
Heim >Betrieb und Instandhaltung >Betrieb und Wartung von Linux >Was bedeutet die Linux-I-Node-Nummer?
Was bedeutet die Linux-I-Node-Nummer?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-29 17:19:412192Durchsuche
Die Inode-Nummer ist die Nummernkennung, die zur Unterscheidung verschiedener Dateien im Linux-System verwendet wird. Linux verwendet intern Inode-Nummern zur Identifizierung von Dateien anstelle von Dateinamen. Für das System sind Dateinamen ein anderer Name für Inode-Nummern, der für Benutzer praktisch ist, um Dateien zu identifizieren. Es besteht eine Eins-zu-eins-Entsprechung zwischen Dateinamen und Inode Zahlen, und jede Inode-Nummer entspricht einem Dateinamen.
1. i-Knoten unter Linux
Unter Linux bezieht sich i-Knoten auf den Inode-Knoten.
Unter Linux erfolgt die Dateisuche nicht nach Dateinamen. Tatsächlich wird die Suche und Positionierung von Dateien über i-Knoten erreicht. Wir können den i-Knoten als Zeiger-Fip visualisieren. Wenn eine Datei auf der Festplatte gespeichert wird, wird die Datei definitiv an einem Speicherort auf der Festplatte gespeichert. Sie können sich vorstellen, dass wir die Adresse der Dateidaten kennen, wenn wir sie lesen und lesen möchten Schreiben Sie die Datei. Können wir zu diesem Zeitpunkt einfach diese Adresse verwenden, um die Datei zu finden?
Ja, unter Linux kann man sich den i-Node tatsächlich so vorstellen. Der i-Node wird als Adresse betrachtet, die auf den Dateispeicherbereich auf der Festplatte verweist. Normalerweise können wir diese Adresse nicht direkt verwenden, sondern müssen sie indirekt über den Dateinamen verwenden. Tatsächlich enthält der i-Knoten neben der Adresse des Dateidatenspeicherbereichs auch viele andere Informationen, wie z. B. Dateigröße, Dateiinformationen usw. Der i-Knoten speichert den Dateinamen jedoch nicht. Der Dateiname wird in einem Verzeichniseintrag gespeichert. Jeder Verzeichniseintrag enthält den Dateinamen und den I-Node.
Wir können ein Diagramm verwenden, um die Beziehung zwischen Verzeichniselementen, i-Knoten und Dateidaten anzuzeigen.
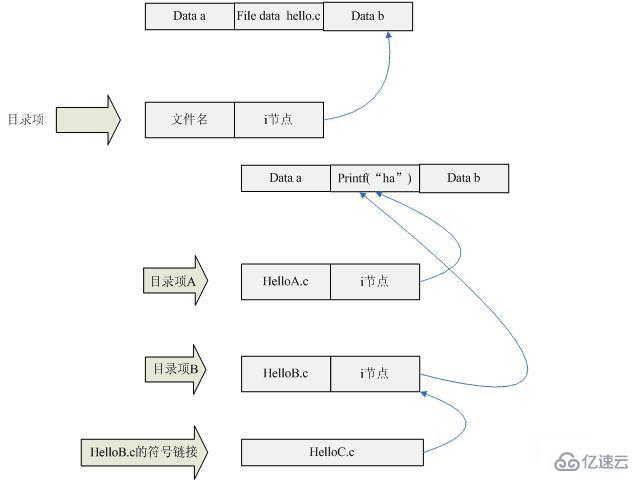
Wie Sie auf dem Bild oben sehen können, enthält der Verzeichniseintrag den Dateinamen und den i-Knoten.
Gleichzeitig werden Sie feststellen, dass in der obigen Abbildung die i-Knoten von Verzeichniselement A und Verzeichniselement B auf denselben Speicherbereich verweisen und dieser Speicherbereich die Daten von printf speichert ( "Ha").
Das bedeutet, dass die Inhalte von helloA.c und helloB.c gleich sind.
i Knotennummer
Jeder Inode hat eine Nummer (d. h. Inode-Nummer), und das Betriebssystem verwendet die Inode-Nummer, um verschiedene Dateien zu identifizieren .
