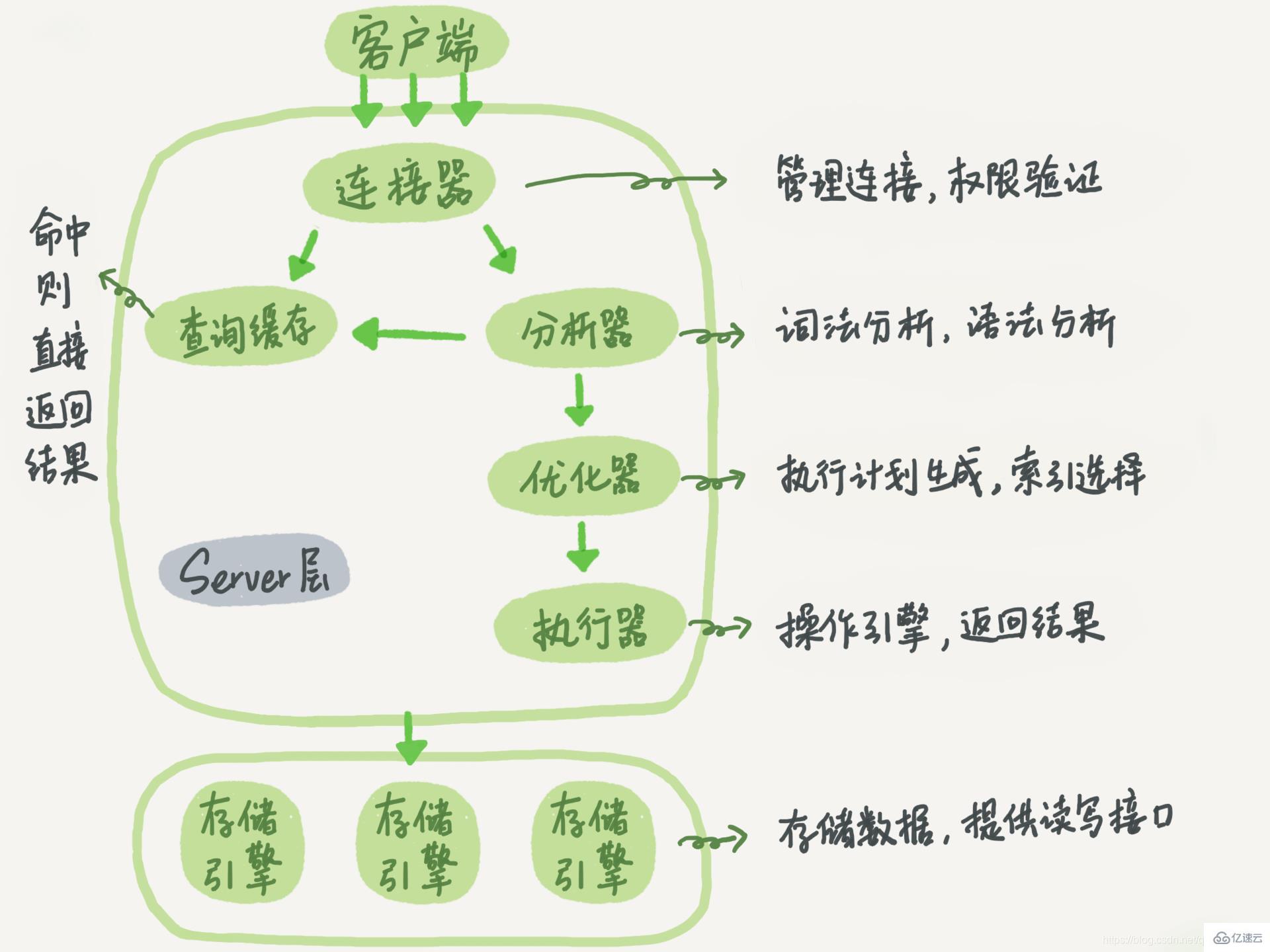
MySQL kann in zwei Teile unterteilt werden, die Serverschicht und die Speicher-Engine-Schicht
Die Serverschicht umfasst Konnektoren, Abfragecaches, Analysatoren, Optimierer, Ausführer usw., deckt MySQL ab Die meisten Kerndienstfunktionen sowie alle integrierten Funktionen (z. B. Datum, Uhrzeit, Mathematik- und Verschlüsselungsfunktionen usw.) sowie alle speicherübergreifenden Engine-Funktionen sind in dieser Schicht implementiert, z. B. gespeicherte Prozeduren. Trigger, Ansichten usw.
