
Heim >Datenbank >MySQL-Tutorial >So stellen Sie sicher, dass Spark SQL den Aktualisierungsvorgang beim Schreiben von MySQL unterstützt
So stellen Sie sicher, dass Spark SQL den Aktualisierungsvorgang beim Schreiben von MySQL unterstützt

- PHPznach vorne
- 2023-06-02 15:19:211929Durchsuche
Zusätzlich zur Unterstützung von „Anhängen“, „Überschreiben“, „ErrorIfExists“ und „Ignorieren“ werden auch Aktualisierungsvorgänge unterstützt Aus dem Quellcode geht hervor, dass Spark keine Aktualisierungsvorgänge unterstützt.
2. Wie man SparkSQL-Unterstützungsaktualisierungen durchführt :
dataframe.write
.format("sql.execution.customDatasource.jdbc")
.option("jdbc.driver", "com.mysql.jdbc.Driver")
.option("jdbc.url", "jdbc:mysql://localhost:3306/test?user=root&password=&useUnicode=true&characterEncoding=gbk&autoReconnect=true&failOverReadOnly=false")
.option("jdbc.db", "test")
.save()Dann verwendet Spark auf der untersten Ebene den JDBC-Dialekt JdbcDialect, um die Daten zu übersetzen, in die wir einfügen möchten:
insert into student (columns_1 , columns_2 , ...) values (? , ? , ....)
Dann wird die über den Dialekt analysierte SQL-Anweisung über die Funktion „executeBatch()“ von PrepareStatement an MySQL übermittelt die Daten werden eingefügt; 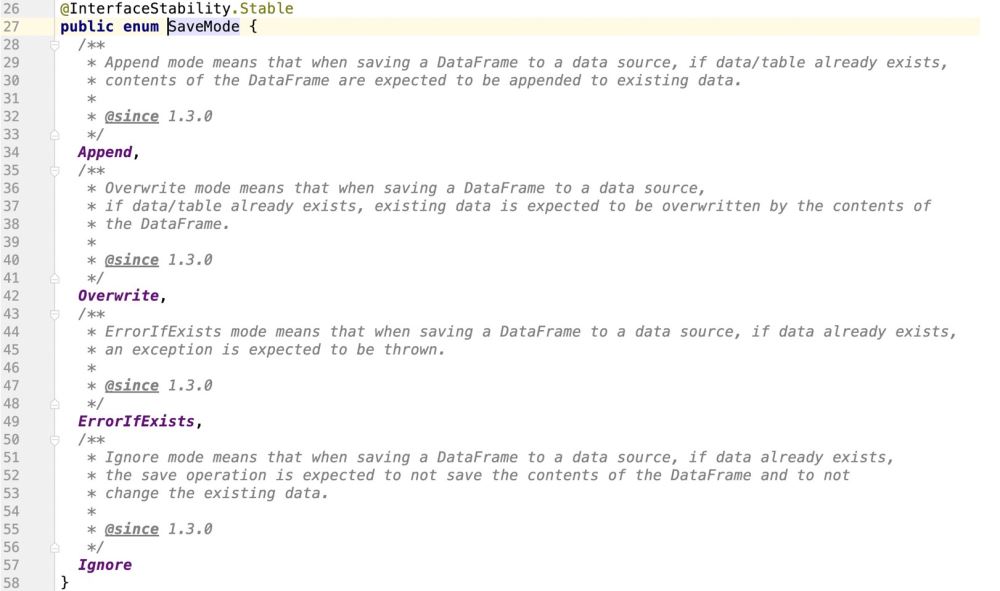
