
Heim >Datenbank >MySQL-Tutorial >Wie MySQL das InnoDB-Zeilenformat anhand von Binärinhalten erkennt
Wie MySQL das InnoDB-Zeilenformat anhand von Binärinhalten erkennt

- 王林nach vorne
- 2023-06-03 09:55:281331Durchsuche

InnoDB ist eine Speicher-Engine, die Daten in Tabellen auf der Festplatte speichern kann, sodass unsere Daten auch dann erhalten bleiben, wenn der Server nach einem Neustart heruntergefahren wird. Der eigentliche Prozess der Datenverarbeitung findet im Speicher statt, daher müssen die Daten auf der Festplatte in den Speicher geladen werden. Wenn eine Schreib- oder Änderungsanforderung verarbeitet wird, muss auch der Inhalt im Speicher auf der Festplatte aktualisiert werden. Und wir wissen, dass die Geschwindigkeit beim Lesen und Schreiben auf die Festplatte sehr langsam ist, was sich um mehrere Größenordnungen vom Lesen und Schreiben im Speicher unterscheidet. Wenn wir also bestimmte Datensätze aus der Tabelle abrufen möchten, muss die InnoDB-Speicher-Engine lesen die Datensätze einzeln von der Festplatte löschen?
Die von InnoDB verwendete Methode besteht darin, die Daten in mehrere Seiten aufzuteilen und Seiten als grundlegende Interaktionseinheit zwischen Festplatte und Speicher zu verwenden. Die Größe einer Seite in InnoDB beträgt im Allgemeinen 16 KB. Das heißt, unter normalen Umständen werden jeweils mindestens 16 KB Inhalt von der Festplatte in den Speicher gelesen und jeweils mindestens 16 KB des Speicherinhalts auf der Festplatte aktualisiert.
mysql> show variables like '%innodb_page_size%'; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | innodb_page_size | 16384 | +------------------+-------+ 1 row in set (0.00 sec)
Wir fügen Daten normalerweise in Datensatzeinheiten in Tabellen ein, und die Art und Weise, wie diese Datensätze auf der Festplatte gespeichert werden, wird auch Zeilenformat oder Datensatzformat genannt. Die InnoDB-Speicher-Engine hat vier verschiedene Arten von Zeilenformaten entwickelt, nämlich kompakte, redundante, dynamische und komprimierte Zeilenformate.
Klassifizierung und Einführung von Zeilendatensatzformaten
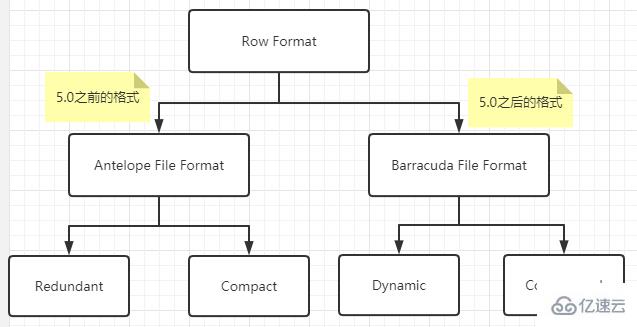
Da es in frühen InnoDB-Versionen nur ein Dateiformat gab, war es nicht erforderlich, dieses Dateiformat zu benennen. Um neue Funktionen und Inkompatibilität mit früheren Versionen zu unterstützen, hat die InnoDB-Engine ein neues Dateiformat entwickelt. Um die Systemkompatibilität in Upgrade- und Downgrade-Situationen sowie bei der Ausführung verschiedener MySQL-Versionen zu verwalten, begann InnoDB mit der Verwendung eines benannten Dateiformats.