Speicher Die Engine ist für die Datenspeicherung und den Datenabruf verantwortlich. Es können mehrere Speicher-Engines (wie InnoDB, MyISAM und Memory) unterstützt werden, die auf dem Plug-in-Architekturmodell basieren. InnoDB ist derzeit die am häufigsten verwendete Speicher-Engine und ist seit MySQL-Version 5.5.5 die Standard-Speicher-Engine. Die Möglichkeit, die Ausführung der Speicher-Engine festzulegen, besteht darin, engin=memory in der SQL-Anweisung zu verwenden. Der Connector ist für den Aufbau einer Verbindung mit dem Client sowie für deren Verwaltung und Verwaltung verantwortlich. verbinden. Der Verbindungsbefehl lautet im Allgemeinen:
mysql -h$ip -P$port -u$user -p
MySQL im Verbindungsbefehl ist ein Client-Tool, das zum Herstellen einer Verbindung mit dem Server verwendet wird. Nach Abschluss des TCP-Handshakes beginnt der Connector mit der Authentifizierung der Identität. Wenn der Benutzername oder das Kennwort falsch ist, erhalten Sie die Fehlermeldung „Zugriff für Benutzer verweigert“ und das Client-Programm beendet die Ausführung Wenn Sie Ihr Passwort eingeben, werden Ihre Berechtigungen aus der Berechtigungstabelle abgerufen. Anschließend hängt die Berechtigungsbeurteilungslogik in diesem Zusammenhang von den zu diesem Zeitpunkt gelesenen Berechtigungen ab
Das bedeutet, dass, nachdem ein Benutzer erfolgreich eine Verbindung hergestellt hat, selbst wenn die Berechtigungen des Benutzers mit dem Administratorkonto geändert werden, dies keine Auswirkungen hat Berechtigungen bestehender Verbindungen. Nachdem die Änderung abgeschlossen ist, verwenden nur neu erstellte Verbindungen die neuen Berechtigungseinstellungen
Nach Abschluss der Verbindung befindet sich die Verbindung in einem Ruhezustand, wenn Sie keine weiteren Aktionen ausführen. Dies können Sie im Befehl „show Processlist“ sehen
- Wenn der Befehl „Sleep“ lautet, bedeutet dies, dass es sich bei dieser Verbindung um eine Leerlaufverbindung handelt. Wenn der Client zu lange inaktiv ist, wird sie vom Connector automatisch getrennt. Diese Zeit wird durch den Parameter wait_timeout gesteuert. Der Standardwert beträgt 8 Stunden
Wenn der Client nach dem Trennen der Verbindung erneut eine Anfrage sendet, erhält er eine Fehlermeldung: Verbindung zum MySQL-Server während der Abfrage verloren. Zu diesem Zeitpunkt müssen Sie die Verbindung wiederherstellen und dann die Anforderung ausführen. Wenn der Client weiterhin Anforderungen sendet, bezieht sich eine lange Verbindung auf die Verwendung derselben Verbindung nach dem Herstellen einer Verbindung mit der Datenbank. Unter einer kurzen Verbindung versteht man das Trennen der Verbindung, nachdem jedes Mal einige Abfragen ausgeführt wurden, und das erneute Herstellen einer Verbindung für die nächste Abfrage.
Der Vorgang des Verbindungsaufbaus ist normalerweise komplizierter. Daher wird empfohlen, möglichst lange Verbindungen zu verwenden Aber verwenden Sie sie alle Nach einer langen Verbindung nimmt der von MySQL belegte Speicher manchmal sehr schnell zu. Dies liegt daran, dass der von MySQL während der Ausführung vorübergehend verwendete Speicher im Verbindungsobjekt verwaltet wird. Diese Ressourcen werden freigegeben, wenn die Verbindung getrennt wird. Wenn sich lange Verbindungen ansammeln, belegen sie möglicherweise zu viel Speicher und werden vom System zwangsweise beendet. Dem Phänomen nach kann MySQL mit den folgenden zwei Lösungen neu gestartet werden:
