
Heim >Datenbank >MySQL-Tutorial >Was ist das MVCC-Prinzip von MySQL InnoDB?
Was ist das MVCC-Prinzip von MySQL InnoDB?

- 王林nach vorne
- 2023-05-30 13:20:54797Durchsuche

MVCC steht für Multi-Version Concurrency Control, eine Parallelitätskontrolle für mehrere Versionen, die hauptsächlich der Verbesserung der Parallelitätsleistung der Datenbank dient. Wenn eine Lese- oder Schreibanforderung für dieselbe Datenzeile auftritt, wird diese gesperrt und blockiert. MVCC verwendet eine optimiertere Methode zur Verarbeitung von Lese- und Schreibanforderungen und kann Konflikte bei Lese- und Schreibanforderungen ohne Sperren verarbeiten. Dies bezieht sich auf das Lesen von Schnappschüssen, nicht auf das aktuelle Lesen, bei dem es sich um einen pessimistischen Sperrmechanismus handelt. In den folgenden Studien lernen wir, wie Lese- und Schreibvorgänge ohne Sperren ausgeführt werden, und die Konzepte des Snapshot-Lesens und des aktuellen Lesens werden ebenfalls analysiert.
MySQL kann Phantom-Leseprobleme unter der Isolationsstufe REPEATABLE READ weitgehend vermeiden.
Versionskette
Wir wissen, dass für Tabellen, die die InnoDB-Speicher-Engine verwenden, die Clustered-Index-Datensätze zwei erforderliche versteckte Spalten enthalten (row_id ist nicht erforderlich, die von uns erstellte Tabelle verfügt über einen Primärschlüssel oder einen nicht NULL UNIQUE-Schlüssel die Spalte row_id nicht einschließen):
trx_id: Jedes Mal, wenn eine Transaktion einen Clustered-Index-Datensatz ändert, wird die Transaktions-ID der Transaktion der ausgeblendeten Spalte trx_id zugewiesen.
roll_pointer: Jedes Mal, wenn ein Clustered-Index-Datensatz geändert wird, wird die alte Version in das Rückgängig-Protokoll geschrieben. Dann entspricht diese versteckte Spalte einem Zeiger, der verwendet werden kann, um den Datensatz vor der Änderung zu finden.
Um dieses Problem zu veranschaulichen, erstellen wir eine Demotabelle:
CREATE TABLE `teacher` ( `number` int(11) NOT NULL, `name` varchar(100) DEFAULT NULL, `domain` varchar(100) DEFAULT NULL, PRIMARY KEY (`number`)) ENGINE=InnoDB DEFAULT CHARSET=utf8
Fügen Sie dann ein Datenelement in diese Tabelle ein:
mysql> insert into teacher values(1, 'J', 'Java');Query OK, 1 row affected (0.01 sec)
Die Daten sehen jetzt so aus:
mysql> select * from teacher; +--------+------+--------+ | number | name | domain | +--------+------+--------+ | 1 | J | Java | +--------+------+--------+ 1 row in set (0.00 sec)
