
Heim >Betrieb und Instandhaltung >Sicherheit >Analyse von Serverausfallinstanzen
Analyse von Serverausfallinstanzen

- 王林nach vorne
- 2023-06-02 15:12:051316Durchsuche
1. Etwas ist schief gelaufen
Da wir in der IT-Branche tätig sind, müssen wir uns jeden Tag mit Ausfällen und Problemen auseinandersetzen, sodass wir als Feuerwehrmänner bezeichnet werden können, die herumlaufen, um Probleme zu lösen. Diesmal ist der Umfang des Fehlers jedoch etwas groß und der Host-Computer kann nicht geöffnet werden.
Glücklicherweise hat das Überwachungssystem einige Beweise hinterlassen.
Es wurde nachgewiesen, dass die CPU, der Speicher und die Dateizugriffe der Maschine mit dem Wachstum des Unternehmens weiter zunahmen ... bis die Überwachung die Informationen nicht mehr erfassen konnte.
Das Schreckliche ist, dass auf diesen Hosts viele Java-Prozesse bereitgestellt werden. Aus keinem anderen Grund als der Kostenersparnis wurden die Anträge gemischt. Wenn ein Host allgemeine Anomalien aufweist, kann es schwierig sein, den Schuldigen zu finden.
Da die Remote-Anmeldung abgelaufen ist, kann ungeduldiges Betriebs- und Wartungspersonal nur noch einen Neustart der Maschine wählen und nach dem Neustart mit dem Neustart von Anwendungen beginnen. Nach einer langen Wartezeit kehrten alle Prozesse wieder in den Normalbetrieb zurück, doch schon nach kurzer Zeit stürzte der Host-Rechner plötzlich ab.
Das Geschäft steckt in einer Sackgasse, was wirklich ärgerlich ist. Es macht den Menschen auch Angst. Nach mehreren Versuchen brachen Betrieb und Wartung zusammen und der Notfallplan wurde gestartet: Rollback! Es gibt viele aktuelle Online-Aufzeichnungen und es gibt Entwickler, die online gehen und privat bereitstellen. Der Betrieb und die Wartung sind verwirrt: Was sollte zurückgesetzt werden? Was sonst? Jemand hatte plötzlich eine gute Idee und erinnerte sich, dass es auch einen Suchbefehl gibt. Suchen Sie dann alle kürzlich aktualisierten JAR-Pakete und setzen Sie sie zurück.
find /apps/deploy -mtime +3 | grep jar$
Wenn Sie den Suchbefehl nicht kennen, ist das wirklich eine Katastrophe. Zum Glück weiß es jemand.
Ich habe mehr als ein Dutzend JAR-Pakete zurückgesetzt, es gab keine Schemaänderung in der Datenbank und das System lief endlich normal.
2. Finden Sie den Grund
Es gibt keine andere Möglichkeit, überprüfen Sie die Protokolle und führen Sie eine Codeüberprüfung durch.
Um die Qualität des Codes sicherzustellen, sollte sich der Umfang der Codeüberprüfung auf Codeänderungen in den letzten 1 oder 2 Wochen beschränken, da einige Funktionscodes eine gewisse Zeit zur Reife benötigen, bevor sie online glänzen können.
Beim Blick auf den Einreichungsdatensatz „OK“, der den Bildschirm ausfüllte, wurde das Gesicht des technischen Managers grün.
„xjjdog sagte: „80 % der Programmierer können keine Commit-Datensätze schreiben“, ich denke, 100 % von Ihnen können es nicht schreiben.“
Alle waren still und ertrug den Schmerz, um die historischen Veränderungen zu überprüfen. Nach unermüdlichem Einsatz aller haben wir schließlich zwischen den Bergen von Scheiße einige problematische Codes gefunden. Eine vom CxO selbst erstellte Gruppe, in die jeder Code hineinwirft, der Probleme verursachen kann.
„Der Systemdienst war fast eine Stunde lang unterbrochen und die Auswirkungen waren sehr schlimm.“ Der CxO sagte: „Das Problem muss vollständig gelöst werden. Die Anleger sind sehr besorgt über dieses Problem.“ DingTalk, die Gesten aller werden einheitlich.
3. Thread-Pool-Parameter
Es gibt viel Code und alle haben den Problemcode schon lange diskutiert. Dieser Satz kann wie folgt umgeschrieben werden: Wir haben einigen komplexen Code untersucht, der parallele Streams verwendet und in Lambda-Ausdrücken verschachtelt ist, wobei wir besonderes Augenmerk auf die Verwendung von Thread-Pools gelegt haben.
Am Ende haben sich alle entschieden, den Thread-Pool-Code noch einmal durchzugehen. Einer der Absätze sagt dies.
RejectedExecutionHandler handler = new ThreadPoolExecutor.DiscardOldestPolicy(); ThreadPoolExecutor executor = new ThreadPoolExecutor(100,200, 60000, TimeUnit.MILLISECONDS, new LinkedBlockingDeque(10), handler);
Ganz zu schweigen davon, dass die Parameter anständig sind und sogar eine Ablehnungsstrategie in Betracht gezogen wird.
Der Thread-Pool von Java macht das Programmieren sehr einfach. Diese Parameter können nicht überprüft werden, ohne sie einzeln durchzugehen, wie im Bild oben gezeigt.
corePoolSize: Die Anzahl der Kernthreads, der Kernthread bleibt bestehen, nachdem er erstellt wurde
maxPoolSize: Die maximale Anzahl von Threads
keepAliveTime: Thread-Leerlaufzeit
-
workQueue: Blockierungswarteschlange
-
threadFactory: Thread Fabrik erstellen
handler: Ablehnungsstrategie
Lassen Sie uns ihre Beziehung vorstellen.
