Was ist der Grund, warum der MySQL-Index schnell ist?
PHPznach vorne
2023-05-31 20:58:101960Durchsuche
Durch die Vorsortierung kann der Index mit hocheffizienten Algorithmen wie der binären Suche durchsucht werden. Die Komplexität der allgemeinen sequentiellen Suche beträgt O(n), während die Komplexität der binären Suche O(log2n) beträgt; wenn n sehr groß ist, ist der Effizienzunterschied zwischen den beiden enorm.
MySQL ist eine sehr beliebte Datenbank im Internet. Das Design der zugrunde liegenden Speicher-Engine und der Datenabruf-Engine ist sehr wichtig. Insbesondere die Speicherform von MySQL-Daten und das Design des Index bestimmen die Gesamtleistung beim Datenabruf MySQL.
Wir wissen, dass die Funktion eines Index darin besteht, Daten schnell abzurufen, und das Wesentliche beim schnellen Abruf ist die Datenstruktur. Durch die Auswahl verschiedener Datenstrukturen können verschiedene Daten schnell abgerufen werden. In einer Datenbank sind effiziente Suchalgorithmen sehr wichtig, da eine große Datenmenge in der Datenbank gespeichert ist und ein effizienter Index eine enorme Zeitersparnis ermöglichen kann. Wenn MySQL beispielsweise in der folgenden Datentabelle den Indexalgorithmus nicht implementiert, können Sie zum Suchen der Daten mit der ID = 7 nur eine gewaltsame sequentielle Durchquerung verwenden, um die Daten mit der ID = 7 zu finden Sie müssen es 7 Mal vergleichen. Wenn diese Tabelle 10 Millionen Daten mit der ID = 1000 W speichert, wird sie 1000 W verglichen. Diese Geschwindigkeit ist inakzeptabel.
1. Auswahl der zugrunde liegenden Datenstruktur des MySQL-Index
Hash-Tabelle (Hash)
Hash-Tabelle ist ein effektives Tool für den schnellen Datenabruf.
Hash-Algorithmus: Auch Hash-Algorithmus genannt. Er wandelt jeden Wert (Schlüssel) über eine Hash-Funktion in eine Schlüsseladresse fester Länge um und verwendet diese Adresse, um eine Datenstruktur für bestimmte Daten zu erstellen.
Betrachten Sie diesen Datenbanktabellenbenutzer. Es gibt 7 Daten in der Tabelle. Die SQL-Syntax lautet:
select * from user where id=7;
Der Hash-Algorithmus berechnet und speichert Daten mit der ID = 7 Die physische Adresse addr = hash (7) = 4231, und die durch 4231 zugeordnete physische Adresse ist 0x77. Dies ist die physische Adresse der mit der ID = 7 gespeicherten Daten. finden Sie über diese unabhängige Adresse. Dies ist der Berechnungsprozess, den der Hash-Algorithmus verwendet, um Daten schnell abzurufen.
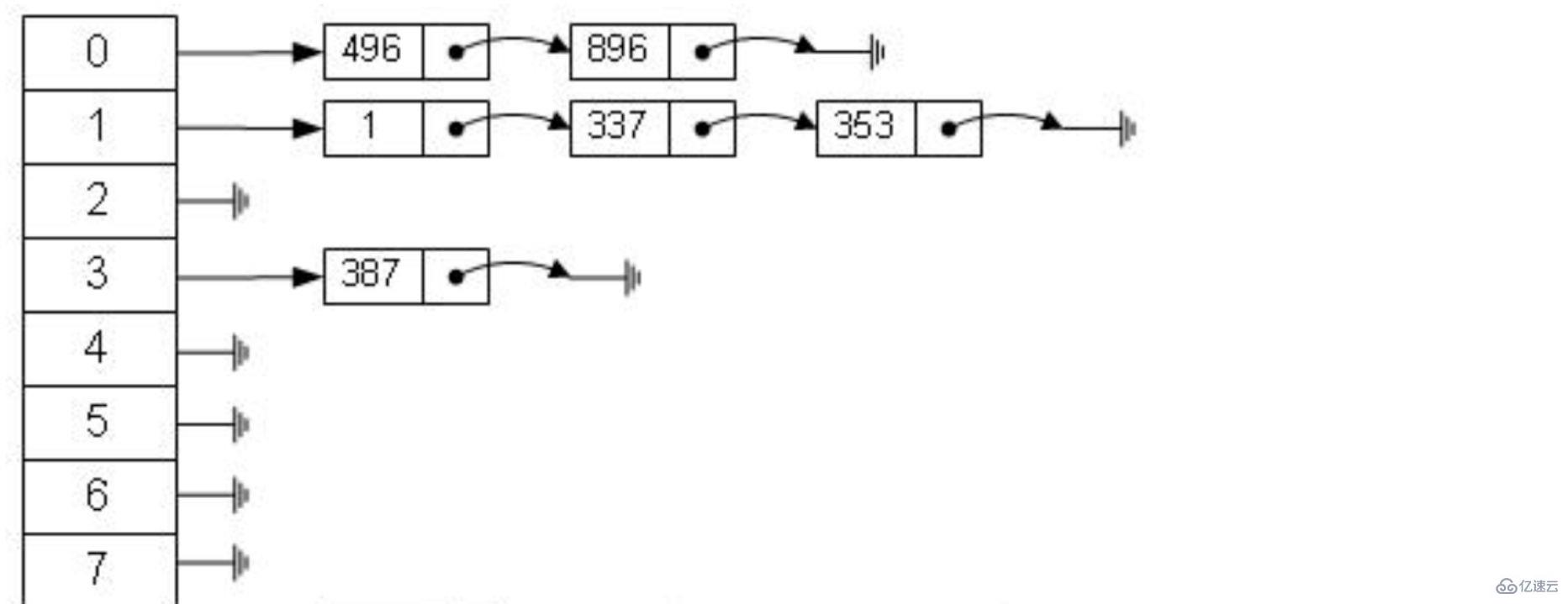
Aber der Hash-Algorithmus weist ein Datenkollisionsproblem auf, das heißt, die Hash-Funktion berechnet möglicherweise dasselbe Ergebnis für verschiedene Schlüssel. Beispielsweise kann Hash (7) dasselbe Ergebnis wie Hash (199) berechnen, was unterschiedlich ist Der Schlüssel wird auf dasselbe Ergebnis abgebildet, was ein Kollisionsproblem darstellt. Eine gängige Methode zur Lösung des Kollisionsproblems ist die Kettenadressmethode, bei der die kollidierenden Daten mithilfe einer verknüpften Liste verbunden werden. Nach der Berechnung des Hash-Werts müssen Sie auch prüfen, ob der Hash-Wert eine Kollision in der verknüpften Datenliste aufweist. Wenn dies der Fall ist, wird er bis zum Ende der verknüpften Liste durchlaufen, bis die dem tatsächlichen Schlüssel entsprechenden Daten gefunden werden.
