
Heim >Datenbank >MySQL-Tutorial >Welche Kenntnisse gibt es zur MySQL-Datenbankoptimierung?
Welche Kenntnisse gibt es zur MySQL-Datenbankoptimierung?

- PHPznach vorne
- 2023-05-31 16:04:061343Durchsuche
Einerseits besteht die Datenbankoptimierung darin, die Engpässe des Systems zu identifizieren und die Gesamtleistung der MySQL-Datenbank zu verbessern. Andererseits sind angemessene Strukturdesigns und Parameteranpassungen erforderlich, um die Reaktionsgeschwindigkeit des Benutzers zu verbessern. Es ist auch notwendig, Systemressourcen so weit wie möglich zu schonen, damit der Benutzer das System stärker belasten kann.
1. Optimierungsübersicht
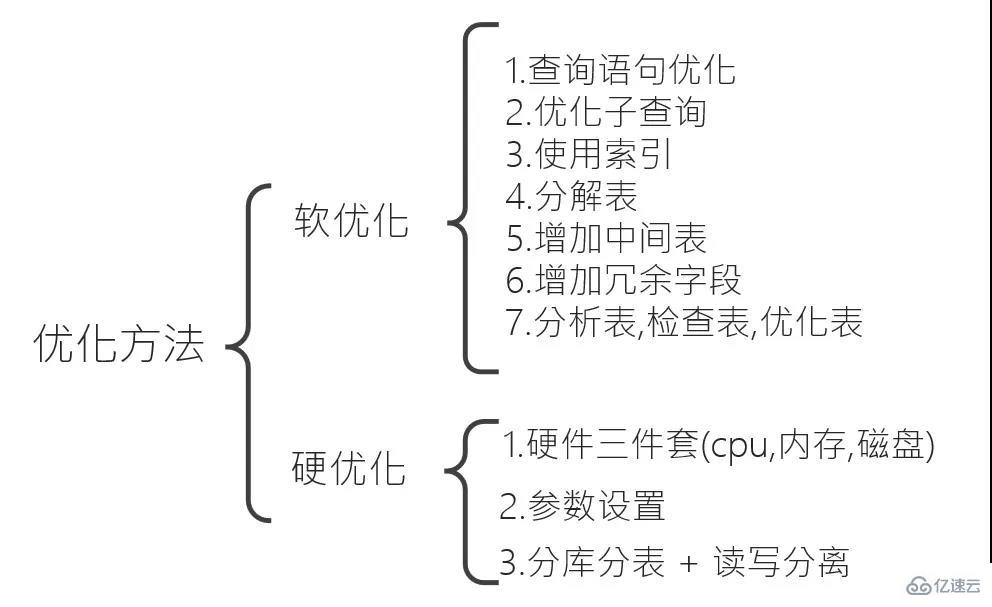
2. Optimieren Sie
Der Autor unterteilt die Optimierung in zwei Kategorien: weiche Optimierung und harte Optimierung. Die weiche Optimierung umfasst im Allgemeinen den Betrieb der Datenbank, während die harte Optimierung den Betrieb der Serverhardware und der Parametereinstellungen umfasst.
2.1 Sanfte Optimierung
2.1.1 Optimierung der Abfrageanweisung
1. Zunächst können wir den Befehl EXPLAIN oder DESCRIBE (Abkürzung: DESC) verwenden, um die Ausführungsinformationen einer Abfrageanweisung zu analysieren.
2. Beispiel:
DESC SELECT * FROM `user`
Anzeige:

Es werden Informationen wie die Anzahl der gelesenen Index- und Abfragedaten angezeigt
2.1.2 Unterabfrage optimieren
Versuchen Sie in MySQL, JOIN anstelle von Unterabfragen zu verwenden. Beim Verschachteln von Abfragen wird eine temporäre Tabelle erstellt, während die Verknüpfungsabfrage keinen großen Systemaufwand verursacht temporäre Tabelle, daher effizienter als verschachtelte Unterabfragen.
2.1.3 Index verwenden
Die Indizierung ist eine der wichtigsten Möglichkeiten, die Geschwindigkeit von Datenbankabfragen zu verbessern. Eine ausführlichere Einführung finden Sie im Artikel des Autors:
#🎜🎜 # 1. Analysetabelle: Verwenden Sie das Schlüsselwort ANALYZE, z. B. ANALYZE TABLE user;
Op: Gibt den auszuführenden Vorgang an. Msg_type: Informationstyp, einschließlich Status, Info, Hinweis, Warnung, Fehler.
-
Msg_text: Informationen anzeigen.