In msyql 5.7.9 und späteren Versionen wird das Standardzeilenformat durch die Variable innodb_default_row_format bestimmt und ihr Standardwert ist dynamisch:
mysql> show variables like "innodb_file_format"; +--------------------+-----------+ | Variable_name | Value | +--------------------+-----------+ | innodb_file_format | Barracuda | +--------------------+-----------+ 1 row in set (0.01 sec) mysql> show variables like "innodb_default_row_format"; +---------------------------+---------+ | Variable_name | Value | +---------------------------+---------+ | innodb_default_row_format | dynamic | +---------------------------+---------+ 1 row in set (0.00 sec)
Zeigen Sie das von der aktuellen Tabelle verwendete Zeilenformat an:
mysql> show table status like 'dept_emp'\G*************************** 1. row ***************************
Name: dept_emp Engine: InnoDB
Version: 10
Row_format: Dynamic Rows: 331570
Avg_row_length: 36
Data_length: 12075008Max_data_length: 0
Index_length: 5783552
Data_free: 0
Auto_increment: NULL
Create_time: 2021-08-11 09:04:36
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options: Comment:1 row in set (0.00 sec)Geben Sie an Zeilenformat der Tabelle:
CREATE TABLE 表名(列的信息) ROW_FORMAT=行格式名称ALTER TABLE 表名 ROW_FORMAT=行格式名称;
Wenn Sie den Zeilenmodus einer vorhandenen Tabelle auf komprimiert oder dynamisch ändern möchten, müssen Sie zuerst das Dateiformat auf Barracuda einstellen: set global innodb_file_format=Barracuda;, und verwenden Sie dann ALTER TABLE Tabellenname ROW_FORMAT=COMPRESSED; um die Änderung wirksam zu machen.
Zeilenformat
KOMPAKT
Feldliste mit variabler Länge
MySQL unterstützt einige Datentypen mit variabler Länge, wie z. B. VARCHAR(M), VARBINARY(M), verschiedene TEXT-Typen, verschiedene BLOB-Typen und Spalten mit Diese Datentypen können auch als Felder mit variabler Länge bezeichnet werden. Die Anzahl der in einem Feld mit variabler Länge gespeicherten Datenbytes ist nicht festgelegt. Wenn wir also echte Daten speichern, müssen wir auch die Anzahl der von diesen Daten belegten Bytes speichern. aufstehen. Wenn die maximal zulässige Anzahl von Bytes, die im Variablenfeld gespeichert werden dürfen (M × W), 255 Bytes überschreitet und die tatsächliche Anzahl der gespeicherten Bytes (L) 127 Bytes überschreitet, verwenden Sie 2 Bytes zum Aufzeichnen, andernfalls verwenden Sie 1 Bytes zum Aufzeichnen.
Frage 1: Warum also 128 als Trennlinie verwenden? Ein Byte kann bis zu 255 darstellen, aber als MySQL die Längendarstellung entwarf, wurde zur Unterscheidung, ob es sich um ein Byte handelt, das die Länge darstellt, festgelegt, dass, wenn das höchste Bit 1 ist, zwei Bytes die Länge darstellen, andernfalls es ist ein Byte. Zum Beispiel 01111111 bedeutet dies, dass die Länge 127 beträgt, und wenn die Länge 128 beträgt, werden zwei Bytes benötigt, also 10000000 10000000. Das höchste Bit des ersten Bytes ist 1, dann ist dies der Anfang der beiden Bytes, die das darstellen Das zweite Byte kann alle Bits zur Darstellung der Länge verwenden, und es ist zu beachten, dass MySQL die Little-Endian-Zählmethode verwendet, wobei das niedrige Bit zuerst und das hohe Bit zuletzt verwendet wird, sodass 129 10000001 10000000 ist. Die maximale Länge dieser Identifikationsmethode beträgt 32767, also 32 KB.
Frage 2: Was soll ich tun, wenn zwei Bytes nicht ausreichen, um die Länge darzustellen? Die Standardseitengröße von innoDB beträgt 16 KB. Bei einigen Feldern, die viele Bytes belegen, ist die Länge eines Felds beispielsweise größer als 16 KB. Wenn der Datensatz nicht auf einer einzelnen Seite gespeichert werden kann, speichert InnoDB einen Teil der Daten Im sogenannten Überlauf wird nur die auf dieser Seite verbleibende Länge in der Feldlängenliste mit variabler Länge gespeichert, sodass sie mit zwei Bytes gespeichert werden kann. Dieser Überlaufseitenmechanismus bezieht sich später auf den Datenüberlauf.