1 . Lange Verbindung. Nach interner Einschätzung des Programms wird die Verbindung nach einer bestimmten Zeit getrennt, wenn eine Abfrage ausgeführt wird, die viel Speicher beansprucht. Wenn Sie eine erneute Abfrage durchführen müssen, müssen Sie die Verbindung neu herstellen
2 Wenn Sie MySQL5.7 oder eine neuere Version verwenden, können Sie die Verbindungsressource neu initialisieren, indem Sie nach jeder Ausführung eines relativ großen Vorgangs mysql_reset_connection ausführen. Neu formuliert: Obwohl für diesen Vorgang keine erneute Verbindung oder Überprüfung der Berechtigungen erforderlich ist, wird der Verbindungsstatus auf den ursprünglichen Erstellungsstatus zurückgesetzt
2. Abfragecache
可以将参数query_cache_type设置成DEMAND,这样对于默认的SQL语句都不使用查询缓存。而对于确定要是查询缓存的语句,可以用SQL_CACHE显示指定,如下面这条语句一样:
select SQL_CACHE * from T where ID=10;
MySQL8.0版本直接将查询缓存的整块功能删掉了
3、分析器
如果没有命中查询缓存,就要开始真正执行语句了。MySQL首先要对SQL语句做解析
分析器会先做词法分析。MySQL需要识别一条由多个字符串和空格组成的SQL语句,将其中的每个字符串识别并理解其代表的意义
select * from T where ID=10;
当输入select关键字时,MySQL会识别它为一个查询语句。它也要把字符串T识别成表名T,把字符串ID识别成列ID
做完了这些识别以后,就要做语法分析。基于词法分析的结果,语法分析器会依据MySQL语法规则来检查这个SQL语句是否符合规范。如果语法不对,就会收到"You have an error in your SQL syntax"的错误提示
4、优化器
经过了分析器,在开始执行之前,还要先经过优化器的处理
优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联的时候,决定各个表的连接顺序
5、执行器
优化器阶段完成后,这个语句的执行方案就确定下来了,然后进入执行器阶段,开始执行语句
开始执行的时候,要先判断一下你对这个表T有没有执行查询的权限,如果没有,就会返回没有权限的错误,如下所示
mysql> select * from T where ID=10; ERROR 1142 (42000): SELECT command denied to user 'b'@'localhost' for table 'T'
如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口
比如在表T中,ID字段没有索引,那么执行器的执行流程是这样的:
1.调用InnoDB引擎接口取这个表的第一行,判断ID值是不是10,如果不是则跳过,如果是则将这个行存在结果集中
2.调用引擎接口取下一行,重复相同的判断逻辑,直到取到这个表的最后一行
3.执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端
在慢查询日志中可以查看到一个名为rows_examined的字段,其表示执行该语句所扫描的行数。这个值就是在执行器每次调用引擎获取数据行的时候累加的
在有些场景下,执行器调用一次,在引起内部则扫描了多行,因此引擎扫描行数跟rows_examined并不是完全相同的
二、日志系统
表T的创建语句如下,这个表有一个主键ID和一个整型字段c:
create table T(ID int primary key, c int);
如果要将ID=2这一行的值加1,SQL语句如下:
update T set c=c+1 where ID=2;
1、redo log(重做日志)
在MySQL中,如果每次的更新操作都需要写进磁盘,然后磁盘也要找到对应的那条记录,然后再更新,整个过程IO成本、查找成本都很高。MySQL里常说的WAL技术,全称是Write-Ahead Logging,它的关键点就是先写日志,再写磁盘
当有一条记录需要更新的时候,InnoDB引擎就会把记录写到redo log里面,并更新buffer pool的page,这个时候更新就算完成了
buffer pool是物理页的缓存,对InnoDB的任何修改操作都会首先在buffer pool的page上进行,然后这样的页面将被标记为脏页并被放到专门的flush list上,后续将由专门的刷脏线程阶段性的将这些页面写入磁盘
InnoDB的redo log是固定大小的,比如可以配置为一组4个文件,每个文件的大小是1GB,从头开始写,写到末尾就又回到开头循环写
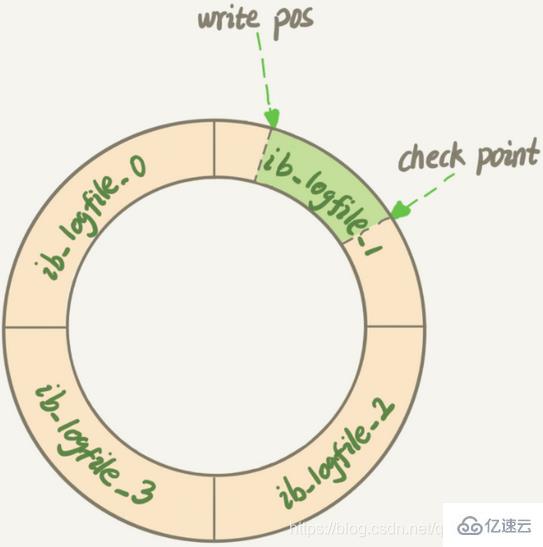
write pos是当前记录的位置,一边写一边后移,写到第3号文件末尾后就回到0号文件开头。check point是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件
write pos和check point之间空着的部分,可以用来记录新的操作。如果write pos追上check point,这时候不能再执行新的更新,需要停下来擦掉一些记录,把check point推进一下
有了redo log,InnoDB就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe
2、binlog(归档日志)
MySQL整体来看就有两块:一块是Server层,主要做的是MySQL功能层面的事情;还有一块是引擎层,负责存储相关的具体事宜。InnoDB引擎拥有一种特定的日志称为redo log,而Server层也有其自己的日志,被称为binlog
为什么会有两份日志?
