
Heim >Datenbank >MySQL-Tutorial >So migrieren Sie das sensorlose SQL Server-System zu MySQL
So migrieren Sie das sensorlose SQL Server-System zu MySQL

- PHPznach vorne
- 2023-06-02 20:36:43976Durchsuche
1. Architekturübersicht
Durch die Analyse der Engpässe des bestehenden Systems haben wir festgestellt, dass sich die Kernfehler im verstreuten Auftragsdaten-Cache konzentrieren, was zu Inkonsistenzen an allen Enden der Daten und der direkten Verbindung zwischen jedem führt Auftragsanwendung und der Datenbank, was zu einer schlechten Skalierbarkeit führt. Durch die Praxis haben wir Middleware geschrieben, um die Datenzugriffsschicht zu abstrahieren und zu vereinheitlichen, und einen Auftragscache basierend auf dem Spiegel der Datenbankbereitstellungsarchitektur erstellt, um heiße Daten einheitlich zu verwalten und die Unterschiede zwischen verschiedenen Enden zu lösen.
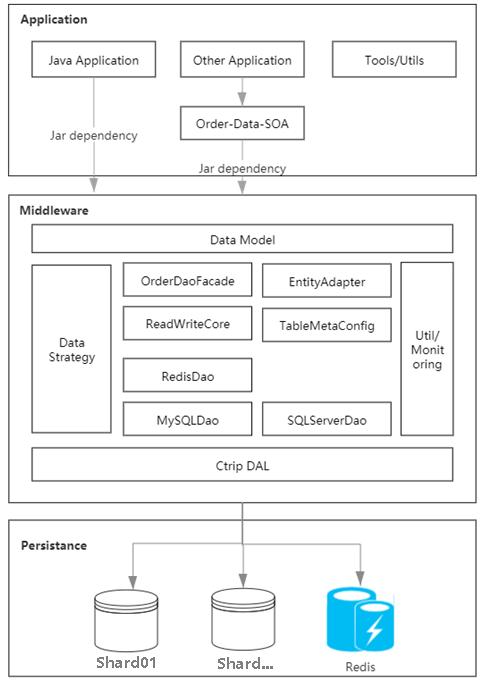
Abbildung 1.1 Diagramm der Speichersystemarchitektur
2. Anwendungsszenarien
1. Neue Synchronisierung auf Einzelsekundenebene an jedem Ende
Die Geschwindigkeit von der Auftragsübermittlung bis zur Sichtbarkeit an jedem Ende ist einer der Kernindikatoren des Wir haben die Hauptglieder der Datenkette optimiert und umfassen die Synchronisierung neuer Bestellungen, den Echtzeit-Nachrichten-Push, die Erstellung von Abfrageindizes und die Offline-Archivierung der Datenplattform, sodass die Datenankunftsgeschwindigkeit im großen System verbessert wird innerhalb von 3 Sekunden, d. h. der Benutzer hat gerade eine Bestellung aufgegeben. Dadurch wird zur sichtbaren Liste meiner Portabilität gesprungen.
Wenn ein neuer Benutzer eine Bestellung erstellt, dient der Synchronisierungsdienst als Datenverbindungseingang, um die Bestelldaten des Benutzers über die Middleware in die Bestellbibliothek zu schreiben. Zu diesem Zeitpunkt schließt die Middleware gleichzeitig den Aufbau des Bestellcaches ab
Wenn die Bestellung das Lagerverhalten und die Hotspot-Datenerstellung abschließt, werden die Bestellinformationen in Echtzeit an jedes Subsystem ausgegeben.
Wenn die neue Bestellung in die Datenbank eingegeben wird, wird sofort ein ES-Index der Bestelldetails erstellt Entwickelt, um Abrufunterstützung für Dritte bereitzustellen.
Schließlich implementiert die Datenplattform T+1 die Archivierung und Bereitstellung von Daten am Tag. Wird für verschiedene Offline-Unternehmen wie BI verwendet.
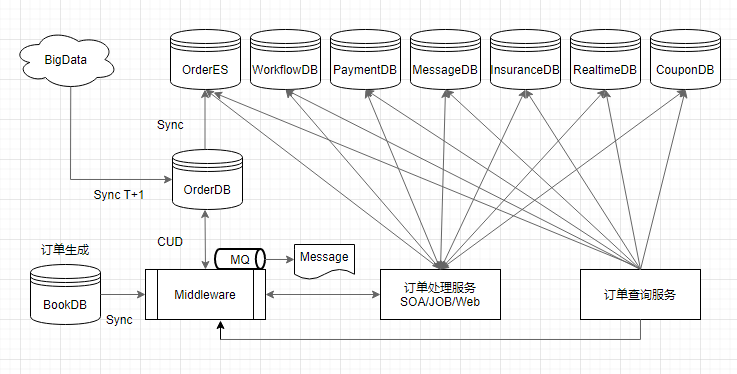
Abbildung 2.1 Datenverknüpfung
2. Automatische Auftragserteilung und Workbench
Die Unterstützung für Kunden, Händler und Mitarbeiter-Workbench ist die grundlegende Aufgabe des Auftragsspeichersystems. Abbildung 2.1 Datenverknüpfung nach Übermittlung der neuen Bestellung Die Verbindung zwischen automatischer Auftragserteilung und der Workbench ist unverzichtbar. Bei der automatischen Bestellung werden Bestelldetails so schnell wie möglich an den Händler gesendet, nachdem der Kunde die Bestellung abgeschickt hat, um den Lagerbestand zu überprüfen und die Bestellung zu bestätigen. Die Werkbank unterstützt die Mitarbeiter dabei, Aufträge einzuholen und manuelle Ereignisse zeitnah abzuwickeln.
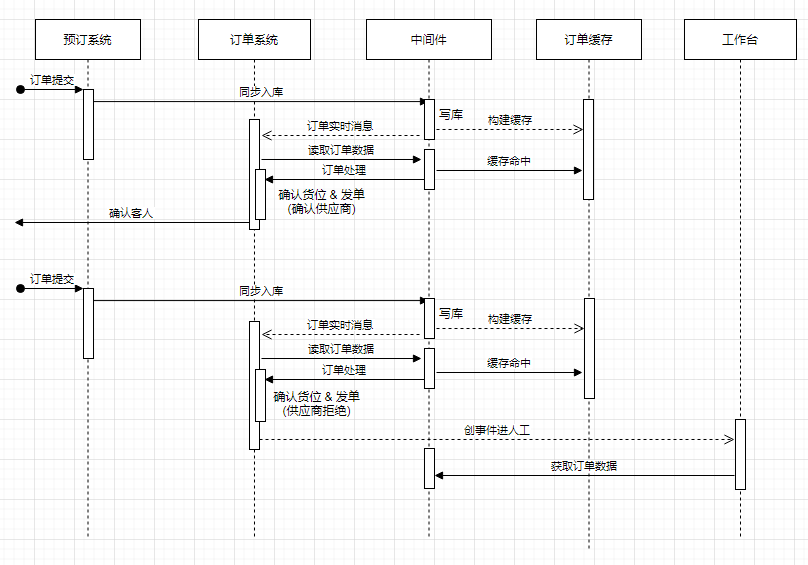
Abbildung 2.2 Die Beziehung zwischen Auftragserteilung und Workbench basierend auf dem Speichersystem (gekürzte Details)
3. Abfrage und Datenanalyse
Basierend auf Auftragsdaten als Kern, ist es hauptsächlich in zwei Geschäftsbereiche unterteilt: Online Abfrage- und Datenanalyse Am Beispiel detaillierter Abfragen bleibt der Zugriffs-QPS das ganze Jahr über auf einem hohen Niveau und es kann während der Feiertagsspitzen leicht zu Abfrageengpässen kommen. Nach der Ursachenprüfung haben wir Anpassungen in diesem Architektur-Upgrade zur Optimierung vorgenommen die hohe Verfügbarkeit verwandter Szenarien.
