
Heim >Datenbank >MySQL-Tutorial >So indizieren Sie Zeichenfolgenfelder in MySQL
So indizieren Sie Zeichenfolgenfelder in MySQL

- 王林nach vorne
- 2023-05-28 14:38:522544Durchsuche
Angenommen, Sie verwalten derzeit ein System, das die E-Mail-Anmeldung unterstützt:
create table SUser( ID bigint unsigned primary key, email varchar(64), ... )engine=innodb;
Da Sie sich per E-Mail anmelden müssen, wird es im Geschäftscode auf jeden Fall ähnliche Anweisungen geben:
select f1, f2 from SUser where email='xxx';
Wenn das E-Mail-Feld „Ohne Index“ lautet, kann diese Anweisung nur einen vollständigen Tabellenscan durchführen.
1) Kann ich einen Index für das E-Mail-Adressfeld erstellen?
MySQL unterstützt den Präfixindex, und Sie können einen Teil der Zeichenfolge als Index definieren
2) Was passiert, wenn die Anweisung, die den Index erstellt, die Präfixlänge nicht angibt?
Der Index enthält die gesamte Zeichenfolge
3) Können Sie ein Beispiel zur Veranschaulichung geben?
alter table SUser add index index1(email); 或 alter table SUser add index index2(email(6));
index1-Index enthält die gesamte Zeichenfolge jedes Datensatzes
Index2-Index benötigt nur die ersten 6 Bytes jedes Datensatzes
4) Diese beiden Was sind die Unterschiede zwischen verschiedenen Definitionen in der Datenstruktur und Lagerung?
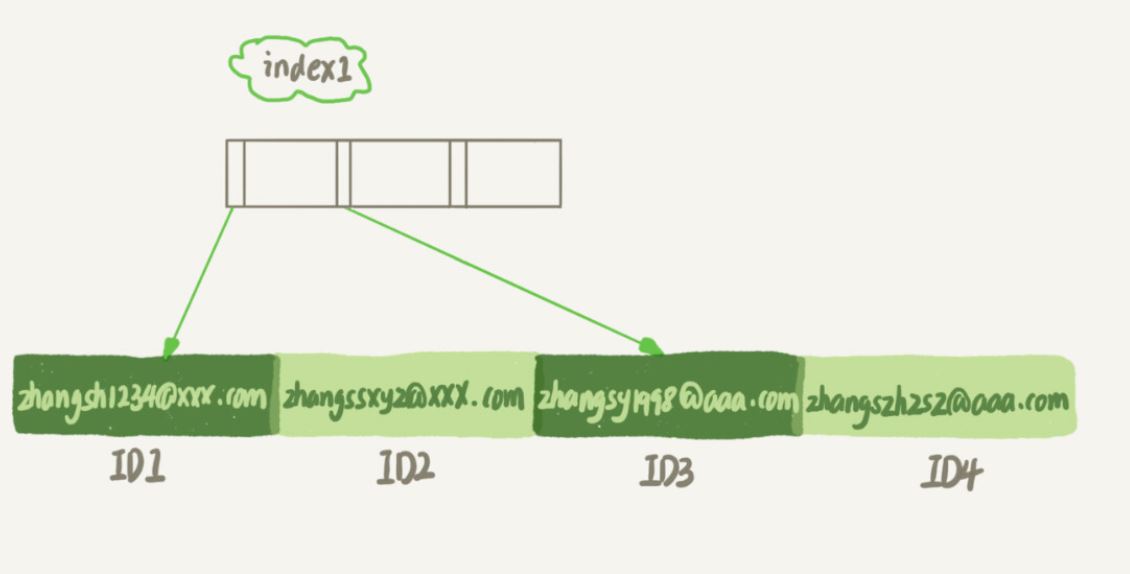
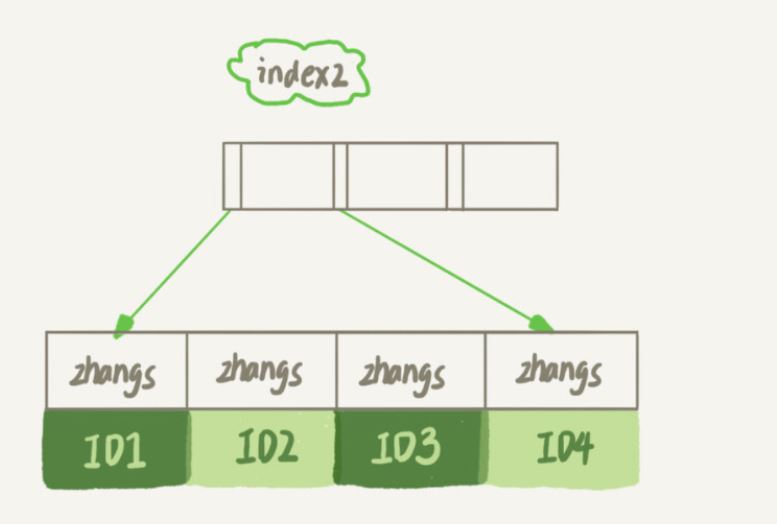
Es ist offensichtlich, dass die E-Mail(6)-Indexstruktur weniger Platz beanspruchen wird
5) Gibt es Mängel in der E-Mail(6)-Indexstruktur?
