
Heim >Datenbank >MySQL-Tutorial >So optimieren Sie die Join-Anweisung in MySQL
So optimieren Sie die Join-Anweisung in MySQL

- PHPznach vorne
- 2023-06-03 09:31:581334Durchsuche
Einfacher Nested-Loop-Join
Werfen wir einen Blick darauf, wie MySQL bei der Durchführung einer Join-Operation funktioniert. Was sind die gängigen Join-Methoden?
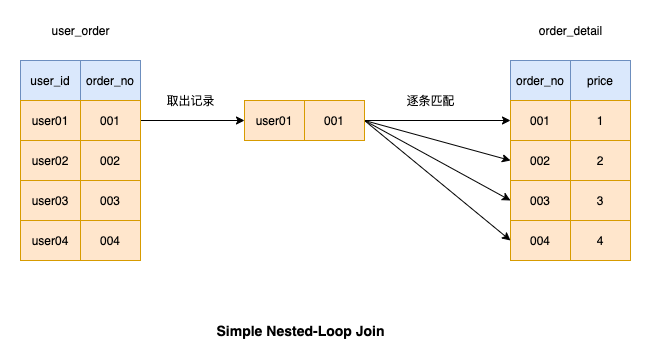
Wie im Bild gezeigt, ist die Tabelle auf der linken Seite, wenn wir den Verbindungsvorgang ausführen Angesteuerte Tabelle , und die Tabelle auf der rechten Seite ist # 🎜🎜#driven table
Einfacher Nested-Loop-Join Bei dieser Join-Operation wird ein Datensatz aus der Treibertabelle entnommen und dann mit den Datensätzen der getriebenen Tabelle abgeglichen Wenn die Bedingungen übereinstimmen, wird das Ergebnis zurückgegeben. Fahren Sie dann mit dem Abgleichen des nächsten Datensatzes in der Treibertabelle fort, bis alle Daten in der Treibertabelle abgeglichen wurden.Weil es zeitaufwändig ist, jedes Mal Daten aus der Treibertabelle abzurufen , MySQL verwendet diesen Algorithmus nicht, um Verbindungsvorgänge auszuführen
Nested-Loop-Join blockieren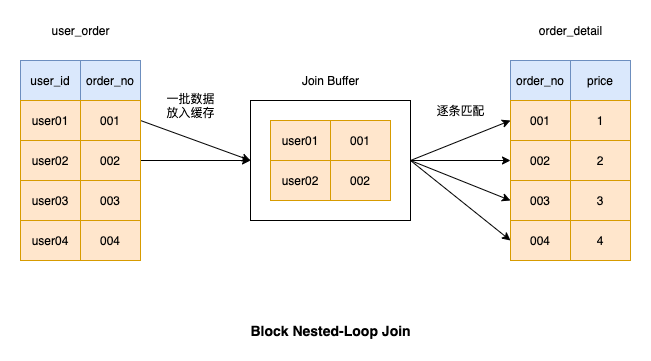
show variables like '%join_buffer%'Verschieben Sie die zuvor verwendete Single_Table-Tabelle, erstellen Sie 2 Tabellen basierend auf der Single_Table-Tabelle und fügen Sie 1 W zufällig ein Datensätze in jede Tabelle
CREATE TABLE single_table (
id INT NOT NULL AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1),
UNIQUE KEY idx_key2 (key2),
KEY idx_key3 (key3),
KEY idx_key_part(key_part1, key_part2, key_part3)
) Engine=InnoDB CHARSET=utf8;
create table t1 like single_table;
create table t2 like single_table;# 🎜🎜#Wenn Sie die Join-Anweisung direkt verwenden, wählt der MySQL-Optimierer möglicherweise Tabelle t1 oder t2 als treibende Tabelle aus, was sich auf den Prozess der Analyse der SQL-Anweisung auswirkt, daher verwenden wir Straight_join Damit MySQL eine feste Verbindung zum Ausführen der Abfrage verwenden kann
select * from t1 straight_join t2 on (t1.common_field = t2.common_field)Die Laufzeit beträgt 0,035 s
Der Ausführungsplan ist wie folgt

Block Nested-Loop Join basiert# 🎜🎜# Algorithmus
Index Nested-Loop Join # 🎜🎜#Nachdem Sie den
# 🎜🎜#Nachdem Sie den
Algorithmus verstanden haben, können Sie sehen, dass jeder Datensatz in Die Treibertabelle gleicht alle Datensätze in der gesteuerten Tabelle ab. Kann die Effizienz des gesteuerten Tabellenabgleichs verbessert werden? Ich denke, Sie haben auch an diesen Algorithmus gedacht, der darin besteht, Indizes zu den durch die gesteuerte Tabelle verbundenen Spalten hinzuzufügen, sodass der Abgleichsprozess sehr schnell ist, wie im Bild gezeigt