Aus der Zeitkomplexitätsanalyse des Algorithmus geht hervor, dass die Zeitkomplexität des Hash-Algorithmus O (1) ist und die Abrufgeschwindigkeit sehr hoch ist. Wenn Sie beispielsweise nach Daten mit der ID = 7 suchen, muss der Hash-Index nur einmal berechnet werden, um die entsprechenden Daten zu erhalten, und die Abrufgeschwindigkeit ist sehr hoch. Aber MySQL verwendet kein Hashing als zugrunde liegenden Algorithmus. Warum ist das so?
Denn wenn man bedenkt, dass eine gängige Methode zum Datenabruf die Bereichssuche ist, wie zum Beispiel die folgende SQL-Anweisung:
select * from user where id \>3;
Für die obige Anweisung möchten wir die Daten mit der ID>3 finden, was sehr typisch ist Bereichssuche. Wie führt man eine Bereichssuche durch, wenn man einen durch einen Hash-Algorithmus implementierten Index verwendet? Eine einfache Idee besteht darin, alle Daten auf einmal zu finden, in den Speicher zu laden und dann die Daten innerhalb des Zielbereichs im Speicher zu filtern. Diese Bereichssuchmethode ist jedoch zu umständlich und überhaupt nicht effizient.
Obwohl der mit dem Hash-Algorithmus implementierte Index Daten schnell abrufen kann, kann er keine effiziente Bereichssuche der Daten durchführen. Daher ist der Hash-Index keine Datenstruktur, die als zugrunde liegender Index von MySQL geeignet ist.
Binärer Suchbaum (BST)
Der binäre Suchbaum ist eine Datenstruktur, die eine schnelle Datensuche unterstützt, wie in der folgenden Abbildung dargestellt: #🎜 🎜#
Die zeitliche Komplexität eines binären Suchbaums beträgt beispielsweise O(lgn) für Für die obige Binärbaumstruktur müssen wir dreimal berechnen und vergleichen, um die Daten mit der ID = 7 abzurufen. Im Vergleich zur direkten Durchlaufabfrage wird dadurch die Hälfte der Zeit eingespart. Aus Sicht der Abrufeffizienz kann ein schneller Abruf erreicht werden . Kann die Struktur des Binärbaums außerdem die Bereichssuchfunktion lösen, die der Hash-Index nicht bereitstellen kann? Die Antwort ist ja. Beachten Sie das Bild oben. Die Blattknoten des Binärbaums sind in aufsteigender Reihenfolge von links nach rechts angeordnet. Wenn wir die Daten mit der ID> 5 finden müssen, können wir den Knoten mit Knoten 6 und dessen rechten Knoten herausnehmen Unterbaum. Die Bereichssuche ist relativ einfach zu implementieren. Aber der gewöhnliche binäre Suchbaum weist einen fatalen Mangel auf: Im Extremfall degeneriert er zu einer linear verknüpften Liste, die binäre Suche degeneriert auch zu einer Traversalsuche und die Zeitkomplexität degeneriert zu O( N) und die Abrufleistung wird stark sinken. In der folgenden Situation ist beispielsweise der Binärbaum extrem unausgeglichen und zu einer verknüpften Liste degeneriert, und die Abrufgeschwindigkeit ist stark reduziert. Zu diesem Zeitpunkt beträgt die Anzahl der Berechnungen, die zum Abrufen der Daten mit der ID = 7 erforderlich sind, 7.
