
Heim >Datenbank >MySQL-Tutorial >MySQL-Optimierungs- und Indizierungsmethoden
MySQL-Optimierungs- und Indizierungsmethoden

- PHPznach vorne
- 2023-06-02 13:58:211211Durchsuche
Eine kurze Einführung in Indizes
Die Essenz von Indizes:
Die Essenz von MySQL-Indizes oder anderen relationalen Datenbankindizes ist nur ein Satz: Tauschen Sie Raum gegen Zeit aus.
Die Rolle des Index:
Index relationale Datenbankdatenstruktur (Festplattenspeicher), um das Abrufen von Zeilendaten in der Tabelle zu beschleunigen
Klassifizierung des Index
Kategorie des obige Datenstruktur:
HASH-Index
Hohe Effizienz des gleichen Matchings
Unterstützt keine Bereichssuche
Tree. Index
Bin Ary-Baum, rekursive binäre Suchmethode, links klein rechts groß
Ausgeglichener Binärbaum, vom Binärbaum zum ausgeglichenen Binärbaum, der Hauptgrund ist die Links-Rechts-Rotation
Nachteil 1, zu viele E/A-Zeiten
Nachteil 2, geringe E/A-Auslastung, IO-Sättigung
Mehrere Pfade Ausgewogener Suchbaum (B-Baum)
Funktionen, die die Höhe des Baumes erheblich reduzieren
B+-Baum
Funktionen unter Verwendung der geschlossener Vergleich Methode
Wurzelknoten Verzweigungsknoten Es gibt keinen Datenbereich, nur Blattknoten enthalten den Datenbereich (um es ganz klar auszudrücken: Selbst wenn der Wurzelknoten und die untergeordneten Knoten gefunden wurden, wird er nicht gestoppt, da kein Datenbereich vorhanden ist , und wird fortgesetzt, bis der Blattknoten gefunden wird.)