Weil es zu Beginn keine InnoDB-Engine in MySQL gab. Die mit MySQL gelieferte Engine ist MyISAM, aber MyISAM verfügt nicht über Absturzsicherungsfunktionen und Binlog-Protokolle können nur zur Archivierung verwendet werden. InnoDB wird in Form eines Plug-Ins in MySQL eingeführt. Da es keine absturzsicheren Funktionen gibt, verwendet InnoDB das Binlog-Protokollformat: Es gibt drei Binlog-Formate: STATEMENT, ROW, MIXED
1), STATEMENT-Modus
Der Originaltext der SQL-Anweisung wird im Binlog aufgezeichnet. Der Vorteil besteht darin, dass Datenänderungen nicht in jeder Zeile aufgezeichnet werden müssen, wodurch die Anzahl der Binlog-Protokolle reduziert, IO eingespart und die Leistung verbessert wird. Der Nachteil besteht darin, dass in einigen Fällen die Daten im Master-Slave inkonsistent sind (z. B. die Funktion „sleep()“, „last_insert_id()“ und benutzerdefinierte Funktionen (udf) usw. verursachen Probleme)
2) , ROW-Modus
Es müssen nur die geänderten Daten und der geänderte Status aufgezeichnet werden, ohne die Kontextinformationen jeder SQL-Anweisung aufzuzeichnen. Und es wird kein Problem sein, dass die Aufrufe und Trigger von gespeicherten Prozeduren oder Funktionen oder Triggern unter bestimmten Umständen nicht korrekt kopiert werden können. Der Nachteil besteht darin, dass eine große Menge an Protokollen generiert wird, insbesondere bei der Durchführung von Tabellenänderungsvorgängen, was zu einem schnellen Anstieg der Protokolle führt
3), GEMISCHTER Modus
Die gemischte Verwendung der beiden oben genannten Modi, allgemeine Replikation Verwendet den STATEMENT-Modus, um Binlog zu speichern. Für Vorgänge, die nicht im STATEMENT-Modus kopiert werden können, verwendet MySQL die Protokollspeichermethode entsprechend der ausgeführten SQL-Anweisung
3 Der Unterschied zwischen Redo-Log und Binlog-Log
1. Das Redo-Log ist einzigartig für die InnoDB-Engine und kann von allen Engines verwendet werden Bestimmte Daten; das Binlog ist ein logisches Protokoll, das die ursprüngliche Version der Anweisung aufzeichnet. Fügen Sie beispielsweise 1 zum c-Feld in der Zeile mit der ID = 2
3 hinzu. und der Speicherplatz wird immer aufgebraucht; das Binlog kann zusätzlich geschrieben werden, und die Binlog-Datei wird nach Erreichen einer bestimmten Größe zum nächsten gewechselt, das vorherige Protokoll wird nicht überschrieben
4. Phase Commit Der interne Prozess des Executors und der InnoDB-Engine beim Ausführen dieser Update-Anweisung:1 Der Executor findet zuerst die Engine und übernimmt ID=2 Diese Zeile. Die ID ist der Primärschlüssel, und die Engine verwendet direkt die Baumsuche, um diese Zeile zu finden. Wenn sich die Daten der Zeile mit der ID=2 bereits im Speicher befinden, werden sie direkt an den Executor zurückgegeben. Andernfalls müssen sie zuerst von der Festplatte in den Speicher gelesen und dann zurückgegeben werden Von der Engine bereitgestellte Zeilendaten. Addieren Sie 1 zu diesem Wert, um eine neue Datenzeile zu erhalten, und rufen Sie dann die Engine-Schnittstelle auf, um diese neue Datenzeile zu schreiben3 Die Engine aktualisiert diese neue Datenzeile in den Speicher und zeichnet sie auf Der Aktualisierungsvorgang wird in das Redo-Log geschrieben, wenn sich das Redo-Log im Vorbereitungszustand befindet. Informieren Sie dann den Executor darüber, dass die Ausführung abgeschlossen ist und Sie die Transaktion jederzeit senden können
4 Der Executor generiert das Binlog dieser Operation und schreibt das Binlog auf die Festplatte5. und die Engine schreibt das soeben geschriebene Redo. Das Protokoll wird in den übermittelten Status geändert und das Update wird wie folgt ausgeführt. Das Leuchtfeld im Bild zeigt an, dass es in InnoDB ausgeführt wird Das dunkle Kästchen zeigt an, dass es im Executor ausgeführt wird.