Die Online-Abfrage basiert hauptsächlich auf der Zwischenspeicherung von Bestellungen. Um den Abfragedruck zu verringern, wird bei der Übermittlung von Bestellungen ein Hotspot-Cache erstellt, der gemäß den konfigurierten Zeitparametern lange gültig sein kann.
Nicht-Online-Abfrageszenarien werden durch Echtzeit-Nachrichten-Push übermittelt und mit dem Hive-Data-Warehouse-T+1-Modus kombiniert. Bei jedem Anlass, der langfristige Bestelldaten erfordert (z. B. Echtzeitberichte), kann auf Bestellnachrichten zugegriffen werden Echtzeitberechnung. Bei der Durchführung umfangreicher Datenanalysen verwendet Offline-BI Hive-Tabellen und führt täglich in der Zeit mit geringer Spitzenlast am frühen Morgen eine Datensynchronisierung durch niederfrequenten Zugriff aus der Datenbank durch.
Auf diese Weise schützen wir den Zugriff auf die Hauptauftragsdatenbank hinter der Troika aus Auftragscache, Echtzeit-Messaging und Hive-Data-Warehouse und entkoppeln ihn weitestgehend vom Geschäft.
3. System-Upgrade-Praxis
Beim Upgrade des Kernspeichersystems von Ctrip muss während des gesamten Prozesses eine Live-Migration durchgeführt werden, und das Ziel besteht darin, alle Vorgänge für die Anwendungen auf der Datenverbindung transparent und verlustfrei zu machen erreicht. Unser Design analysiert umfassend die Eigenschaften der Datenverbindungen der Gruppe. Das Auftragscachesystem ermöglicht eine Datenbankspiegelung, um die direkte Kopplung zwischen der Anwendung und der Datenbank zu reduzieren. Anschließend wird die Middleware verwendet, um die physische Beziehung zwischen den von SQLServer stammenden Daten transparent zu entfernen. MySQL und stellt der Anwendung den zugrunde liegenden Layer für die Live-Migration bereit.
In Kombination mit dem Prozessdesign der verlustfreien Migration konzentriert es sich auf die Sichtbarkeit und Kontrollierbarkeit jedes Datenbankverkehrs, unterstützt Verkehrsverteilungsstrategien auf der gesamten Datenbank-, Shard-Ebene, Tabellenebene und CRUD-Betriebsebene und bietet ausreichende Implementierungsmittel für die zugrunde liegende Ebene Datenmigration. Das Data Warehouse-Verbindungsdesign konzentriert sich auf die Lösung des Synchronisierungsproblems zwischen den zig Milliarden Offlinedaten auf der Datenplattform und der Online-Phase mit zwei Datenbanken sowie auf die Lösung der Datenprobleme, die beim vollständigen Zugriff auf MySQL auftreten.
Das Folgende wird in drei Teile unterteilt, um die Erfahrungen zu teilen, die wir in diesem Prozess gemacht haben.
1. Verteiltes Bestell-Caching
Mit der Geschäftsentwicklung steigt die Anzahl der Benutzer und Besuche, und auch der Druck auf Bestellsystemanwendungen und Server nimmt zu. Bevor das Order-Caching eingeführt wurde, stellte jede Anwendung unabhängig eine Verbindung zur Datenbank her, was zu abgefragten Daten führte, die nicht zwischen Anwendungen geteilt werden konnten, und es gab eine Obergrenze für die Anzahl der DB-Abfragen und Verbindungen pro Sekunde basierte auf DB-Speicher und es bestand ein einziges Risiko eines Punktausfalls.
Nach der Datenanalyse liest das Bestellsystem normalerweise mehr und schreibt weniger. Um heiße Abfragedaten zu teilen und die DB-Last zu reduzieren, ist die Einführung des Caches, wie in Abbildung 3.1 dargestellt, der Fall Wenn zwischengespeicherte Daten vorhanden sind, wird das Ergebnis direkt zurückgegeben. Wenn sich kein Treffer im Cache befindet, werden die DB-Ergebnisdaten gemäß der Konfigurationsrichtlinie überprüft , werden die DB-Daten zur späteren Abfrageverwendung in den Cache geschrieben, andernfalls werden sie nicht in den Cache geschrieben. Geben Sie schließlich DB-Abfrageergebnisse zurück.

Abbildung 3.1 Grunddesign des Auftragscaches
Bezüglich des Hardware-Overheads nach der Einführung neuer Cache-Komponenten können die Gesamtkosten durch die Konvergenz der ursprünglich verstreuten Hardwareressourcen jeder Anwendung reduziert werden, es wird jedoch auch Probleme bei der Benutzerfreundlichkeit mit sich bringen Zentralisierte Verwaltung Neben Problemen wie der Datenkonsistenz ist es notwendig, die Kapazitätsbewertung, die Verkehrsschätzung und die Analyse der Cache-Tabellenwerte vollständig auf dem vorhandenen System durchzuführen. Nur Hot-Data-Tabellen mit hohem Zugriffsvolumen zwischenspeichern. Durch geeignete Cache-Strukturdesign-, Datenkomprimierungs- und Cache-Eliminierungsstrategien können wir die Cache-Trefferquote maximieren und einen guten Kompromiss zwischen Cache-Kapazität, Hardwarekosten und Verfügbarkeit erzielen.
Das traditionelle Cache-Design besteht darin, dass ein Datenbanktabellendatensatz einem Cache-Datenelement entspricht. Im Bestellsystem ist es sehr üblich, mehrere Tabellen für eine Bestellung abzufragen. Wenn ein traditionelles Design übernommen wird, steigt die Anzahl der Redis-Zugriffe in einer Benutzerabfrage mit der Anzahl der Tabellen. Dieses Design hat große Netzwerk-IOs und ist zeitaufwändig. aufwändig. Bei der Bestandsaufnahme der Tabellendimensions-Verkehrsdaten haben wir festgestellt, dass einige Tabellen häufig zusammen abgefragt werden und weniger als 30 % der Tabellen mehr als 90 % des Abfrageverkehrs ausmachen. Aus geschäftlicher Sicht können sie gleich aufgeteilt werden Abstraktes Domänenmodell und dann basierend auf der Hash-Struktur gespeichert, wie in Abbildung 3.2, wobei die Bestellnummer als Schlüssel, der Feldname als Feld und die Felddaten als Wert verwendet werden.