In der Datenbank ist die automatische Dateninkrementierung eine sehr häufige Form Beispielsweise ist der Primärschlüssel einer Tabelle die ID, und der Primärschlüssel wird im Allgemeinen automatisch inkrementiert. Wenn eine Datenstruktur wie ein Binärbaum als Index verwendet wird, tritt zwangsläufig das Problem der linearen Suche auf, das durch das oben eingeführte Ungleichgewicht verursacht wird geschehen. Daher weist ein einfacher binärer Suchbaum das Problem einer verringerten Abrufleistung auf, die durch ein Ungleichgewicht verursacht wird, und kann nicht direkt zur Implementierung des zugrunde liegenden Index von MySQL verwendet werden.
AVL-Baum und Rot-Schwarz-Baum
Es gibt ein Ungleichgewichtsproblem im binären Suchbaum, daher haben Wissenschaftler dies vorgeschlagen Baumknoten werden automatisch gedreht und angepasst, um den Binärbaum in einem grundsätzlich ausgeglichenen Zustand zu halten und so die beste Suchleistung des Binärsuchbaums aufrechtzuerhalten. Zu den auf dieser Idee basierenden selbstanpassenden Gleichgewichtszustands-Binärbäumen gehören AVL-Bäume und Rot-Schwarz-Bäume. Zuerst stellen wir kurz den Rot-Schwarz-Baum vor. Dies ist eine Baumstruktur, die die Baumform automatisch anpasst, wenn sich der Binärbaum in einem unausgeglichenen Zustand befindet Der Baum dreht automatisch die linken und rechten Knoten und ändert die Farbe und passt die Form des Baums an, um einen ausgeglichenen Grundzustand beizubehalten (Zeitkomplexität ist O(logn)), wodurch sichergestellt wird, dass die Sucheffizienz nicht wesentlich verringert wird. Wenn beispielsweise Datenknoten in aufsteigender Reihenfolge von 1 bis 7 eingefügt werden, degeneriert ein gewöhnlicher binärer Suchbaum zu einer verknüpften Liste, aber ein rot-schwarzer Baum passt die Form des Baums kontinuierlich an, um ein grundlegendes Gleichgewicht aufrechtzuerhalten, wie gezeigt in der Abbildung unten. Die Anzahl der zu vergleichenden Knoten bei der Suche nach id = 7 im folgenden rot-schwarzen Baum beträgt 4, wodurch die gute Sucheffizienz des Binärbaums erhalten bleibt. Der Rot-Schwarz-Baum weist eine gute durchschnittliche Sucheffizienz auf und es gibt keine extreme O(n)-Situation. Kann der Rot-Schwarz-Baum als zugrunde liegende Indeximplementierung von MySQL verwendet werden? Tatsächlich haben rot-schwarze Bäume auch einige Probleme. Schauen Sie sich das Beispiel unten an.
Der rot-schwarze Baum fügt nacheinander 1 bis 7 Knoten ein, und die Anzahl der Knoten, die bei der Suche nach id = 7 berechnet werden müssen, beträgt 4.
Der rot-schwarze Baum fügt 1 bis 16 Knoten nacheinander ein und findet die ID = 16 Die Anzahl der zu vergleichenden Knoten beträgt das Sechsfache. Beobachten Sie die Form dieses Baums. Stimmt es, dass die Form des Baums beim sequentiellen Einfügen von Daten immer einen „rechtsgerichteten“ Trend aufweist? Grundsätzlich löst der Rot-Schwarz-Baum den binären Suchbaum nicht vollständig auf. Obwohl dieser „rechtsgerichtete“ Trend weitaus weniger übertrieben ist als der binäre Suchbaum, der zu einer linearen verknüpften Liste degeneriert, ist die grundlegende automatische Inkrementierungsoperation des Primärschlüssels im In der Datenbank beträgt der Primärschlüssel im Allgemeinen Millionen und Dutzende Millionen. Wenn der Rot-Schwarz-Baum ein solches Problem hat, verbraucht er auch viel Suchleistung. Unsere Datenbank kann dieses bedeutungslose Warten nicht tolerieren.