UPDATE table_name SET field1=new-value1, field2=new-value2Aber MySQL unterstützt ausschließlich eine solche SQL-Anweisung:
INSERT INTO student (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';
Die ungefähre Bedeutung Wenn die Daten nicht vorhanden sind, führen Sie den Aktualisierungsvorgang aus. Unser Fokus liegt also darauf, Spark SQL in die Lage zu versetzen, solche SQL-Anweisungen zu generieren, wenn eine interne Verbindung mit JdbcDialect besteht Um den Quellcode umzuwandeln, müssen Sie den gesamten Code-Design- und Ausführungsprozess verstehen. Zuallererst: INSERT INTO 表名称 (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';Der Aufruf der Schreibmethode bedeutet, eine Klasse zurückzugeben: DataFrameWriterHauptsächlich, weil DataFrameWriter die Eintragsklasse ist, mit der SparkSQL eine Verbindung herstellen kann an externe Datenquellen. Der folgende Inhalt wird für DataFrameWriter registriert. Tragen Sie die Informationen:
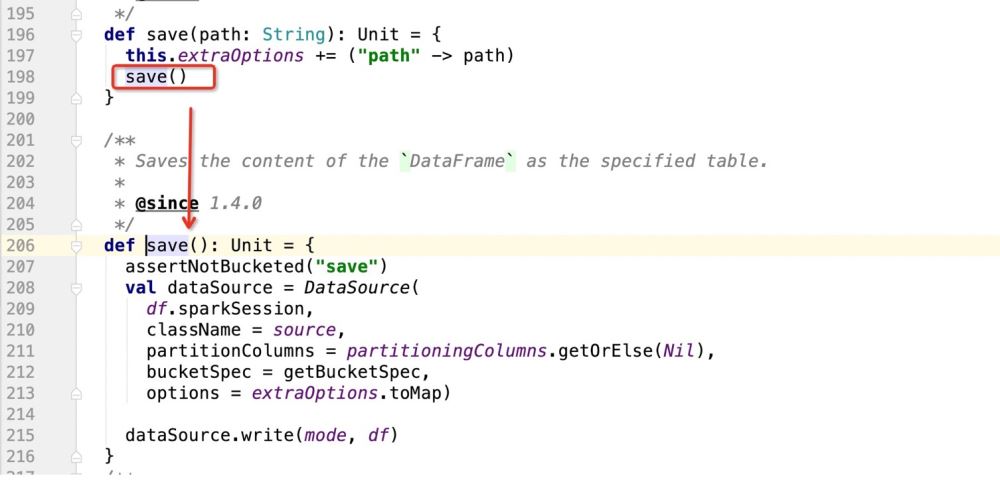
Beginnen Sie dann nach dem Starten des save()-Vorgangs mit dem Schreiben der Daten. Schauen Sie sich als nächstes den save()-Quellcode an
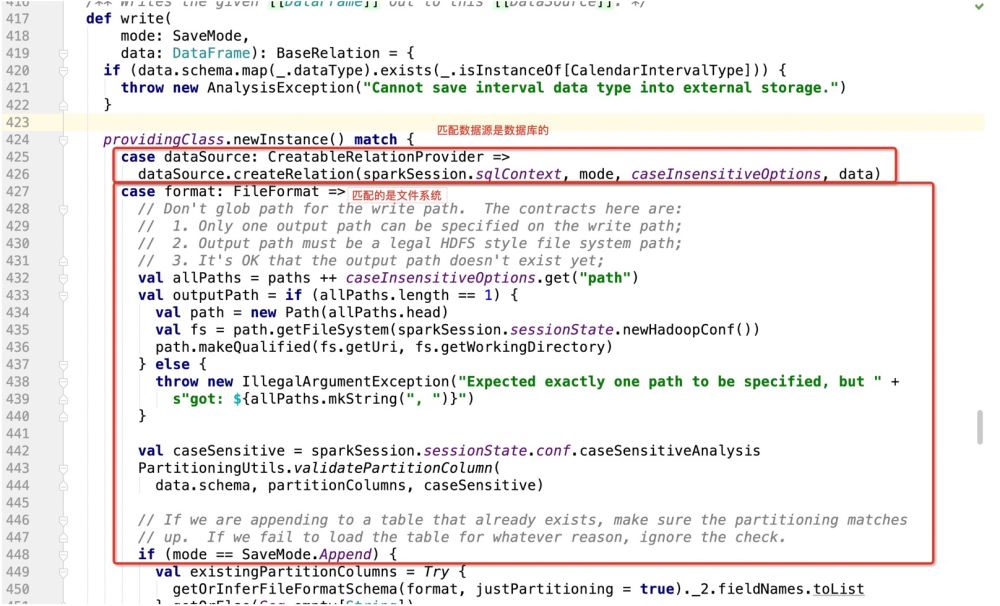
Im obigen Quellcode besteht die Hauptsache darin, die DataSource-Instanz zu registrieren und dann die Schreibmethode von DataSource zum Schreiben von Daten zu verwenden
Beim Instanziieren von DataSource:
dataframe.write
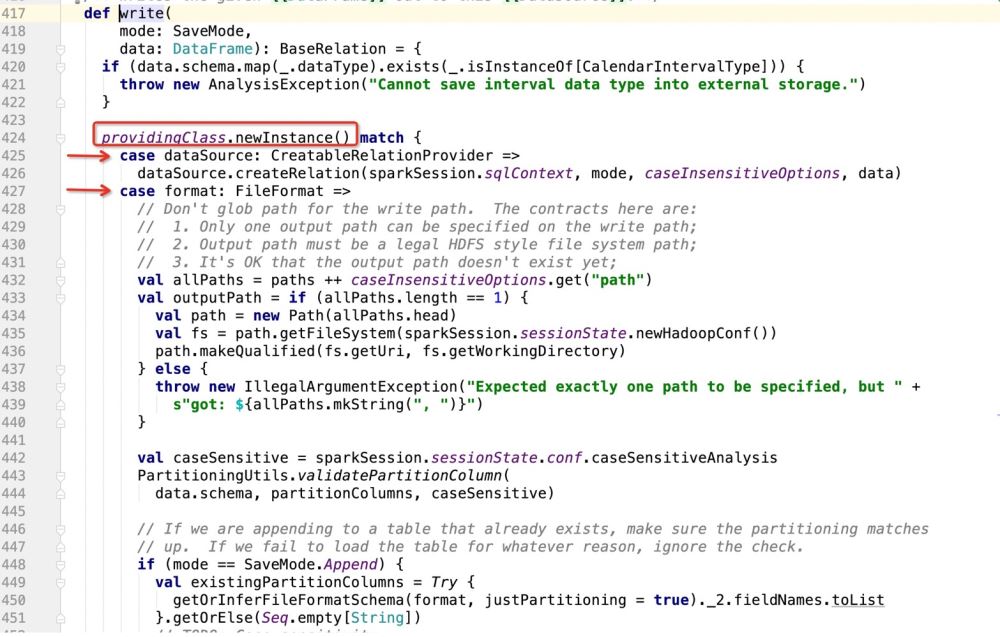
Dann gibt es die Details von dataSource.write(mode, df). Die gesamte Logik lautet:
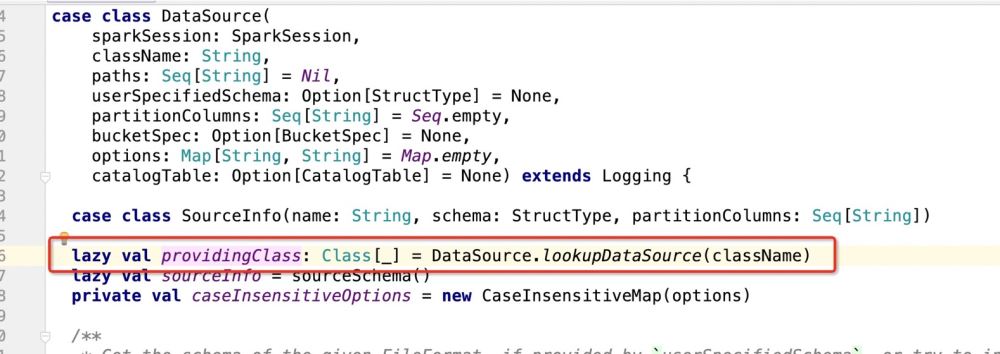
Machen Sie den Modus entsprechend der Bereitstellungsklasse.newInstance() und führen Sie dann den Code aus, wo immer er übereinstimmt. Schauen Sie sich dann an, was die Bereitstellungsklasse ist:
Nachdem das Programm den Paketpfad.DefaultSource erhalten hat, gibt es Folgendes ein: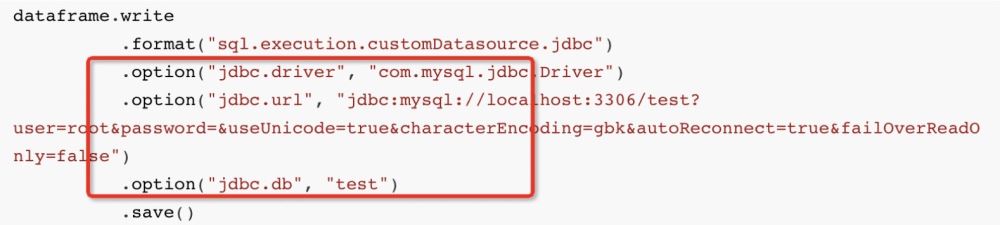
def save(): Unit = {
assertNotBucketed("save")
val dataSource = DataSource(
df.sparkSession,
className = source,//自定义数据源的包路径
partitionColumns = partitioningColumns.getOrElse(Nil),//分区字段
bucketSpec = getBucketSpec,//分桶(用于hive)
options = extraOptions.toMap)//传入的注册信息
//mode:插入数据方式SaveMode , df:要插入的数据
dataSource.write(mode, df)
} Im Quellcode der Spark Production SQL-Anweisung steht es jedoch wie folgt:
Im Quellcode der Spark Production SQL-Anweisung steht es jedoch wie folgt:
 Es gibt Keine Beurteilungslogik, die darin besteht, endlich eine zu generieren:
Es gibt Keine Beurteilungslogik, die darin besteht, endlich eine zu generieren:
if(isUpdate){
sql语句:INSERT INTO student (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';
}else{
insert into student (columns_1 , columns_2 , ...) values (? , ? , ....)
