
Heim >Backend-Entwicklung >Python-Tutorial >Welche Methoden gibt es zur Verarbeitung kategorialer Funktionen beim maschinellen Lernen von Python?
Welche Methoden gibt es zur Verarbeitung kategorialer Funktionen beim maschinellen Lernen von Python?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-03 10:45:131669Durchsuche
Kategorische Merkmale beziehen sich auf Merkmale mit Werten, die in eine endliche Menge von Kategorien fallen, wie z. B. Beruf und Blutgruppe. Die ursprüngliche Eingabe erfolgt normalerweise in Form einer Zeichenfolge. Numerische kategoriale Merkmale werden nicht als numerische Merkmale behandelt, was zu Fehlern im trainierten Modell führt.
Label-Codierung
Label-Codierung verwendet ein Wörterbuch, um jede Kategoriebezeichnung einer aufsteigenden Ganzzahl zuzuordnen, d. h. einen Index in einem Instanzarray namens class_ zu generieren.
Der LabelEncoder in Scikit-learn wird zum Codieren kategorialer Merkmalswerte verwendet, also zum Codieren diskontinuierlicher Werte oder Texte. Es umfasst die folgenden gängigen Methoden:
fit(y): fit kann als leeres Wörterbuch betrachtet werden, und y kann als ein Wort betrachtet werden, das im Wörterbuch verankert ist.
fit_transform(y): Dies entspricht der Durchführung einer Anpassung und der anschließenden Transformation, d. h. dem Einfügen von y in das Wörterbuch und der anschließenden Transformation, um den Indexwert zu erhalten.
inverse_transform(y): Erhalten Sie die Originaldaten basierend auf dem Indexwert y.
transform(y): Wandelt y in einen Indexwert um.
from sklearn.preprocessing import LabelEncoder le = LabelEncoder() city_list = ["paris", "paris", "tokyo", "amsterdam"] le.fit(city_list) print(le.classes_) # 输出为:['amsterdam' 'paris' 'tokyo'] city_list_le = le.transform(city_list) # 进行Encode print(city_list_le) # 输出为:[1 1 2 0] city_list_new = le.inverse_transform(city_list_le) # 进行decode print(city_list_new) # 输出为:['paris' 'paris' 'tokyo' 'amsterdam']
Mehrspaltige Datenkodierungsmethode:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
df = pd.DataFrame({
'pets': ['cat', 'dog', 'cat', 'monkey', 'dog', 'dog'],
'owner': ['Champ', 'Ron', 'Brick', 'Champ', 'Veronica', 'Ron'],
'location': ['San_Diego', 'New_York', 'New_York', 'San_Diego', 'San_Diego',
'New_York']
})
d = {}
le = LabelEncoder()
cols_to_encode = ['pets', 'owner', 'location']
for col in cols_to_encode:
df_train[col] = le.fit_transform(df_train[col])
d[col] = le.classes_Factorize() von Pandas kann die Nominaldaten in der Reihe einer Reihe von Zahlen zuordnen, und derselbe Nominaltyp wird derselben Zahl zugeordnet. Die Funktion Factorize gibt ein Tupel zurück, das zwei Elemente enthält. Das erste Element ist ein Array, dessen Elemente Zahlen sind, denen nominale Elemente zugeordnet sind; das zweite Element ist ein Indextyp, bei dem es sich bei allen Elementen um nominale Elemente ohne Duplikate handelt.
import numpy as np import pandas as pd df = pd.DataFrame(['green','bule','red','bule','green'],columns=['color']) pd.factorize(df['color']) #(array([0, 1, 2, 1, 0], dtype=int64),Index(['green', 'bule', 'red'], dtype='object')) pd.factorize(df['color'])[0] #array([0, 1, 2, 1, 0], dtype=int64) pd.factorize(df['color'])[1] #Index(['green', 'bule', 'red'], dtype='object')
Label Encoding wandelt Text nur in numerische Werte um und löst nicht das Problem der Textmerkmale: Alle Beschriftungen werden zu Zahlen, und das Algorithmusmodell berücksichtigt ähnliche Zahlen direkt basierend auf ihrem Abstand, unabhängig von der spezifischen Bedeutung der Beschriftung . Die mit dieser Methode verarbeiteten Daten können auf Algorithmusmodelle angewendet werden, die kategoriale Attribute unterstützen, wie z. B. LightGBM.
