
Heim >Datenbank >MySQL-Tutorial >Was ist der Grund, warum temporäre MySQL-Tabellen doppelte Namen haben können?
Was ist der Grund, warum temporäre MySQL-Tabellen doppelte Namen haben können?

- PHPznach vorne
- 2023-06-02 22:01:011522Durchsuche
Heute beginnen wir mit dieser Frage: Welche Eigenschaften haben temporäre Tabellen und für welche Szenarien eignen sie sich?
Hier muss ich Ihnen zunächst helfen, ein leicht missverständliches Problem zu klären: Manche Leute denken vielleicht, dass temporäre Tabellen Speichertabellen sind. Diese beiden Konzepte sind jedoch völlig unterschiedlich.
Speichertabelle bezieht sich auf eine Tabelle, die die Memory-Engine verwendet. Die Tabellenerstellungssyntax lautet create table …engine=memory. **Die Daten dieser Art von Tabelle werden im Speicher gespeichert und beim Neustart des Systems gelöscht, die Tabellenstruktur bleibt jedoch erhalten. ** Abgesehen von diesen beiden Funktionen, die im Vergleich zu anderen Funktionen „seltsam“ aussehen, handelt es sich um eine normale Tabelle.
Temporärer Tisch, es können verschiedene Motortypen verwendet werden. Wenn Sie die temporäre Tabelle der InnoDB-Engine oder der MyISAM-Engine verwenden, werden die Daten beim Schreiben auf die Festplatte geschrieben. Natürlich können auch temporäre Tabellen die Memory Engine nutzen.
Nachdem wir den Unterschied zwischen Speichertabellen und temporären Tabellen geklärt haben, werfen wir einen Blick auf die Eigenschaften temporärer Tabellen.
Eigenschaften temporärer Tabellen
Zur Erleichterung des Verständnisses werfen wir einen Blick auf die folgende Operationssequenz:

Wie Sie sehen können, werden temporäre Tabellen mit den folgenden Eigenschaften verwendet:
Die Syntax zum Erstellen Eine Tabelle ist temporäre Tabelle erstellen ….
Andere Threads können nicht auf die von einer bestimmten Sitzung erstellte temporäre Tabelle zugreifen, sie ist nur für diese Sitzung sichtbar. Daher ist die von Sitzung A in der Abbildung erstellte temporäre Tabelle t für Sitzung B unsichtbar.
Eine temporäre Tabelle kann denselben Namen wie eine normale Tabelle haben.
Wenn in Sitzung A temporäre Tabellen und normale Tabellen mit demselben Namen vorhanden sind, greifen die showcreate-Anweisung und die Add-, Delete-, Modify- und Query-Anweisungen auf die temporäre Tabelle zu. Der Befehl
showtables zeigt keine temporären Tabellen an.
Da auf die temporäre Tabelle nur von der Sitzung zugegriffen werden kann, die sie erstellt hat, wird die temporäre Tabelle automatisch gelöscht, wenn die Sitzung endet.
Das Join-Optimierungsszenario im vorherigen Artikel eignet sich besonders für die Verwendung temporärer Tabellen, da temporäre Tabellen über diese Funktion verfügen. Warum? Zu den Gründen gehören hauptsächlich die folgenden zwei Aspekte:
Temporäre Tabellen in verschiedenen Sitzungen können umbenannt werden Wenn mehrere Sitzungen gleichzeitig die Join-Optimierung ausführen, besteht kein Grund zur Sorge, dass die Tabellenerstellung fehlschlägt auf wiederholte Tabellennamen.
Sie müssen sich keine Sorgen über das Löschen von Daten machen. Wenn eine normale Tabelle verwendet wird, der Client während der Prozessausführung abnormal getrennt wird oder die Datenbank abnormal neu gestartet wird, müssen die während des Zwischenprozesses generierten Datentabellen bereinigt werden. Da die temporäre Tabelle automatisch recycelt wird, ist dieser zusätzliche Vorgang nicht erforderlich.
Anwendung temporärer Tabellen
Da kein Grund zur Sorge über doppelte Namenskonflikte zwischen Threads besteht, werden temporäre Tabellen häufig im Optimierungsprozess komplexer Abfragen verwendet. Unter diesen ist die datenbankübergreifende Abfrage des Unterdatenbank- und Untertabellensystems ein typisches Nutzungsszenario.
Im Allgemeinen besteht das Szenario des Datenbank- und Tabellen-Sharding darin, eine logisch große Tabelle auf verschiedene Datenbankinstanzen zu verteilen. Zum Beispiel. Teilen Sie für ein gegebenes Feld f die große Tabelle ht in 1024 Untertabellen auf und verteilen Sie diese Untertabellen auf 32 Datenbankinstanzen. Wie in der folgenden Abbildung dargestellt:
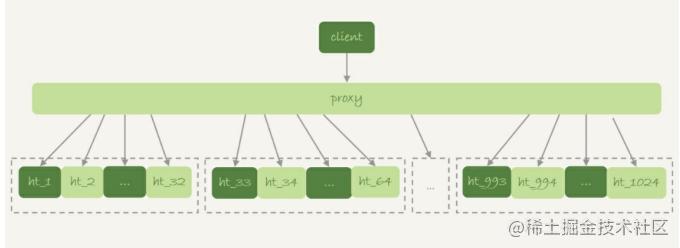
Im Allgemeinen verfügt diese Art von Unterdatenbank- und Untertabellensystem über einen Zwischenschicht-Proxy. Es gibt jedoch auch einige Lösungen, die es dem Client ermöglichen, sich direkt mit der Datenbank zu verbinden, d. h. es gibt keine Proxy-Schicht.