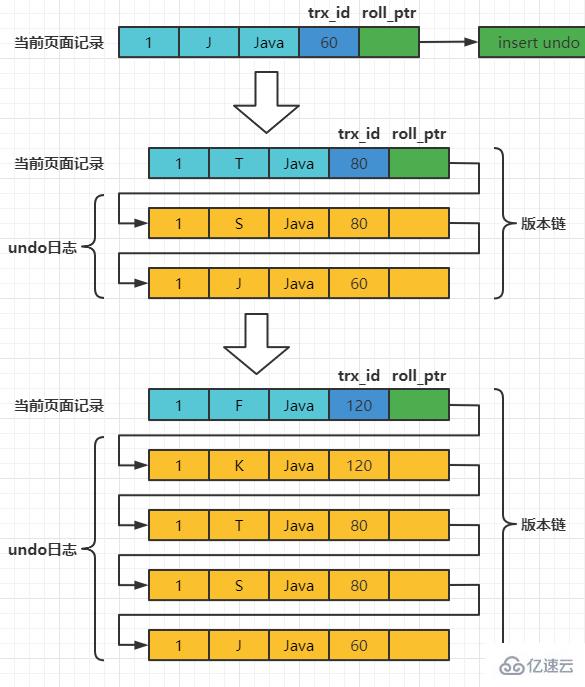
Nehmen Sie an, dass die Transaktions-ID des eingefügten Datensatzes ist ist 60, dann sieht das schematische Diagramm des Datensatzes in diesem Moment wie folgt aus:

Angenommen, zwei Transaktionen mit den Transaktions-IDs 80 und 120 führen UPDATE-Vorgänge für diesen Datensatz aus. Der Vorgang ist wie folgt:
| Trx80 | Trx120 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| beginnen | ||||||||||||||
| beginnen | ||||||||||||||
| Lehrersatzname='S' aktualisieren, wo. Nummer= 1; | ||||||||||||||
| Lehrer aktualisieren set name='T ' where number=1; | ||||||||||||||
| commit | ||||||||||||||
| update teacher set name = 'K' where number=1; =' F' where number=1 ; | ||||||||||||||
| commit | ||||||||||||||
|
每次对记录进行改动,都会记录一条undo日志,每条undo日志也都有一个roll_pointer属性(INSERT操作对应的undo日志没有该属性,因为该记录并没有更早的版本),可以将这些undo日志都连起来,串成一个链表,所以现在的情况就像下图一样:
对该记录每次更新后,都会将旧值放到一条undo日志中,就算是该记录的一个旧版本,随着更新次数的增多,所有的版本都会被roll_pointer属性连接成一个链表,我们把这个链表称之为版本链,版本链的头节点就是当前记录最新的值。另外,每个版本中还包含生成该版本时对应的事务id。于是可以利用这个记录的版本链来控制并发事务访问相同记录的行为,那么这种机制就被称之为多版本并发控制(Mulit-Version Concurrency Control MVCC)。 ReadView对于使用READ UNCOMMITTED隔离级别的事务来说,由于可以读到未提交事务修改过的记录,所以直接读取记录的最新版本就好了。 对于使用SERIALIZABLE隔离级别的事务来说,InnoDB使用加锁的方式来访问记录。 对于使用READ COMMITTED和REPEATABLE READ隔离级别的事务来说,都必须保证读到已经提交了的事务修改过的记录,也就是说假如另一个事务已经修改了记录但是尚未提交,是不能直接读取最新版本的记录的,核心问题就是:READ COMMITTED和REPEATABLE READ隔离级别在不可重复读和幻读上的区别,这两种隔离级别关键是需要判断一下版本链中的哪个版本是当前事务可见的。 为此,InnoDB提出了一个ReadView的概念,这个ReadView中主要包含4个比较重要的内容:
有了这个ReadView,这样在访问某条记录时,只需要按照下边的步骤判断记录的某个版本是否可见:
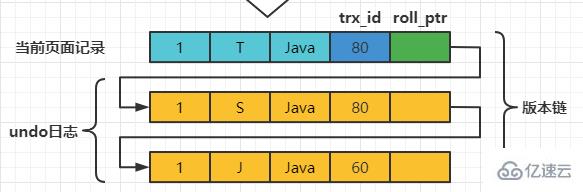
在MySQL中,READ COMMITTED和REPEATABLE READ隔离级别的的一个非常大的区别就是它们生成ReadView的时机不同。 我们还是以表teacher为例,假设现在表teacher中只有一条由事务id为60的事务插入的一条记录,接下来看一下READ COMMITTED和REPEATABLE READ所谓的生成ReadView的时机不同到底不同在哪里。 READ COMMITTED每次读取数据前都生成一个ReadView假设现在系统里有两个事务id分别为80、120的事务在执行: # Transaction 80 set session transaction isolation level read committed; begin update teacher set name='S' where number=1; update teacher set name='T' where number=1; 此刻,表teacher中number为1的记录得到的版本链表如下所示:
假设现在有一个使用READ COMMITTED隔离级别的事务开始执行: set session transaction isolation level read committed; # 使用READ COMMITTED隔离级别的事务 begin; # SELECE1:Transaction 80、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J' 这个SELECE1的执行过程如下:
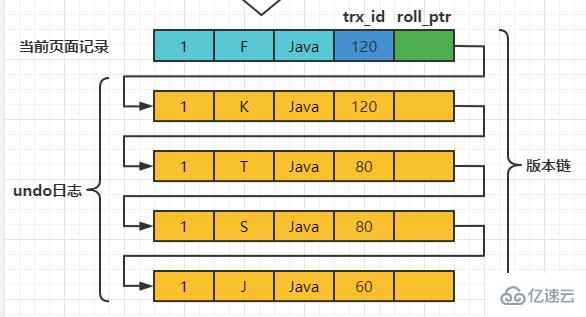