Ordinale Kodierung
Ordinale Kodierung ist die einfachste Idee. Für ein Feature mit m Kategorien ordnen wir es entsprechend einer Ganzzahl von [0,m-1] zu. Natürlich eignet sich die ordinale Codierung besser für ordinale Merkmale, das heißt, jedes Merkmal hat eine inhärente Reihenfolge. Beispielsweise können Kategorien wie „Bildung“, „Bachelor“, „Master“ und „Ph.D.“ natürlich als [0,2] codiert werden, da sie von Natur aus eine solche logische Reihenfolge enthalten. Für eine Kategorie wie „Farbe“ ist es jedoch unvernünftig, „Blau“, „Grün“ und „Rot“ jeweils in [0,2] zu kodieren, da wir keinen Grund zu der Annahme haben, dass „Blau“ und „Grün“ eine Lücke bilden zwischen „blau“ und „rot“ hat unterschiedliche Auswirkungen auf Merkmale.
ord_map = {'Gen 1': 1, 'Gen 2': 2, 'Gen 3': 3, 'Gen 4': 4, 'Gen 5': 5, 'Gen 6': 6}
df['GenerationLabel'] = df['Generation'].map(gord_map)One-Hot-Codierung
In tatsächlichen Anwendungsaufgaben für maschinelles Lernen sind Merkmale manchmal nicht immer kontinuierliche Werte, sondern können einige kategorische Werte sein. Beispielsweise kann das Geschlecht in männlich und weiblich unterteilt werden. Bei maschinellen Lernaufgaben müssen wir solche Funktionen normalerweise digitalisieren. Beispielsweise gibt es die folgenden drei Feature-Attribute:
Geschlecht: [„männlich“, „weiblich“]
Region: [ " Europa“, „USA“, „Asien“]
Browser: [„Firefox“, „Chrome“, „Safari“, „Internet Explorer“]
Für ein bestimmtes Beispiel, z. B. [„männlich““ „, „US“, „Internet Explorer“], wir müssen die Merkmale dieses Klassifizierungswerts digitalisieren. Als direkteste Methode können wir Serialisierung verwenden: [0,1,3]. Obwohl die Daten in numerische Form umgewandelt werden, kann unser Klassifikator die oben genannten Daten nicht direkt verwenden. Weil Klassifikatoren häufig standardmäßig darauf achten, dass die Daten kontinuierlich und geordnet sind. Nach obiger Darstellung sind die Zahlen nicht geordnet, sondern zufällig vergeben. Eine solche Merkmalsverarbeitung kann nicht direkt in Algorithmen für maschinelles Lernen integriert werden.
Um das oben genannte Problem zu lösen, ist die Verwendung von One-Hot Encoding eine der möglichen Lösungen. One-Hot-Codierung, auch bekannt als Ein-Bit-effiziente Codierung. Die Methode besteht darin, ein N-Bit-Statusregister zu verwenden, um N Zustände zu kodieren. Jeder Zustand hat sein eigenes unabhängiges Registerbit, und zu jedem Zeitpunkt ist nur eines davon gültig. Die One-Hot-Codierung wandelt jedes Merkmal in m binäre Merkmale um, wobei m die Anzahl der möglichen Werte für das Merkmal ist. Außerdem schließen sich diese Funktionen gegenseitig aus und es ist jeweils nur eine aktiv. Daher werden die Daten spärlich.
Für das obige Problem ist das Geschlechtsattribut zweidimensional und der Browser vierdimensional. Auf diese Weise können wir die One-Hot-Codierung verwenden, um das obige Beispiel zu codieren „, „US“, „Internet Explorer“]-Kodierung, männlich entspricht [1, 0], ähnlich entspricht US [0, 1, 0] und Internet Explorer entspricht [0, 0, 0, 1]. Das vollständige Ergebnis der Feature-Digitalisierung ist: [1,0,0,1,0,0,0,0,1].