————Linux verwendet intern Inode-Nummern, um Dateien anstelle von Dateinamen zu identifizieren. Für das System ist der Dateiname ein Alias für die Inode-Nummer, was für Benutzer praktisch ist, um Dateien zu identifizieren Dateiname und Inode-Nummer Es besteht eine Eins-zu-Eins-Entsprechung, und jede Inode-Nummer entspricht einem Dateinamen.
Die Inode-Nummer ist der einzige vom System erkannte Code, und der Dateiname dient nur der Benutzeridentifizierung. Die Inode-Tabelle (Indexknoten) enthält eine Liste aller Dateien im Dateisystem (Indexknoten) befindet sich in einem Tabelleneintrag, der Informationen (Metadaten) über die Datei enthält.
Die Struktur der Festplattenpartition:
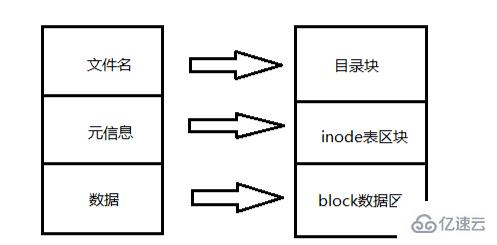
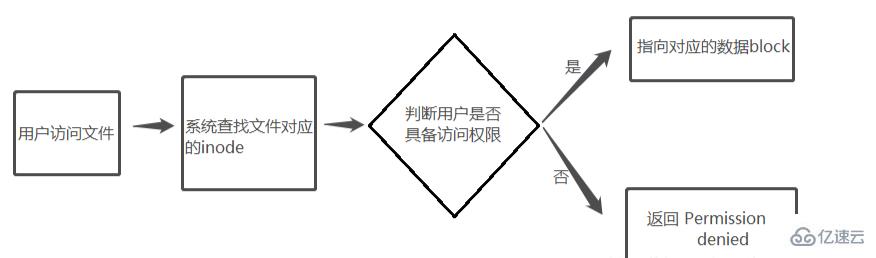
Wenn der Benutzer versucht, darauf zuzugreifen Das Linux-System sucht zunächst anhand des Dateinamens nach der entsprechenden Inode-Nummer. Überprüfen Sie anhand der Inode-Informationen, ob der Benutzer über die Berechtigung zum Zugriff auf die Datei verfügt ; wenn ja, zeigen Sie auf den entsprechenden Datenblock und lesen Sie die Daten; wenn nicht, werden sie zurückgegeben.
Einfacher Prozess für den Zugriff auf Dateien:
2. Linux-Dateien Speicher
2.1 Die Begrenzung der Anzahl der Inodes
Inodes verbrauchen ebenfalls viel Speicherplatz, also Beim Formatieren unterteilt das Betriebssystem die Festplatte automatisch in zwei Bereiche: Der eine ist der Datenbereich, in dem Dateidaten gespeichert werden, der andere ist der Inode-Bereich, in dem die im Inode enthaltenen Informationen gespeichert werden. Die Größe jedes Inodes beträgt im Allgemeinen 128 Byte oder 256 Byte.
Normalerweise müssen Sie nicht auf die Größe eines einzelnen Inodes achten, sondern müssen sich auf die Gesamtzahl der Inodes konzentrieren Inodes wurden während der Formatierung ermittelt
——Warum müssen wir uns auf die Gesamtzahl der Inodes konzentrieren? Weil Wenn die Inodes aufgebraucht sind, können keine neuen Dateien erstellt werden, selbst wenn noch Platz auf dem ist disk , denn beim Erstellen einer Datei ist eine entsprechende Inode-Nummer erforderlich, und natürlich können neue Dateien nicht ohne Inode erstellt werden.
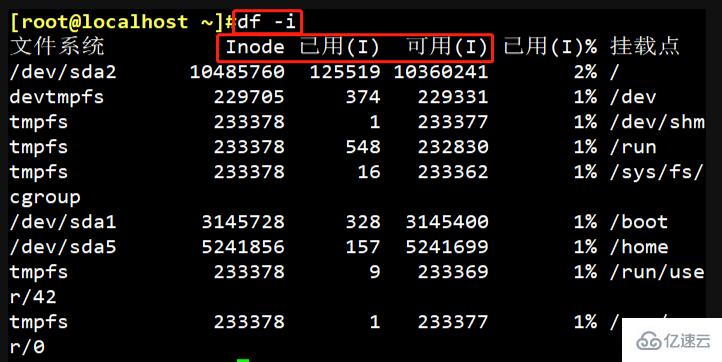
Führen Sie den Befehl „df-i“ aus, um die Gesamtzahl der Inodes entsprechend jeder Festplattenpartition und die Anzahl der verwendeten Inodes anzuzeigen.