之后,我们把事务id为80的事务提交一下,然后再到事务id为120的事务中更新一下表teacher 中number为1的记录: set session transaction isolation level read committed; # Transaction 120 begin update teacher set name='K' where number=1; update teacher set name='F' where number=1; 此刻,表teacher 中number为1的记录的版本链就长这样:
然后再到刚才使用READ COMMITTED隔离级别的事务中继续查找这个number 为1的记录,如下: # 使用READ COMMITTED隔离级别的事务 begin; # SELECE1:Transaction 80、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J' # SELECE2:Transaction 80提交、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'T' 这个SELECE2 的执行过程如下:
以此类推,如果之后事务id为120的记录也提交了,再次在使用READCOMMITTED隔离级别的事务中查询表teacher中number值为1的记录时,得到的结果就是’F’了,具体流程我们就不分析了。 总结一下就是:使用READCOMMITTED隔离级别的事务在每次查询开始时都会生成一个独立的ReadView。 REPEATABLE READ —— 在第一次读取数据时生成一个ReadView对于使用REPEATABLE READ隔离级别的事务来说,只会在第一次执行查询语句时生成一个ReadView,之后的查询就不会重复生成了。我们还是用例子看一下是什么效果。 假设现在系统里有两个事务id分别为80、120的事务在执行: # Transaction 80 begin update teacher set name='S' where number=1; update teacher set name='T' where number=1; 此刻,表teacher中number为1的记录得到的版本链表如下所示:
假设现在有一个使用REPEATABLE READ隔离级别的事务开始执行: # 使用REPEATABLE READ隔离级别的事务 begin; # SELECE1:Transaction 80、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J' 这个SELECE1的执行过程如下(与READ COMMITTED的过程一致):
之后,我们把事务id为80的事务提交一下,然后再到事务id为120的事务中更新一下表teacher 中number为1的记录: # Transaction 80 begin update teacher set name='K' where number=1; update teacher set name='F' where number=1; 此刻,表teacher 中number为1的记录的版本链就长这样:
然后再到刚才使用REPEATABLE READ隔离级别的事务中继续查找这个number为1的记录,如下: # 使用REPEATABLE READ隔离级别的事务 begin; # SELECE1:Transaction 80、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J' # SELECE2:Transaction 80提交、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J' 这个SELECE2的执行过程如下:
可重复读的意思是两次SELECT查询的结果相同,记录的列值均为'J'。 如果我们之后再把事务id为120的记录提交了,然后再到刚才使用REPEATABLE READ隔离级别的事务中继续查找这个number为1的记录,得到的结果还是’J’,具体执行过程大家可以自己分析一下。 MVCC下的幻读现象和幻读解决前面我们已经知道了,REPEATABLE READ隔离级别下MVCC可以解决不可重复读问题,那么幻读呢?MVCC是怎么解决的?幻读是一个事务按照某个相同条件多次读取记录时,后读取时读到了之前没有读到的记录,而这个记录来自另一个事务添加的新记录。 我们可以想想,在REPEATABLE READ隔离级别下的事务T1先根据某个搜索条件读取到多条记录,然后事务T2插入一条符合相应搜索条件的记录并提交,然后事务T1再根据相同搜索条件执行查询。结果会是什么?按照ReadView中的比较规则: 无论事务T2是否先于事务T1开启,事务T1都无法观察到T2的提交。请根据以上所述的版本历史、阅读视图与可视性判断规则,自行进行分析。 但是,在REPEATABLE READ隔离级别下InnoDB中的MVCC可以很大程度地避免幻读现象,而不是完全禁止幻读。怎么回事呢?我们来看下面的情况:
Nun, was ist los? Transaktion T1 weist offensichtlich ein Phantomlesephänomen auf. Unter der Isolationsstufe REPEATABLE READ generiert T1 eine ReadView, wenn zum ersten Mal eine normale SELECT-Anweisung ausgeführt wird, und dann fügt T2 einen neuen Datensatz in die Lehrertabelle ein und übermittelt ihn. ReadView kann T1 nicht daran hindern, die UPDATE- oder DELETE-Anweisung auszuführen, um den neu eingefügten Datensatz zu ändern (da T2 bereits übermittelt wurde, führt eine Änderung des Datensatzes nicht zu einer Blockierung), aber auf diese Weise wird der Wert der ausgeblendeten Spalte trx_id dieses neuen Datensatzes geändert be Es wird zur Transaktions-ID von T1. Danach kann T1 diesen Datensatz sehen, wenn er eine gewöhnliche SELECT-Anweisung zum Abfragen dieses Datensatzes verwendet, und diesen Datensatz an den Client zurückgeben. Aufgrund dieses besonderen Phänomens kann MVCC Phantom-Lesevorgänge nicht vollständig eliminieren. MVCC-ZusammenfassungAus der obigen Beschreibung können wir ersehen, dass sich das sogenannte MVCC (Multi-Version ConcurrencyControl, Multi-Version-Parallelitätskontrolle) auf die Verwendung der beiden Isolationsstufen READ COMMITTD und REPEATABLE READ zur Ausführung gewöhnlicher Transaktionen bezieht Bei der SELECT-Operation handelt es sich um den Prozess des Zugriffs auf die aufgezeichnete Versionskette. Dadurch können die Lese-/Schreib- und Schreib-/Lesevorgänge verschiedener Transaktionen gleichzeitig ausgeführt werden, wodurch die Systemleistung verbessert wird. Ein großer Unterschied zwischen den beiden Isolationsstufen READ COMMITTD und REPEATABLE READ besteht darin, dass der Zeitpunkt der Generierung von ReadView unterschiedlich ist. READ COMMITTD generiert vor jeder gewöhnlichen SELECT-Operation eine ReadView, während REPEATABLE READ nur zum ersten Mal eine ReadView generiert Generieren Sie einfach eine ReadView vor der SELECT-Operation und verwenden Sie diese ReadView für nachfolgende Abfragevorgänge wieder, wodurch das Phänomen des Phantomlesens grundsätzlich vermieden wird. Wir sagten zuvor, dass die Ausführung einer DELETE-Anweisung oder einer UPDATE-Anweisung, die den Primärschlüssel aktualisiert, den entsprechenden Datensatz nicht sofort von der Seite löscht, sondern eine sogenannte Löschmarkierungsoperation ausführt, die dem einfachen Setzen von a entspricht Löschflag für den Datensatz. Dies gilt hauptsächlich für MVCC. Darüber hinaus wird das sogenannte MVCC nur dann wirksam, wenn wir gewöhnliche SEELCT-Abfragen durchführen. Alle SELECT-Anweisungen, die wir bisher gesehen haben, sind gewöhnliche Abfragen. Darüber werden wir später sprechen. |
Das obige ist der detaillierte Inhalt vonWas ist das MVCC-Prinzip von MySQL InnoDB?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!