Wenn wir nach den Daten 13 suchen, können wir sowohl den Wurzelknoten als auch den untergeordneten Knoten finden, aber wir werden immer den Blattknoten finden.
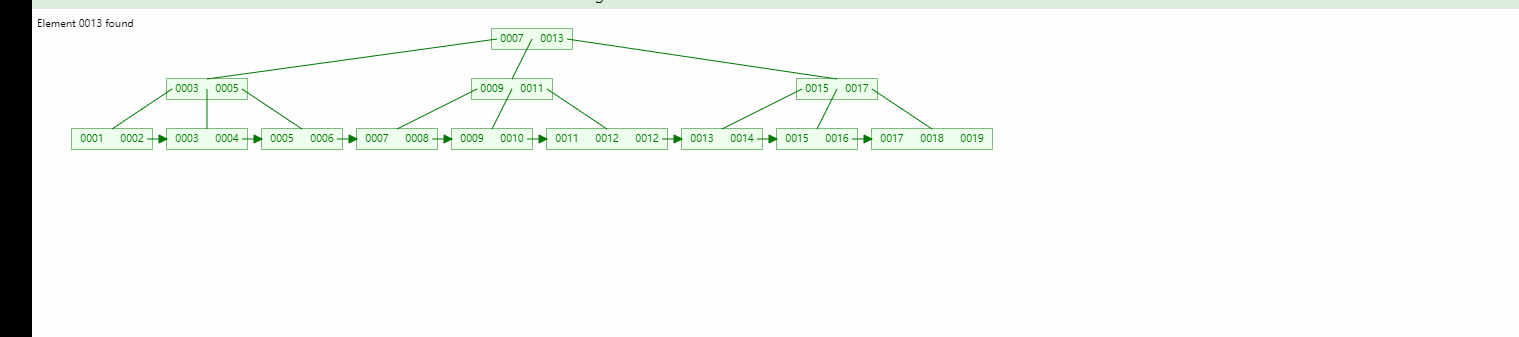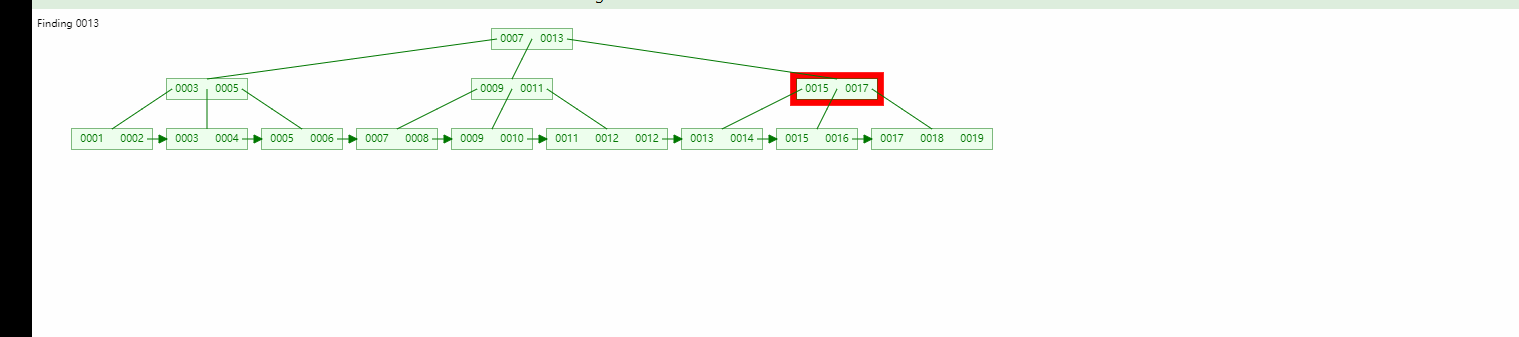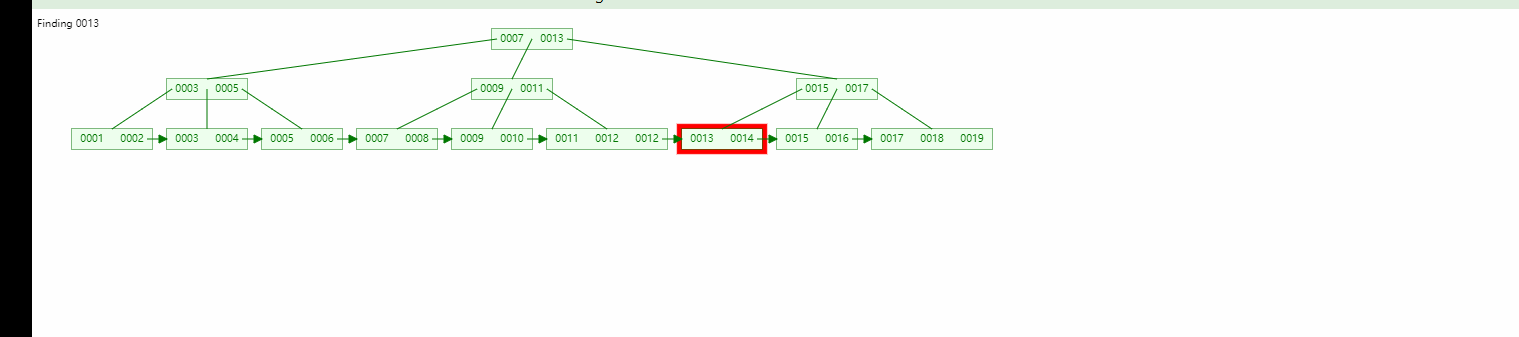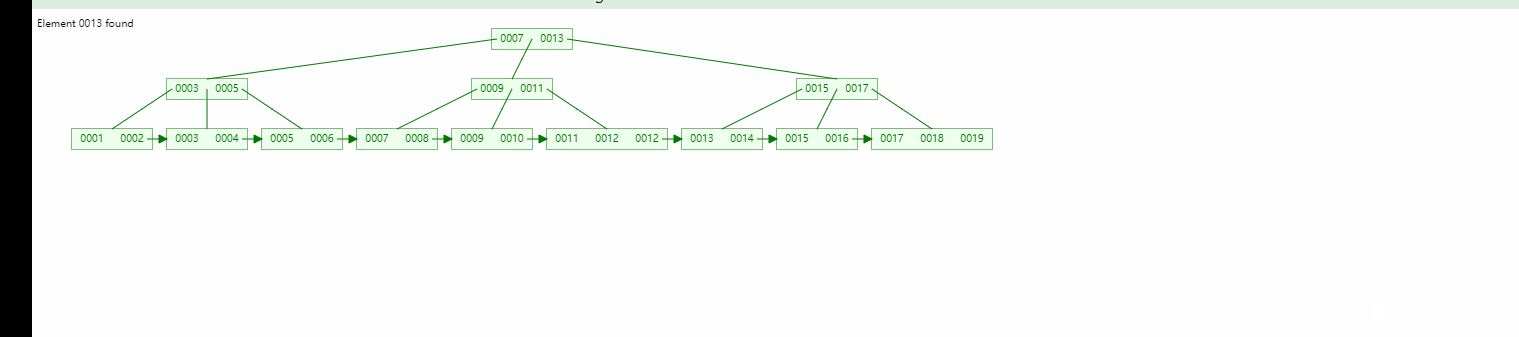
Binärbaum Ausgeglichener Binärbaum, B-Baum-Vergleich:
Wie in der Abbildung gezeigt, wenn es sich um einen automatisch erhöhenden Primärschlüssel handelt:
Der Binärbaum ist offensichtlich nicht für relationale Datenbanken geeignet Indizierung (kein Unterschied zum vollständigen Tabellenscan) .
Was den ausgeglichenen Binärbaum betrifft, so löst er zwar diese Situation, führt aber auch dazu, dass der Baum dünn und hoch wird, was ebenfalls zu vielen Abfrage-E/A-Zeiten und einer geringen E/A-Auslastung führt, wie oben erwähnt.
B-Tree hat diese beiden Probleme offensichtlich gelöst. Im Folgenden wird erklärt, warum MySQL in diesem Fall immer noch B+ Tree verwendet und diese Verbesserungen vorgenommen hat.

Vergleich von B-Baum und B+-Baum:

Optimierung von B+-Baum auf B-Baum:
IO ist effizienter (jeder Knoten des B-Baums behält die Datenbereich, während B+-Bäume dies nicht tun. Unter der Annahme, dass wir drei Ebenen durchlaufen müssen, um ein Datenelement abzufragen, ist der E/A-Verbrauch in der B+-Baumabfrage offensichtlich geringer.
Die Reichweitensucheffizienz ist höher (wie in der Abbildung gezeigt). Abbildung: Der B + -Baum hat eine natürliche verknüpfte Listenform gebildet und muss nur auf der letzten Kettenstruktursuche basieren.

Indexbasiertes Datenscannen ist effizienter.
Klassifizierung von Indextypen
Indextypen können in zwei Kategorien unterteilt werden:
Primärschlüsselindex
Hilfsindex (Sekundärindex)
Einzigartiger Index
-
Zusammengesetzter Index
Normaler Index
Abdeckender Index
Obwohl die Leistung des Primärschlüsselindex relativ am besten ist, werden wir normalerweise bei der SQL-Optimierung den Hilfsindex verbessern und ergänzen.
B+-Baum wird auf der Ebene der Speicher-Engine implementiert
Wir erstellen jeweils zwei Tabellen
test_innodb(unter Verwendung von InnoDB als Speicher-Engine) test_myisam (unter Verwendung von MyISAM als Speicher-Engine) Die folgende Abbildung zeigt die relevanten Dateien für die Festplattenimplementierung der beiden Tabellen Die beiden Speicher-Engines auf der B+-Baum-Plattenebene sind völlig unterschiedlich.