Betrachten Sie nun einen weiteren strengeren selbstausgleichenden Binärbaum, den AVL-Baum. Da der AVL-Baum ein absolut ausgeglichener Binärbaum ist, verbraucht er mehr Leistung bei der Anpassung der Form des Binärbaums.
AVL-Baum fügt nacheinander 1 ~ 16 Knoten ein und findet id=16 Die Anzahl der zu vergleichenden Knoten beträgt 4. In Bezug auf die Sucheffizienz ist die Suchgeschwindigkeit des AVL-Baums höher als die des Rot-Schwarz-Baums (der AVL-Baum umfasst 4 Vergleiche, der Rot-Schwarz-Baum umfasst 6 Vergleiche). Der Form des Baumes nach zu urteilen, haben AVL-Bäume nicht das Problem der „richtigen Neigung“ rot-schwarzer Bäume. Mit anderen Worten: Eine große Anzahl aufeinanderfolgender Einfügungen führt nicht zu einer Verringerung der Abfrageleistung, wodurch das Problem der Rot-Schwarz-Bäume grundsätzlich gelöst wird.
Um die Vorteile von AVL-Bäumen zusammenzufassen: #🎜 🎜 #Gute Suchleistung (O(logn)), es gibt keine extrem ineffiziente Suchsituation.
kann eine Bereichssuche und Datensortierung realisieren.
Es scheint, dass der AVL-Baum als Datenstruktur für die Datensuche wirklich gut ist, aber der AVL-Baum ist nicht für die Indexdatenstruktur von geeignet die MySQL-Datenbank, denn unter Berücksichtigung Schauen wir uns diese Frage an:
Der Engpass bei Datenbankabfragedaten ist Festplatten-E/A. Wenn wir einen AVL-Baum verwenden, speichert jeder unserer Baumknoten nur ein Datenelement Wir können die Daten jeweils nur auf einem Knoten über Festplatten-E/A abrufen. Um beispielsweise die Daten-ID=7 abzufragen, ist dies sehr zeitaufwändig -verbrauchend. Daher müssen wir beim Entwerfen von Datenbankindizes zunächst überlegen, wie wir die Anzahl der Festplatten-E/As so weit wie möglich reduzieren können.
Disk IO hat die Eigenschaft, dass die Zeit, die zum Lesen von 1B-Daten und 1KB-Daten von der Festplatte benötigt wird, grundsätzlich gleich ist. Basierend auf dieser Idee können wir alle Daten auf einem Baumknoten verarbeiten Es ist möglich, Daten an mehreren Orten zu speichern und mit einem Festplatten-IO mehr Daten in den Speicher zu laden. Dies ist das Designprinzip von B-Tree und B+-Tree.
B-Baum
Der folgende B-Baum ist auf die Speicherung von bis zu zwei Schlüsseln pro Knoten beschränkt Ein Schlüssel wird automatisch aufgeteilt. Der folgende B-Baum speichert beispielsweise 7 Daten. Sie müssen nur zwei Knoten abfragen, um den spezifischen Speicherort der Daten mit der ID = 7 zu ermitteln. Das heißt, Sie können die angegebenen Daten mit zwei Festplatten-E / A abfragen der AVL-Baum.
Das Folgende ist ein B-Baum, der 16 Daten speichert. Ebenso kann jeder Knoten bis zu 2 Schlüssel speichern. Das Abfragen der Daten mit der ID = 16 erfordert das Abfragen und Vergleichen von 4 Knoten, was 4 Mal Festplatten-IO bedeutet. Es sieht so aus, als ob die Abfrageleistung mit der des AVL-Baums identisch ist.
Aber wenn man den Verbrauch von Festplatten-E/A beim Lesen eines Datens und beim Lesen von 100 Daten berücksichtigt Die Zeit ist grundsätzlich gleich, dann kann unsere Optimierungsidee dahingehend geändert werden: In einem Festplatten-IO so viele Daten wie möglich in den Speicher einlesen. Dies spiegelt sich direkt in der Struktur des Baums wider, dh die Schlüssel, die jeder Knoten speichern kann, können entsprechend erhöht werden.
Wenn wir das Schlüsselanzahllimit für einen einzelnen Knoten auf 6 setzen, ist für einen B-Baum, der 7 Datenelemente speichert, die erforderliche Festplatten-E/A zum Abfragen der Daten mit der ID=7 2-mal.
Das obige ist der detaillierte Inhalt vonWas ist der Grund, warum der MySQL-Index schnell ist?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!