Auf diese Weise muss jede Bestellung nur einmal auf Redis zugreifen, unabhängig davon, ob es sich um eine einzelne Tabelle oder eine Abfrage mit mehreren Tabellen handelt, was nicht nur den Schlüssel reduziert, sondern auch die Anzahl der Abfragen mit mehreren Tabellen verringert und die Leistung verbessert. Gleichzeitig wird der Wert basierend auf Protostuff komprimiert, was auch den Speicherplatz von Redis und den daraus resultierenden Netzwerkverkehrs-Overhead reduziert.

Abbildung 3.2 Kurze Beschreibung der domänenbasierten Speicherstruktur
2. Verlustfreier Migrationsprozess
Wie man eine verlustfreie Hot-Migration erreicht, ist der anspruchsvollste Teil des gesamten Projekts. Unsere Vorarbeit besteht darin, zunächst die Entwicklung der Middleware abzuschließen, mit dem Ziel, Datenbank- und Business-Layer-Anwendungen zu trennen, damit das Prozessdesign durchgeführt werden kann. Zweitens implementiert die abstrakte Dao-Schicht die Domänenisierung und die Datendomänenschicht stellt Datendienste für Anwendungen bereit. Unter der Domäne werden zwei Datenbanken, SQLServer und MySQL, einheitlich angepasst und verpackt. Auf dieser Basis kann eine verlustfreie thermische Migration für die folgende Prozessgestaltung umgesetzt werden.
SQLServer- und MySQL-Dualdatenbanken sind online und implementieren duales Schreiben, primäres Schreiben von SQLServer und synchrones sekundäres Schreiben von MySQL. Wenn der SQLServer-Vorgang fehlschlägt, schlägt der gesamte Vorgang fehl und die doppelte Schreibtransaktion wird zurückgesetzt.
Ein Synchronisierungsjob wird zwischen SQLServer und MySQL hinzugefügt, um die im letzten Zeitfenster von SQLServer geänderten Daten in Echtzeit abzufragen und die Konsistenz der Einträge in MySQL zu überprüfen. Die Unterschiede können zurückverfolgt werden, um sicherzustellen, dass unerwartete Inkonsistenzen zwischen den Zwei Seiten beim doppelten Schreiben können sichergestellt werden, insbesondere wenn noch eine direkte Verbindung zum Schreiben von SQL Server-Anwendungen besteht.
Die Middleware ist mit einem Konfigurationssystem ausgestattet, das alle wichtigen Abfragedimensionen unterstützt und die Datenquelle entsprechend der Konfiguration genau an SQLServer oder MySQL weiterleiten und steuern kann, ob sie nach dem Lesen in den Auftragscache geladen werden soll. Die Anfangseinstellung besteht darin, nur die SQLServer-Datenquelle zu laden, um Cache-Datensprünge zu vermeiden, die durch Dateninkonsistenzen zwischen den beiden Datenbanken verursacht werden. In der Anfangsphase können Graustufen eingerichtet und eine kleine Anzahl nicht zum Kern gehörender Tabellen zur Überprüfung direkt mit MySQL verbunden werden, um die Zuverlässigkeit sicherzustellen. Sobald die Erwartung einer späten Datenkonsistenz erreicht ist, kann der Auftragscache nach Belieben in die angegebene Datenbank geladen werden.
Nachdem die Datenkonsistenz beim Abfragen von Daten sichergestellt wurde, unterstützt die Verkehrsrichtlinie das einzelne Schreiben in die Datenbank gemäß jeder steuerbaren Dimension in Abbildung 3.3. In tatsächlichen Projekten wird Single-Write hauptsächlich in Tabellendimensionen implementiert. Wenn eine bestimmte Tabelle mit Single-Write-MySQL konfiguriert wird, werden alle CRUD-Verhaltensweisen, die die Tabelle betreffen, an MySQL weitergeleitet, einschließlich der Cache-Ladequelle.
Schließlich werden die nach außen gesendeten Bestellnachrichten über die Middleware vereinheitlicht. Alle Nachrichten basieren auf der CUD-Operation der Middleware und haben nichts mit der physischen Datenbank zu tun Die Nachricht ist transparent, alle oben genannten Prozessvorgänge können verknüpft werden und die Datenkette bleibt konsistent.
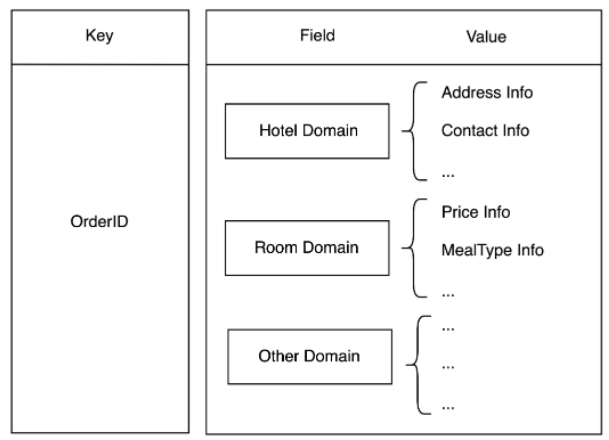
Abbildung 3.3 Einführung in den Betriebsprozess
3. Data-Warehouse-Verbindung
Um das Verständnis der Migration von Produktionsdaten in die ODS-Schichtdaten des Data Warehouse zu erleichtern und für die transparent zu machen Nachfolgend finden Sie eine kurze Einführung in die Klassifizierung herkömmlicher Data Warehouse-Schichtsysteme. Normalerweise ist das Data Warehouse hauptsächlich in fünf Schichten unterteilt: ODS (Originaldatenschicht), DIM (Dimension), EDW (Enterprise Data Warehouse), CDM (Common Model Layer), ADM (Application Model Layer), wie in der folgenden Abbildung dargestellt :
Abbildung 3.4 Hierarchische Struktur des Data Warehouse
Wie aus Abbildung 3.4 ersichtlich ist, ist jede Schicht des Data Warehouse auf die Daten der ODS-Schicht angewiesen. Um nicht alle Anwendungen der Datenplattform zu beeinträchtigen, müssen wir diese nur übertragen Ursprüngliche Auftragsdatenbank, ODS-Layer-Datenquelle von SQL Server. Migrieren Sie einfach in die MySQL-Bibliothek.
Auf dem Bild ist intuitiv zu erkennen, dass die Migration nur durch Ändern der Datenquelle nicht sehr mühsam ist. Um die Datenqualität sicherzustellen, haben wir jedoch viele Vorarbeiten durchgeführt, wie zum Beispiel: DBA synchronisiert Senden Sie die Produktionsdaten an die Produktions-MySQL-Datenbank, MySQL im Voraus Echtzeit-Datensynchronisation, Überprüfung der Datenkonsistenz auf beiden Seiten der Produktion, Synchronisierung der MySQL-Seitendaten mit der ODS-Schicht, Überprüfung der Datenkonsistenz der ODS-Schicht und ursprüngliche ODS-Schicht-Synchronisierungsauftragsdatenquelle Umschalten usw.