}Die erste Aufgabe besteht also darin, wie man es macht. Der aktuelle Code unterstützt: ON DUPLICATE KEY UPDATE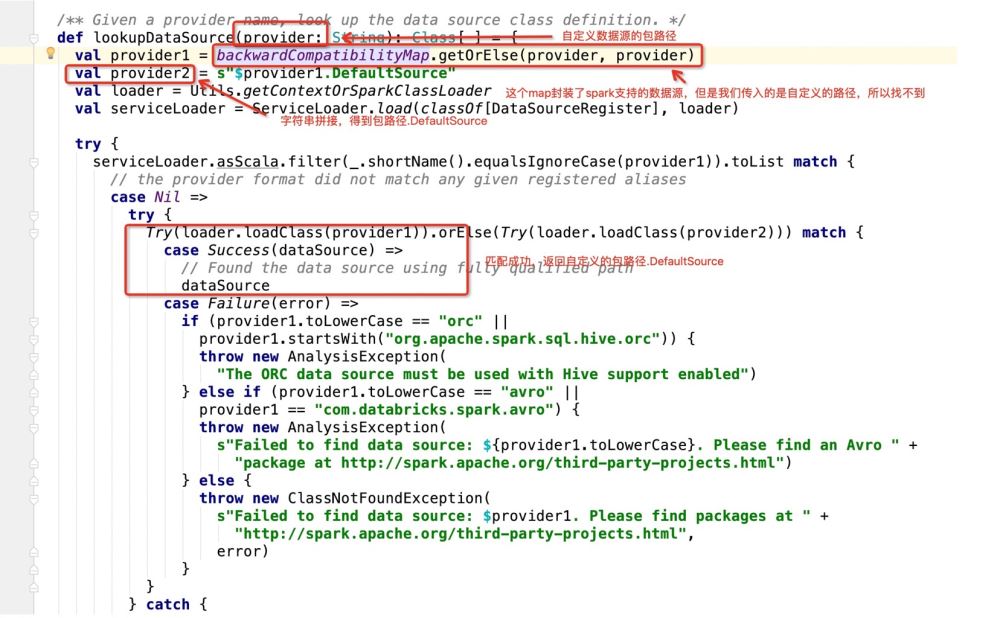
INSERT INTO TABLE (字段1 , 字段2....) VALUES (? , ? ...)Auf diese Weise führen wir im vom Benutzer übergebenen Savemode-Modus eine Überprüfung durch. Wenn es sich um einen Aktualisierungsvorgang handelt, geben wir die entsprechende SQL-Anweisung zurück!
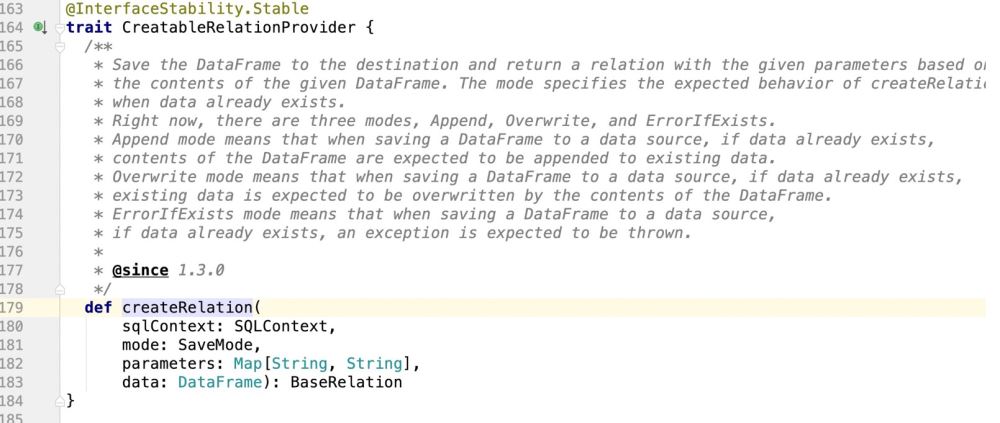
 Nach der obigen Logik ist unser Code also wie folgt geschrieben:
Nach der obigen Logik ist unser Code also wie folgt geschrieben:
 Auf diese Weise erhalten wir die entsprechende SQL-Anweisung.
Auf diese Weise erhalten wir die entsprechende SQL-Anweisung.
Aber nur diese SQL-Anweisung reicht nicht aus, da dies von der PrepareStatement-Operation von JDBC ausgeführt wird in Spark ausgeführt werden. Dabei handelt es sich um Cursor.
