
Heim >Datenbank >MySQL-Tutorial >Beispielanalyse einer MySQL-Unterdatenbank und -Untertabelle
Beispielanalyse einer MySQL-Unterdatenbank und -Untertabelle

- PHPznach vorne
- 2023-06-03 18:34:301227Durchsuche
1 Warum müssen wir die Datenbank in Tabellen aufteilen? Es reicht aus, eine Einzelmaschinendatenbank als Server zu verwenden Der Datenverkehr wird immer größer und wir stehen immer mehr Anfragen gegenüber. Wir trennen das Lesen und Schreiben der Datenbank. Wir verwenden mehrere Slave-Datenbankkopien (Slave), die für das Lesen verantwortlich sind, und die Hauptdatenbank (Master), die für das Schreiben verantwortlich ist . Der Master und der Slave realisieren die Datensynchronisierung und -aktualisierung durch Master-Slave-Replikation, um die Daten konsistent zu halten. Die Slave-Bibliothek kann horizontal erweitert werden, sodass mehr Leseanforderungen kein Problem darstellen. Das Hinzufügen eines Masters kann das Problem nicht lösen, da die Daten konsistent sein müssen und der Schreibvorgang eine Synchronisierung zwischen den beiden Mastern erfordert, was einer Duplizierung gleichkommt, und das Architekturdesign, das Speichern der Datenbank und der Tabellen, komplizierter ist Verschiedene MySQL-Server, jeder Server kann die Anzahl der Schreibanforderungen ausgleichen groß: Die einzelne Datenbank verfügt über eine begrenzte Verarbeitungskapazität, nicht genügend Speicherplatz auf dem Server und es treten E/A-Engpässe auf. Die einzelne Datenbank muss in mehrere kleinere Bibliotheken aufgeteilt werden#🎜🎜 #
A Eine einzelne Tabelle ist zu groß: Die CURD-Effizienz ist sehr gering.Die Datenmenge ist zu groß, was dazu führt, dass die Indexdatei zu groß wird und das Laden des Index durch Festplatten-E/A einige Zeit in Anspruch nimmt, was zu einer Zeitüberschreitung der Abfrage führt. Es reicht also nicht aus, nur Indizes zu verwenden. Sie müssen eine einzelne Tabelle in mehrere Tabellen mit kleineren Datensätzen aufteilen. Die von MyCat bereitgestellten Tabellenaufteilungsalgorithmen befinden sich alle in der Datei Rule.xml, die nach verschiedenen Tabellenaufteilungsalgorithmen aufgeteilt werden kann, z. B. zeitbasierte Aufteilung, konsistentes Hashing, direkte Verwendung des Primärschlüssels zum Modulieren der Anzahl der geteilten Tabellen usw.