In dieser Architektur basiert die Auswahl der Partitionsschlüssel auf dem Prinzip „Datenbank- und tabellenübergreifende Operationen reduzieren“. Wenn die meisten Anweisungen die entsprechende Bedingung von f enthalten, sollte f als Partitionsschlüssel verwendet werden. Der Proxy, der die SQL-Anweisung analysiert hat, entscheidet, an welche Tabelle sie zur Abfrage weitergeleitet wird.
Zum Beispiel die folgende Aussage:
select v from ht where f=N;
Zu diesem Zeitpunkt können wir die Untertabellenregeln (z. B. N%1024) verwenden, um zu bestätigen, in welcher Untertabelle die erforderlichen Daten platziert werden. Diese Art von Anweisung muss nur auf eine Untertabelle zugreifen und ist die beliebteste Anweisungsform im Unterdatenbank- und Untertabellenschema.
Wenn es jedoch einen anderen Index k in dieser Tabelle gibt und die Abfrageanweisung wie folgt lautet:
select v from ht where k >= M order by t_modified desc limit 100;
Da das Partitionsfeld f zu diesem Zeitpunkt nicht in den Abfragebedingungen verwendet wird, können wir nur alle Partitionen finden, die erfüllt sind die Bedingungen Alle Zeilen, und führen Sie dann die Reihenfolge nach Operation einheitlich aus. In diesem Fall gibt es zwei häufig verwendete Ideen.
Die erste Idee besteht darin, die Sortierung im Prozesscode der Proxy-Schicht zu implementieren. Der Vorteil dieser Methode besteht darin, dass die Verarbeitungsgeschwindigkeit hoch ist. Nachdem die Daten aus der Unterdatenbank abgerufen wurden, können sie direkt an der Berechnung im Speicher teilnehmen. Allerdings liegen auch die Mängel dieser Lösung auf der Hand:
- erfordert einen relativ großen Entwicklungsaufwand. Die Aussage, die wir als Beispiel gegeben haben, ist relativ einfach. Wenn es sich um komplexe Vorgänge wie Gruppieren oder sogar Beitreten handelt, sind die Entwicklungskapazitäten der mittleren Schicht relativ hoch
对proxy端的压力比较大,尤其是很容易出现内存不够用和CPU瓶颈的问题。
另一种思路就是,把各个分库拿到的数据,汇总到一个MySQL实例的一个表中,然后在这个汇总实例上做逻辑操作。
比如上面这条语句,执行流程可以类似这样:
在汇总库上创建一个临时表temp_ht,表里包含三个字段v、k、t_modified;
在各个分库上执行
select v,k,t_modified from ht_x where k >= M order by t_modified desc limit 100;把分库执行的结果插入到temp_ht表中;
执行
select v from temp_ht order by t_modified desc limit 100;
得到结果。 这个过程对应的流程图如下所示:
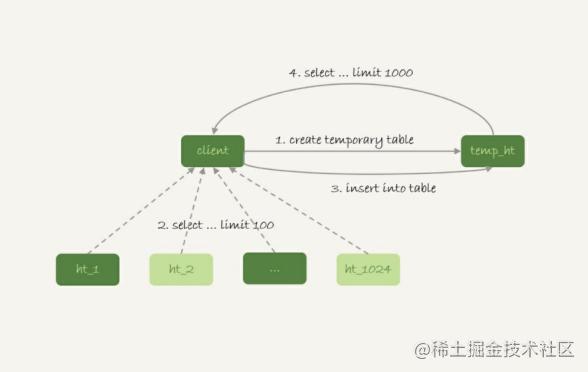
在实践中,我们往往会发现每个分库的计算量都不饱和,所以会直接把临时表temp_ht放到32个分库中的某一个上。
为什么临时表可以重名?
你可能会问,不同线程可以创建同名的临时表,这是怎么做到的呢?