Das heißt, wenn JDBC diese SQL durchläuft, macht der Quellcode Folgendes:
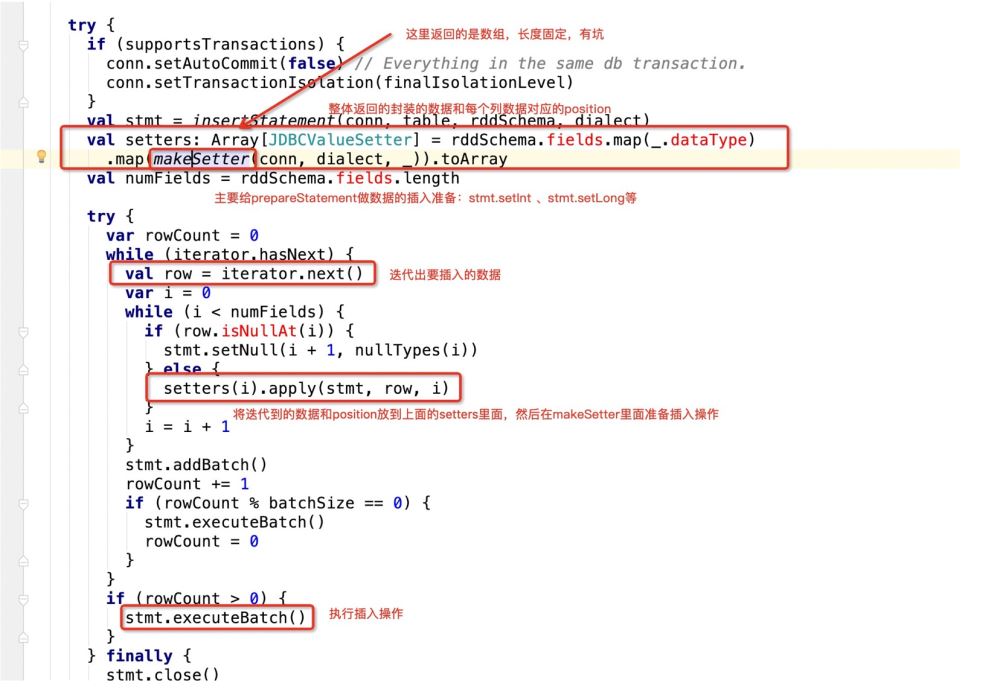
看下makeSetter:

所谓有坑就是:
insert into table (字段1 , 字段2, 字段3) values (? , ? , ?)
那么当前在源码中返回的数组长度应该是3:
val setters: Array[JDBCValueSetter] = rddSchema.fields.map(_.dataType)
.map(makeSetter(conn, dialect, _)).toArray但是如果我们此时支持了update操作,既:
insert into table (字段1 , 字段2, 字段3) values (? , ? , ?) ON DUPLICATE KEY UPDATE 字段1 = ?,字段2 = ?,字段3=?;
那么很明显,上面的sql语句提供了6个? , 但在规定字段长度的时候只有3
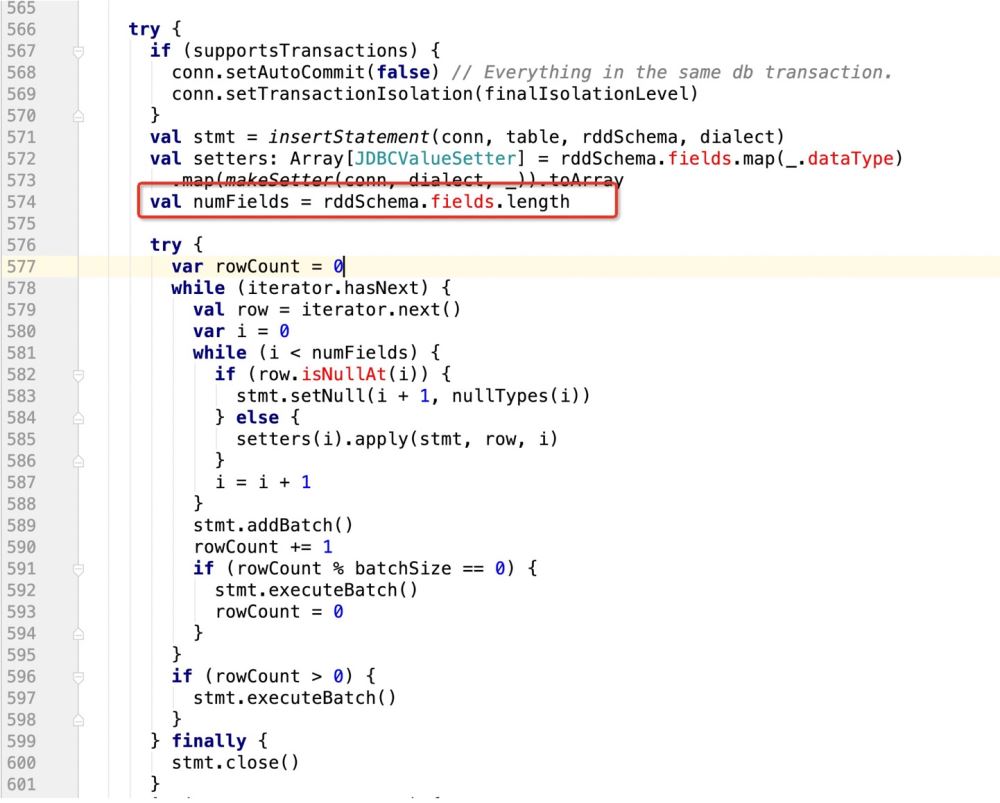
这样的话,后面的update操作就无法执行,程序报错!