Das Redo-Log-Schreiben ist in zwei Schritte unterteilt: Vorbereiten und Festschreiben, was ein zweistufiges Festschreiben ist, da Redo-Log und Binlog zwei unabhängige Logiken sind Ein zweistufiges Commit ist nicht erforderlich. Schreiben Sie entweder zuerst das Redo-Log und dann das Binlog, oder beenden Sie das Schreiben des Binlogs und schreiben Sie dann das Redo-Log1 Beenden Sie zuerst das Redo-Log und schreiben Sie dann das Binlog. Wenn der MySQL-Prozess abnormal neu startet, nachdem das Redo-Log geschrieben wurde, das Binlog jedoch noch nicht geschrieben wurde. Da die Daten nach dem Schreiben des Redo-Protokolls auch bei einem Systemabsturz noch wiederhergestellt werden können, beträgt der Wert von c in dieser Zeile nach der Wiederherstellung 1. Da das Binlog jedoch vor seiner Fertigstellung abstürzte, wurde diese Anweisung zu diesem Zeitpunkt nicht im Binlog aufgezeichnet. Der im Binlog aufgezeichnete Wert von c ist 02. Schreiben Sie zuerst das Binlog und dann das Redo-Log. Wenn es nach dem Schreiben des Binlogs zu einem Absturz kommt, ist die Transaktion nach der Wiederherstellung nach dem Absturz ungültig, da das Redo-Log noch nicht geschrieben wurde. Daher ist der Wert von c in dieser Zeile 0. Aber das Binlog hat bereits das Protokoll der Änderung von c von 0 auf 1 aufgezeichnet. Daher gibt es bei Verwendung der Binlog-Wiederherstellung eine weitere Transaktion und der Wert der endgültig wiederhergestellten Spalte C beträgt 1Wenn kein zweiphasiges Commit verwendet wird, stimmt der Datenbankstatus möglicherweise nicht mit dem Bibliotheksstatus über die Protokollwiederherstellung überein . Sowohl das Redo-Log als auch das Binlog können verwendet werden, um den Commit-Status einer Transaktion darzustellen, und das zweistufige Commit dient dazu, die beiden Zustände logisch konsistent zu halten. Das Redo-Log wird verwendet, um absturzsichere Funktionen sicherzustellen. Wenn der Parameter innodb_flush_log_at_trx_commit auf 1 gesetzt ist, bedeutet dies, dass das Redo-Protokoll jeder Transaktion direkt auf der Festplatte gespeichert wird. Dies kann sicherstellen, dass Daten nach einem abnormalen Neustart von MySQL nicht verloren gehen Das Binlog jeder Transaktion wird auf der Festplatte gespeichert, wodurch sichergestellt wird, dass das Binlog nach einem abnormalen Neustart von MySQL nicht verloren geht三、MySQL刷脏页
1、刷脏页的场景
当内存数据页跟磁盘数据页不一致的时候,我们称这个内存页为脏页。当内存数据被写入磁盘后,内存和磁盘上的数据页就会保持一致,这种状态被称为“干净页”
第一种场景是,InnoDB的redo log写满了,这时候系统会停止所有更新操作,把checkpoint往前推进,redo log留出空间可以继续写

checkpoint位置从CP推进到CP’,就需要将两个点之间的日志对应的所有脏页都flush到磁盘上。之后,上图中从write pos到CP’之间就是可以再写入的redo log的区域第二种场景是,系统内存不足。当内存空间不足以分配新的内存页时,系统会选择淘汰一些数据页来腾出内存空间以供其他数据页使用。如果淘汰的是脏页,就要先将脏页写到磁盘
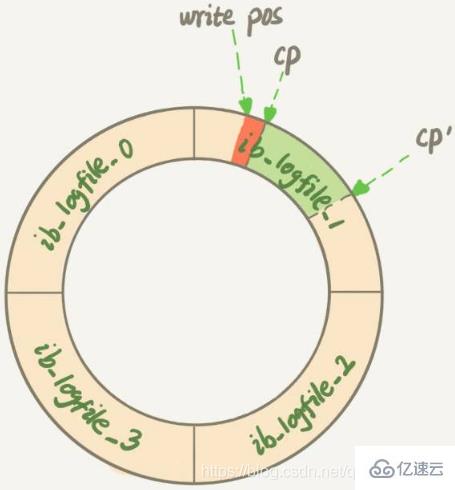
这时候不能直接把内存淘汰掉,下次需要请求的时候,从磁盘读入数据页,然后拿redo log出来应用不就行了?
这里是从性能考虑的。如果刷脏页一定会写盘,就保证了每个数据页有两种状态:一种是内存里存在,内存里就肯定是正确的结果,直接返回;另一种是内存里没有数据,就可以肯定数据文件上是正确的结果,读入内存后返回。这样的效率最高
第三种场景是,MySQL认为系统空闲的时候刷脏页,当然在系统忙的时候也要找时间刷一点脏页
第四种场景是,MySQL正常关闭的时候会把内存的脏页都flush到磁盘上,这样下次MySQL启动的时候,就可以直接从磁盘上读数据,启动速度会很快
redo log写满了,要flush脏页,出现这种情况的时候,整个系统就不能再接受更新了,所有的更新都必须堵住
内存不够用了,要先将脏页写到磁盘,这种情况是常态。InnoDB用缓冲池管理内存,缓冲池中的内存页有三种状态:
第一种是还没有使用的
第二种是使用了并且是干净页
第三种是使用了并且是脏页
InnoDB的策略是尽量使用内存,因此对于一个长时间运行的库来说,未被使用的页面很少
如果要读取的数据页不在内存中,则需要从缓冲池中请求一个数据页。这时候只能把最久不使用的数据页从内存中淘汰掉:如果要淘汰的是一个干净页,就直接释放出来复用;但如果是脏页,即必须将脏页先刷到磁盘,变成干净页后才能复用
刷页虽然是常态,但是出现以下两种情况,都是会明显影响性能的:
一个查询要淘汰的脏页个数太多,会导致查询的响应时间明显变长
日志写满,更新全部堵住,写性能跌为0,这种情况对敏感业务来说,是不能接受的
2、InnoDB刷脏页的控制策略
首先,要正确地告诉InnoDB所在主机的IO能力,这样InnoDB才能知道需要全力刷脏页的时候,可以刷多快。参数为innodb_io_capacity,建议设置成磁盘的IOPS
考虑到脏页比例和redo log写入速度,InnoDB的刷盘速度得到优化。默认值为75%,参数innodb_max_dirty_pages_pct限制了脏页的比例。脏页比例是通过Innodb_buffer_pool_pages_dirty/Innodb_buffer_pool_pages_total得到的,SQL语句如下:
mysql> select VARIABLE_VALUE into @a from performance_schema.global_status where VARIABLE_NAME = 'Innodb_buffer_pool_pages_dirty'; select VARIABLE_VALUE into @b from performance_schema.global_status where VARIABLE_NAME = 'Innodb_buffer_pool_pages_total'; select @a/@b;
四、日志相关问题
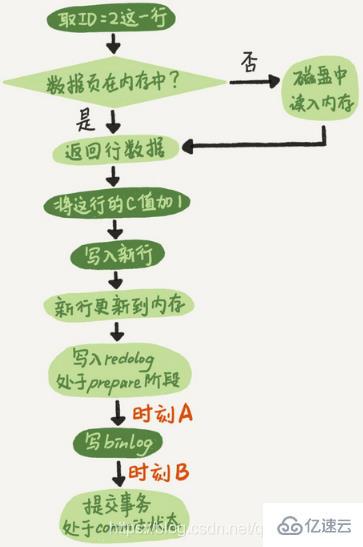
问题一:在两阶段提交的不同时刻,MySQL异常重启会出现什么现象
如果在图中时刻A的地方,也就是写入redo log处于prepare阶段之后、写binlog之前,发生了崩溃,由于此时binlog还没写,redo log也还没提交,所以崩溃恢复的时候,这个事务会回滚。这时候,binlog还没写,所以也不会传到备库
如果在图中时刻B的地方,也就是binlog写完,redo log还没commit前发生崩溃,那崩溃恢复的时候MySQL怎么处理?