Unter diesen sind die Datenkonsistenzprüfung auf beiden Seiten der Produktion und die Datenkonsistenzprüfung auf der ODS-Schicht des Data Warehouse am komplexesten und zeitaufwändigsten. Die Datenquelle muss nur dann gewechselt werden, wenn jede Tabelle und jedes Feld muss konsequent sein. Im tatsächlichen Betrieb kann es jedoch nicht vollständig konsistent sein. Behandeln Sie entsprechend der tatsächlichen Situation den Zeittyp, die Genauigkeit des Gleitkommawerts, die Dezimalstellen usw. entsprechend.
Das Folgende ist eine Einführung in den Gesamtprozess:
Zunächst haben wir für die Online-Datenkonsistenzüberprüfung einen Online-Synchronisationsjob entwickelt, um die SQLServer-Daten und MySQL-Daten zu vergleichen Die Daten werden als Basis aktualisiert, um die Konsistenz der Daten auf beiden Seiten sicherzustellen.
Zweitens haben wir für die Offline-Datenkonsistenzüberprüfung mit Data-Warehouse-Kollegen zusammengearbeitet, um die MySQL-Seitendaten mit der ODS-Schicht zu synchronisieren (verwenden Sie den Datenbanknamen, um zu unterscheiden, ob es sich um einen SQLServer oder eine MySQL-Tabelle handelt) und die geplanten Aufgaben und SQLServer zu platzieren Nebenaufgaben in Versuchen Sie, zeitlich konsistent zu sein. Nachdem die Daten auf beiden Seiten vorbereitet waren, entwickelten wir einen Offline-Datenverifizierungsskriptgenerator. Basierend auf den Data Warehouse-Metadaten wurde für jede Tabelle ein Synchronisierungsauftrag generiert und auf der Planungsplattform bereitgestellt.
Die Synchronisierungsaufgabe basiert auf den Synchronisierungsdaten der ODS-Schichten auf beiden Seiten. Nach Abschluss der T+1-Datensynchronisierung wird eine Konsistenzprüfung durchgeführt und die inkonsistenten Bestellnummern in der inkonsistenten Detailtabelle aufgezeichnet Die Menge der inkonsistenten Daten wird gezählt und die Ergebnisse werden in der Statistiktabelle gespeichert. Anschließend erstellen wir einen Bericht auf der Self-Service-Berichtsplattform und senden die täglichen Statistiken der inkonsistenten Tabellen und der Anzahl der Inkonsistenzen an das Postfach. Wir beheben täglich die inkonsistenten Tabellen, um Probleme zu finden, passen die Vergleichsstrategie an und aktualisieren den Vergleich Arbeit. Der allgemeine Prozess ist wie folgt:
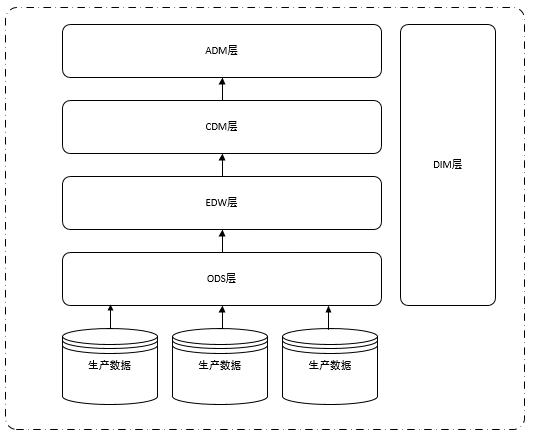
Abbildung 3.5 Der gesamte Prozess der Konsistenzüberprüfung
Abschließend, als die Online- und Offline-Daten allmählich konsistent werden, haben wir die Datenquelle, die der ursprüngliche SQLServer mit der ODS-Schicht synchronisiert hat, auf MySQL umgestellt . Einige Studenten hier haben möglicherweise Fragen: Warum nicht direkt die Tabellen in der ODS-Schicht auf der MySQL-Seite verwenden? Der Grund dafür ist, dass es laut Statistik Tausende von Jobs gibt, die auf der ursprünglichen ODS-Schichttabelle basieren. Wenn der abhängige Job auf die ODS-Tabelle auf der MySQL-Seite umgestellt wird, ist der Änderungsaufwand sehr hoch, sodass wir direkt auf die ursprüngliche ODS umsteigen Layer-Synchronisationsdatenquelle in MySQL.
Im tatsächlichen Betrieb können wir die Datenquellen nicht alle auf einmal ausschneiden. Wir finden zunächst ein Dutzend weniger wichtiger Tabellen als den ersten Stapel, führen ihn dann zwei Wochen lang aus und sammeln ihn Daten. Die erste Probencharge wurde zwei Wochen später erfolgreich analysiert und wir erhielten keine Datenprobleme in nachgelagerten Berichten, was die Zuverlässigkeit der Probendatenqualität beweist. Teilen Sie dann die verbleibenden Hunderte von Tischen entsprechend ihrer Bedeutung in zwei Stapel auf und schneiden Sie weiter, bis sie fertig sind.
Zu diesem Zeitpunkt haben wir die Migration der Bestelldatenbank von SQLServer zu MySQL auf der Data-Warehouse-Ebene abgeschlossen.
4. Verfeinerte Kernthemen
Egal wie gründlich die Analyse und das Design sind, es ist unvermeidlich, während des Ausführungsprozesses auf verschiedene Herausforderungen zu stoßen. Wir haben einige klassische Probleme zusammengefasst. Obwohl diese großen und kleinen Probleme endlich mit technischen Mitteln gelöst und die Ziele erreicht wurden, glaube ich, dass Sie als Leser bessere Lösungen finden müssen. Wir freuen uns, gemeinsam zu lernen und Fortschritte zu machen.
1. Wie man die Migration von SQLServer und MySQL differenziert überwacht. Das Bestellsystem umfasst eine große Anzahl von Anwendungen und Tabellen. Eine Anwendung entspricht 1 bis n Anwendungen Typisch ist, dass es viele-zu-viele-Beziehungen gibt. Wie in Abbildung 4.1 dargestellt, ist für Anwendungen der oberen Ebene beim Wechsel von einer SQLServer-Datenbank zu einer anderen MySQL-Datenbank der grundlegende Prozess entsprechend dem Kapitel zum Betriebsprozess in mindestens die folgenden Schritte unterteilt:
- Von Single-Write-SQLServer zum Dual-Write-SQLServer und MySQL
- Vom Single-Read-SQLServer zum Single-Read-MySQL
- Vom Dual-Write-SQLServer und MySQL zum Single-Write-MySQL
- Offline-SQLServer
 Abbildung 4.1 Beziehungsdiagramm zwischen Anwendung und Datenbank und Tabellen
Abbildung 4.1 Beziehungsdiagramm zwischen Anwendung und Datenbank und Tabellen
Das Ersetzen des Datenbanksystems in der Produktionsumgebung ist wie ein Reifenwechsel auf der Autobahn, ohne anzuhalten. Die ursprüngliche Geschwindigkeit muss beibehalten werden und ist für den Benutzer unempfindlich, da sonst keine Konsequenzen auftreten können vorgestellt.