所以我们需要有一个 识别机制,既:
if(isupdate){
val numFields = rddSchema.fields.length * 2
}else{
val numFields = rddSchema.fields.length
}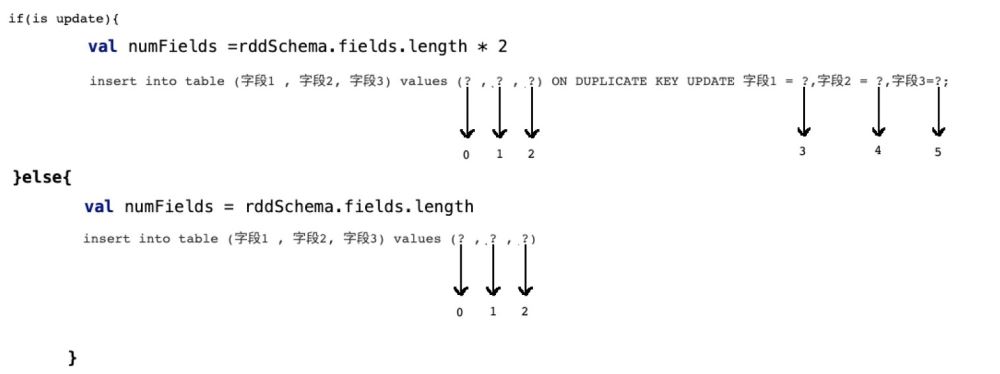
row[1,2,3] setter(0,1) //index of setter , index of row setter(1,2) setter(2,3) setter(3,1) setter(4,2) setter(5,3)