NULL-Werteliste
Einige Spalten in der Tabelle können NULL-Werte speichern, wenn diese NULL-Werte in den realen Daten des Datensatzes gespeichert werden. Daher werden diese vom Compact-Zeilenformat verwaltet Spalten mit NULL-Werten werden einheitlich erstellt und in einer Liste von NULL-Werten gespeichert. Für jede Spalte, die NULL speichern kann, gibt es ein entsprechendes Binärbit. Wenn der Wert des Binärbits 1 ist, bedeutet dies, dass der Wert der Spalte NULL ist. Wenn der binäre Bitwert 0 ist, bedeutet dies, dass der Wert der Spalte nicht NULL ist.
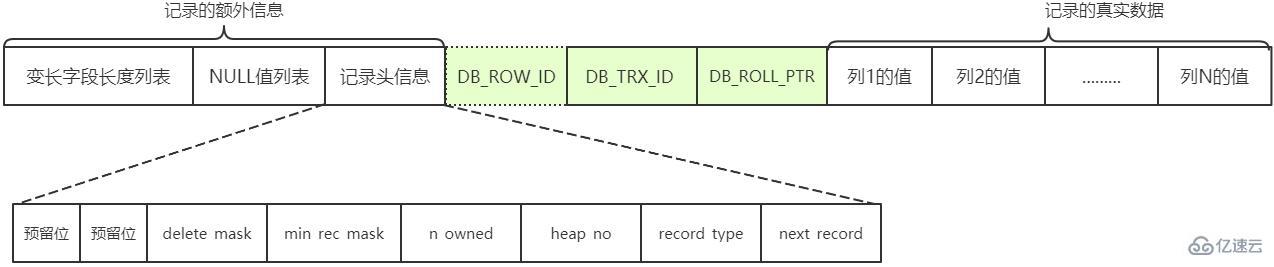
Datensatz-Header-Informationen
Die Datensatz-Header-Informationen, die zur Beschreibung des Datensatzes verwendet werden und aus festen 5 Bytes bestehen. 5 Bytes sind 40 Binärbits, und verschiedene Bits haben unterschiedliche Bedeutungen.
| 字段 | 长度(bit) | 说明 |
|---|---|---|
| 预留位1 | 1 | 没有使用 |
| 预留位2 | 1 | 没有使用 |
| delete_mask | 1 | 标记该记录是否被删除 |
| min_rec_mask | 1 | B+树的每层非叶子节点中的最小记录都会添加该标记 |
| n_owned | 4 | 表示当前记录拥有的记录数 |
| heap_no | 13 | 表示当前记录在页的位置信息 |
| record_type | 3 | 表示当前记录的类型,0 表示普通记录,1 表示B+树非叶子节点记录,2 表示最小记录,3 表示最大记录 |
| next_record | 16 | 表示下一条记录的相对位置 |
隐藏列
记录的真实数据除了我们自己定义的列的数据以外,MySQL会为每个记录默认的添加一些列(也称为隐藏列),包括:
DB_ROW_ID(row_id):非必须,6字节,表示行ID,唯一标识一条记录
DB_TRX_ID:必须,6字节,表示事务ID
DB_ROLL_PTR:必须,7字节,表示回滚指针
InnoDB表对主键的生成策略是:优先使用用户自定义主键作为主键,如果用户没有定义主键,则选取一个Unique键作为主键,如果表中连Unique 键都没有定义的话,则InnoDB会为表默认添加一个名为row_id的隐藏列作为主键。
DB_TRX_ID(也可以称为trx_id) 和DB_ROLL_PTR(也可以称为roll_ptr) 这两个列是必有的,但是row_id是可选的(在没有自定义主键以及Unique 键的情况下才会添加该列)。
其他的行格式和Compact行格式差别不大。
Redundant行格式
Redundant行格式是MySQL5.0之前用的一种行格式,不予深究。
Dynamic行格式
MySQL5.7的默认行格式就是Dynamic,Dynamic行格式和Compact行格式挺像,只不过在处理行溢出数据时有所不同。
Compressed行格式
Compressed行格式在Dynamic行格式的基础上会采用压缩算法对页面进行压缩,以节省空间。以zlib的算法进行压缩,因此对于BLOB、TEXT、VARCHAR这类大长度数据能够进行有效的存储(减少40%,但对CPU要求更高)。
数据溢出
如果我们定义一个表,表中只有一个VARCHAR字段,如下:
CREATE TABLE test_varchar( c VARCHAR(60000))