我们在执行
create temporary table temp_t(id int primary key)engine=innodb;
这个语句的时候,MySQL要给这个InnoDB表创建一个frm文件保存表结构定义,还要有地方保存表数据。
这个frm文件放在临时文件目录下,文件名的后缀是.frm,前缀是“#sql{进程id}_ {线程id}_ 序列号”。
从文件名的前缀规则,我们可以看到,其实创建一个叫作t1的InnoDB临时表,MySQL在存储上认为我们创建的表名跟普通表t1是不同的,因此同一个库下面已经有普通表t1的情况下,还是可以再创建一个临时表t1的。
先来举一个例子。

进程号为1234的进程,它的线程id分别为4和5,分别属于会话A和会话B。因此,可以看出,session A和session B创建的临时表在磁盘上的文件名不会冲突。
MySQL维护数据表,除了物理上要有文件外,内存里面也有一套机制区别不同的表,每个表都对应一个table_def_key。
一个普通表的table_def_key的值是由“库名+表名”得到的,所以如果你要在同一个库下创建两个同名的普通表,创建第二个表的过程中就会发现table_def_key已经存在了。
而对于临时表,table_def_key在“库名+表名”基础上,又加入了“server_id+thread_id”。
也就是说,session A和session B创建的两个临时表t1,它们的table_def_key不同,磁盘文件名也不同,因此可以并存。
在实现上,每个线程都维护了自己的临时表链表。这样每次session内操作表的时候,先遍历链表,检查是否有这个名字的临时表,如果有就优先操作临时表,如果没有再操作普通表;在session结束的时候,对链表里的每个临时表,执行 “DROPTEMPORARY TABLE +表名”操作。
你会注意到,在binlog中也有DROP TEMPORARY TABLE命令的记录。你一定会觉得奇怪,临时表只在线程内自己可以访问,为什么需要写到binlog里面?这,就需要说到主备复制了。
临时表和主备复制
既然写binlog,就意味着备库需要。 你可以设想一下,在主库上执行下面这个语句序列:
create table t_normal(id int primary key, c int)engine=innodb;/*Q1*/ create temporary table temp_t like t_normal;/*Q2*/ insert into temp_t values(1,1);/*Q3*/ insert into t_normal select * from temp_t;/*Q4*/
如果关于临时表的操作都不记录,那么在备库就只有create table t_normal表和insert intot_normal select * fromtemp_t这两个语句的binlog日志,备库在执行到insert into t_normal的时候,就会报错“表temp_t不存在”。
你可能会说,如果把binlog设置为row格式就好了吧?因为binlog是row格式时,在记录insert intot_normal的binlog时,记录的是这个操作的数据,即:write_rowevent里面记录的逻辑是“插入一行数据(1,1)”。
确实是这样。如果当前的binlog_format=row,那么跟临时表有关的语句,就不会记录到binlog里。也就是说,只在binlog_format=statment/mixed的时候,binlog中才会记录临时表的操作。
在这种情况下,执行创建临时表语句的操作会被传递到备用数据库进行处理,从而触发备用数据库的同步线程创建相应的临时表。主库在线程退出的时候,会自动删除临时表,但是备库同步线程是持续在运行的。因此,我们需要在主数据库中再运行一个DROP TEMPORARY TABLE命令以便备用数据库执行。
Es spielt keine Rolle, ob verschiedene Threads in der Hauptdatenbank temporäre Tabellen mit demselben Namen erstellen, aber wie erfolgt die Übertragung zur Standby-Datenbank zur Ausführung?
Lassen Sie mich nun ein Beispiel geben. In der folgenden Sequenz ist Instanz S die Standby-Datenbank von M.

Zwei Sitzungen in der Hauptdatenbank M haben eine temporäre Tabelle t1 mit demselben Namen erstellt. Diese beiden Anweisungen zum Erstellen einer temporären Tabelle t1 werden an die Standby-Datenbank S übertragen.
Allerdings wird der Anwendungsprotokollthread der Standby-Datenbank gemeinsam genutzt, was bedeutet, dass die Create-Anweisung zweimal im Anwendungsthread ausgeführt werden muss. Trotz Multithread-Replikation ist es immer noch möglich, demselben Worker in der Slave-Bibliothek zur Ausführung zugewiesen zu werden. Wird dies dazu führen, dass der Synchronisierungsthread einen Fehler meldet?
Natürlich nicht, sonst wäre die temporäre Tabelle ein Bug. Mit anderen Worten: Der Backup-Thread muss die beiden T1-Tabellen als unabhängige temporäre Tabellen für die Verarbeitung während der Ausführung behandeln. Wie wird dies erreicht? Wenn MySQL das Binlog aufzeichnet, schreibt es die Thread-ID der Hauptbibliothek, um diese Anweisung auszuführen, in das Binlog. Auf diese Weise kann der Anwendungsthread in der Standby-Datenbank die Hauptdatenbank-Thread-ID kennen, die jede Anweisung ausführt, und diese Thread-ID verwenden, um den table_def_key der temporären Tabelle zu erstellen:
Die temporäre Tabelle t1 der Sitzung A, die table_def_key in der Standby-Datenbank ist: Bibliotheksname + t1 + „M's serverid“ + „session A’s thread_id“; + „thread_id der Sitzung B“.
Da table_def_key unterschiedlich ist, kommt es zwischen diesen beiden Tabellen nicht zu Konflikten im Anwendungsthread der Standby-Datenbank.
Das obige ist der detaillierte Inhalt vonWas ist der Grund, warum temporäre MySQL-Tabellen doppelte Namen haben können?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!