kann die Anzahl zusätzlicher Datensatzscans erhöhen
6) Wie wird die folgende Anweisung unter diesen beiden Indexdefinitionen ausgeführt?
select id,name,email from SUser where email='zhangssxyz@xxx.com';
index1 (d. h. die Indexstruktur der gesamten E-Mail-Zeichenfolge), die Ausführungssequenz
-
findet den Datensatz, der den Indexwert von ’zhangssxyz@xxx.com’ erfüllt. und erhält den Wert von ID2;
-
Gehen Sie zurück zur Tabelle und suchen Sie die Zeile, deren Primärschlüsselwert ID2 ist, beurteilen Sie, ob der Wert von email korrekt ist, und fügen Sie diese Zeile mit Datensätzen zur Ergebnismenge hinzu;
Fahren Sie mit dem nächsten Datensatz im Indexbaum fort und stellen Sie fest, dass die E-Mail-Bedingung nicht mehr erfüllt ist ='zhangssxyz@xxx.com’, die Schleife endet. - Bei diesem Vorgang müssen Sie die Daten nur einmal aus dem Primärschlüsselindex abrufen, sodass das System davon ausgeht, dass nur eine Zeile gescannt wurde.
- Holen Sie sich die nächste Zeichnen Sie den gerade gefundenen Standort auf Index2 auf und stellen Sie fest, dass es sich immer noch um „zhangs“ handelt. Nehmen Sie ID2 heraus, rufen Sie dann die gesamte Zeile im ID-Index ab und beurteilen Sie, ob der Wert dieses Mal korrekt ist. Fügen Sie diese Zeile mit Datensätzen hinzu Ergebnissatz;
- Wiederholen Sie den vorherigen Schritt, bis der auf idxe2 erhaltene Wert nicht mehr lautet. Wenn ’zhangs’, endet der Zyklus.
- In diesem Prozess muss der Primärschlüsselindex viermal abgerufen werden, dh es werden vier Zeilen gescannt.
7) Welche Schlussfolgerungen lassen sich aus dem obigen Vergleich ziehen?
- 8) Sind Präfixindizes wirklich nutzlos?
- 9) Was sind also die Vorsichtsmaßnahmen für die Verwendung des Präfixindex?
- 10) Woher weiß ich beim Erstellen eines Präfixindex für eine Zeichenfolge, wie lang der Präfixindex sein sollte?
- 11) Wie zählt man, wie viele verschiedene Werte es auf dem Index gibt?
select count(distinct email) as L from SUser;
12) Was sollen wir als nächstes tun, nachdem wir erhalten haben, wie viele verschiedene Werte dem Index entsprechen?
Wählen Sie nacheinander Präfixe unterschiedlicher Länge aus, um diesen Wert anzuzeigen Über diesen Index werden Daten mit einem Score von über 95 % gefunden.
- 13) Welchen Einfluss hat der Präfixindex auf den Deckungsindex?
- Die folgende SQL-Anweisung:
select count(distinct left(email,4))as L4, count(distinct left(email,5))as L5, count(distinct left(email,6))as L6, count(distinct left(email,7))as L7, from SUser;
select id,email from SUser where email='zhangssxyz@xxx.com';im vorherigen Beispiel erfordert die erste Anweisung nur die Rückgabe der Felder „ID“ und „E-Mail“.
