
Heim >Datenbank >MySQL-Tutorial >So unterscheiden Sie zwischen Groß- und Kleinschreibung beim Abfragen von in MySQL gespeicherten Daten
So unterscheiden Sie zwischen Groß- und Kleinschreibung beim Abfragen von in MySQL gespeicherten Daten

- 王林nach vorne
- 2023-05-31 16:26:313564Durchsuche
Szenenbeschreibung
Nach der heutigen Synchronisierung der Hive-Tabelle mit MySQL ist eine der Spalten die einzige Spalte, aber bei der Abfrage in MySQL sind count und distinct count Die abgefragten Werte sind unterschiedlich. Unter diesem Gesichtspunkt liegen doppelte Daten vor (was nicht der Fall sein sollte, da in Hive die beiden Werte gleich sind). Überprüfen Sie dann die doppelten Daten Und werfen Sie einen Blick darauf, ich habe festgestellt, dass es sich um ein Problem mit der Groß- und Kleinschreibung handelt. Dann habe ich es überprüft und festgestellt, dass in der MySQL-Datenbank standardmäßig alle zugehörigen Vorgänge für Zeichenfolgenfelder „unabhängig von der Groß- und Kleinschreibung“ sind. count 与 distinct count 查询出来的数值是不一样的,这么来看的话是有重复的数据(按理说不应该的,因为在 Hive 中,这两个数值是一样的),那么将重复的数据查出来看了一下,发现是大小写的问题,然后查了一下,发现 MySQL 数据库默认情况下,字符串字段的所有相关运算是大小写"不敏感"的。
这一点与其它流行的数据库都不相同。
解决办法
1. 查询时指定大小写敏感
MySQL 允许在查询的时候指定以大小写敏感方式,需要使用关键字 BINARY,查询如下:
SELECT * FROM student WHERE BINARY name = 'ZhangSan'; --或者 SELECT * FROM student WHERE name = BINARY 'ZhangSan';
很多时候当发现 MySQL 数据库存在上述问题时,系统已经运行了一段时间,如果采用方法二或方法三的代价可能会很大。
使用此方法最大的好处便是可以快速实现功能。
但是这个方法也存在很大的限制:如此可能因为无法使用索引导致查询性能下降。
原因很好理解,因为此时针对查询字段的索引也是按照大小写不敏感方式建立的。
除非数据量不大,或者在你的应用中不在乎这点性能上的损失,那么只能选择方法二或方法三了。
2. 定义表结构时指定字段大小写敏感
在创建表时指定具体的字段大小写敏感,示例如下:
CREATE TABLE student ( ... name VARCHAR(64) BINARY NOT NULL, ... )
关键字 BINARY 指定 name 字段大小写敏感。
如此在查询时就算不使用 BINARY 关键字,查询语句也是大小写敏感的。
在此基础上创建的 name 相关的索引也是大小写敏感的,也就能够使用索引来提高性能。
MySQL 允许在大多数字符串类型上使用 BINARY 关键字,用于指明所有针对该字段的运算是大小写敏感的,更多信息请参见 MySQL 官方文档。
这种方法使得设计者可以精确地控制每个字段是否大小写敏感。在许多系统的设计中,通常期望所有字段都是大小写敏感的,甚至大多数字段都是如此。MySQL 也提供了解决方案,这就要用到方法三。
3. 修改排序规则(COLLATE)
在 MySQL 中执行 show create table <tablename></tablename> 指令,可以看到一张表的建表语句,example 如下:
CREATE TABLE `table1` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`field1` text COLLATE utf8_general_ci NOT NULL COMMENT '字段1',
`field2` varchar(128) COLLATE utf8_general_ci NOT NULL DEFAULT '' COMMENT '字段2',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8_unicode_ci;大部分字段我们都能看懂,但是今天要看的是 COLLATE 关键字。这个值后面对应的 utf8_general_ci 是什么意思呢?下面我们就来了解一下。
COLLATE是用来做什么的?