Im Umschaltprozess sind die Prozesse Doppelschreiben, Einzellesen und Einzelschreiben ineinandergreifend und Schritt für Schritt voneinander abhängig. Als unterstützende Methode zur Designüberwachung muss vor dem Fortfahren bestätigt werden, dass der vorherige Vorgang den erwarteten Effekt erzielt der nächste. Wenn Sie überspringen oder vorschnell mit dem nächsten Schritt fortfahren, ohne sauber zu wechseln, z. B. wenn Sie mit dem Lesen von MySQL-Daten beginnen, bevor der Doppelschreibvorgang vollständig konsistent ist, kann dies dazu führen, dass keine Daten oder fehlerhafte Daten gefunden werden! Dann ist es notwendig, das Lesen und Schreiben jedes CRUD-Vorgangs zu überwachen und während des Migrationsprozesses eine visuelle 360-Grad-Verkehrssegmentierungskontrolle ohne blinde Flecken zu erreichen. Die spezifische Methode ist wie folgt:
Alle Anwendungen sind mit der Middleware verbunden, und CRUD wird von der Middleware gesteuert, um entsprechend der Konfiguration zu lesen und zu schreiben, welche Datenbank und welche Tabelle.
Die detaillierten Informationen zu jedem Lesevorgang und der Schreibvorgang wird in ES geschrieben, in der visuellen Anzeige auf Kibana und Grafana, und über DBTrace können Sie wissen, auf welcher DB jedes SQL ausgeführt wird
Schritt-für-Schritt-Konfiguration der Dual-Write-DB entsprechend der Anwendungsebene; Echtzeitvergleich, Reparatur und Aufzeichnung der DB-Unterschiede auf beiden Seiten durch Synchronisierungsjobs und anschließende Überprüfung der endgültigen Inkonsistenz beim Doppelschreiben durch Offline-T+1 usw., bis das Doppelschreiben konsistent ist Doppeltes Schreiben ist konsistent, beginnen Sie schrittweise vom Lesen von SQLServer zum Lesen von MySQL und bestätigen Sie dies durch ES-Überwachung und DBTrace. Wenn überhaupt kein SQLServer-Lesen erfolgt, bedeutet dies, dass das einzelne Lesen von MySQL abgeschlossen ist. Beim Erhöhen des Primärschlüssels übernehmen wir die Methode, das Schreiben in SQLServer stapelweise entsprechend der Tabellendimension zu unterbrechen, bis alle Tabellen allein in MySQL geschrieben sind.
Zusammenfassend lässt sich sagen, dass die grundlegende Lösung darin besteht, Middleware als Pipeline zu verwenden, um alle Anwendungen, auf die zugegriffen wird, auf einheitliche Weise zu vergraben, die Verkehrsverteilung zu beobachten, indem das Verhalten der Anwendungsschicht in Echtzeit angezeigt wird, und die Anwendung mit zu überprüfen Das Visualisierungstool von Trace auf der Datenbankseite des Unternehmens stimmt mit den tatsächlichen QPS- und Lastschwankungen der Datenbank überein, um die Migrationsaufgabe zu überwachen.
2. So lösen Sie das DB-Konsistenzproblem beim Doppelschreiben
Die Bestelldatenbank des Hotels hat eine Geschichte von etwa zwanzig Jahren. Im Laufe der Jahre verlassen sich mehrere Teams abteilungsübergreifend und innerhalb des Hotels direkt oder indirekt auf die Bestelldatenbank SQLServer. Wenn Sie zu MySQL wechseln möchten, müssen Sie zunächst das Problem der DB-Konsistenz beim doppelten Schreiben lösen. Die Inkonsistenz spiegelt sich hauptsächlich in den folgenden zwei Punkten wider:
Beim doppelten Schreiben wird tatsächlich nur SQLServer geschrieben, weggelassen MySQL;
Das Doppelschreiben von SQLServer und MySQL ist erfolgreich, wenn Parallelität, unzuverlässiges Netzwerk, GC usw. auftreten, sind MySQL-Daten möglicherweise nicht mit SQL Server konsistent.
Im Hinblick auf die Gewährleistung der Datenkonsistenz beim doppelten Schreiben verwenden wir den Synchronisierungsjob, um die SQLServer-Daten basierend auf der letzten Aktualisierungszeit abzugleichen. Wenn sie inkonsistent sind, reparieren wir sie die MySQL-Daten und speichern Sie die inkonsistenten Informationen. Schreiben Sie sie zur anschließenden Fehlerbehebung der Grundursache.
Aber die Einführung zusätzlicher Jobs zum Bearbeiten von MySQL-Daten hat zu neuen Problemen geführt, d MySQL-Daten, was zu einem doppelten Schreibfehler führt. Wenn daher der Doppelschreibteil fehlschlägt, wird ein Failover-Mechanismus hinzugefügt, der eine neue Runde von Vergleichs- und Reparaturarbeiten auslöst, indem er Nachrichten auslöst, bis die DB-Daten auf beiden Seiten vollständig konsistent sind.
Obwohl der synchronisierte Job- und Failover-Meldungsmechanismus die Daten am Ende konsistent machen kann, gibt es doch ein Intervall der zweiten Ebene, und die Daten auf beiden Seiten sind inkonsistent. Und das ist für verschiedene Szenarien vieler Anwendungen unvermeidlich Beim alleinigen Schreiben von SQL Server kommt es zu Auslassungen. Diese verpassten Schreibvorgänge in MySQL können über DBTrace nicht gefunden werden, da nicht festgestellt werden kann, dass ein CUD-Vorgang nur in SQLServer und nicht in MySQL geschrieben wird. Gibt es also eine Möglichkeit, das Szenario des fehlenden MySQL im Voraus herauszufinden? Wir haben eines herausgefunden: Ändern Sie die Datenbankverbindungszeichenfolge, verwenden Sie die neue Verbindungszeichenfolge für die mit der Middleware verbundene Anwendung und finden Sie dann alles heraus Vorgänge, die die alte Verbindungszeichenfolge verwenden, können den Datenverkehr, der MySQL verfehlt, genau lokalisieren.
Am Ende haben wir die DB-Inkonsistenzrate bei doppeltem Schreiben schrittweise von 2/100.000 auf fast 0 reduziert. Warum sind die Daten aufgrund einiger Unterschiede in den DB-Eigenschaften natürlich inkonsistent? . Es wird eine ausführliche Diskussion geben.
3. Umgang mit dem durch die Einführung des Auftrags-Caching verursachten Daten-Out-of-Synchronisationsproblem
Nach der Einführung des Caches ist das Schreiben oder Aktualisieren des Caches wie folgt:
Schreiben Zuerst in die DB schreiben und dann den Cache schreiben.
Zuerst den Cache schreiben und dann die DB schreiben Aufgrund der Nachteile verschiedener Methoden kann es in bestimmten Implementierungen möglich sein, einen Double-Delete-Cache oder einen verzögerten Double-Delete-Cache zu verwenden. Wir wenden ein Schema an, bei dem zuerst in die Datenbank geschrieben und dann der Cache gelöscht wird. Bei datensensiblen Tabellen wird eine verzögerte doppelte Löschung durchgeführt. Der Hintergrundsynchronisierungsjob vergleicht, repariert und zeichnet die Unterschiede zwischen den Datenbankdaten und den Redis-Daten auf. Obwohl das Design die endgültige Konsistenz gewährleisten kann, gab es in der Anfangsphase immer noch viele Dateninkonsistenzen. Dies spiegelt sich hauptsächlich in den folgenden Aspekten wider:
Es gibt Szenarien, in denen die Anwendung nicht mit der Middleware verbunden ist und der Cache nach dem Ausführen von CUD-Vorgängen in der Datenbank nicht gelöscht wird.