2. Tabelle prüfen: Verwenden Sie das Schlüsselwort CHECK, z. B. CHECK TABLE user [option]
Option ist nur für MyISAM gültig, mit insgesamt fünf Parameterwerten: - SCHNELL: Leitungen nicht scannen, nicht auf schlechte Verbindungen prüfen. SCHNELL: Überprüfen Sie nur Tabellen, die nicht korrekt geschlossen sind. GEÄNDERT: Nur Tabellen prüfen, die seit der letzten Prüfung geändert wurden und Tabellen, die nicht korrekt geschlossen wurden. MITTEL: Scannen Sie Zeilen, um zu überprüfen, ob die gelöschte Verbindung gültig ist, und berechnen Sie außerdem Schlüsselwortprüfsummen für jede Zeile.
ERWEITERT: Die umfassendste Inspektion, umfassende Suche nach Schlüsselwörtern in jeder Zeile.
3. Optimieren Sie die Tabelle: Verwenden Sie das Schlüsselwort OPTIMIZE, z. B. OPTIMIZE [LOCAL|NO_WRITE_TO_BINLOG] TABLE user;
-
LOCAL|NO_WRITE_TO_BINLOG bedeutet, dass nicht in das Protokoll geschrieben wird. Die Dateifragmentierung kann durch die OPTIMIZE TABLE-Anweisung beseitigt werden, und während der Ausführung werden schreibgeschützte Sperren hinzugefügt. 🎜🎜 #
2.2 Harte Optimierung
2.2.1 Dreiteiliges Hardware-Set
1. Konfigurieren Sie Multi-Core- und Hochfrequenz-CPU. Multi-Core kann mehrere Threads ausführen.- 2. Konfigurieren Sie einen großen Speicher und erhöhen Sie den Speicher, um die Cache-Kapazität zu erhöhen, wodurch die E/A-Zeit der Festplatte verkürzt und die Reaktionsgeschwindigkeit verbessert wird.
3. Konfigurieren Sie Hochgeschwindigkeitsfestplatten oder verteilen Sie sie angemessen: Hochgeschwindigkeitsfestplatten verbessern die E/A, und verteilte Festplatten können die Fähigkeit paralleler Vorgänge verbessern.
2.2.2 Datenbankparameter optimierenDie Optimierung der Datenbankparameter kann die Ressourcennutzung verbessern und dadurch die Leistung des MySQL-Servers verbessern. Die Parameter, die einen größeren Einfluss auf die Leistung haben, sind unten aufgeführt. 🎜🎜#
key_buffer_size: Indexpuffergröße- table_cache: Die Anzahl der Tabellen, die gleichzeitig geöffnet werden können
query_cache_size und query_cache_type: Ersteres ist die Größe des Abfragepuffers, letzteres ist der Schalter des vorherigen Parameters. 0 bedeutet, den Puffer nicht zu verwenden, 1 bedeutet, den Puffer zu verwenden, kann aber in der Abfrage verwendet werden. SQL_NO_CACHE bedeutet, den Puffer nicht zu verwenden Puffer, 2 bedeutet in der Abfrage Es wird deutlich darauf hingewiesen, dass der Puffer nur verwendet werden sollte, wenn der Puffer verwendet wird, also SQL_CACHE.
sort_buffer_size: Sortierpuffer
2.2.3 Unterdatenbank und Untertabelle
Da die Datenbank zu stark belastet ist, besteht das erste Problem darin, dass die Systemleistung in Spitzenzeiten reduziert werden kann, da eine übermäßige Datenbanklast Auswirkungen auf die Leistung hat. Noch eine Frage: Was sollten Sie tun, wenn Ihre Datenbank aufgrund übermäßigen Drucks abstürzt? Zu diesem Zeitpunkt müssen Sie das System also in Datenbanken und Tabellen + Lese-/Schreibtrennung unterteilen, dh eine Datenbank in mehrere Datenbanken aufteilen, diese auf mehreren Datenbankdiensten bereitstellen und dann als Hauptdatenbank für die Verarbeitung von Schreibanforderungen dienen. Anschließend stellt jede Master-Bibliothek mindestens eine Slave-Bibliothek bereit, und die Slave-Bibliothek verarbeitet Leseanforderungen.