Split-Strategie- Eine einzelne Bibliothek ist zu groß, überlegen Sie zunächst, ob es zu viele Tabellen gibt oder zu viele Daten:
- # 🎜🎜#Wenn aufgrund zu vieler Tabellen zu viele Daten vorhanden sind, verwenden Sie die vertikale Aufteilung, d. h. die Aufteilung in verschiedene Bibliotheken je nach Unternehmen#🎜🎜 #
- #🎜 🎜#Wenn die Datenmenge in einer einzelnen Tabelle zu groß ist, verwenden Sie die horizontale Aufteilung, d. h. teilen Sie die Tabellendaten gemäß einer bestimmten Regel (definierter Tabellenaufteilungsalgorithmus) in mehrere Tabellen auf by Rule.xml)
#🎜 🎜#
Das Prinzip der Unterdatenbank und Untertabelle sollte darin bestehen, zuerst die vertikale Aufteilung und dann die horizontale Aufteilung zu berücksichtigen
3. Vertikale Aufteilung Teildatenbank-Sharding und Lese-/Schreibtrennung können zusammen durchgeführt werden
1. Vertikale Teildatenbank#🎜🎜 #
server.xml<user name="root"> <property name="password">123456</property> <property name="schemas">USERDB1,USERDB2</property> </user>#🎜 🎜#Konfiguriert die beiden logischen Bibliotheken USERDB1 und USERDB2
schema.xml
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <!-- 逻辑数据库 --> <schema name="USERDB1" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1" /> <!-- 两个逻辑库对应两个不同的数据节点 --> <schema name="USERDB2" checkSQLschema="false" sqlMaxLimit="100"dataNode="dn2" /> <!-- 存储节点 --> <dataNode name="dn1" dataHost="node1" database="mytest1" /> <!-- 两个数据节点对应两个不同的物理机器 --> <dataNode name="dn2" dataHost="node2" database="mytest2" /> <!-- USERDB1对应mytest1,USERDB2对应mytest2 --> <!-- 数据库主机 --> <dataHost name="node1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.131.129" url="192.168.131.129:3306" user="root" password="123456" /> </dataHost> <dataHost name="node2" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.0.6" url="192.168.0.6:3306" user="root" password="123456" /> </dataHost> </mycat:schema>
Der Client muss eine Verbindung zu verschiedenen Logikbibliotheken herstellen. Je nach Geschäftsbetrieb werden verschiedene Logikbibliotheken verwendet.
Die beiden Maschinen teilten die Bibliothek gleichmäßig auf und teilten den Druck der ursprünglichen Einzelmaschine. Das Datenbank-Sharding geht mit dem Tabellen-Sharding einher, das die Tabelle aus geschäftlicher Sicht aufteilt. Es wird im Allgemeinen für große Tabellen mit Hunderten von Spalten verwendet, um „seitenübergreifende“ Probleme zu vermeiden, die