
Heim >Datenbank >MySQL-Tutorial >So verstehen Sie das Problem der Verwendung des B+-Baums in der MySQL-Indexstruktur
So verstehen Sie das Problem der Verwendung des B+-Baums in der MySQL-Indexstruktur

- 王林nach vorne
- 2023-05-29 15:31:131560Durchsuche
1. B-Baum und B+-Baum
Im Allgemeinen verwenden Datenbankspeicher-Engines B-Baum oder B+-Baum zum Speichern von Indizes. Schauen Sie sich zunächst den B-Baum an, wie in der Abbildung gezeigt.
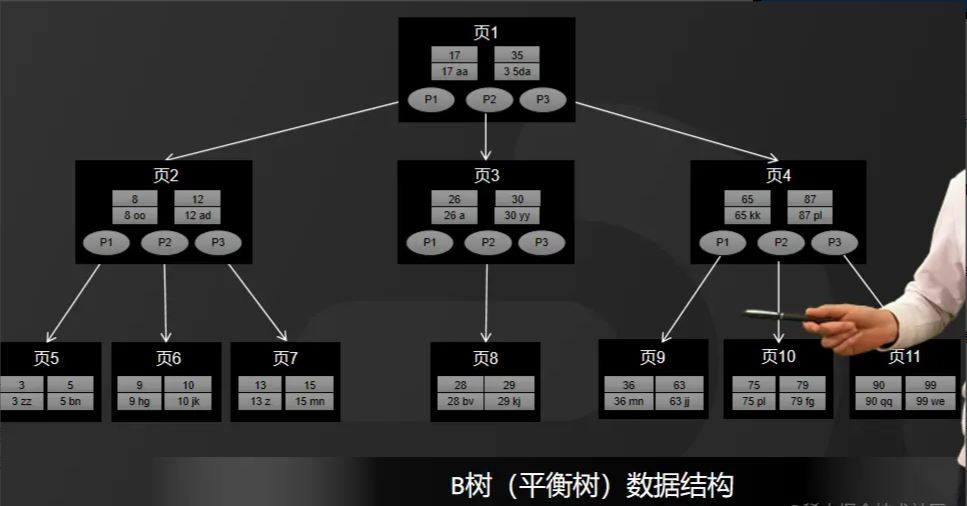
B-Baum ist ein mehrseitig ausgeglichener Baum. Wenn diese Speicherstruktur zum Speichern einer großen Datenmenge verwendet wird, ist ihre Gesamthöhe viel kürzer als bei einem Binärbaum.
Bei Datenbanken werden alle Daten auf der Festplatte gespeichert, und die Effizienz der Festplatten-E/A ist relativ gering, insbesondere bei zufälliger Festplatten-E/A.
Die Höhe bestimmt also die Anzahl der Festplatten-E/As, desto größer ist die Leistungsverbesserung. Aus diesem Grund wird B-Baum als Indexspeicherstruktur verwendet.
Die InnoDB-Speicher-Engine von MySQL verwendet eine verbesserte B-Baum-Struktur, nämlich den B+-Baum, als Index- und Datenspeicherstruktur.
Im Vergleich zur B-Baumstruktur wurde der B+-Baum in zwei Aspekten optimiert, wie in der Abbildung dargestellt.
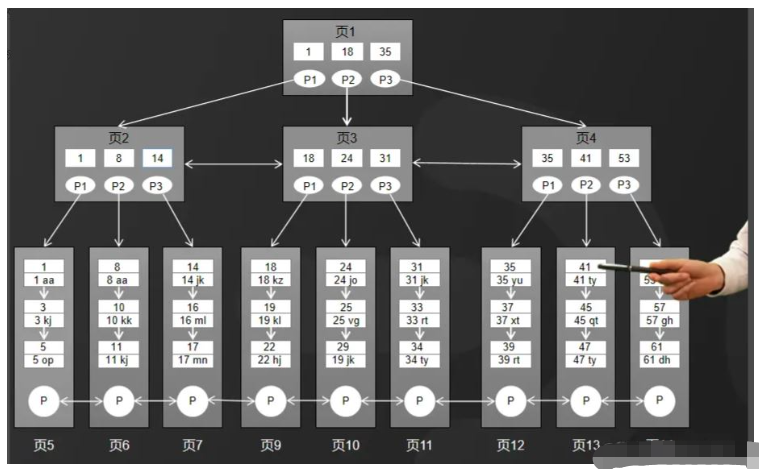
1. Alle Daten im B+-Baum werden in Blattknoten gespeichert, und Nicht-Blattknoten speichern nur Indizes.
2. Die Daten in Blattknoten werden mithilfe einer doppelt verknüpften Liste verknüpft.
2. Ursachenanalyse
Ich denke, dass die MySQL-Indexstruktur den B+-Baum aus den folgenden 4 Gründen verwendet:

1 Aus Sicht der Festplatten-E/A-Effizienz: Die Nicht-Blattknoten des B+-Baums keine Daten speichern, sodass jede Ebene des Baums mehr Indizes speichern kann. Mit anderen Worten: Bei gleicher Ebenenhöhe kann der B+-Baum mehr Daten speichern, was indirekt die Anzahl der Festplatten-E/A-Vorgänge verringert .
2. Aus Sicht der Bereichsabfrageeffizienz: In MySQL ist die Bereichsabfrage eine relativ häufige Operation, und alle in den Blattknoten des B + -Baums gespeicherten Daten sind mithilfe doppelt verknüpfter Listen verknüpft, sodass Sie beim Abfragen des B + -Baums nur Folgendes benötigen um zwei Knoten auf Durchquerung zu prüfen, während der B-Baum alle Knoten abrufen muss. Daher ist der B+-Baum bei Bereichsabfragen effizienter.
3. Aus Sicht des vollständigen Tabellenscans: Da die Blattknoten des B+-Baums alle Daten speichern, ist die globale Scanfähigkeit des B+-Baums stärker, da nur die Blattknoten gescannt werden müssen. Der B-Baum muss den gesamten Baum durchlaufen.
4. Aus der Perspektive einer sich selbst erhöhenden ID: Eine auf dem B + -Baum basierende Datenstruktur kann die Aufteilung von Blattknoten beim Hinzufügen großer Datenmengen besser vermeiden Probleme.
Das obige ist der detaillierte Inhalt vonSo verstehen Sie das Problem der Verwendung des B+-Baums in der MySQL-Indexstruktur. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!