然后往这个字段插入60000个字符,会发生什么?前边说过,MySQL中磁盘和内存交互的基本单位是页,也就是说MySQL是以页为基本单位来管理存储空间的,我们的记录都会被分配到某个页中存储。而一个页的大小一般是16KB,也就是16384字节,而一个VARCHAR(M)类型的列就最多可以存储65532个字节,这样就可能造成一个页存放不了一条记录的情况。
在Compact和Redundant行格式中,对于占用存储空间非常大的列,在记录的真实数据处只会存储该列的该列的前768个字节的数据,然后把剩余的数据分散存储在几个其他的页中,记录的真实数据处用20个字节(768字节后20个字节)存储指向这些页的地址。这个过程也叫做行溢出,存储超出768字节的那些页面也被称为溢出页。
Dynamic和Compressed行格式,不会在记录的真实数据处存储字段真实数据的前768个字节,而是把所有的字节都存储到其他页面中,只在记录的真实数据处存储其他页面的地址。
实战分析行格式
准备表及数据:
create table row_test ( t1 varchar(10), t2 varchar(10), t3 char(10), t4 varchar(10) ) engine=innodb charset=latin1 row_format=compact; insert into row_test values('a','bb','bb','ccc'); insert into row_test values('d','ee','ee','fff'); insert into row_test values('d',NULL,NULL,'fff');
在Linux环境下,使用hexdump -C -v mytest.ibd>mytest.txt,打开mytest.txt文件,找到如下内容:
0000c070 73 75 70 72 65 6d 75 6d 03 02 01 00 00 00 10 00 |supremum........| 0000c080 2c 00 00 00 00 02 00 00 00 00 00 0f 61 c8 00 00 |,...........a...| 0000c090 01 d4 01 10 61 62 62 62 62 20 20 20 20 20 20 20 |....abbbb | 0000c0a0 20 63 63 63 03 02 01 00 00 00 18 00 2b 00 00 00 | ccc........+...| 0000c0b0 00 02 01 00 00 00 00 0f 62 c9 00 00 01 b2 01 10 |........b.......| 0000c0c0 64 65 65 65 65 20 20 20 20 20 20 20 20 66 66 66 |deeee fff| 0000c0d0 03 01 06 00 00 20 ff 98 00 00 00 00 02 02 00 00 |..... ..........| 0000c0e0 00 00 0f 67 cc 00 00 01 b6 01 10 64 66 66 66 00 |...g.......dfff.|
该行记录从0000c078开始,第一行整理如下:
03 02 01 // 变长字段长度列表,逆序,t4列长度为3,t2列长度为2,t1列长度为1 00 // NULL标志位,第一行没有NULL值 00 00 10 00 2c // 记录头信息,固定5字节长度 00 00 00 2b 68 00 // RowID我们建的表没有主键,因此会有RowID,固定6字节长度 00 00 00 00 06 05 // 事务ID,固定6个字节80 00 00 00 32 01 10 // 回滚指针,固定7个字节61 // t1数据'a'62 62 // t2'bb'62 62 20 20 20 20 20 20 20 20 // t3数据'bb'63 63 63 // t4数据'ccc'
第二行整理如下:
03 02 01 // 变长字段长度列表,逆序,t4列长度为3,t2列长度为2,t1列长度为1 00 // NULL标志位,第二行没有NULL值 00 00 18 00 2b // 记录头信息,固定5字节长度 00 00 00 00 02 01 // RowID我们建的表没有主键,因此会有RowID,固定6字节长度 00 00 00 00 0f 62 // 事务ID,固定6个字节 c9 00 00 01 b2 01 10 // 回滚指针,固定7个字节64 // t1数据'd'65 65 // t2数据'ee'65 65 20 20 20 20 20 20 20 20 // t3数据'ee'66 66 66 // t4数据'fff'