所以在prepareStatment中的占位符应该是row的两倍,而且应该是类似这样的一个逻辑
因此,代码改造前样子:
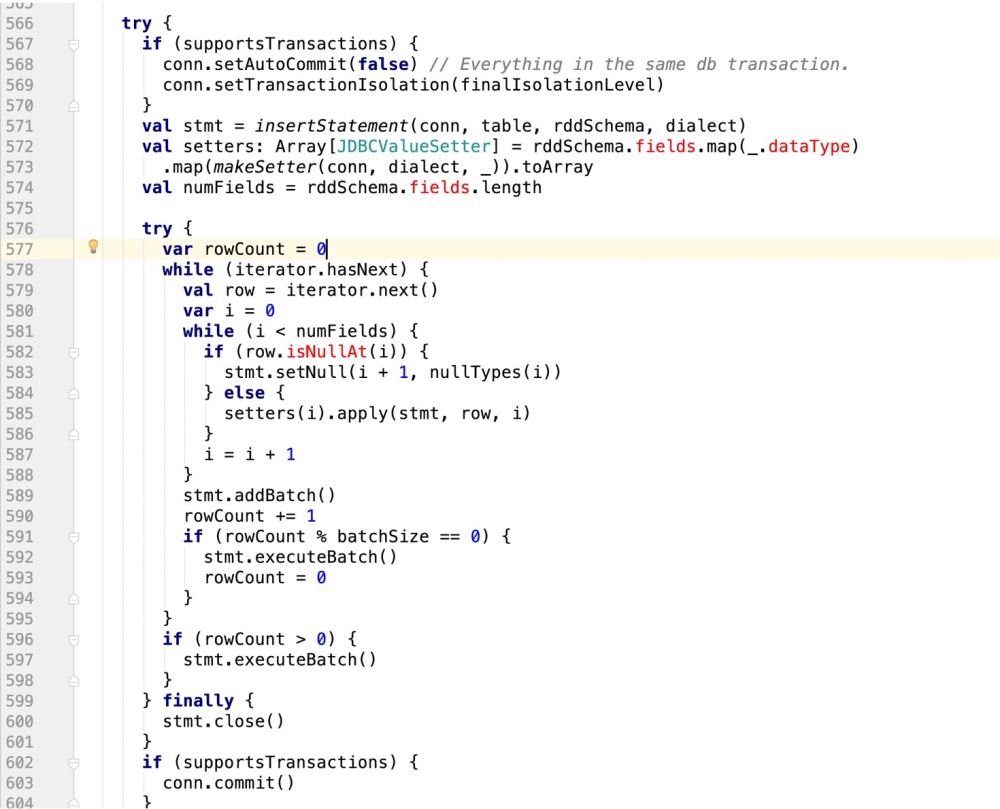
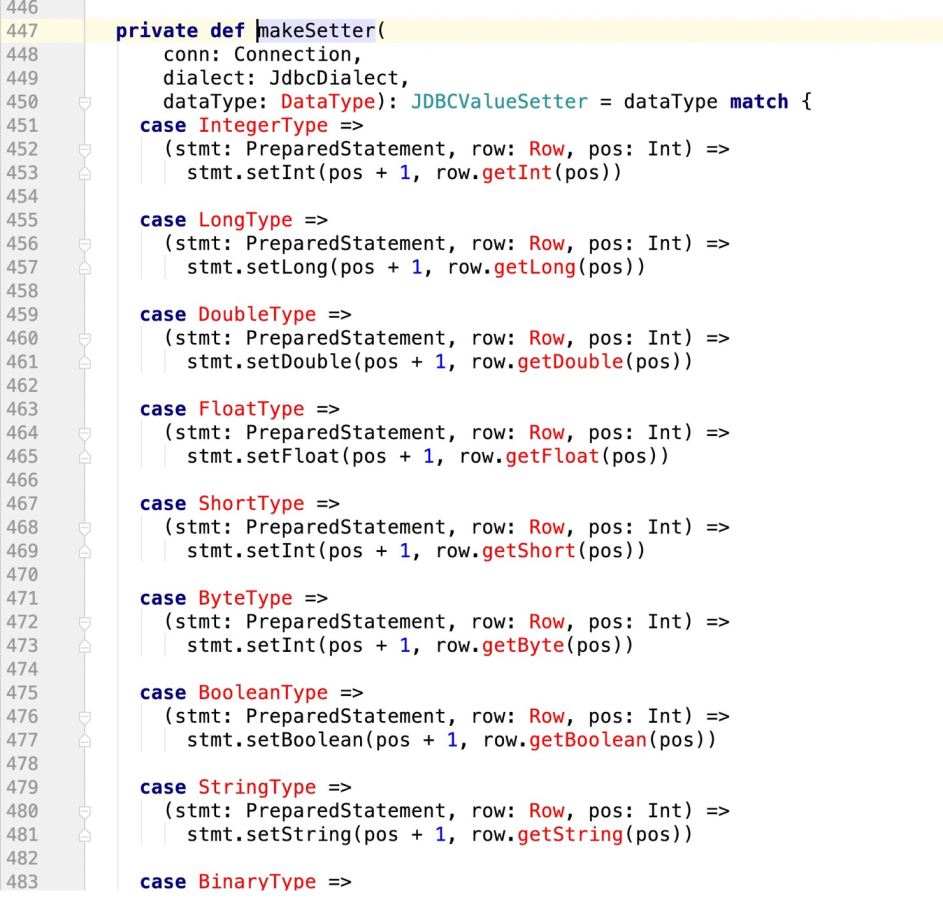
改造后的样子:
try {
if (supportsTransactions) {
conn.setAutoCommit(false) // Everything in the same db transaction.