使用 Navicat 开发的可能会比较眼熟,因为其中的选项中已经给出了答案:
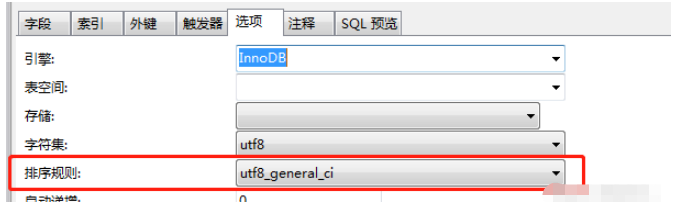
所谓 utf8_general_ci,其实是用来排序的规则。对于 MySQL 中那些字符类型的列,如VARCHAR,CHAR,TEXT 类型的列,都需要有一个 COLLATE 类型来告知 MySQL 如何对该列进行排序和比较。简而言之,COLLATE 会影响到 ORDER BY 语句的顺序,会影响到 WHERE 条件中大于小于号筛选出来的结果,会影响 DISTINCT、GROUP BY、HAVING 语句的查询结果。另外,MySQL 建索引的时候,如果索引列是字符类型,也会影响索引创建,只不过这种影响我们感知不到。总之,凡是涉及到字符类型比较或排序的地方,都会和 COLLATE 有关。
涉及字符串的各种运算其核心必然涉及到采用何种字符排序规则(COLLATE,也有翻译为"核对")。MySQL的字符串运算是否区分大小写,本质上取决于它所使用的COLLATE排序规则。
utf8_general_ci 是一个具体的 COLLATE 取值。每个具体的 COLLATE 都对应唯一的字符集,可以看出该 COLLATE 对应字符集为 utf8。而与大小写敏感问题相关的是其后缀 _ci,MySQL 官方文档对其的解释是 Case Ignore 的缩写,即大小写不敏感。由于 MySQL 将 utf8_general_ci 指定作为字符集 utf8 的默认 COLLATE,这也就导致文章开头所说的现象。与此同时,MySQL 也提供了其它的 COLLATE 取值选项,utf8_bin 就是大小写敏感的。事实上所有大小写敏感的 COLLATE 都以 _bin或 _cs 为后缀,前者是 Binary 的缩写,后者是 Case Sensitive
1. Groß-/Kleinschreibung bei Abfragen angeben
🎜MySQL ermöglicht die Angabe von Groß-/Kleinschreibung bei Abfragen. Sie müssen das SchlüsselwortBINARY verwenden. Die Abfrage lautet wie folgt 🎜Wenn die oben genannten Probleme in der MySQL-Datenbank auftreten, ist das System oft schon seit einiger Zeit in Betrieb und die Kosten für die Verwendung von Methode zwei oder drei können sehr hoch sein. 🎜🎜Der größte Vorteil dieser Methode besteht darin, dass die Funktion schnell implementiert werden kann. 🎜🎜Aber diese Methode weist auch große Einschränkungen auf: Sie kann dazu führen, dass die Abfrageleistung abnimmt, da der Index nicht verwendet werden kann. 🎜🎜Der Grund ist leicht zu verstehen, da der Index für das Abfragefeld ebenfalls ohne Berücksichtigung der Groß- und Kleinschreibung erstellt wird. 🎜🎜 Sofern die Datenmenge nicht groß ist oder Ihnen der Leistungsverlust Ihrer Anwendung egal ist, können Sie nur Methode zwei oder drei wählen. 🎜2. Geben Sie beim Definieren der Tabellenstruktur die Groß-/Kleinschreibung des Felds an.