2.2 Der Inhalt von Inode
inode enthält Die Metainformationen der Datei umfassen insbesondere den folgenden Inhalt:
Die Anzahl der Bytes der Datei
- #🎜 🎜#Die Anzahl der Bytes der Dateibesitzer-Benutzer-ID
- Dateigruppen-ID
- Datei gelesen, Schreib- und Ausführungsberechtigungen#🎜 🎜# Die Anzahl der Links, d. h. wie viele Dateien auf diesen Inode verweisen
- #🎜 🎜#Der Zeitstempel der Datei #🎜 🎜#
Zwei Möglichkeiten, die Inode-Informationen einer Datei anzuzeigen
# 🎜🎜#
Methode eins: stat [Dateiname]
Atvantations: Sie können die detaillierten Informationen der Datei inode method 2: ls -i [Dateiname] anzeigen Die Inode -Nummer kann nur angezeigt werden 2.3 Drei Linux-Systemdateien Die Hauptzeitattribute Die drei Hauptzeitattribute von Linux-Systemdateien (d. h. der Zeitstempel im Inode) ctime (Änderungszeit) bezieht sich auf den letzten bezieht sich auf die letzte Aufgrund der Trennung von Inode-Nummer und Dateiname kommt es bei einigen Unix/Linux-Systemen zu folgendem Phänomen: So löschen Sie eine Datei durch Löschen der Inode-Nummer: Methode zwei (direktes Löschen): find ./ -inum [Inode-Nummer] -delete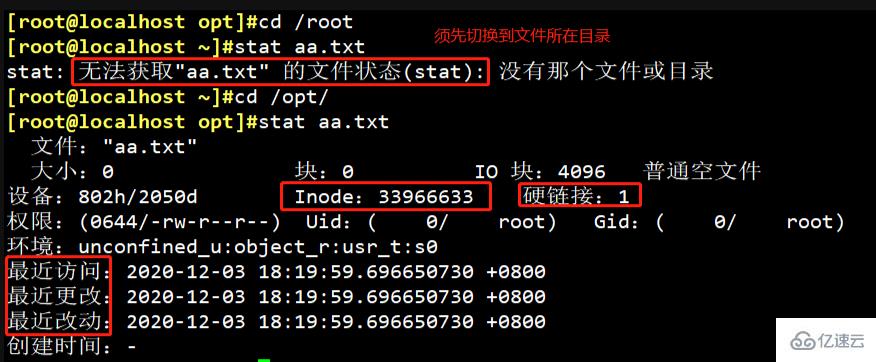

bezieht sich auf die letzte Änderungsdatei oder das letzte Verzeichnis ( Attribut) Die Zeit
Zugriff auf die Datei oder das Verzeichnis
Änderung Datei oder Verzeichnis (Inhalt). ) Zeit 3. Die besondere Rolle von Inode
Methode Eins (Informationen müssen vor dem Löschen bestätigt werden): find ./ -inum [Inode-Nummer] -exec rm -i {} ;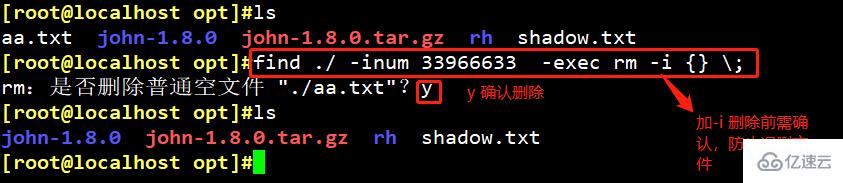
Das obige ist der detaillierte Inhalt vonWas bedeutet die Linux-I-Node-Nummer?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Erfahren Sie, wie Sie den Nginx-Server unter Linux installieren
- Detaillierte Einführung in den wget-Befehl von Linux
- Ausführliche Erläuterung von Beispielen für die Verwendung von yum zur Installation von Nginx unter Linux
- Detaillierte Erläuterung der Worker-Verbindungsprobleme in Nginx
- Detaillierte Erläuterung des Installationsprozesses von Python3 unter Linux