崩溃恢复时的判断规则:
1)如果redo log里面的事务是完整的,也就是已经有了commit标识,则直接提交
2)如果redo log里面的事务只有完整的prepare,则判断对应的事务binlog是否存在并完整
a.如果完整,则提交事务
b.否则,回滚事务
时刻B发生崩溃对应的就是2(a)的情况,崩溃恢复过程中事务会被提交
问题二:MySQL怎么知道binlog是完整的?
一个事务的binlog是有完整格式的:
statement格式的binlog,最后会有COMMIT
row格式的binlog,最后会有一个XID event
问题三:redo log和binlog是怎么关联起来的?
它们有一个共同的数据字段,叫XID。崩溃恢复的时候,会按顺序扫描redo log:
如果碰到既有prepare、又有commit的redo log,就直接提交
如果碰到只有prepare、而没有commit的redo log,就拿着XID去binlog找对应的事务
问题四:redo log一般设置多大?
如果是现在常见的几个TB的磁盘的话,redo log设置为4个文件、每个文件1GB
问题五:正常运行中的实例,数据写入后的最终落盘,是从redo log更新过来的还是从buffer pool更新过来的呢?
redo log并没有记录数据页的完整数据,所以它并没有能力自己去更新磁盘数据页,也就不存在数据最终落盘是由redo log更新过去的情况
脏页是指在正常运行的实例中,当数据页被修改后,与存储在磁盘上的数据页不一致。最终数据落盘,就是把内存中的数据页写盘。这个过程,甚至与redo log毫无关系
2.在崩溃恢复场景中,InnoDB如果判断到一个数据页可能在崩溃恢复的时候丢失了更新,就会将它对到内存,然后让redo log更新内存内容。更新完成后,内存页变成脏页,就回到了第一种情况的状态
问题六:redo log buffer是什么?是先修改内存,还是先写redo log文件?
在一个事务的更新过程中,日志是要写多次的。比如下面这个事务:
begin;insert into t1 ...insert into t2 ...commit;
这个事务要往两个表中插入记录,插入数据的过程中,生成的日志都得先保存起来,但又不能在还没commit的时候就直接写到redo log文件里
所以,redo log buffer就是一块内存,用来先存redo日志的。也就是说,在执行第一个insert的时候,数据的内存被修改了,redo log buffer也写入了日志。在执行commit语句时,才真正将日志写入redo log文件
五、MySQL是怎么保证数据不丢的?