conn.setTransactionIsolation(finalIsolationLevel)
}
// val stmt = insertStatement(conn, table, rddSchema, dialect)
//此处采用最新自己的sql语句,封装成prepareStatement
val stmt = conn.prepareStatement(sqlStmt)
println(sqlStmt)
/**
* 在mysql中有这样的操作:
* INSERT INTO user_admin_t (_id,password) VALUES ('1','第一次插入的密码')
* INSERT INTO user_admin_t (_id,password)VALUES ('1','第一次插入的密码') ON DUPLICATE KEY UPDATE _id = 'UpId',password = 'upPassword';
* 如果是下面的ON DUPLICATE KEY操作,那么在prepareStatement中的游标会扩增一倍
* 并且如果没有update操作,那么他的游标是从0开始计数的
* 如果是update操作,要算上之前的insert操作
* */
//makeSetter也要适配update操作,即游标问题
val isUpdate = saveMode == CustomSaveMode.Update
val setters: Array[JDBCValueSetter] = isUpdate match {
case true =>
val setters: Array[JDBCValueSetter] = rddSchema.fields.map(_.dataType)
.map(makeSetter(conn, dialect, _)).toArray
Array.fill(2)(setters).flatten
case _ =>
rddSchema.fields.map(_.dataType)
val numFieldsLength = rddSchema.fields.length
val numFields = isUpdate match{
case true => numFieldsLength *2
case _ => numFieldsLength
val cursorBegin = numFields / 2
try {
var rowCount = 0
while (iterator.hasNext) {
val row = iterator.next()
var i = 0
while (i < numFields) {
if(isUpdate){
//需要判断当前游标是否走到了ON DUPLICATE KEY UPDATE
i < cursorBegin match{
//说明还没走到update阶段
case true =>
//row.isNullAt 判空,则设置空值
if (row.isNullAt(i)) {
stmt.setNull(i + 1, nullTypes(i))
} else {
setters(i).apply(stmt, row, i, 0)
}
//说明走到了update阶段
case false =>
if (row.isNullAt(i - cursorBegin)) {
//pos - offset
stmt.setNull(i + 1, nullTypes(i - cursorBegin))
setters(i).apply(stmt, row, i, cursorBegin)
}
}else{
if (row.isNullAt(i)) {
stmt.setNull(i + 1, nullTypes(i))
} else {
setters(i).apply(stmt, row, i ,0)
}
//滚动游标
i = i + 1
}
stmt.addBatch()
rowCount += 1
if (rowCount % batchSize == 0) {
stmt.executeBatch()
rowCount = 0
}
if (rowCount > 0) {
stmt.executeBatch()
} finally {
stmt.close()
conn.commit()
committed = true
Iterator.empty
} catch {
case e: SQLException =>
val cause = e.getNextException
if (cause != null && e.getCause != cause) {
if (e.getCause == null) {
e.initCause(cause)
} else {
e.addSuppressed(cause)
throw e
} finally {
if (!committed) {
// The stage must fail. We got here through an exception path, so
// let the exception through unless rollback() or close() want to
// tell the user about another problem.
if (supportsTransactions) {
conn.rollback()
conn.close()
} else {
// The stage must succeed. We cannot propagate any exception close() might throw.
try {
conn.close()
} catch {
case e: Exception => logWarning("Transaction succeeded, but closing failed", e)// A `JDBCValueSetter` is responsible for setting a value from `Row` into a field for
// `PreparedStatement`. The last argument `Int` means the index for the value to be set
// in the SQL statement and also used for the value in `Row`.
//PreparedStatement, Row, position , cursor
private type JDBCValueSetter = (PreparedStatement, Row, Int , Int) => Unit
private def makeSetter(
conn: Connection,
dialect: JdbcDialect,
dataType: DataType): JDBCValueSetter = dataType match {
case IntegerType =>
(stmt: PreparedStatement, row: Row, pos: Int,cursor:Int) =>
stmt.setInt(pos + 1, row.getInt(pos - cursor))
case LongType =>
stmt.setLong(pos + 1, row.getLong(pos - cursor))
case DoubleType =>
stmt.setDouble(pos + 1, row.getDouble(pos - cursor))
case FloatType =>
stmt.setFloat(pos + 1, row.getFloat(pos - cursor))
case ShortType =>
stmt.setInt(pos + 1, row.getShort(pos - cursor))
case ByteType =>
stmt.setInt(pos + 1, row.getByte(pos - cursor))
case BooleanType =>
stmt.setBoolean(pos + 1, row.getBoolean(pos - cursor))
case StringType =>
// println(row.getString(pos))
stmt.setString(pos + 1, row.getString(pos - cursor))
case BinaryType =>
stmt.setBytes(pos + 1, row.getAs[Array[Byte]](pos - cursor))
case TimestampType =>
stmt.setTimestamp(pos + 1, row.getAs[java.sql.Timestamp](pos - cursor))
case DateType =>
stmt.setDate(pos + 1, row.getAs[java.sql.Date](pos - cursor))
case t: DecimalType =>
stmt.setBigDecimal(pos + 1, row.getDecimal(pos - cursor))
case ArrayType(et, _) =>
// remove type length parameters from end of type name
val typeName = getJdbcType(et, dialect).databaseTypeDefinition
.toLowerCase.split("\\(")(0)
val array = conn.createArrayOf(
typeName,
row.getSeq[AnyRef](pos - cursor).toArray)
stmt.setArray(pos + 1, array)
case _ =>
(_: PreparedStatement, _: Row, pos: Int,cursor:Int) =>
throw new IllegalArgumentException(
s"Can't translate non-null value for field $pos")
}Das obige ist der detaillierte Inhalt vonSo stellen Sie sicher, dass Spark SQL den Aktualisierungsvorgang beim Schreiben von MySQL unterstützt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!