Die Cache-Löschverzögerung nach dem Schreiben in die Die Datenbank führt zum Beispiel dazu, dass unzuverlässige Netzwerke, GC usw. den Cache löschen, nachdem die Datenbank geschrieben wurde, was zum Beispiel beim Redis-Master-Slave-Wechsel zur Folge hat , es kann nur gelesen, aber nicht geschrieben werden.
Um das Cache-Konsistenzproblem zu lösen, wie in Abbildung 4.2 dargestellt, haben wir optimistische Sperren und CUD-Konstruktionsmarkierungen basierend auf dem ursprünglichen Cache und der DB hinzugefügt, um das Verhalten beim Laden von Daten in den Cache zu begrenzen, die sich in gleichzeitigen Situationen überlappen. Und die Kenntnis der CUD-Operation, die derzeit an den überprüften Daten ausgeführt wird. Der auf optimistischer Sperrung basierende Last-Writer-Gewinnmechanismus kann verwendet werden, um den Abfrageverkehr so zu realisieren, dass er eine direkte Verbindung zur Datenbank herstellt und das Wettbewerbsproblem löst, wenn diese beiden Szenarien nicht abgeschlossen sind. Am Ende wurde unsere Cache-Inkonsistenzrate von 2 Teilen pro Million auf 3 Teile pro 10 Millionen kontrolliert.

Abbildung 4.2 Cache-Konsistenzlösung
Abbildung 4.2 Wenn die Abfrage den Cache verfehlt oder derzeit eine optimistische Sperre oder Konstruktionsmarkierung für die Daten vorliegt, wird die Abfrage direkt mit der Datenbank verbunden, bis die zwischengespeicherten Daten anschließend freigegeben werden Die entsprechende Transaktion ist abgeschlossen.
4. So kalibrieren Sie die vorhandenen Auftragsdaten auf einmal
Zu Beginn des Projekts führten wir eine einmalige Aufbereitung der Daten der letzten N Jahre für MySQL durch, was zu den folgenden zwei Datenszenarien führte kann in der Double-Write-Phase nicht kalibriert werden:
Da die Produktionsauftragsdatenbank so voreingestellt ist, dass sie Daten von fast N Jahren speichert, bevor der Job, der für die Bereinigung des Backups verantwortlich ist, mit der Middleware verbunden wird, werden die Daten gespeichert, die in MySQL vorhanden waren für N Jahre kann von der Police nicht überschrieben und bereinigt werden.
Es dauert lange, die Verbindungs-Middleware anzuwenden. Die Daten sind möglicherweise inkonsistent, bevor die Middleware doppelt geschrieben wird. Nachdem die gesamte Verbindungs-Middleware angewendet wurde und alle Tabellen doppelt geschrieben sind, müssen die vorherigen Daten sofort repariert werden -geschrieben.
Für den ersten Punkt haben wir einen MySQL-Datenbereinigungsjob entwickelt. Da die Auftragsdatenbank über mehrere Shards verfügt, wird die Gesamtzahl der Kernthreads intern im Job basierend auf der tatsächlichen Anzahl der Shards festgelegt, für die jeder Thread verantwortlich ist Führen Sie zur Bereinigung mehrere Server parallel aus, um die Bereinigungsaufgaben zu verteilen, ohne die Auslastung der Produktionsdatenbank zu beeinträchtigen.
Zum zweiten Punkt können die vorhandenen Auftragsdaten repariert werden, nachdem die gesamte Anwendungsverbindungs-Middleware und alle Tabellen doppelt geschrieben wurden, indem der Startzeitstempel des Online-Synchronisierungsauftragsscans angepasst wird. Bei der Reparatur sollte besonders darauf geachtet werden, dass die gescannten Daten in Slices nach Zeiträumen verarbeitet werden müssen, um zu verhindern, dass zu viele Daten geladen werden und die CPU des Auftragsdatenbankservers zu hoch wird.
5. Einige Probleme mit Datenbankfunktionsunterschieden
Wenn wir eine Live-Migration von Datenbanken in einem großen System durchführen möchten, müssen wir ein tiefes Verständnis für die Ähnlichkeiten und Unterschiede zwischen verschiedenen Datenbanken haben, damit wir das Problem effektiv lösen können. Obwohl MySQL und SQL Server beide beliebte relationale Datenbanken sind und standardisierte SQL-Abfragen unterstützen, gibt es dennoch einige Unterschiede im Detail. Schauen wir uns die Probleme bei der Migration genauer an.
1) Problem mit dem Schlüssel mit automatischer Inkrementierung
Um ein noch größeres Risiko einer Datenreparatur durch inkonsistente Seriennummern mit automatischer Inkrementierung zu vermeiden, sollten Sie sicherstellen, dass die beiden Datenbanken dieselbe Seriennummer mit automatischer Inkrementierung verwenden. Daher sollte es nicht jedem gestattet sein, automatische Inkrementierungsvorgänge durchzuführen. Wenn Daten doppelt geschrieben werden, schreiben wir daher die von SQLServer generierte Auto-Inkrement-ID zurück in die MySQL-Auto-Inkrement-Spalte. Wenn Daten nur in MySQL geschrieben werden, wird MySQL verwendet, um den Auto-Inkrement-ID-Wert direkt zu generieren.
2) Problem mit der Datumsgenauigkeit
Um die Datenkonsistenz nach dem doppelten Schreiben sicherzustellen, muss auf beiden Seiten der Daten eine Konsistenzüberprüfung durchgeführt werden. Felder vom Typ Datum, Datum/Uhrzeit und Zeitstempel werden aufgrund der inkonsistenten Speichergenauigkeit nicht durchgeführt Beim Vergleich ist eine spezielle Verarbeitung erforderlich, bei der zum Vergleich Sekunden herangezogen werden.
3) XML-Feldproblem
Der XML-Datentyp wird in SQL Server unterstützt, MySQL 5.7 unterstützt den XML-Typ jedoch nicht. Nachdem ich stattdessen varchar(4000) verwendet hatte, stieß ich auf einen Fall, in dem das Schreiben der MySQL-Daten fehlschlug, der Synchronisierungsjob die SQLServer-Daten jedoch normal zurück nach MySQL schreiben konnte. Nach der Analyse schreibt das Programm beim Schreiben unkomprimierte XML-Zeichenfolgen automatisch, MySQL jedoch nicht. Daher schlägt der Schreibvorgang mit einer Länge von mehr als 4000 fehl und die Länge nach der SQLServer-Komprimierung ist kleiner als 4000. und kann normal in MySQL zurückschreiben. Zu diesem Zweck schlagen wir Gegenmaßnahmen vor, darunter das Komprimieren und Überprüfen der Länge vor dem Schreiben, das Abfangen unwichtiger Felder vor dem Speichern, das Optimieren der Speicherstruktur wichtiger Felder oder das Ändern von Feldtypen.