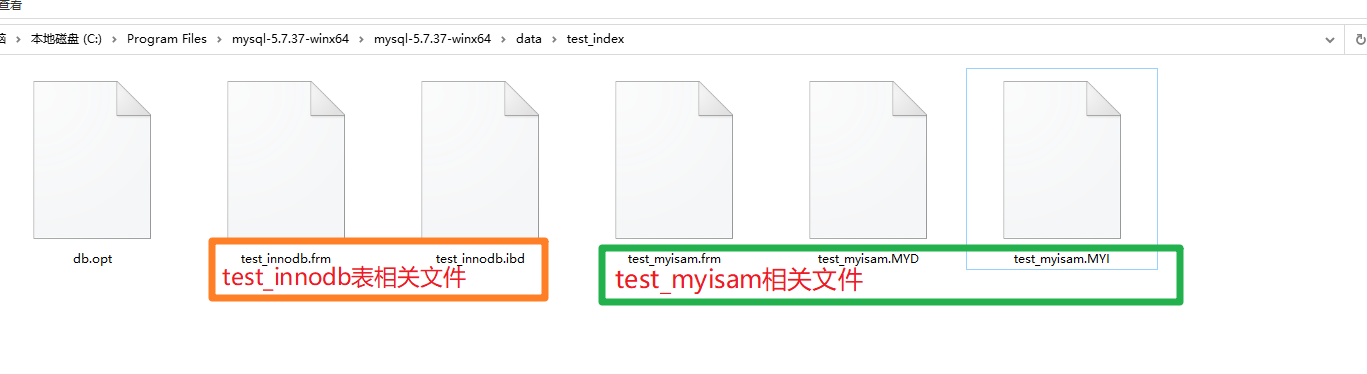
B+-Baum ist in MyISAM implementiert:
*.frm-Datei ist eine Tabellenskelettdatei. Welche Art von ID-Feldnamensfeld in dieser Tabelle wird hier beispielsweise gespeichert
*.MYD (D=Daten) speichert Daten
*.MYI (I=Index) speichert Index

Wenn beispielsweise die folgende SQL-Anweisung jetzt ausgeführt wird, dann ist sie in MyISAM der Fall Suchen Sie zuerst in test_myisam.MYI nach 103, erhalten Sie die Adresse 0x194281, suchen Sie dann die Daten in test_myisam.MYD und geben Sie sie zurück.
SELECT id,name from test_myisam where id =103
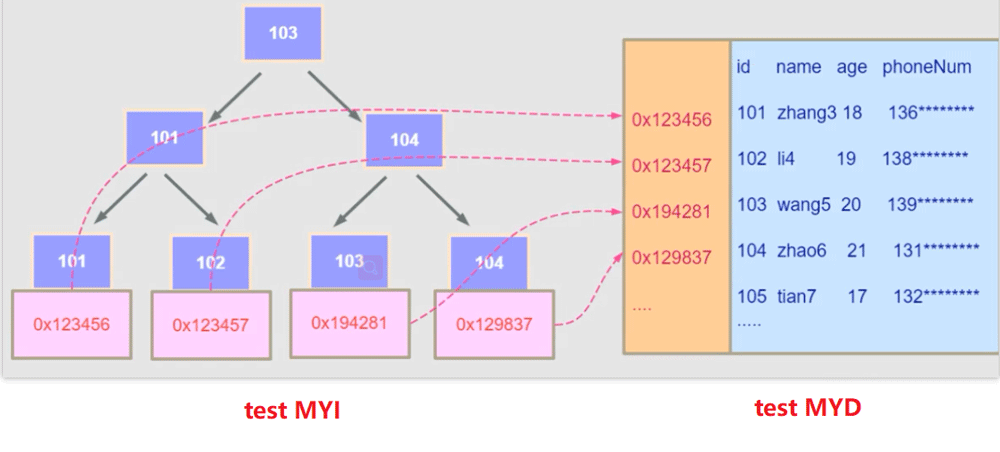
如果
test_myisam表中,id为主键索引,name也是一个索引,那么在test_myisam.MYI中则会有两个平级的B+树,这也导致MyISAM引擎中主键索引和二级索引是没有主次之分的,是平级关系。因为这种机制在MyISAM引擎中,有可能使用多个索引,在InnoDB中则不会出现这种情况。
B+树在InnoDB落地:

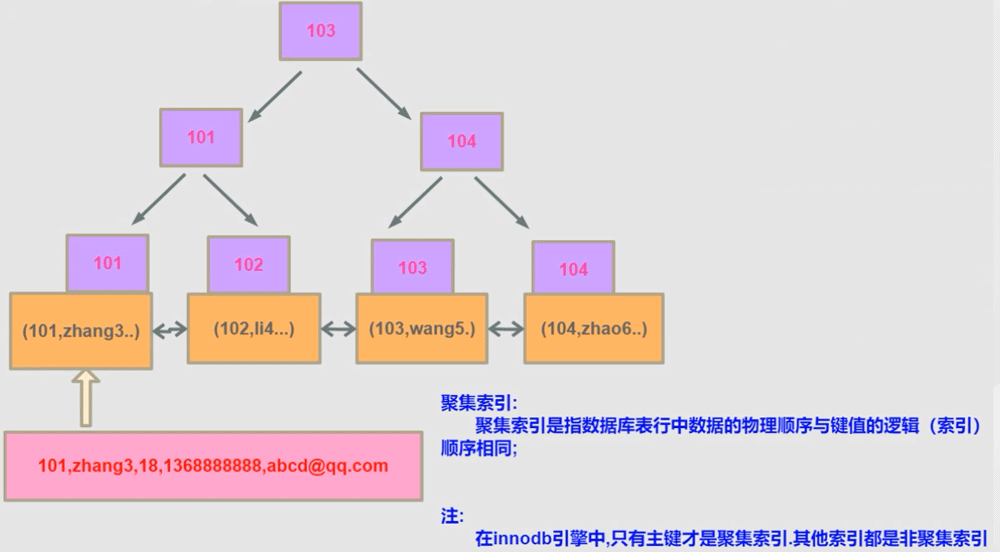
InnoDB不像MyISAM来独立一个MYD 文件来存储数据,它的数据直接存储在叶子结点关键字对应的数据区在这保存这一个id列所有行的详细记录。
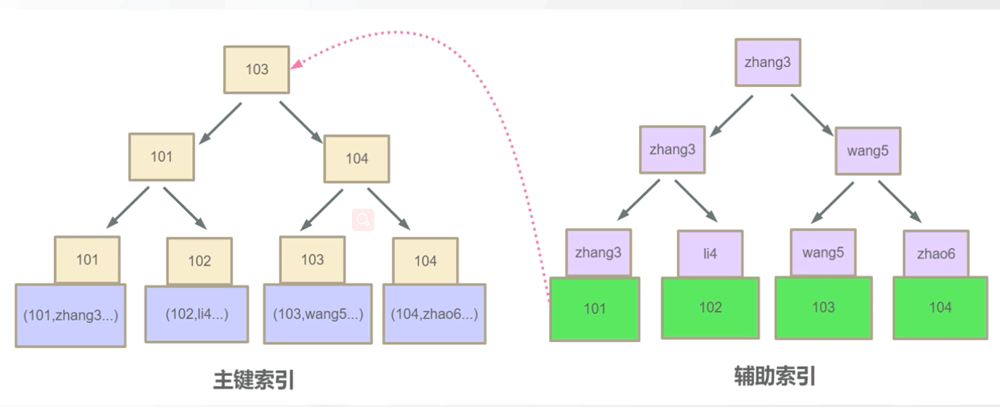
InnoDB 主键索引和辅助索引关系
我们现在执行如下SQL语句,他会先去找辅助索引,然后找到辅助索引下101的主键,再去回表(二次扫描)根据主键索引查询103这条数据将其返回。
SELECT id,name from test_myisam where name ='zhangsan'
这里就有一个问题了,为什么不像MyISAM在辅助索引下直接记录磁盘地址,而是要多此一举再去回表扫描主键索引,这个问题在下面相关面试题中回答,记一下这个问题是这里来的。
相关面试题
为什么MySQL选择B+树作为索引结构
这个就不说了,上文应该讲清楚了。
B+树在MyISAM和InnoDB落地区别。
这个可以总结一下,MyISAM落地数据储存会有三个类型文件 ,.frm文件是表骨架文件,.MYD(D=data)则储存数据 ,.MYI (I=index)则储存索引,MyISAM引擎中主键索引和二级索引平级关系,在MyISAM引擎中,有可能使用多个索引,InnoDB则相反,主键索引和二级索有严格的主次之分在InnoDB一条语句只能用一个索引要么不用。
如何判断一条sql语句是否使用了索引。
可以通过执行计划来判断 可以在sql语句前explain/ desc
set global optimizer_trace='enabled=on' 打开执行计划开关他将会把每一条查询sql执行计划记录在information_schema 库中OPTIMIZER_TRACE表中
为什么主键索引最好选择自增列?