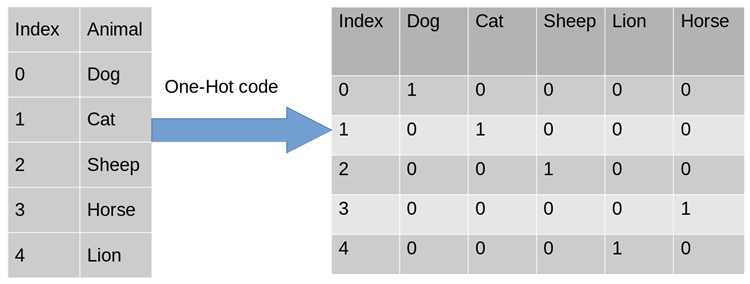
Warum kann ich One-Hot Encoding verwenden?
使用one-hot编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点。在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,也是基于的欧式空间。
使用One-Hot编码对离散型特征进行处理可以使得特征之间的距离计算更加准确。比如,有一个离散型特征,代表工作类型,该离散型特征,共有三个取值,不使用one-hot编码,计算出来的特征的距离是不合理。那如果使用one-hot编码,显得更合理。
独热编码优缺点
优点:独热编码解决了分类器不好处理属性数据的问题,在一定程度上也起到了扩充特征的作用。它的值只有0和1,不同的类型存储在垂直的空间。
缺点:当类别的数量很多时,特征空间会变得非常大。在这种情况下,一般可以用PCA(主成分分析)来减少维度。在实际应用中,One-Hot Encoding与PCA结合的方法也非常实用。
One-Hot Encoding的使用场景
独热编码用来解决类别型数据的离散值问题。将离散型特征进行one-hot编码的作用,是为了让距离计算更合理,但如果特征是离散的,并且不用one-hot编码就可以很合理的计算出距离,那么就没必要进行one-hot编码,比如,该离散特征共有1000个取值,我们分成两组,分别是400和600,两个小组之间的距离有合适的定义,组内的距离也有合适的定义,那就没必要用one-hot 编码。
树结构方法,如随机森林、Bagging和Boosting等,在特征处理方面不需要进行标准化操作。对于决策树来说,one-hot的本质是增加树的深度,决策树是没有特征大小的概念的,只有特征处于他分布的哪一部分的概念。
基于Scikit-learn 的one hot encoding
LabelBinarizer:将对应的数据转换为二进制型,类似于onehot编码,这里有几点不同:
可以处理数值型和类别型数据
输入必须为1D数组
可以自己设置正类和父类的表示方式
from sklearn.preprocessing import LabelBinarizer lb = LabelBinarizer() city_list = ["paris", "paris", "tokyo", "amsterdam"] lb.fit(city_list) print(lb.classes_) # 输出为:['amsterdam' 'paris' 'tokyo'] city_list_le = lb.transform(city_list) # 进行Encode print(city_list_le) # 输出为: # [[0 1 0] # [0 1 0] # [0 0 1] # [1 0 0]] city_list_new = lb.inverse_transform(city_list_le) # 进行decode print(city_list_new) # 输出为:['paris' 'paris' 'tokyo' 'amsterdam']
OneHotEncoder只能对数值型数据进行处理,需要先将文本转化为数值(Label encoding)后才能使用,只接受2D数组:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
def LabelOneHotEncoder(data, categorical_features):
d_num = np.array([])
for f in data.columns:
if f in categorical_features:
le, ohe = LabelEncoder(), OneHotEncoder()
data[f] = le.fit_transform(data[f])
if len(d_num) == 0:
d_num = np.array(ohe.fit_transform(data[[f]]))
else:
d_num = np.hstack((d_num, ohe.fit_transform(data[[f]]).A))
else:
if len(d_num) == 0:
d_num = np.array(data[[f]])
else:
d_num = np.hstack((d_num, data[[f]]))
return d_num
df = pd.DataFrame([
['green', 'Chevrolet', 2017],
['blue', 'BMW', 2015],
['yellow', 'Lexus', 2018],
])
df.columns = ['color', 'make', 'year']
df_new = LabelOneHotEncoder(df, ['color', 'make', 'year'])基于Pandas的one hot encoding
其实如果我们跳出 scikit-learn, 在 pandas 中可以很好地解决这个问题,用 pandas 自带的get_dummies函数即可
import pandas as pd
df = pd.DataFrame([
['green', 'Chevrolet', 2017],
['blue', 'BMW', 2015],
['yellow', 'Lexus', 2018],
])
df.columns = ['color', 'make', 'year']
df_processed = pd.get_dummies(df, prefix_sep="_", columns=df.columns[:-1])
print(df_processed)get_dummies的优势在于:
本身就是 pandas 的模块,所以对 DataFrame 类型兼容很好
不管你列是数值型还是字符串型,都可以进行二值化编码
能够根据指令,自动生成二值化编码后的变量名
get_dummies虽然有这么多优点,但毕竟不是 sklearn 里的transformer类型,所以得到的结果得手动输入到 sklearn 里的相应模块,也无法像 sklearn 的transformer一样可以输入到pipeline中进行流程化地机器学习过程。
频数编码(Frequency Encoding/Count Encoding)
将类别特征替换为训练集中的计数(一般是根据训练集来进行计数,属于统计编码的一种,统计编码,就是用类别的统计特征来代替原始类别,比如类别A在训练集中出现了100次则编码为100)。这个方法对离群值很敏感,所以结果可以归一化或者转换一下(例如使用对数变换)。未知类别可以替换为1。
频数编码使用频次替换类别。有些变量的频次可能是一样的,这将导致碰撞。尽管可能性不是非常大,没法说这是否会导致模型退化,不过原则上我们不希望出现这种情况。
import pandas as pd
data_count = data.groupby('城市')['城市'].agg({'频数':'size'}).reset_index()
data = pd.merge(data, data_count, on = '城市', how = 'left')目标编码(Target Encoding/Mean Encoding)
目标编码(target encoding),亦称均值编码(mean encoding)、似然编码(likelihood encoding)、效应编码(impact encoding),是一种能够对高基数(high cardinality)自变量进行编码的方法 (Micci-Barreca 2001) 。
如果某一个特征是定性的(categorical),而这个特征的可能值非常多(高基数),那么目标编码(Target encoding)是一种高效的编码方式。在实际应用中,这类特征工程能极大提升模型的性能。
一般情况下,针对定性特征,我们只需要使用sklearn的OneHotEncoder或LabelEncoder进行编码。
LabelEncoder kann unregelmäßige Feature-Spalten empfangen und in ganzzahlige Werte von 0 bis n-1 umwandeln (vorausgesetzt, es gibt insgesamt n verschiedene Kategorien); OneHotEncoder kann durch Dummy-Codierung eine m*n-sparse-Matrix erstellen (vorausgesetzt, es gibt m Zeilen). (Anzahl der Daten insgesamt, ob das spezifische Ausgabematrixformat spärlich ist, kann durch den Sparse-Parameter gesteuert werden).
„Kardinalität“ eines qualitativen Merkmals bezieht sich auf die Gesamtzahl der unterschiedlichen möglichen Werte, die das Merkmal annehmen kann. Angesichts qualitativer Merkmale mit hoher Kardinalität erzielen diese Datenvorverarbeitungsmethoden häufig keine zufriedenstellenden Ergebnisse.
Beispiele für qualitative Merkmale mit hoher Kardinalität: IP-Adresse, E-Mail-Domänenname, Stadtname, Privatadresse, Straße, Produktnummer.
Hauptgrund:
LabelEncoder kodiert qualitative Merkmale mit hoher Kardinalität. Obwohl nur eine Spalte erforderlich ist, hat jede natürliche Zahl eine unterschiedliche Bedeutung und ist für y linear untrennbar. Die Verwendung eines einfachen Modells ist anfällig für eine Unteranpassung und kann die Unterschiede zwischen verschiedenen Kategorien nicht vollständig erfassen. Die Verwendung eines komplexen Modells ist an anderen Stellen anfällig für eine Überanpassung.
OneHotEncoder codiert qualitative Merkmale mit hoher Kardinalität, die unweigerlich zu spärlichen Matrizen mit Zehntausenden von Spalten führen, was leicht viel Speicher und Trainingszeit verbraucht, es sei denn, der Algorithmus selbst ist optimiert (z. B. SVM).