第三行整理如下:
03 01 // 变长字段长度列表,逆序,t4列长度为3,t1列长度为1 06 // 00000110 NULL标志位,t2和t3列为空 00 00 20 ff 98 // 记录头信息,固定5字节长度 00 00 00 00 02 02 // RowID我们建的表没有主键,因此会有RowID,固定6字节长度 00 00 00 00 0f 67 // 事务ID,固定6个字节 cc 00 00 01 b6 01 10 // 回滚指针,固定7个字节64 // t1数据'd'66 66 66 // t4数据'fff'
接下来更新下数据:
mysql> update row_test set t2=null where t1='a'; Query OK, 1 row affected (0.02 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> delete from row_test where t2='ee'; Query OK, 1 row affected (0.01 sec)
查看二进制内容(需要等一会,有可能只写入了缓存,磁盘上的文件并没有更新):
0000c070 73 75 70 72 65 6d 75 6d 03 01 02 00 00 10 00 58 |supremum.......X| 0000c080 00 00 00 00 02 00 00 00 00 00 0f 68 4d 00 00 01 |...........hM...| 0000c090 9e 04 a9 61 62 62 20 20 20 20 20 20 20 20 63 63 |...abb cc| 0000c0a0 63 63 63 63 03 02 01 00 20 00 18 00 00 00 00 00 |cccc.... .......| 0000c0b0 00 02 01 00 00 00 00 0f 6a 4e 00 00 01 9f 10 c0 |........jN......| 0000c0c0 64 65 65 65 65 20 20 20 20 20 20 20 20 66 66 66 |deeee fff| 0000c0d0 03 01 06 00 00 20 ff 98 00 00 00 00 02 02 00 00 |..... ..........| 0000c0e0 00 00 0f 67 cc 00 00 01 b6 01 10 64 66 66 66 00 |...g.......dfff.|
该行记录从0000c078开始,第一行整理如下:
03 01 // 变长字段长度列表,逆序,t4列长度为3,t1列长度为1 02 // 0000 0010 NULL标志位,表示t2为null 00 00 10 00 58 // 记录头信息,固定5字节长度 00 00 00 00 02 00 // RowID我们建的表没有主键,因此会有RowID,固定6字节长度 00 00 00 00 0f 68 // 事务ID,固定6个字节 4d 00 00 01 9e 04 a9 // 回滚指针,固定7个字节61 // t1数据'a'62 62 20 20 20 20 20 20 20 20 // t3数据'bb'63 63 63 // t4数据'ccc'
第二行整理如下:
03 02 01 // 变长字段长度列表,逆序,t4列长度为3,t2列长度为2,t1列长度为1 00 // NULL标志位,第二行没有NULL值20 00 18 00 00 // 0010 delete_mask=1 标记该记录是否被删除 记录头信息,固定5字节长度 00 00 00 00 02 01 // RowID我们建的表没有主键,因此会有RowID,固定6字节长度 00 00 00 00 0f 6a // 事务ID,固定6个字节 4e 00 00 01 9f 10 c0 // 回滚指针,固定7个字节64 // t1数据'd'65 65 // t2数据'ee'65 65 20 20 20 20 20 20 20 20 // t3数据'ee'66 66 66 // t4数据'fff'
第三行数据未发生变化。
Das obige ist der detaillierte Inhalt vonWie MySQL das InnoDB-Zeilenformat anhand von Binärinhalten erkennt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!