自增列,数据插入时整个索引树是只有右边在增加的,相对来说索引树的变动更小。
为什么经常变动的列不建议使用索引?
和上一个问题原因一样,当一个索引经常发生变化,那么就意味这,这个缩印树也要经常发生变化。4
为什么说重复度高的列,不建议建立索引?
这个原因是因为离散性,比如说,一张一百万数据的表,其中一个字段代表性别,0代表男1代表女,把这字段加了索引,那么在索引树上,将会有大量的重复数据。而我们常见的索引建立一般都是驱动型的。其目的是,尽可能的删减数据的查询范围,这个显然是不匹配的。
什么是联合索引
联合索引是一个包含了多个功效的索引,他只是一个索引而不是多个,
其次,单列索引是一种特殊的联合索引
联合索引的创立要遵循最左前置原则(最常用列>离散度>占用空间小)
什么是覆盖索引
通过索引项信息可直接返回所需要查询的索引列,该索引被称之为覆盖索引,说白了就是不需要做回表操作,可以从二级索引中直接取到所需数据。
什么是ICP机制
索引下推,简单点来说就是,在sql执行过程中,面对where多条件过滤时,通过一个索引,完成数据搜索和过滤条件其,特点能减少io操作。
在InnoDB表中不可能没有主键对还是不对原因是什么?
首先这句话是对的,但是情况有三种:
Das heißt, wenn Sie dieses Feld manuell als Primärschlüssel angeben, wird dieses Feld als Clustered-Index verwendet.
Es gibt zwei Situationen, in denen der Primärschlüssel nicht explizit angegeben wird:
Er sucht nach dem ersten UK (eindeutiger Schlüssel) als Primärschlüsselindex, um die Indexanordnung zu organisieren.
Wenn weder der Primärschlüssel noch das Vereinigte Königreich angegeben sind, wird die Zeilen-ID (jeder Datensatz in der InnoDB-Tabelle verfügt über eine versteckte (6 Byte) Zeilen-ID) als Clustered-Index verwendet.
Was ist ein Tabellenrückgabevorgang?
In InnoDB kann der auf dem Hilfsindex abgefragte Inhalt nicht direkt aus dem Hilfsindex abgerufen werden. Der Vorgang erfordert einen sekundären Scan basierend auf dem Primärschlüssel index wird als Tabellenrückgabeoperation bezeichnet.
Warum zeichnet der Hilfsindexblattknoten-Datenbereich in InnoDB den Wert des Primärschlüsselindex auf, anstatt wie in MyISAM die Festplattenadresse aufzuzeichnen?
Der Grund ist eigentlich sehr einfach, da sich die Datenstruktur des Primärschlüsselindex häufig ändert. Wenn die Festplattenadresse im Hilfsindexdatenbereich aufgezeichnet wird, nehmen wir an, dass wir 10 Hilfsindizes haben, wenn unser Primärschlüsselindex Strukturänderungen Schließlich müssen die Hilfsindizes einzeln benachrichtigt werden, und die Struktur des Primärschlüsselindex ändert sich häufig, und Hinzufügungen und Löschungen können sich auf die Datenstruktur auswirken.
Das obige ist der detaillierte Inhalt vonMySQL-Optimierungs- und Indizierungsmethoden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!