Im Folgenden sind einige allgemeine Punkte aufgeführt, die Sie während des Migrationsprozesses beachten sollten.

5. Frühwarnpraxis
Unsere Frühwarnpraxis beschränkt sich nicht auf die Überwachung von Anforderungen während des Projektfortschritts, wie man regelmäßig Anomalien beim Schreiben von Daten in Dutzenden von Milliarden Daten scannt und die Datenkonsistenzrate beim doppelten Schreiben während des Projekts vervollständigt Auf den folgenden Seiten wird beschrieben, wie Sie den normalen Trend des Auftragsschreibvolumens auf jedem Shard der Auftragsbibliothek in Echtzeit überwachen und alarmieren und wie Sie regelmäßig die Hochverfügbarkeit des gesamten Systems akzeptieren/überprüfen.
1. Warnung vor zig Milliarden Datenunterschieden
Um die Anforderungen der Auftragsdatenmigration von SQLServer zur MySQL-Datenbank zu erfüllen, ist die Datenqualität eine notwendige Voraussetzung für die Migration. Wenn die Datenkonsistenz die Anforderungen nicht erfüllt, ist dies bei einer transparenten Migration nicht der Fall möglich sein, so dass eine angemessene Überprüfung erfolgen kann. Der Plan hängt vom Fortschritt der Migration ab. Für die Datenüberprüfung unterteilen wir sie in zwei Typen: Online und Offline:
Online-Datenüberprüfung und Frühwarnung
Während der Migration haben wir den Job synchronisiert, die inkonsistenten Daten berechnet, die inkonsistenten Tabellen und Felder in ElasticSearch geschrieben und dann mit Kibana ein Überwachungs-Dashboard der Menge inkonsistenter Daten und des Anteils inkonsistenter Tabellen erstellt Mit dem Überwachungs-Dashboard können wir in Echtzeit überwachen, welche Tabellen hohe Dateninkonsistenzen aufweisen, und dann mithilfe von DBA-Tools anhand der Tabellennamen herausfinden, welche Anwendungen CUD-Vorgänge für die Tabellen ausgeführt haben, und außerdem Anwendungen und Codes lokalisieren, bei denen Middleware fehlt .
Im tatsächlichen Betrieb haben wir eine große Anzahl von Anwendungen gefunden, die nicht mit der Middleware verbunden waren, und diese transformiert. Da immer mehr Anwendungen mit der Middleware verbunden sind, verbessert sich die Datenkonsistenz allmählich Auch die Menge nahm allmählich ab. Die Konsistenz wurde jedoch nie auf Null reduziert. Der Grund liegt in der Parallelität von Anwendungen und Synchronisationsjobs. Dies ist auch das problematischste Problem.
Vielleicht fragen sich einige Schüler, warum sie den Synchronisierungsvorgang nicht stoppen sollten, da doppelt geschrieben wird. Der Grund dafür ist, dass SQL Server die Hauptschreibmethode ist und der von der Middleware abgedeckte CUD-Bereich als Benchmark verwendet wird. Abgesehen davon, dass kein hundertprozentiger Erfolg beim Schreiben von Daten in MySQL garantiert wird, gibt es auch keine Garantie dafür, dass die Datenmenge in der zwei Datenbanken sind gleich, daher ist ein konsistenter Job erforderlich. Obwohl die Daten nicht vollständig konsistent sein können, können Inkonsistenzen durch gleichzeitige Verarbeitung weiter reduziert werden.
Unser Ansatz besteht darin, beim Vergleichen von Konsistenzjobs eine 5-Sekunden-Stabilitätslinie festzulegen (d. h. Daten innerhalb von 5 Sekunden nach der aktuellen Zeit gelten als instabile Daten. Zeitstempel innerhalb der Stabilitätslinie werden nicht verglichen und sind stabil). Beim Vergleich außerhalb der Linie wird erneut berechnet, ob die Auftragsdaten innerhalb der stabilen Linie liegen. Wenn bestätigt wird, dass alle Daten außerhalb der stabilen Linie liegen, wird der Vergleich abgebrochen und die Konsistenz überprüft Die Prüfung wird beim nächsten Zeitplan durchgeführt.
Offline-Datenüberprüfung und Frühwarnung
Die Migration der Bestelldatenbank umfasst Hunderte von Tabellen und eine große Menge an Offline-Daten. Die Menge an auftragsbezogenen Daten in nur einem Jahr erreicht Milliarden, was die Offline-Datenprüfung vor erhebliche Herausforderungen stellt. Wir haben einen Datenkonsistenzskriptgenerator geschrieben, um für jede Tabelle ein Vergleichsskript zu generieren und es auf der Planungsplattform bereitzustellen. Das Vergleichsskript basiert auf dem Synchronisierungsauftrag auf beiden Seiten des Upstream-SQLServers und der Daten Der Vergleich wird automatisch durchgeführt, um die inkonsistenten Daten zu vergleichen. Die Anzahl der Inkonsistenzen wird auf der Grundlage der detaillierten Tabelle berechnet, die in Form eines täglichen Berichts ausgegeben wird jeden Tag überprüft und gelöst.
Wir suchen und beheben Inkonsistenzen in der Regel kontinuierlich, einschließlich der Behebung von Problemen in Vergleichsskripten und der Überprüfung der Qualität von Offline-Daten. Die Überprüfung jedes Felds in jeder Offline-Datentabelle ist sehr kompliziert. Wir schreiben eine UDF-Funktion zum Vergleich. Die Funktion der UDF-Funktion besteht darin, die Nicht-Primärschlüsselfelder jeder Tabelle zu verbinden Neues Feld. Bei der Durchführung eines vollständigen Outer-Joins sollten auch Datensätze mit gleichen Primärschlüsseln oder logischen Primärschlüsseln neue Felder generieren. Solange sie unterschiedlich sind, werden sie als inkonsistente Daten betrachtet. Hier sollten wir auf das Abfangen von Datumsfeldern, die Datengenauigkeit und die Verarbeitung von Dezimalzahlen mit Nullen am Ende achten.
Nach mehr als drei Monaten harter Arbeit haben wir alle Anwendungen identifiziert, die nicht mit der Middleware verbunden waren, und alle ihre CUD-Vorgänge mit der Middleware verbunden. Nachdem wir Dual-Write aktiviert hatten, verbesserte sich die Konsistenz von Online- und Offline-Daten schrittweise Ziel der Datenmigration.
2. Echtzeit-Überwachung des Gesamtauftragsvolumens von ALL Shard
Jedes Unternehmen verfügt über eine einheitliche Frühwarnplattform Sitemon, die hauptsächlich verschiedene Auftragswarnungen überwacht, darunter Hotels, Flugtickets, Mobilfunk, Hoch-. Schnellbahn, Urlaub. Das System verfügt über die Funktion einer unabhängigen Suche und Anzeige basierend auf Online/Offline-, Inlands-/Auslands- und Zahlungsmethoden sowie Benachrichtigungen für alle Arten von Bestellungen.