durch große Datenmengen bei Abfragen verursacht werden. Im Allgemeinen gibt es viele Felder in der Tabelle, und die weniger häufig verwendeten Felder mit größeren Daten und längeren Längen (z. B. Texttypfelder) werden in erweiterte Tabellen aufgeteilt. Felder mit höherer Zugriffshäufigkeit werden in einer separaten Tabelle platziert 4. Horizontale Unterdatenbank und Tabelle Für eine einzelne Tabelle mit einer großen Datenmenge (z. B. eine Bestellung). Tabelle) Befolgen Sie bestimmte Regeln (RANGE, HASH-Modulus usw.), um die Daten in mehrere Tabellen aufzuteilen. Nicht empfohlen, da sich die Tabellen immer noch in derselben Datenbank befinden und es daher möglicherweise zu einem E/A-Engpass bei der Ausführung von Vorgängen für die gesamte Datenbank kommt. Tabellen und Bibliotheken sind lediglich unterschiedliche Datensammlungen in den Tabellen. Die Anwendung der Subdatenbank- und Subtabellentechnologie kann die Leistungsengpässe und -belastungen einzelner Maschinen und einzelner Datenbanken wirksam lindern und auch Einschränkungen im Zusammenhang mit E/A, Anzahl der Verbindungen, Hardwareressourcen usw. überwinden.# 🎜🎜##🎜🎜 #Unterdatenbank und Untertabelle können gleichzeitig mit der Master-Slave-Replikation durchgeführt werden, basieren jedoch nicht auf der Master-Slave-Replikation, sondern auf der Master-Slave-Replikation. 🎜🎜 ## 🎜🎜 ## 🎜🎜#server.xml
<user name="root"> <property name="password">123456</property> <property name="schemas">USERDB</property> </user>#🎜 🎜#Schema.xml
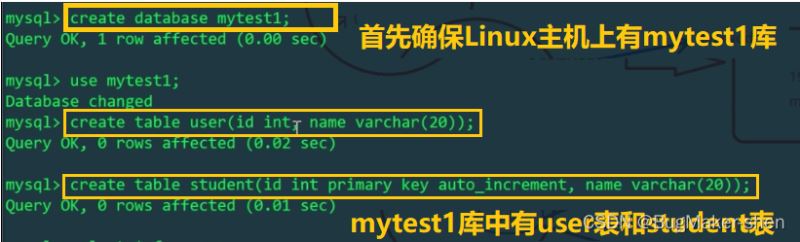
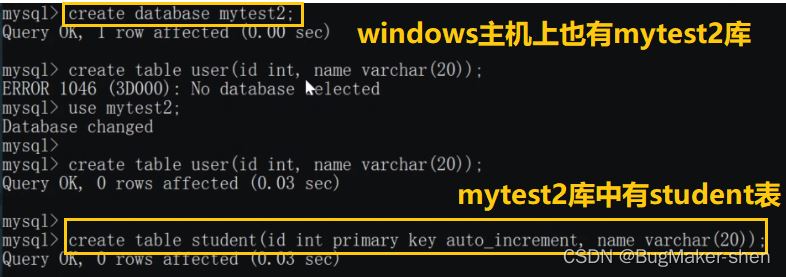
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <!-- 逻辑数据库 --> <schema name="USERDB" checkSQLschema="false" sqlMaxLimit="100"> <table name="user" dataNode="dn1" /> <!-- 这里的user和student都是实际存在的物理表名 --> <table name="student" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2" rule="mod-long"/> </schema> <!-- 存储节点 --> <dataNode name="dn1" dataHost="node1" database="mytest1" /> <dataNode name="dn2" dataHost="node2" database="mytest2" /> <!