Wenn die Kardinalität eines bestimmten kategorialen Merkmals relativ gering ist (Merkmale mit geringer Kardinalität), d. Die Hot-Encoding-Methode wird im Allgemeinen verwendet, um die Merkmale in numerische Werte umzuwandeln. Die One-Hot-Codierung kann während der Datenvorverarbeitung oder während des Modelltrainings durchgeführt werden. Aus Sicht der Trainingszeit ist die letztgenannte Methode auch für kategoriale Merkmale mit geringer Kardinalität effizienter.
Offensichtlich wird diese Codierungsmethode neben Funktionen mit hoher Kardinalität, wie z. B. der Benutzer-ID, eine große Anzahl neuer Funktionen generieren, was zu einer Dimensionalitätskatastrophe führt. Eine Kompromissmethode besteht darin, die Kategorien in eine begrenzte Anzahl von Gruppen zu gruppieren und dann eine One-Hot-Codierung durchzuführen. Eine häufig verwendete Methode ist die Gruppierung nach Zielvariablenstatistiken (Zielstatistiken, im Folgenden als TS bezeichnet), mit denen der erwartete Wert der Zielvariablen für jede Kategorie geschätzt wird. Manche Leute verwenden TS sogar direkt als neue numerische Variable, um die ursprüngliche kategoriale Variable zu ersetzen. Wichtig ist, dass wir durch Festlegen des Schwellenwerts für numerische TS-Merkmale auf der Grundlage des logarithmischen Verlusts, des Gini-Koeffizienten oder des mittleren quadratischen Fehlers die optimale unter allen möglichen Unterteilungen erhalten können, die die Kategorie für den Trainingssatz in zwei Teile teilen. In LightGBM werden kategoriale Merkmale bei jedem Schritt der Gradientenverstärkung durch Gradient Statistics (GS) dargestellt. Obwohl sie wichtige Informationen für den Baumaufbau liefert, hat diese Methode die folgenden zwei Nachteile:
Erhöht die Berechnungszeit, da GS für jedes Kategoriemerkmal und in jedem Schritt der Iteration berechnet werden muss
Erhöhter Speicherbedarf . Für eine kategoriale Variable ist es notwendig, die Kategorie jedes Knotens jedes Mal zu speichern.
Um diese Mängel zu beheben, klassifiziert LightGBM alle Long-Tail-Kategorien in einer Kategorie Es wird behauptet, dass diese Methode bei der Verarbeitung von Merkmalen mit hoher Kardinalität viel besser ist als die One-Hot-Codierung. Mithilfe von TS-Funktionen wird nur eine Zahl pro Kategorie berechnet und gespeichert. Daher ist die Verwendung von TS als neues numerisches Merkmal zur Verarbeitung kategorialer Merkmale am effektivsten und kann den Informationsverlust minimieren. TS wird auch häufig bei Klickvorhersageaufgaben verwendet. Zu den Kategoriefunktionen in diesem Szenario gehören Benutzer, Regionen, Anzeigen, Anzeigenherausgeber usw. In der folgenden Diskussion konzentrieren wir uns auf TS und lassen One-Hot-Codierung und GS vorerst beiseite.
Das Folgende ist die Berechnungsformel:
wobei n die Anzahl der Werte für ein bestimmtes Merkmal darstellt,
die Anzahl positiver Beschriftungen für einen bestimmten Merkmalswert darstellt, mdl ein Mindestschwellenwert ist und die Anzahl Anzahl der Stichproben ist kleiner als Die Merkmalskategorie dieses Werts wird ignoriert und die Priorität ist der Mittelwert des Labels. Beachten Sie, dass, wenn Sie mit einem Regressionsproblem zu tun haben, dieses in den Durchschnitt/Maximum des Beschriftungswerts unter der entsprechenden Funktion verarbeitet werden kann. Für k Klassifizierungsprobleme werden entsprechende k-1 Merkmale generiert.
Diese Methode ist auch anfällig für Überanpassung. Die folgenden Methoden werden verwendet, um eine Überanpassung zu verhindern:
Erhöhen Sie die Größe des regulären Termes a
Fügen Sie Rauschen zu dieser Spalte des Trainingssatzes hinzu
Verwenden Sie Crossover. Stellen Sie sicher, dass
die Zielcodierung eine überwachte Codierungsmethode ist. Bei richtiger Verwendung kann sie die Genauigkeit des Vorhersagemodells effektiv verbessern (Pargent, Bischl und Thomas 2019). Der Codierungsprozess wird reguliert, um Überanpassungsprobleme zu vermeiden.