Wenn Sie Index1 (dh die Indexstruktur der gesamten E-Mail-Zeichenfolge) verwenden, können Sie die ID durch Überprüfen der E-Mail ermitteln. Dies ist ein abdeckender Index.
用 index2(即 email(6) 索引结构)的话,就不得不回到 ID 索引再去判断 email 字段的值。
14)那我把index2 的定义修改为 email(18) 的前缀索引不就行了?
这个18是你自己定义的,系统不知道18这个长度是否已经大于我的email长度,所以它还是会回表去查一下验证。
总而言之:使用前缀索引就用不上覆盖索引对查询性能的优化了
针对类似于邮箱这样的字段,使用前缀索引可能会产生不错的效果。但是,遇到身份证这种前缀的区分度不够好的情况时,我们要怎么办呢?
索引选取的要更长一些。
但是所以越长的话,占的磁盘空间更大,相同的一页能放下的索引值就变少了,反而会影响查询效率。
16)如果我们能够确定业务需求里面只有按照身份证进行等值查询的需求,还有没有别的处理方法呢?
-
既然正过来相同的多,那我就把它倒过来存。查询时候这样查
select field_list from t where id_card = reverse('input_id_card_string');
使用 的时候用count(distinct) 方法去做个验证
-
使用 hash 字段。在表上再创建一个整数字段,来保存身份证的校验码,同时在这个字段上创建索引。
alter table t add id_card_crc int unsigned, add index(id_card_crc);
新记录插入时必须使用 crc32() 函数生成校验码,并填入新字段中。由于校验码可能存在冲突,也就是说两个不同的身份证号通过 crc32() 函数得到的结果可能是相同的,所以你的查询语句 where 部分要判断 id_card 的值是否精确相同。
select field_list from t where id_card_crc=crc32('input_id_card_string') and id_card='input_id_card_string'
这样,索引的长度变成了 4 个字节(int类型),比原来小了很多
17)使用倒序存储和使用 hash 字段这两种方法有什么异同点?
相同点:都不支持范围查询
倒序存储的字段上创建的索引是按照倒序字符串的方式排序的,已经没有办法利用索引方式查出身份证号码在[ID_X, ID_Y]的所有市民了。同样地,hash 字段的方式也只能支持等值查询。
区别
从占用的额外空间来看,倒序存储方式在主键索引上,不会消耗额外的存储空间,而 hash 字段方法需要增加一个字段。当然,倒序存储方式使用 4 个字节的前缀长度应该是不够的,如果再长一点,这个消耗跟额外这个 hash 字段也差不多抵消了。
在 CPU 消耗方面,倒序方式每次写和读的时候,都需要额外调用一次 reverse 函数,而 hash 字段的方式需要额外调用一次 crc32() 函数。以仅考虑这两个函数的计算复杂度为前提,reverse 函数对 CPU 资源的额外消耗将较少。
就查询性能而言,采用哈希字段方式的查询更具可靠性。虽然crc32算法不可避免地存在冲突的风险,但这种风险极其微小,因此我们可以认为查询时平均扫描行数接近于1。使用倒序存储方式仍然需要使用前缀索引来进行扫描,因此会增加扫描的行数。
案例:如果你在维护一个学校的学生信息数据库,学生登录名的统一格式是”学号 @gmail.com", 而学号的规则是:十五位的数字,其中前三位是所在城市编号、第四到第六位是学校编号、第七位到第十位是入学年份、最后五位是顺序编号。
学生必须输入正确的登录名和密码,方可继续使用系统。如果只考虑登录验证这个行为,你会如何为登录名设计索引?
如果一个学校每年预计2万新生,50年才100万记录,如果直接使用全字段索引,可以节省多少存储空间?。除非遇到超大规模数据,否则不需要使用后两种方法,从而避免了开发转换和限制风险
在实际操作中,只需对所有字段进行索引,一个学校的数据库数据量和查询负担不会变得很大。 如果单从优化数据表的角度: \1. 后缀@gmail可以单独一个字段来存,或者用业务代码来保证, \2. 城市编号和学校编号估计也不会变,也可以用业务代码来配置 \3. 然后直接存年份和顺序编号就行了,这个字段可以全字段索引
Das obige ist der detaillierte Inhalt vonSo indizieren Sie Zeichenfolgenfelder in MySQL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!