Bei Feldern muss die Groß-/Kleinschreibung beachtet werden. 🎜🎜Auf diese Weise wird bei der Abfrageanweisung die Groß-/Kleinschreibung beachtet, auch wenn das SchlüsselwortBINARY nicht in der Abfrage verwendet wird. 🎜🎜Der auf dieser Basis erstellte namensbezogene Index unterscheidet auch zwischen Groß- und Kleinschreibung, sodass der Index zur Verbesserung der Leistung verwendet werden kann. 🎜🎜MySQL erlaubt die Verwendung des Schlüsselworts BINARY für die meisten Zeichenfolgentypen, das angibt, dass bei allen Vorgängen in diesem Feld die Groß-/Kleinschreibung beachtet wird. Weitere Informationen finden Sie in der offiziellen MySQL-Dokumentation. 🎜🎜Mit diesem Ansatz können Designer genau steuern, ob in jedem Feld die Groß-/Kleinschreibung beachtet wird. Beim Entwurf vieler Systeme wird häufig erwartet, dass bei allen Feldern oder sogar bei den meisten Feldern die Groß-/Kleinschreibung beachtet wird. MySQL bietet auch eine Lösung, die die Verwendung von Methode drei erfordert. 🎜3. Sortierregeln ändern (COLLATE)
🎜Führen Sie den Befehlshow create table <tablename></tablename> in MySQL aus. Sie können die Tabellenerstellungsanweisung einer Tabelle sehen, das Beispiel lautet wie folgt:🎜CREATE DATABASE <db_name> DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;🎜Wir können die meisten Felder verstehen, aber was wir uns heute ansehen wollen, ist das Schlüsselwort COLLATE. Was bedeutet der diesem Wert entsprechende
utf8_general_ci? Finden wir es weiter unten heraus. 🎜Wofür wird COLLATE verwendet?
🎜Die mit Navicat entwickelten Lösungen kommen Ihnen vielleicht bekannt vor, da die Antworten bereits in den Optionen enthalten sind: 🎜🎜 🎜🎜Der sogenannte
🎜🎜Der sogenannte utf8_general_ci ist eigentlich eine Regel, die zum Sortieren verwendet wird. Für diese Zeichentypspalten in MySQL, wie z. B. VARCHAR-, CHAR- und TEXT-Typspalten, ist ein COLLATE-Typ erforderlich, um MySQL mitzuteilen, wie die Spalte sortiert und verglichen werden soll. Kurz gesagt, COLLATE beeinflusst die Reihenfolge der ORDER BY-Anweisung, der durch das „Größer-als-Kleiner“-Zeichen in der WHERE-Bedingung herausgefilterten Ergebnisse und der DISTINCT-, GROUP BY-, HAVING-Anweisungen. Wenn MySQL außerdem einen Index erstellt und die Indexspalte vom Typ Zeichen ist, wirkt sich dies auch auf die Indexerstellung aus, wir können diese Auswirkung jedoch nicht wahrnehmen. Kurz gesagt: Alles, wo es um den Vergleich oder die Sortierung von Zeichentypen geht, wird mit COLLATE in Verbindung gebracht. 🎜🎜Der Kern verschiedener Operationen mit Zeichenfolgen muss die Zeichensortierregel (COLLATE, auch übersetzt als „Überprüfung“) umfassen. Ob bei den String-Operationen von MySQL die Groß-/Kleinschreibung beachtet wird, hängt im Wesentlichen von der verwendeten COLLATE-Sortierung ab. 