Zum Beispiel entspricht Kategorie A 200 Tags 1, 300 Tags 2 und 500 Tags 3, die wie folgt codiert werden können: 2/10, 3/10, 3/6. Das Wichtigste in der Mitte ist, wie man eine Überanpassung vermeidet (die ursprüngliche Zielkodierung kodiert direkt alle Daten und Beschriftungen des Trainingssatzes, was dazu führt, dass die erhaltenen Kodierungsergebnisse zu stark vom Trainingssatz abhängen. Eine gängige Lösung ist die Verwendung von 2). Ebenen der Kreuzvalidierung ermitteln den Zielmittelwert. Die Idee ist wie folgt:
把train data划分为20-folds (举例:infold: fold #2-20, out of fold: fold #1)
计算 10-folds的 inner out of folds值 (举例:使用inner_infold #2-10 的target的均值,来作为inner_oof #1的预测值)
对10个inner out of folds 值取平均,得到 inner_oof_mean
将每一个 infold (fold #2-20) 再次划分为10-folds (举例:inner_infold: fold #2-10, Inner_oof: fold #1)
计算oof_mean (举例:使用 infold #2-20的inner_oof_mean 来预测 out of fold #1的oof_mean
将train data 的 oof_mean 映射到test data完成编码
比如划分为10折,每次对9折进行标签编码然后用得到的标签编码模型预测第10折的特征得到结果,其实就是常说的均值编码。
目标编码尝试对分类特征中每个级别的目标总体平均值进行测量。当数据量较少时,每个级别的数据量减少意味着估计的均值与真实均值之间的差距增加,方差也会更大。
from category_encoders import TargetEncoder import pandas as pd from sklearn.datasets import load_boston # prepare some data bunch = load_boston() y_train = bunch.target[0:250] y_test = bunch.target[250:506] X_train = pd.DataFrame(bunch.data[0:250], columns=bunch.feature_names) X_test = pd.DataFrame(bunch.data[250:506], columns=bunch.feature_names) # use target encoding to encode two categorical features enc = TargetEncoder(cols=['CHAS', 'RAD']) # transform the datasets training_numeric_dataset = enc.fit_transform(X_train, y_train) testing_numeric_dataset = enc.transform(X_test)
Beta Target Encoding
Kaggle竞赛Avito Demand Prediction Challenge 第14名的solution分享:14th Place Solution: The Almost Golden Defenders。和target encoding 一样,beta target encoding 也采用 target mean value (among each category) 来给categorical feature做编码。不同之处在于,为了进一步减少target variable leak,beta target encoding发生在在5-fold CV内部,而不是在5-fold CV之前:
把train data划分为5-folds (5-fold cross validation)
target encoding based on infold data
train model
get out of fold prediction
同时beta target encoding 加入了smoothing term,用 bayesian mean 来代替mean。Bayesian mean (Bayesian average) 的思路:某一个category如果数据量较少( 另外,对于target encoding和beta target encoding,不一定要用target mean (or bayesian mean),也可以用其他的统计值包括 medium, frqequency, mode, variance, skewness, and kurtosis — 或任何与target有correlation的统计值。 M-Estimate Encoding 相当于 一个简化版的Target Encoding: 其中????+代表所有正Label的个数,m是一个调参的参数,m越大过拟合的程度就会越小,同样的在处理连续值时????+可以换成label的求和,????+换成所有label的求和。 一种基于目标的算法是 James-Stein 编码。算法的思想很简单,对于特征的每个取值 k 可以根据下面的公式获得: 其中B由以下公式估计: 但是它有一个要求是target必须符合正态分布,这对于分类问题是不可能的,因此可以把y先转化成概率的形式。在实际操作中,可以使用网格搜索方法来选择一个较优的B值。 Weight Of Evidence 同样是基于target的方法。 使用WOE作为变量,第i类的WOE等于: WOE特别合适逻辑回归,因为Logit=log(odds)。WOE编码的变量被编码为统一的维度(是一个被标准化过的值),变量之间直接比较系数即可。 这个方法类似于SUM的方法,只是在计算训练集每个样本的特征值转换时都要把该样本排除(消除特征某取值下样本太少导致的严重过拟合),在计算测试集每个样本特征值转换时与SUM相同。可见以下公式: 使用二进制编码对每一类进行编号,使用具有log2N维的向量对N类进行编码。以 (0,0) 为例,它表示第一类,而 (0,1) 表示第二类,(1,0) 表示第三类,(1,1) 则表示第四类 类似于One-hot encoding,但是通过hash函数映射到一个低维空间,并且使得两个类对应向量的空间距离基本保持一致。使用低维空间来降低了表示向量的维度。 特征哈希可能会导致要素之间发生冲突。一个哈希编码的好处是不需要指定或维护原变量与新变量之间的映射关系。因此,哈希编码器的大小及复杂程度不随数据类别的增多而增多。 