-- 数据库主机 --> <dataHost name="node1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.131.129" url="192.168.131.129:3306" user="root" password="123456" /> </dataHost> <dataHost name="node2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.0.6" url="192.168.0.6:3306" user="root" password="123456" /> </dataHost> </mycat:schema>#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#Benutzer repräsentiert eine Gewöhnliche Tabelle, direkt auf dem Datenknoten dn1 platziert, auf einer Maschine platziert. Die Tabelle muss nicht geteilt werden Am Ende wird diese Tabelle in zwei Maschinen aufgeteilt und physisch getrennt, aber logischerweise ist es immer noch eine, welche Tabelle hinzugefügt werden soll, welche Abfrage auf beiden Maschinen durchgeführt werden soll und wie diese Vorgänge alle von mycat abgeschlossen werden
Die Aufteilungsregel ist Modulo (mod - long), jede Einfügung verwendet die Anzahl der auf dem ID-Modul (2) vorhandenen Maschinen.
Darüber hinaus ist der folgende Aufteilungsalgorithmus erforderlich muss in Rule.xml konfiguriert werden 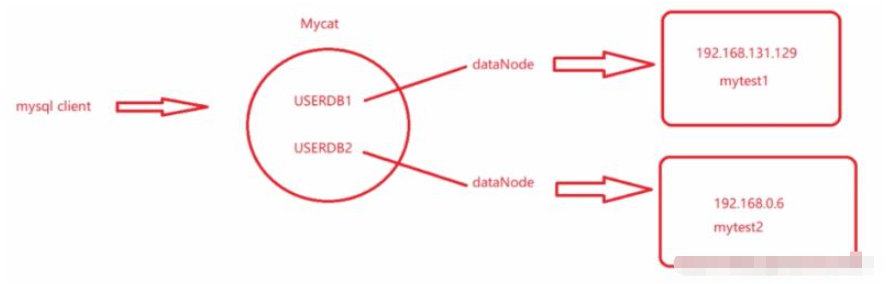
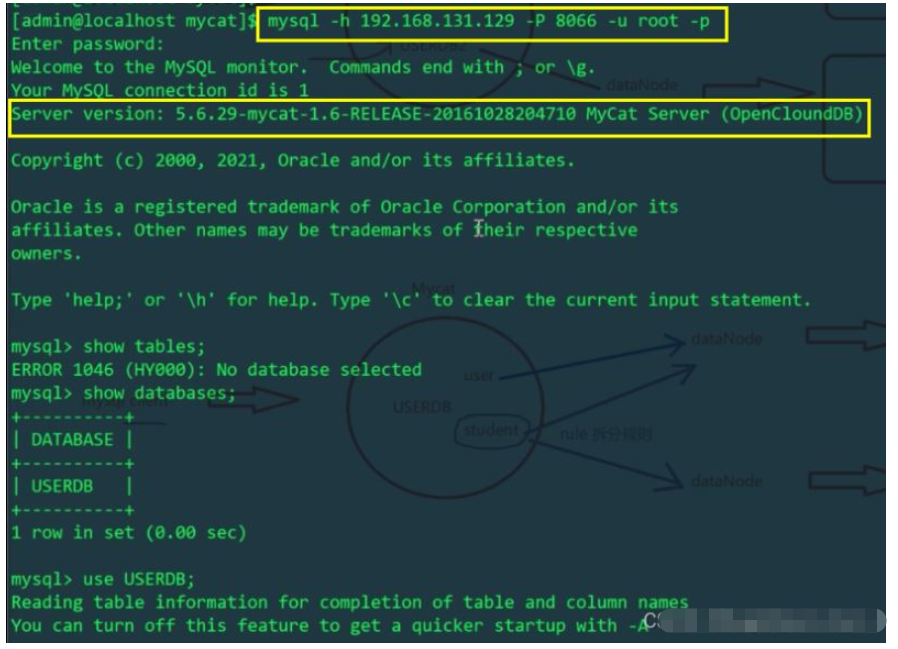
Finden Sie den Algorithmus mod-long, da wir die logische Tabelle „Student“ zwei Hosts separat zuordnen, sodass die Anzahl der geänderten Datenknoten 2 beträgt Windows Der Host

Melden Sie sich bei Port 8066 von mycat an
 Verwenden Sie MyCat, um zwei Daten in die Benutzertabelle einzufügen
Verwenden Sie MyCat, um zwei Daten in die Benutzertabelle einzufügen
 Aufgrund der Konfigurationsdatei schema.xml ist der Benutzer der logischen Tabelle befindet sich nur in der mytest1-Bibliothek des Linux-Hosts. Ja, der von mycat betriebene logische Tabellenbenutzer wirkt sich auf die physische Tabelle auf dem Linux-Host aus, nicht jedoch auf die Tabelle auf dem Windows-Host. Wir überprüfen die Benutzertabellen der Linux- und Windows-Hosts:
Aufgrund der Konfigurationsdatei schema.xml ist der Benutzer der logischen Tabelle befindet sich nur in der mytest1-Bibliothek des Linux-Hosts. Ja, der von mycat betriebene logische Tabellenbenutzer wirkt sich auf die physische Tabelle auf dem Linux-Host aus, nicht jedoch auf die Tabelle auf dem Windows-Host. Wir überprüfen die Benutzertabellen der Linux- und Windows-Hosts:

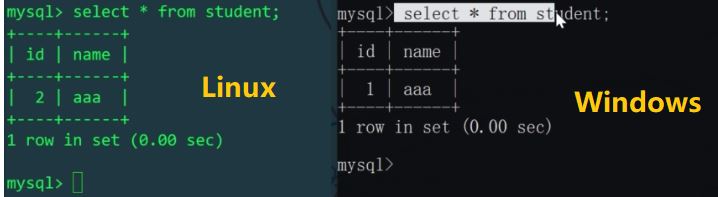
, um zu entscheiden, welche physische Tabelle verwendet werden soll). einfügen). Schauen wir uns die Schülertabellen der Linux- und Windows-Hosts an: 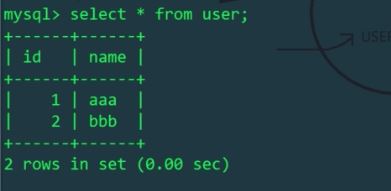


id%机器数
Das obige ist der detaillierte Inhalt vonBeispielanalyse einer MySQL-Unterdatenbank und -Untertabelle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!