
Heim >Datenbank >MySQL-Tutorial >Wozu dienen Indizes in MySQL?
Wozu dienen Indizes in MySQL?

- 王林nach vorne
- 2023-06-03 15:22:171357Durchsuche
Index
1. Vorteile des Index
(1) Verbesserung der Abfrageeffizienz (Reduzierung der E/A-Nutzung)
(2) Reduzierung der CPU-Auslastung
Zum Beispiel Abfragereihenfolge nach Alter desc, da der B+-Indexbaum selbst ist Der Rang ist in Ordnung. Wenn Sie also erneut eine Abfrage durchführen und den Index auslösen, müssen Sie keine erneute Abfrage durchführen.
2. Nachteile des Index
(1) Der Index selbst ist groß und kann im Speicher oder auf der Festplatte gespeichert werden, normalerweise auf der Festplatte.
(2) Indizes werden nicht in allen Situationen verwendet, z. B. ① eine kleine Datenmenge ② sich häufig ändernde Felder ③ selten verwendete Felder
(3) Indizes verringern die Effizienz von Hinzufügungen, Löschungen und Änderungen
3. Indexklassifizierung
(1) Einzelwertindex
(2) Eindeutiger Index
(3) Union-Index
(4) Primärschlüsselindex
Hinweis: Der einzige Unterschied zwischen eindeutigem Index und Primärschlüsselindex: Primärschlüssel Index darf nicht null sein
4. Index erstellen
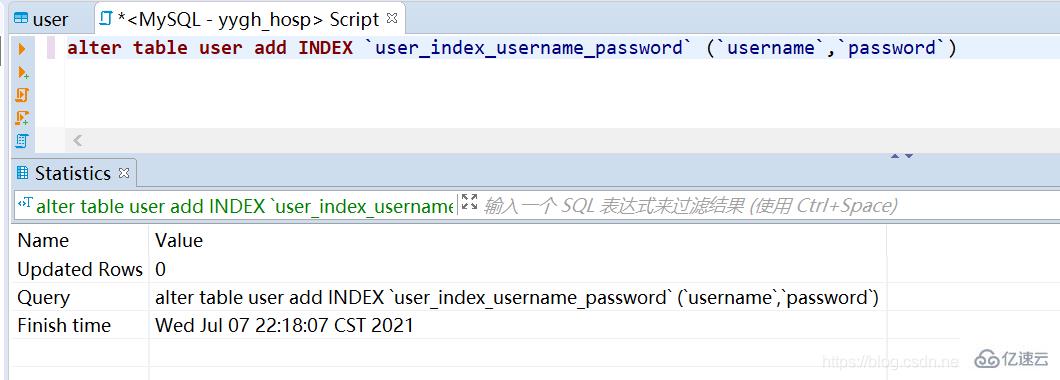 5. MySQL-Index-Prinzip -> B-Tree eignet sich besser für die Implementierung einer externen Speicherindexstruktur. Die InnoDB-Speicher-Engine verwendet B+Tree, um ihre Indexstruktur zu implementieren.
5. MySQL-Index-Prinzip -> B-Tree eignet sich besser für die Implementierung einer externen Speicherindexstruktur. Die InnoDB-Speicher-Engine verwendet B+Tree, um ihre Indexstruktur zu implementieren.
Jeder Knoten im B-Tree-Strukturdiagramm enthält nicht nur den Schlüsselwert der Daten, sondern auch den Datenwert. Der Speicherplatz jeder Seite ist begrenzt. Wenn die Datenmenge groß ist, ist die Anzahl der Schlüssel, die in jedem Knoten gespeichert werden können (d. h. eine Seite), sehr gering zu B- Die Tiefe des Baums ist größer, was die Anzahl der Festplatten-E/As während der Abfrage erhöht und sich dadurch auf die Abfrageeffizienz auswirkt. In B+Tree werden alle Datensatzknoten in der Reihenfolge ihres Schlüsselwerts auf Blattknoten gespeichert. Auf Nicht-Blattknoten werden nur Schlüsselwertinformationen gespeichert Knoten. Reduzieren Sie die Höhe von B+Baum.
B+Tree weist im Vergleich zu B-Tree mehrere Unterschiede auf:
Nicht-Blattknoten speichern nur Schlüsselwertinformationen.
Es gibt einen Linkzeiger zwischen allen Blattknoten.Datensätze werden in Blattknoten gespeichert.
Optimieren Sie den B-Baum im vorherigen Abschnitt. Da die Nicht-Blattknoten von B + Baum nur Schlüsselwertinformationen speichern, wird davon ausgegangen, dass jeder Festplattenblock 4 Schlüsselwerte und Zeigerinformationen speichern kann +Baum. Wie in der folgenden Abbildung gezeigt:
Normalerweise gibt es in B+Baum zwei Kopfzeiger, einer zeigt auf den Wurzelknoten und der andere zeigt auf den Blattknoten mit dem kleinsten Schlüsselwort, und es gibt eine Art der Beziehung zwischen allen Blattknoten (d. h. Datenknoten). Daher können für B+Tree zwei Suchvorgänge durchgeführt werden: einer ist eine Bereichssuche und eine Paging-Suche nach dem Primärschlüssel und der andere ist eine Zufallssuche ausgehend vom Wurzelknoten.