🎜🎜utf8_general_ci ist ein spezifischer COLLATE-Wert. Jede spezifische COLLATE entspricht einem eindeutigen Zeichensatz. Es ist ersichtlich, dass der diesem COLLATE entsprechende Zeichensatz utf8 ist. Mit der Frage der Groß-/Kleinschreibung verbunden ist das Suffix _ci. In der offiziellen MySQL-Dokumentation wird es als Abkürzung für Case Ignore erklärt, was bedeutet, dass die Groß-/Kleinschreibung nicht beachtet wird. Da MySQL utf8_general_ci als Standard-COLLATE des Zeichensatzes utf8 angibt, führt dies auch zu dem am Anfang des Artikels erwähnten Phänomen. Gleichzeitig bietet MySQL auch andere COLLATE-Wertoptionen, bei utf8_bin wird die Groß-/Kleinschreibung beachtet. Tatsächlich haben alle COLLATEs, bei denen die Groß-/Kleinschreibung beachtet wird, das Suffix _bin oder _cs. Ersteres ist die Abkürzung für Binary und letzteres ist Groß-/Kleinschreibung Abkürzung für Sensitive. 🎜Der Unterschied zwischen verschiedenen COLLATE
COLLATE hängt normalerweise mit der Datenkodierung (CHARSET) zusammen. Im Allgemeinen unterstützt jedes CHARSET mehrere COLLATEs, und jedes CHARSET hat ein COLLATE als Standardwert angegeben . Beispielsweise ist die Standard-COLLATE für die Latin1-Kodierung latin1_swedish_ci, die Standard-COLLATE für die GBK-Kodierung ist gbk_chinese_ci und der Standardwert für die utf8mb4-Kodierung ist utf8mb4_general_ci. latin1_swedish_ci,GBK 编码的默认 COLLATE 为 gbk_chinese_ci,utf8mb4 编码的默认值为 utf8mb4_general_ci。
这里顺便讲个题外话,MySQL 中有 utf8 和 utf8mb4 两种编码,在 MySQL 中请大家忘记 utf8,永远使用 utf8mb4。这是 MySQL 的一个遗留问题,MySQL 中的 utf8 最多只能支持 3bytes 长度的字符编码,对于一些需要占据 4bytes 的文字,MySQL 的 utf8 就不支持了,要使用 utf8mb4 才行。
很多 COLLATE 都带有 _ci 字样,这是 Case Insensitive 的缩写,即大小写无关,也就是说 "A" 和 "a" 在排序和比较的时候是一视同仁的。selection * from table1 where field1="a" 同样可以把 field1 为 "A" 的值选出来。与此同时,对于那些 _cs 后缀的 COLLATE,则是 Case Sensitive,即大小写敏感的。
在 MySQL 中使用 show collation 指令可以查看到 MySQL 所支持的所有 COLLATE。以 utf8mb4 为例,该编码所支持的所有 COLLATE 如下图所示。

图中我们能看到很多国家的语言自己的排序规则。在国内比较常用的是 utf8mb4_general_ci(默认)、utf8mb4_unicode_ci、utf8mb4_bin 这三个。我们来探究一下这三个的区别:
UTF8mb4_bin的比较方式是将所有字符作为二进制串,然后从最高位到最低位进行比较。所以很显然它是区分大小写的。
而 utf8mb4_unicode_ci 和 utf8mb4_general_ci 对于中文和英文来说,其实是没有任何区别的。对于我们开发的国内使用的系统来说,随便选哪个都行。只是对于某些西方国家的字母来说,utf8mb4_unicode_ci 会比 utf8mb4_general_ci 更符合他们的语言习惯一些,general 是 MySQL 一个比较老的标准了。例如,德语字母 "ß",在 utf8mb4_unicode_ci 中是等价于 "ss" 两个字母的(这是符合德国人习惯的做法),而在 utf8mb4_general_ci 中,它却和字母 "s"
utf8
und verwenden Sie immerutf8mb4#🎜 🎜#. Dies ist ein Legacy-Problem von MySQL. Für einige Texte, die 4 Bytes belegen müssen, muss utf8 verwendet werden.
Viele COLLATEs haben die Wörter _ci, was die Abkürzung für Case Insensitive ist, d. h. Groß-/Kleinschreibung unempfindlich, mit anderen Worten, "A" und "a" werden beim Sortieren und Vergleichen gleich behandelt. selection * from table1 where field1="a" kann auch den Wert von field1 als "A" auswählen. Gleichzeitig ist für COLLATEs mit dem Suffix _cs Case Sensitive, d. h. die Groß-/Kleinschreibung beachtet. Verwenden Sie den Befehl show collation in MySQL, um alle von MySQL unterstützten COLLATEs anzuzeigen. Am Beispiel von utf8mb4 sind alle von dieser Codierung unterstützten COLLATEs wie in der folgenden Abbildung dargestellt. den beiden Buchstaben "ss" in utf8mb4_unicode_ci (dies entspricht den deutschen Gewohnheiten), während in utf8mb4_unicode_ci In utf8mb4_general_ci , es entspricht dem Buchstaben "s". Allerdings sind die subtilen Unterschiede zwischen den beiden Kodierungen für die normale Entwicklung schwer zu erkennen. Wir