Wenn die Anzahl der Threads geringer ist als die Anzahl der Kern-Threads und eine neue Aufgabe eintrifft, erstellt das System einen neuen Thread zur Bearbeitung der Aufgabe. Wenn die aktuelle Anzahl der Threads die Anzahl der Kernthreads überschreitet und die Blockierungswarteschlange nicht voll ist, wird die Aufgabe in die Blockierungswarteschlange gestellt. Wenn die Anzahl der Threads größer ist als die Anzahl der Kern-Threads und die Blockierungswarteschlange voll ist, werden neue Threads erstellt, die bedient werden, bis die Anzahl der Threads die maximale PoolSize-Größe erreicht. Wenn zu diesem Zeitpunkt neue Aufgaben vorhanden sind, wird die Ablehnungsrichtlinie ausgelöst.
Lassen Sie uns noch einmal über die Ablehnungsstrategie sprechen. JDK verfügt über 4 integrierte Richtlinien. Die Standardrichtlinie ist AbortPolicy, die direkt eine Ausnahme auslöst. Einige weitere werden im Folgenden vorgestellt.
DiscardPolicy ist radikaler als Abort und verwirft die Aufgabe direkt ohne Ausnahmeinformationen.
Die Aufgabenverarbeitung wird vom aufrufenden Thread ausgeführt, der die Implementierung von CallerRunsPolicy darstellt. Wenn die Thread-Pool-Ressourcen einer Webanwendung voll sind, werden Tomcat-Threads neue Aufgaben zur Ausführung zugewiesen. In einigen Fällen kann diese Methode den Ausführungsdruck einiger Aufgaben verringern, aber in mehr Fällen blockiert sie direkt die Ausführung des Hauptthreads.
-
DiscardOldestPolicy verwirft die Aufgabe an der Spitze der Warteschlange und versucht dann, sie auszuführen Die Aufgabe noch einmal
Dieser Thread-Pool-Code wurde neu hinzugefügt und die Parametereinstellungen sind relativ vernünftig, sodass es kein großes Problem gibt. Die Verwendung der DiscardOldestPolicy-Ablehnungsrichtlinie ist das einzig mögliche Risiko. Wenn viele Aufgaben vorhanden sind, führt diese Ablehnungsrichtlinie dazu, dass Aufgaben in die Warteschlange gestellt werden und Anfragen eine Zeitüberschreitung erfahren.
Natürlich können wir dieses Risiko nicht außer Acht lassen. Ehrlich gesagt ist es der wahrscheinlichste Risikocode, der bisher gefunden werden kann.
„Ändern Sie die DiscardOldestPolicy in die Standard-AbortPolicy, verpacken Sie sie neu und probieren Sie es online aus.“ Der Technik-Guru sagte in der Gruppe.
4. Was ist das Problem?
Nachdem der Graustufendienst gestartet wurde, starb der Host kurz darauf. Das ist der Grund, warum es nicht ausgeführt wurde, aber warum?
Die Größe des Thread-Pools, das Minimum ist 100, das Maximum ist 200, nichts ist zu viel. Die Kapazität der Blockierungswarteschlange beträgt nur 10, sodass keine Probleme auftreten. Wenn Sie sagen, dass es durch diesen Thread-Pool verursacht wird, werde ich Ihnen nicht einmal glauben.
Aber die Geschäftsabteilung hat berichtet, dass dieser Code stirbt, wenn er hinzugefügt wird, aber wenn er nicht hinzugefügt wird, ist alles in Ordnung. Die Technikexperten rätseln über ihre Schwester.
Am Ende konnte jemand nicht mehr anders und hat den Geschäftscode heruntergeladen, um ihn zu debuggen.
Als er Idea öffnete, war er verwirrt und verstand sofort. Endlich verstand er, warum dieser Code Probleme verursachte.
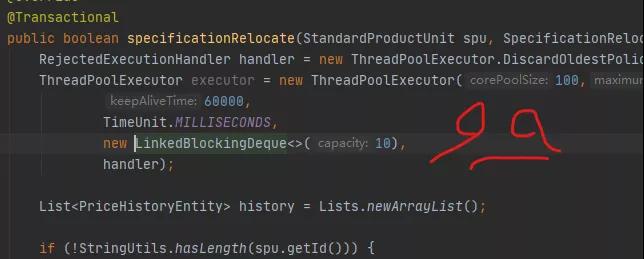
Der Thread-Pool wird tatsächlich in der Methode erstellt!
Bei jeder Anforderung wird ein Thread-Pool erstellt, bis das System keine Ressourcen mehr zuweisen kann.
Wie dominant.
Jeder achtet darauf, wie die Parameter des Thread-Pools festgelegt werden, aber niemand hat jemals daran gezweifelt, wo sich dieser Code befindet.
Das obige ist der detaillierte Inhalt vonAnalyse von Serverausfallinstanzen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Beispielanalyse des CNNVD-Berichts zur Sicherheitslücke Apache Struts2 S2-057
- So führen Sie eine statische Analyse in Android durch
- Was sind die Wissenspunkte des Appium-Frameworks?
- So analysieren Sie netzwerkschichtbezogene Pakete und Daten von TCP und IP
- Wie sieht die Django-Entwicklung sowie die Offensiv- und Defensivtests aus?