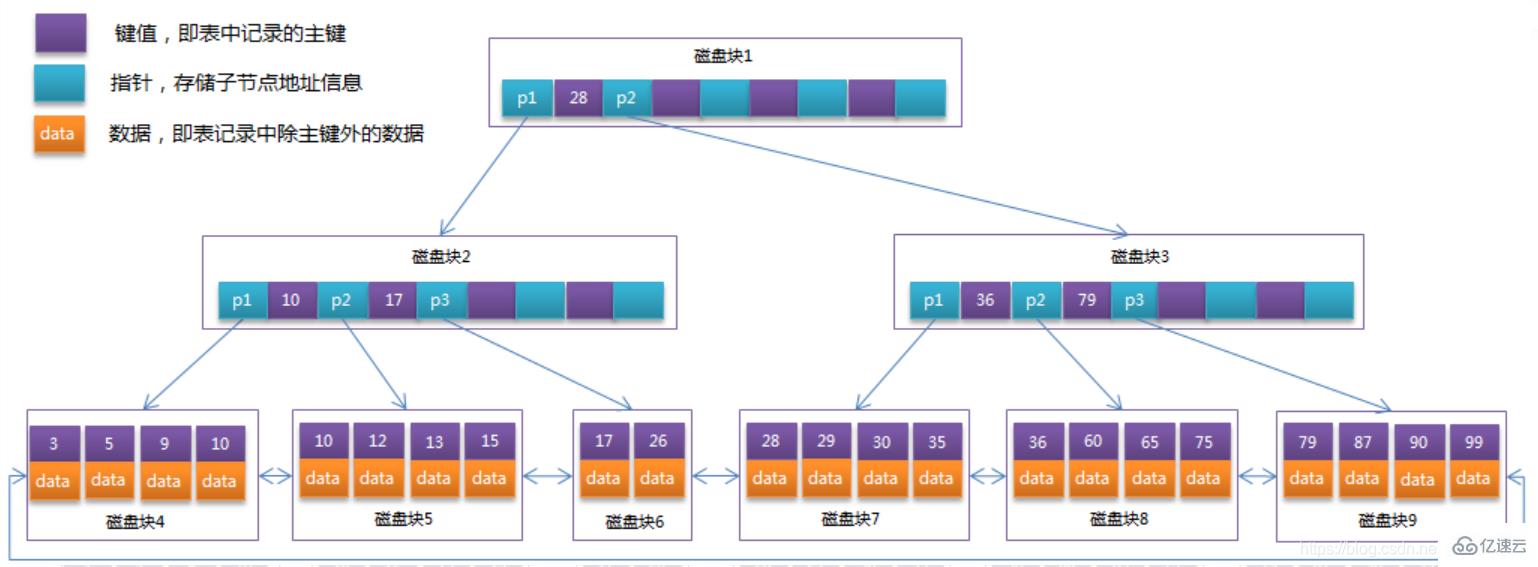 Die Seitengröße in der InnoDB-Speicher-Engine beträgt 16 KB und der Primärschlüsseltyp Die allgemeine Tabelle ist INT (belegt 4 Wörter) oder BIGINT (belegt 8 Bytes). Der Zeigertyp ist im Allgemeinen 4 oder 8 Bytes, was bedeutet, dass eine Seite (ein Knoten in B+Baum) ungefähr 16 KB/(8B+8B) speichert )=1K-Schlüsselwert (da es sich um eine Schätzung handelt, beträgt der Wert von K hier zur Vereinfachung der Berechnung 〖10〗^3). Mit anderen Worten: Ein B+Tree-Index mit einer Tiefe von 3 kann 10^3 * 10^3 * 10^3 = 1 Milliarde Datensätze verwalten.
Die Seitengröße in der InnoDB-Speicher-Engine beträgt 16 KB und der Primärschlüsseltyp Die allgemeine Tabelle ist INT (belegt 4 Wörter) oder BIGINT (belegt 8 Bytes). Der Zeigertyp ist im Allgemeinen 4 oder 8 Bytes, was bedeutet, dass eine Seite (ein Knoten in B+Baum) ungefähr 16 KB/(8B+8B) speichert )=1K-Schlüsselwert (da es sich um eine Schätzung handelt, beträgt der Wert von K hier zur Vereinfachung der Berechnung 〖10〗^3). Mit anderen Worten: Ein B+Tree-Index mit einer Tiefe von 3 kann 10^3 * 10^3 * 10^3 = 1 Milliarde Datensätze verwalten.
In tatsächlichen Situationen ist möglicherweise nicht jeder Knoten vollständig gefüllt, daher beträgt die Höhe von B + Baum in der Datenbank im Allgemeinen 2 bis 4 Schichten. Die InnoDB-Speicher-Engine von MySQL ist so konzipiert, dass der Root-Knoten im Speicher resident ist, was bedeutet, dass nur 1 bis 3 Festplatten-E/A-Vorgänge erforderlich sind, um den Zeilendatensatz eines bestimmten Schlüsselwerts zu finden.
Der B+Tree-Index in der Datenbank kann in Clustered-Index und Sekundärindex unterteilt werden. Das obige B+Tree-Beispieldiagramm ist in der Datenbank als Clustered-Index implementiert. Die Blattknoten im B+Tree des Clustered-Index speichern die Zeilendatensatzdaten der gesamten Tabelle. Der Unterschied zwischen einem Hilfsindex und einem Clustered-Index besteht darin, dass die Blattknoten des Hilfsindex nicht alle Daten des Zeilendatensatzes enthalten, sondern den Clustered-Index-Schlüssel der entsprechenden Zeilendaten, also den Primärschlüssel, speichern. Beim Abfragen von Daten über einen Sekundärindex durchläuft die InnoDB-Speicher-Engine den Sekundärindex, um den Primärschlüssel zu finden, und findet dann über den Primärschlüssel die vollständigen Zeilendatensatzdaten im Clustered-Index.
Das obige ist der detaillierte Inhalt vonWozu dienen Indizes in MySQL?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!