只要redo log和binlog保证持久化到磁盘,就能确保MySQL异常重启后,数据可以恢复
1、binlog的写入机制
事务执行过程中,先把日志写到binlog cache,事务提交的时候,再把binlog cache写到binlog文件中。无法分割一个事务的binlog,因此无论该事务有多大,都必须确保一次性写入
系统给binlog cache分配了一片内存,每个线程一个,参数binlog_cache_size用于控制单个线程内binlog cache所占内存的大小。如果超过了这个参数规定的大小,就要暂存到磁盘
事务提交的时候,执行器把binlog cache里的完整事务写入到binlog中,并清空binlog cache
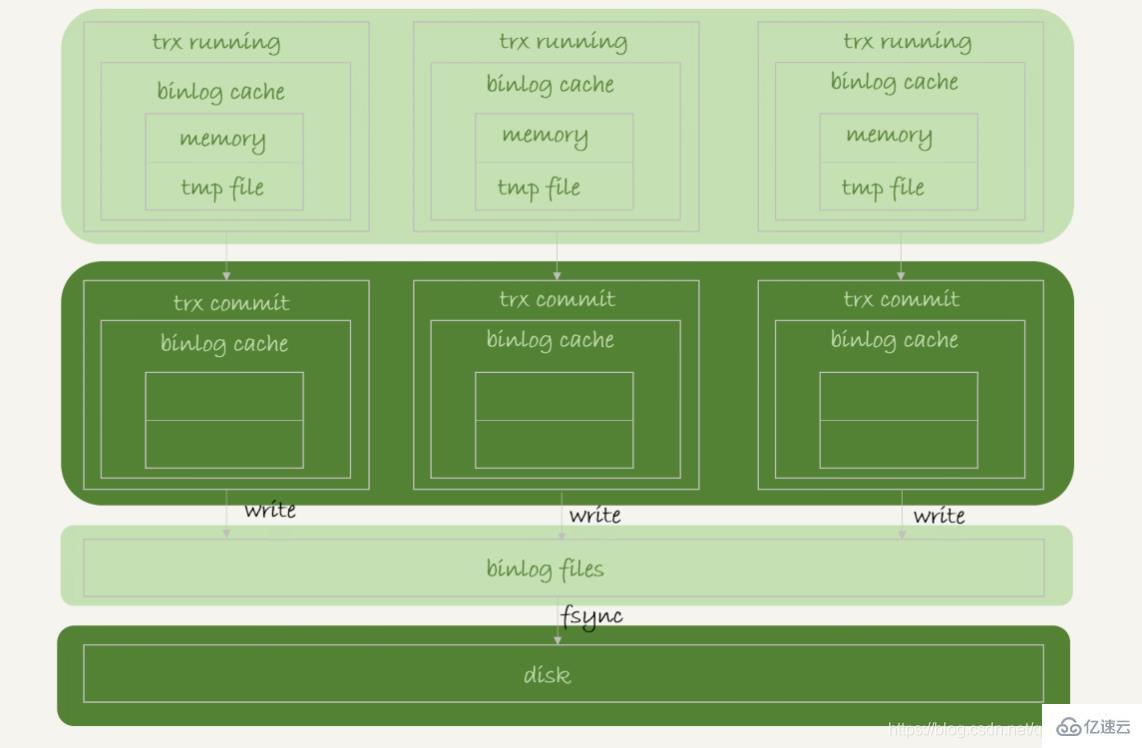
每个线程有自己binlog cache,但是共用一份binlog文件
图中的write,指的就是把日志写入到文件系统的page cache,并没有把数据持久化到磁盘,所以速度比较快
图中的fsync,才是将数据持久化到磁盘的操作。一般情况下认为fsync才占磁盘的IOPS
write和fsync的时机,是由参数sync_binlog控制的:
sync_binlog=0的时候,表示每次提交事务都只write,不fsync
sync_binlog=1的时候,表示每次提交事务都会执行fsync
sync_binlog=N(N>1)的时候,表示每次提交事务都write,但累积N个事务后才fsync
因此,在出现IO瓶颈的场景中,将sync_binlog设置成一个比较大的值,可以提升性能,对应的风险是:如果主机发生异常重启,会丢失最近N个事务的binlog日志
2、redo log的写入机制
在执行事务过程中所产生的 redo log 需要先写入 redo log 缓存。redo log buffer里面的内容不是每次生成后都要直接持久化到磁盘,也有可能在事务还没提交的时候,redo log buffer中的部分日志被持久化到磁盘
redo log可能存在三种状态,对应下图的三个颜色块

这三张状态分别是:
Existiert im Redo-Log-Puffer, physisch im MySQL-Prozessspeicher, dem roten Teil im Bild
wird auf die Festplatte geschrieben, bleibt aber nicht bestehen, physisch im Seitencache des Dateisystems, Das heißt, der gelbe Teil im Bild
wird auf der Festplatte gespeichert, die der Festplatte entspricht, die der grüne Teil im Bild ist
Protokollieren Sie das Schreiben in den Redo-Log-Puffer und das Schreiben in den Seitencache sind beide schnell, aber langlebig. Die Geschwindigkeit beim Flushen auf die Festplatte ist viel langsamer bedeutet, dass jede Transaktion einfach übermittelt wird.
- Bei der Einstellung 1 bedeutet dies, dass das Redo-Protokoll bei jeder Übermittlung einer Transaktion direkt auf der Festplatte gespeichert wird.