verwenden Textfelder selten zum direkten Sortieren, selbst wenn ein oder zwei Buchstaben falsch ausgerichtet sind, kann das wirklich katastrophale Folgen für das System haben? Aus verschiedenen Beiträgen und Diskussionen im Internet geht hervor, dass immer mehr Leute die Verwendung von utf8mb4_unicode_ci empfehlen, aber sie sind nicht sehr resistent gegenüber Systemen, die den Standardwert verwenden, und glauben nicht, dass es ein großes Problem gibt. Fazit: Es wird empfohlen, utf8mb4_unicode_ci zu verwenden. Für Systeme, die bereits utf8mb4_general_ci verwenden, ist kein Zeitaufwand für die Änderung erforderlich. Eine weitere zu beachtende Sache ist, dass ab MySQL 8.0 MySQLs Standard-CHARSET nicht mehr Latin1 ist und in utf8mb4 (Referenzlink) geändert wurde, und das Standard-COLLATE wurde ebenfalls in utf8mb4_0900_ai_ci geändert. utf8mb4_0900_ai_ci ist im Allgemeinen eine weitere Unterteilung von Unicode. 0900 bezieht sich auf die Nummer des Unicode-Vergleichsalgorithmus (Version des Unicode-Sortierungsalgorithmus). ; werden gleich behandelt. Zugehöriger Referenzlink 1, zugehöriger Referenzlink 2COLLATE-Einstellungsebene und ihre PrioritätMySQL-Datenbank ermöglicht in
- ,
- Sortierung wird auf drei Ebenen der Tabelle
und
Spalte angegeben. Bei gemeinsamer Angabe lautet die Prioritätsbeziehung: Spalte > Tabelle > -
COLLATE kann auf
Instanzebene #🎜🎜#, #🎜🎜# Bibliotheksebene #🎜🎜#, #🎜🎜# Tabellenebene #🎜🎜#, #🎜🎜# eingestellt werden Spalte Level #🎜🎜# und #🎜🎜#SQL-Bezeichnung #🎜🎜#. Bei gleichzeitiger Angabe lautet die Prioritätsbeziehung: SQL-Spezifikation > #🎜🎜##🎜🎜##🎜🎜##🎜🎜#Die COLLATE-Einstellung auf Instanzebene ist die Systemvariable collation_connection in der MySQL-Konfigurationsdatei oder der Startanweisung. #🎜🎜##🎜🎜##🎜🎜##🎜🎜#Die COLLATE-Anweisung für die Einstellung der Bibliotheksebene lautet wie folgt: #🎜🎜#
CREATE DATABASE <db_name> DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
如果库级别没有设置 CHARSET 和 COLLATE,则库级别默认的 CHARSET 和 COLLATE 使用实例级别的设置。在 MySQL 8.0 以下版本中,你如果什么都不修改,默认的 CHARSET 是 Latin1,默认的 COLLATE 是 latin1_swedish_ci。从 MySQL 8.0 开始,默认的 CHARSET 已经改为了 utf8mb4,默认的 COLLATE 改为了 utf8mb4_0900_ai_ci。
表级别的 COLLATE 设置,则是在 CREATE TABLE 的时候加上相关设置语句,例如:
CREATE TABLE table_name ( …… ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT = '表注释';
如果表级别没有设置 CHARSET 和 COLLATE,则表级别会继承库级别的 CHARSET 与 COLLATE。
列级别的设置,则在 CREATE TABLE 中声明列的时候指定,例如
CREATE TABLE ( `field1` VARCHAR(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '字段1', …… ) ……
如果列级别没有设置 CHARSET 和 COLATE,则列级别会继承表级别的 CHARSET 与 COLLATE。
最后,你也可以在写 SQL 查询的时候显示声明 COLLATE 来覆盖任何库表列的 COLLATE 设置,不太常用,了解即可:
SELECT DISTINCT field1 COLLATE utf8mb4_general_ci FROM table1; SELECT field1, field2 FROM table1 ORDER BY field1 COLLATE utf8mb4_unicode_ci;
如果全都显示设置了,那么优先级顺序是 SQL 语句 > 列级别设置 > 表级别设置 > 库级别设置 > 实例级别设置。
也就是说列上所指定的 COLLATE可以覆盖表上指定的 COLLATE,表上指定的 COLLATE 可以覆盖库级别的 COLLATE。如果没有指定,则继承下一级的设置。
即列上面没有指定 COLLATE,则该列的 COLLATE 和表上设置的一样。
Das obige ist der detaillierte Inhalt vonSo unterscheiden Sie zwischen Groß- und Kleinschreibung beim Abfragen von in MySQL gespeicherten Daten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!