和WOE相似,只是去掉了log,即: führt eine Summenkodierung für ein bestimmtes Merkmal durch, indem er die Differenz zwischen dem Mittelwert des Etiketts (oder anderen verwandten Variablen) unter dem Wert des Merkmals und dem Mittelwert des Gesamtetiketts vergleicht . um Funktionen zu kodieren. Wenn die Details nicht gut gemacht sind, ist diese Methode sehr anfällig für Überanpassungen und muss daher mit der Methode zum Auslassen eines Auslassens oder der fünffachen Kreuzvalidierung kombiniert werden, um Merkmale zu codieren. Es gibt auch Methoden zum Hinzufügen eines Strafterms basierend auf der Varianz, um eine Überanpassung zu verhindern. Helmert-Kodierung wird häufig in der Ökonometrie verwendet. Nach der Helmert-Codierung (jeder Wert im kategorialen Merkmal entspricht einer Zeile in der Helmert-Matrix) können die codierten Variablenkoeffizienten im linearen Modell den Mittelwert der abhängigen Variablen bei einem bestimmten Kategoriewert der Kategorievariablen widerspiegeln der Mittelwert der abhängigen Variablen angesichts der Werte für die anderen Kategorien in dieser Kategorie. Helm-Codierung ist nach One-Hot-Codierung und Sum-Encoder die am weitesten verbreitete Codierungsmethode. Im Gegensatz zum Sum-Encoder vergleicht sie den Mittelwert der entsprechenden Bezeichnung (oder anderer verwandter Variablen) unter einem bestimmten Merkmalswert mit der Differenz zwischen Mittelwert seiner vorherigen Merkmale und nicht der Mittelwert aller Merkmale. Diese Funktion ist auch anfällig für Überanpassung. Für kategoriale Variablen, deren Anzahl möglicher Werte größer als das One-Hot-Maximum ist, verwendet CatBoost eine sehr effektive Codierungsmethode, die der Mittelwertcodierung ähnelt, aber eine Überanpassung reduzieren kann. Die spezifische Implementierungsmethode lautet wie folgt: Sortieren Sie den Eingabestichprobensatz zufällig und generieren Sie mehrere Gruppen zufälliger Anordnungen. Konvertieren Sie Gleitkomma- oder Attributwert-Tags in Ganzzahlen. Konvertieren Sie alle Ergebnisse der Klassifizierungsmerkmalswerte gemäß der folgenden Formel in numerische Ergebnisse. wobei CountInClass angibt, wie viele Proben im aktuellen Klassifizierungsmerkmalswert einen Markierungswert von 1 haben; Prior ist der Anfangswert des Moleküls, der auf der Grundlage der Anfangsparameter bestimmt wird. TotalCount stellt die Anzahl aller Stichproben mit demselben Klassifizierungsmerkmalswert wie die aktuelle Stichprobe dar, einschließlich der aktuellen Stichprobe selbst. Zusammenfassung der CatBoost-Verarbeitung Kategorische Funktionen: Zunächst berechnen sie Statistiken für einige Daten. Berechnen Sie die Häufigkeit des Auftretens einer Kategorie, fügen Sie Hyperparameter hinzu und generieren Sie neue numerische Merkmale. Diese Strategie erfordert, dass Daten mit derselben Bezeichnung nicht zusammen angeordnet werden können (d. h. zuerst alle Nullen und dann alle Einsen) und der Datensatz vor dem Training verschlüsselt werden muss. Zweitens: Verwenden Sie unterschiedliche Permutationen der Daten (eigentlich 4). Vor dem Bau des Baumes wird jede Runde gewürfelt, um zu entscheiden, welche Anordnung zum Bau des Baumes verwendet werden soll. Der dritte Punkt besteht darin, darüber nachzudenken, verschiedene Kombinationen kategorialer Merkmale auszuprobieren. Beispielsweise kann die Kombination von Farbe und Typ ein Merkmal bilden, das dem eines blauen Hundes ähnelt. Wenn die Anzahl der