Während der Migration der Auftragsdaten von SQL Server nach MySQL haben wir fast 200 Frühwarnstrategien aussortiert, die auf der Auftragsdatenbank basieren. Die zuständigen Kollegen, die für die Überwachung verantwortlich sind, haben eine Kopie der Frühwarnstrategien der SQL Server-Datenquelle erstellt mit der MySQL-Datenquelle verbunden. Nachdem alle Überwachungsalarme mit MySQL als Datenquelle hinzugefügt wurden, aktivieren Sie die Alarmstrategie. Sobald das Auftragsvolumen abnormal ist, erhält NOC zwei Benachrichtigungen, eine vom SQLServer-Datenalarm und eine vom MySQL-Alarm bedeutet, dass die Graustufenüberprüfung bestanden wurde. Andernfalls schlägt es fehl und das MySQL-Überwachungsproblem muss untersucht werden.
Nach einem Zeitraum der Graustufenüberprüfung sind die Alarmdaten auf beiden Seiten konsistent. Wenn die SQLServer-Datentabelle offline geht (d. h. MySQL-Daten werden alleine geschrieben), geht auch die Frühwarnstrategie mit SQLServer als Datenquelle offline Zeit.
3. Praktischer Betrieb „Wandering Earth“
Um die Systemsicherheit zu gewährleisten und die Reaktionsfähigkeit auf Notfälle zu verbessern, müssen notwendige Übungen und Stresstests durchgeführt werden. Zu diesem Zweck haben wir einen vollständigen Notfallplan entwickelt und organisieren regelmäßig Notfallübungen – The Wandering Earth. Zu den Übungselementen gehören Leistungsschalter für Kern-/Nicht-Kern-Anwendungen, DB-Leistungsschalter, Redis-Leistungsschalter, Kern-Firewall, Schalter-Notschalter usw.
Nehmen Sie das Caching als Beispiel: Um die hohe Verfügbarkeit des Cache-Dienstes sicherzustellen, werden wir während der Übung einige Knoten oder Maschinen offline schalten oder sogar den gesamten Redis-Dienst abschalten, um Cache-Lawine, Cache-Ausfall und andere Szenarien zu simulieren. Gemäß dem Plan werden wir vor der Fusion zunächst den Redis-Zugriff der Anwendung unterbrechen, die Redis-Last schrittweise reduzieren und dann Redis zusammenführen, um zu testen, ob jedes Anwendungssystem ohne Redis normal funktionieren kann.
Bei der ersten Übung, als Redis getrennt wurde, stieg die Anzahl der Anwendungsfehler stark an, sodass wir die Übung entschieden anhielten und zurückfuhren, während wir nach der Ursache des Problems suchten. Da die Redis-Vorgänge einiger Anwendungen nicht einheitlich verwaltet und nicht von der Middleware gesteuert werden, wird die Anwendung bei einem Ausfall von Redis sofort abnormal. Als Reaktion auf diese Situation haben wir den Auftragscache-Zugriffsport der Fehlerberichtsanwendung analysiert und mit der Middleware verbunden. Andererseits haben wir die schwache Abhängigkeit zwischen der Middleware und Redis gestärkt, die Trennung von Redis-Vorgängen mit einem Klick unterstützt Verbesserte Überwachung verschiedener Metriken. In der zweiten Übung war der Redis-Leistungsschalter erfolgreich und alle Geschäftssysteme liefen normal mit vollem Datenverkehrszugriff auf MySQL. Bei der letzten Übung „Wandering Earth“ erzielte unser System nach Fehlerinjektionsrunden wie der Blockierung von Computerraumnetzwerken und der Blockierung von Nicht-Kernanwendungen sehr gute erwartete Ergebnisse.
Auf diese Weise haben wir in einer Übung nach der anderen Probleme entdeckt, Erfahrungen zusammengefasst, das System optimiert, Notfallpläne verbessert, Schritt für Schritt die Fähigkeit des Systems zur Bewältigung plötzlicher Ausfälle verbessert und die Geschäftskontinuität sichergestellt und Daten der Integrität. Bieten Sie zugrunde liegende Datenunterstützung, um das gesamte Hotelbestellsystem zu schützen.
6. Zukünftige Planung
1. Bestellen Sie einen manuellen Kontrollschalter für Caches
Obwohl wir über ein vollständiges Überwachungsgremium und ein Frühwarnsystem verfügen, z Leistungsschalter, Bohrer, automatisierte Fehlerübungen, Hardwareausfälle und -wartung sowie unvorhersehbare Probleme. Wenn die Kernentwickler nicht rechtzeitig auf den Betrieb vor Ort reagieren, kann das System nicht vollständig autonom heruntergefahren werden, was zu einer gewissen Leistungseinbuße führen kann, z Reaktionszeit usw. . In Zukunft planen wir, manuelle Steuerungs-Dashboards hinzuzufügen. Nach der Autorisierung können NOC oder TS gezielte Vorgänge ausführen. Wenn beispielsweise der gesamte Redis-Cluster ausfällt, können die fehlerhaften Redis-Shards mit einem Klick abgeschnitten werden Oder basierend auf dem geplanten Nichtverfügbarkeitszeitraum von Redis. Durch die Festlegung der Schnittzeit im Voraus kann die Steuerbarkeit des Systems weitestgehend sichergestellt werden.
2. Automatisches Downgrade der Middleware
Da es manuell gesteuert werden kann, halten wir die Überwachung einiger Kernindikatoren in Zukunft, beispielsweise beim Redis-Master-Slave-Switching, für normal Bedingungen Es ist auf der zweiten Ebene, aber wir haben auch Situationen erlebt, in denen einige Redis nicht länger als 10 Sekunden geschrieben werden konnten. Zu diesem Zeitpunkt können Sie die Menge der schmutzigen Daten überwachen, die zwischen dem Cache und der Datenbank inkonsistent sind Sie können es auch anwenden, indem Sie den Schwellenwert für eine abnormale Antwortzeit überwachen, wenn Redis ausfällt. Einige Strategien ermöglichen es der Middleware, diese ausgefallenen Hosts automatisch herunterzustufen und abzuschneiden, um die grundlegende Stabilität des Dienstes sicherzustellen, und versuchen dann schrittweise, sich wiederherzustellen, nachdem der Cluster erkannt wurde Die Indikatoren sind stabil.
3. Middleware-Zugriff auf Service Mesh
Das aktuelle Auftragsteam verwendet Middleware in Form von JAR, das die zugrunde liegenden Unterschiede in der Datenbank abschirmt und Redis betreibt, um komplexere Ergebnisse zu erzielen Funktionen verfügen natürlich über die Möglichkeit, eine Verbindung zu Service Mesh herzustellen. Nach der Verbindung erfolgt das zugrunde liegende Upgrade schneller und reibungsloser, der Aufruf wird einfacher, die Grid-Integration mit dem Framework wird besser und die Cloud wird bequemer, was möglich ist Ctrips internationale strategische Ziele besser unterstützen.
Das obige ist der detaillierte Inhalt vonSo migrieren Sie das sensorlose SQL Server-System zu MySQL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!