# 🎜🎜#
Werfen wir einen Blick darauf, wie schnell es ist, Abfragen basierend auf Verknüpfungen basierend auf Indexspalten durchzuführen. select * from t1 straight_join t2 on (t1.id = t2.id)
Die Ausführungszeit beträgt 0,001 Sekunden, was offensichtlich um mehr als eine Ebene schneller ist als die Verbindung basierend auf gewöhnlichen Spalten
# 🎜🎜# Der Ausführungsplan lautet wie folgt 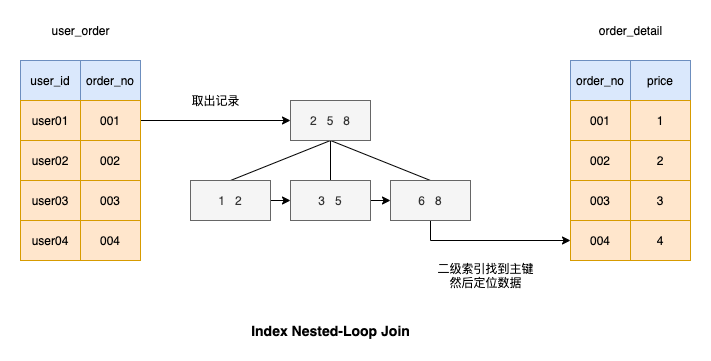
 Wie wähle ich die Treibertabelle aus?
Wie wähle ich die Treibertabelle aus?
Nachdem wir nun die spezifische Implementierung von Join kennen, sprechen wir über eine häufig gestellte Frage, nämlich: Wie wählt man die Treibertabelle aus? Wenn der Join-Puffer groß genug ist, Wer macht das? Die Treibertabelle hat keinen Einfluss weniger Daten und die Häufigkeit, mit der sie in den Join-Puffer gestellt werden, ist gering, was die Anzahl der Scans der Tabelle verringert ein Index Nested-Loop Join-Algorithmus
 Angenommen, die Anzahl der Zeilen der Treibertabelle ist M, daher müssen M Zeilen der Treibertabelle gescannt werden
Angenommen, die Anzahl der Zeilen der Treibertabelle ist M, daher müssen M Zeilen der Treibertabelle gescannt werden
#🎜🎜; #Jede Datenzeile in der treibenden Tabelle muss einmal in der getriebenen Tabelle durchsucht werden. Die ungefähre Komplexität des gesamten Ausführungsprozesses beträgt M + M &lowast 2 ∗ 2∗log2N
Offensichtlich hat M einen größeren Einfluss auf die Anzahl der gescannten Zeilen, daher sollte eine kleine Tabelle als Steuertabelle verwendet werden. Die Voraussetzung dieser Schlussfolgerung ist natürlich, dass der Index der gesteuerten Tabelle verwendet werden kannKurz gesagt, wir können die kleine Tabelle als Treibertabelle verwenden.
Wenn die Join-Anweisung langsam ausgeführt wird, können wir sie mit den folgenden Methoden optimieren:
Beim Ausführen der Join-Operation kann die gesteuerte Tabelle dies tun verwendet werden Index
Verwenden Sie eine kleine Tabelle als Treibertabelle
Erhöhen Sie die Größe des Join-Puffers
Verwenden Sie * nicht als Abfrageliste, sondern geben Sie nur die erforderlichen Spalten zurück
Das obige ist der detaillierte Inhalt vonSo optimieren Sie die Join-Anweisung in MySQL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!