kategorialen Merkmale, die kombiniert werden müssen, zunimmt, berücksichtigt Catboost nur einige Kombinationen. Bei der Auswahl des ersten Knotens wird nur ein Merkmal, z. B. A, berücksichtigt. Berücksichtigen Sie beim Generieren des zweiten Knotens die Kombination von A und einem beliebigen kategorialen Merkmal und wählen Sie das beste aus. Auf diese Weise wird ein Greedy-Algorithmus zur Generierung von Kombinationen verwendet. Viertens wird nicht empfohlen, One-Hot-Vektoren selbst zu generieren, es sei denn, die Dimension ist sehr klein. Überlassen Sie dies am besten dem Algorithmus. # train -> training dataframe
# test -> test dataframe
# N_min -> smoothing term, minimum sample size, if sample size is less than N_min, add up to N_min
# target_col -> target column
# cat_cols -> categorical colums
# Step 1: fill NA in train and test dataframe
# Step 2: 5-fold CV (beta target encoding within each fold)
kf = KFold(n_splits=5, shuffle=True, random_state=0)
for i, (dev_index, val_index) in enumerate(kf.split(train.index.values)):
# split data into dev set and validation set
dev = train.loc[dev_index].reset_index(drop=True)
val = train.loc[val_index].reset_index(drop=True)
feature_cols = []
for var_name in cat_cols:
feature_name = f'{var_name}_mean'
feature_cols.append(feature_name)
prior_mean = np.mean(dev[target_col])
stats = dev[[target_col, var_name]].groupby(var_name).agg(['sum', 'count'])[target_col].reset_index()
### beta target encoding by Bayesian average for dev set
df_stats = pd.merge(dev[[var_name]], stats, how='left')
df_stats['sum'].fillna(value = prior_mean, inplace = True)
df_stats['count'].fillna(value = 1.0, inplace = True)
N_prior = np.maximum(N_min - df_stats['count'].values, 0) # prior parameters
dev[feature_name] = (prior_mean * N_prior + df_stats['sum']) / (N_prior + df_stats['count']) # Bayesian mean
### beta target encoding by Bayesian average for val set
df_stats = pd.merge(val[[var_name]], stats, how='left')
df_stats['sum'].fillna(value = prior_mean, inplace = True)
df_stats['count'].fillna(value = 1.0, inplace = True)
N_prior = np.maximum(N_min - df_stats['count'].values, 0) # prior parameters
val[feature_name] = (prior_mean * N_prior + df_stats['sum']) / (N_prior + df_stats['count']) # Bayesian mean
### beta target encoding by Bayesian average for test set
df_stats = pd.merge(test[[var_name]], stats, how='left')
df_stats['sum'].fillna(value = prior_mean, inplace = True)
df_stats['count'].fillna(value = 1.0, inplace = True)
N_prior = np.maximum(N_min - df_stats['count'].values, 0) # prior parameters
test[feature_name] = (prior_mean * N_prior + df_stats['sum']) / (N_prior + df_stats['count']) # Bayesian mean
# Bayesian mean is equivalent to adding N_prior data points of value prior_mean to the data set.
del df_stats, stats
# Step 3: train model (K-fold CV), get oof predictioM-Estimate Encoding
James-Stein Encoding
Weight of Evidence Encoder
Leave-one-out Encoder (LOO or LOOE)
Binary Encoding
Hashing Encoding
Probability Ratio Encoding
Summenkodierer (Abweichungskodierer, Effektkodierer)
Helmert-Kodierung
CatBoost-Codierung
Das obige ist der detaillierte Inhalt vonWelche Methoden gibt es zur Verarbeitung kategorialer Funktionen beim maschinellen Lernen von Python?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!