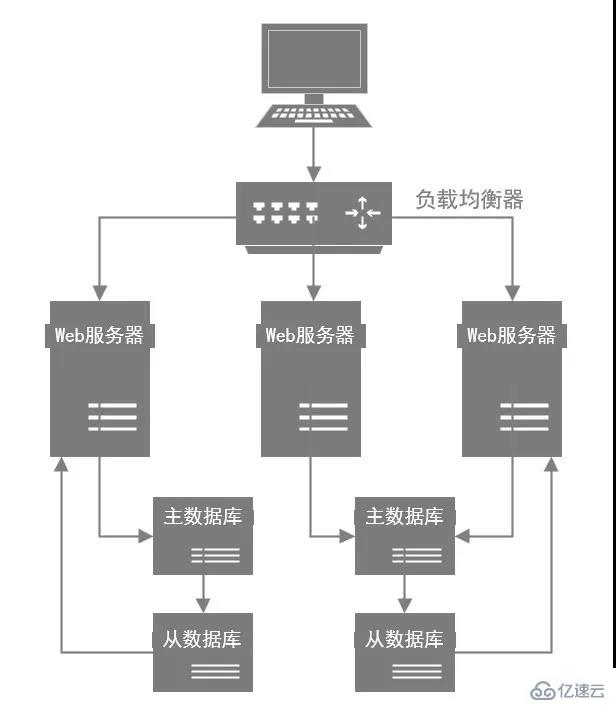
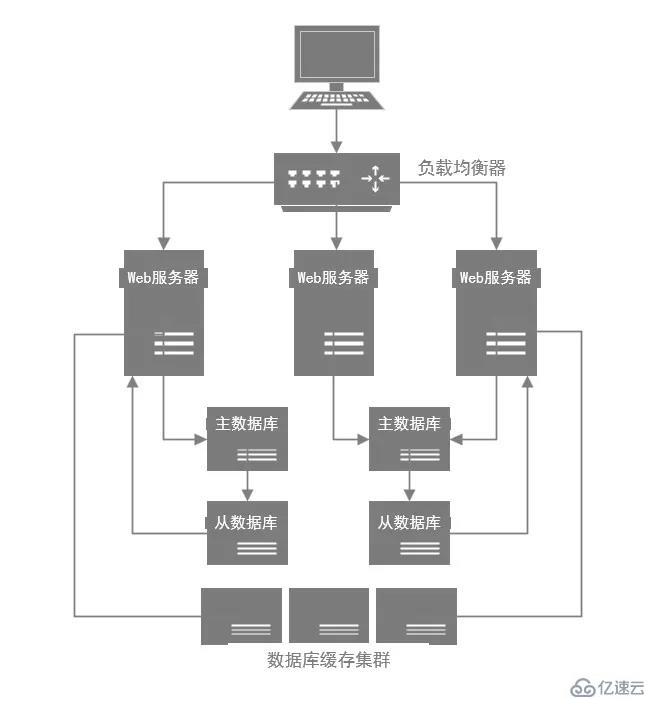
2.2.4 Cache-Cluster
Wenn die Anzahl der Benutzer zunimmt, können Sie weiterhin Maschinen hinzufügen. Wenn Sie beispielsweise weiterhin Maschinen auf Systemebene hinzufügen, können Sie höhere gleichzeitige Anforderungen verarbeiten. Wenn dann die Schreibparallelität auf Datenbankebene immer höher wird, wird der Datenbankserver erweitert und die Maschine wird durch Unterdatenbank- und Tabellen-Sharding erweitert. Wenn die Leseparallelität auf Datenbankebene immer höher wird, erhöht sich die Kapazität erweitert werden und weitere Slave-Datenbanken hinzugefügt werden. Hier gibt es jedoch ein großes Problem: Die Datenbank selbst wird nicht tatsächlich für die Übertragung hoher gleichzeitiger Anforderungen verwendet. Daher liegt die von einer einzelnen Datenbankmaschine pro Sekunde ausgeführte Parallelität im Allgemeinen in der Größenordnung von Tausenden, und die von der Datenbank verwendeten Maschinen sind es auch relativ hoch konfigurierte, relativ teure Maschinen, die Kosten sind sehr hoch. Wenn man einfach immer wieder Maschinen hinzufügt, ist das eigentlich falsch. Daher ist der Cache normalerweise in Architekturen mit hoher Parallelität enthalten. Das Cache-System ist für eine hohe Parallelität ausgelegt. Daher beträgt die von einer einzelnen Maschine übertragene Parallelität Zehntausende oder sogar Hunderttausende pro Sekunde, und die Tragfähigkeit einer hohen Parallelität ist ein bis zwei Größenordnungen höher als die eines Datenbanksystems. Daher können Sie basierend auf den Geschäftsmerkmalen des Systems vollständig einen Cache-Cluster für Anforderungen einführen, die weniger Schreiben und mehr Lesen erfordern. Insbesondere wird beim Schreiben in die Datenbank gleichzeitig eine Kopie der Daten in den Cache-Cluster geschrieben, und dann wird der Cache-Cluster für die Übertragung der meisten Leseanforderungen verwendet. In diesem Fall können durch Cache-Clustering weniger Maschinenressourcen verwendet werden, um eine höhere Parallelität zu hosten.
Das obige ist der detaillierte Inhalt vonWelche Kenntnisse gibt es zur MySQL-Datenbankoptimierung?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!