- Wann Auf 2 gesetzt bedeutet dies, dass InnoDB alle 1 Sekunde einen Hintergrundthread aufruft, um das Protokoll im Redo-Log-Puffer in den Seitencache des Dateisystems zu schreiben, und dann fsync aufruft, um es auf die Festplatte zu übertragen . Das Redo-Protokoll während der Transaktionsausführung wird ebenfalls direkt in den Redo-Log-Puffer geschrieben, und diese Redo-Protokolle werden auch vom Hintergrundthread auf der Festplatte gespeichert. Mit anderen Worten: Selbst wenn eine Transaktion noch nicht festgeschrieben wurde, wurde ihr Redo-Protokoll möglicherweise auf der Festplatte gespeichert
Es gibt zwei Szenarien, in denen das Redo-Protokoll einer nicht festgeschriebenen Transaktion auf die Festplatte geschrieben wird
1.Redo-Log-Puffer Wann Der belegte Speicherplatz erreicht bald die Hälfte von innodb_log_buffer_size, und der Hintergrundthread schreibt aktiv auf die Festplatte. Da die Transaktion nicht übermittelt wurde, besteht die Aktion zum Schreiben auf die Festplatte nur aus dem Schreiben ohne Aufruf von fsync, was bedeutet, dass sie nur im Seitencache des Dateisystems verbleibt2. Wenn eine parallele Transaktion übermittelt wird, wird der Redo-Log-Puffer dieser Transaktion gespeichert wird auf der Festplatte gespeichert. Gehen Sie davon aus, dass Transaktion A die Hälfte der Ausführung abgeschlossen hat und einige Redo-Protokolle in den Puffer geschrieben hat. Wenn innodb_flush_log_at_trx_commit auf 1 gesetzt ist, behält Transaktion B alle Protokolle im Redo-Log-Puffer bei Scheibe. In diesem Fall wird der Redo-Log-Puffer für Transaktion A zusammen auf der Festplatte aufgezeichnet
Zweistufiges Commit: Zuerst wird das Redo-Log vorbereitet, dann wird das Binlog geschrieben und schließlich wird das Redo-Log geschrieben engagiert. Wenn innodb_flush_log_at_trx_commit auf 1 gesetzt ist, wird das Redo-Log einmal in der Vorbereitungsphase beibehalten. Die Double-1-Konfiguration von MySQL bedeutet, dass sowohl sync_binlog als auch innodb_flush_log_at_trx_commit auf 1 gesetzt sind. Mit anderen Worten, bevor eine Transaktion vollständig festgeschrieben wird, muss sie auf zwei Festplatten-Flushes warten, einen für das Redo-Protokoll (Vorbereitungsphase) und einen für den Binlog-Mechanismus. Die logische Sequenznummer des Protokolls lautet LSN Wird monoton ansteigend verwendet, um den Schreibpunkten des Redo-Logs zu entsprechen. Jedes Mal, wenn ein Redo-Log mit der Länge geschrieben wird, wird der Wert von LSN zur Länge hinzugefügt. LSN wird auch auf der Datenseite von InnoDB aufgezeichnet, um sicherzustellen, dass durch die wiederholte Ausführung des Redo-Protokolls wiederholte Aktualisierungen der Datenseite vermieden werden.
Das Bild oben zeigt drei gleichzeitige Transaktionen in der Vorbereitungsphase, die alle das Redo geschrieben haben Protokollpuffer und im Festplattenprozess gespeichert, sind die entsprechenden LSNs 50, 120 bzw. 160. trx1 ist der erste, der eintrifft, und wird als Anführer dieser Gruppe ausgewählt Mit dem Schreiben auf die Festplatte hat diese Gruppe bereits begonnen. Bei drei Transaktionen ist die LSN ebenfalls 160 geworden oder gleich 160 wurden gelöscht. Zu diesem Zeitpunkt können trx2 und trx3 direkt zurückgegeben werden Damit ein fsync mehr Gruppenmitglieder mitbringen kann, haben wir die Zeitverzögerung von MySQL optimiert
binlog kann auch in Gruppen übermittelt werden. Wenn Sie Schritt 4 der obigen Abbildung ausführen, wird das Binlog auf die Festplatte übertragen, wenn die Binlogs von Wenn mehrere Transaktionen geschrieben wurden, werden sie zusammen gespeichert, sodass auch der IOPS-Verbrauch reduziert werden kann . Der Parameter binlog_group_commit_sync_delay gibt an, wie viele Mikrosekunden vor dem Aufruf von fsync verzögert werden sollen. Der Parameter _no_delay_count gibt die Akkumulation an. Solange eine dieser beiden Bedingungen erfüllt ist, wird der WAL-Mechanismus aufgerufen Es profitiert hauptsächlich von zwei Aspekten:Redo-Protokoll und Binlog werden nacheinander geschrieben, und das sequentielle Schreiben auf der Festplatte ist schneller als das zufällige Schreiben.
Der Gruppenübermittlungsmechanismus kann den IOPS-Verbrauch der Festplattenreihenfolge erheblich reduzieren
4. Wenn MySQL jetzt einen Leistungsengpass hat und der Engpass bei IO liegt, welche Methoden können verwendet werden, um die Leistung zu verbessern
1. wie oft akkumuliert werden soll) Rufen Sie nur den Parameter fsync auf, um die Anzahl der Binlog-Schreibvorgänge auf die Festplatte zu reduzieren. Obwohl diese Methode die Antwortzeit der Anweisung verlängern kann, besteht kein Risiko eines Datenverlusts, da dies durch absichtliches Warten erreicht wird
2 Setzen Sie sync_binlog auf einen Wert größer als 1 (schreiben Sie jedes Mal, wenn eine Transaktion festgeschrieben wird, aber kumulatives fsync nach N Transaktionen). Dabei besteht das Risiko, dass das Binlog-Protokoll verloren geht, wenn der Host ausgeschaltet wird
3. Setzen Sie innodb_flush_log_at_trx_commit auf 2 (schreiben Sie das Redo-Protokoll nur jedes Mal in den Seitencache, wenn eine Transaktion festgeschrieben wird). Dabei besteht die Gefahr, dass Daten verloren gehen, wenn der Host ausgeschaltet wird
Das obige ist der detaillierte Inhalt vonBeispielanalyse für MySQL-Infrastruktur und Protokollsystem. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!