| id(Primärschlüssel) | #🎜 🎜#userername#🎜🎜 ## 🎜🎜#Alter#🎜🎜 ## 🎜🎜#adresse#🎜🎜 ## 🎜🎜#Gender#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#1#🎜🎜 ## 🎜🎜#ab | 99 | Shenzhen | männlich |
2 #🎜 🎜#| ac |
98 |
广州 |
männlich |
| # 🎜 🎜# 3
af | 88 | 北京 | 女 | # 🎜🎜 ## 🎜🎜#4 | bc
80 | 上海 | 女#🎜 🎜# #🎜 ## 🎜🎜 # |
6 |
bw |
95
| 天津 |
男#🎜 🎜# |
| 7 | bw | 99
海口| #🎜 🎜#女# 🎜🎜# |
| 8 | cc | 92 | 武汉#🎜 🎜## 🎜 🎜 #男
| 9 | ck | 90 | Shenzhen# 🎜 🎜# 男 |
| 10 |
cx |
93 | #🎜 🎜# Shenzhen# 🎜🎜#男 |
|
Dann sieht sein Clustered-Index wahrscheinlich so aus:
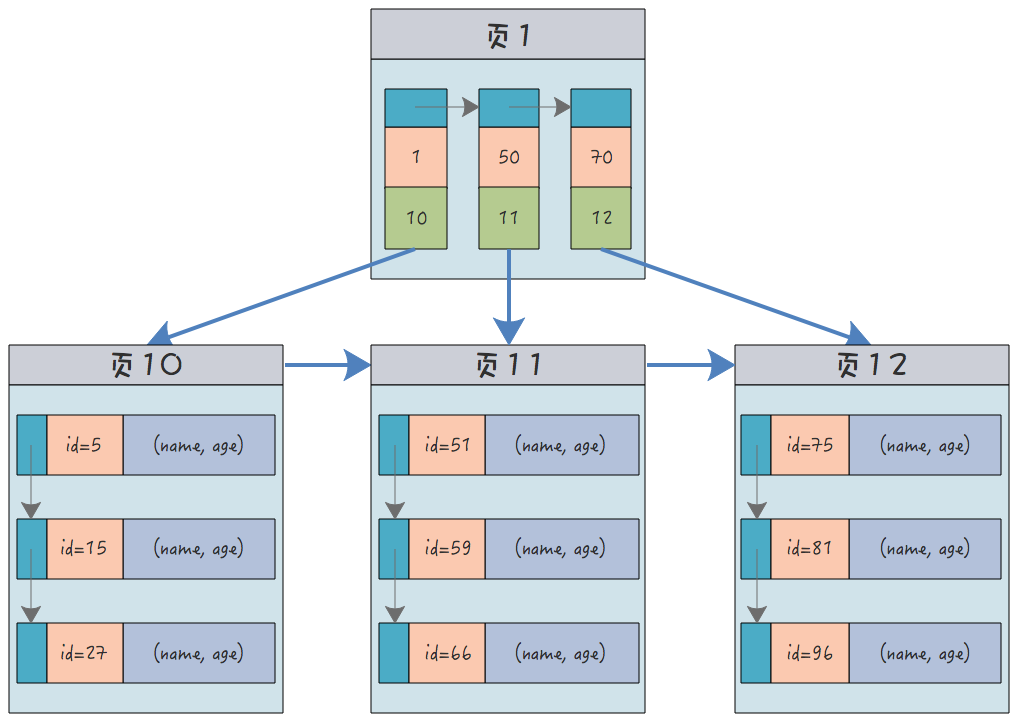
Wie Sie sehen können, gibt es auf den Blättern sowohl Primärschlüsselwerte (Indizes) als auch Datenzeilen und auf den nur Primärschlüsselwerte (Indizes). Knoten.
Freunde, denken Sie darüber nach, die Daten in der MySQL-Tabelle können nur in einer Kopie auf der Festplatte gespeichert werden, und es ist unmöglich, zwei Kopien zu speichern. Daher kann es in einer Tabelle nur einen Clustered-Index geben, nicht mehrere .
2. Clustered-Index und Primärschlüssel
Einige Freunde sind sich über die Beziehung zwischen den beiden nicht im Klaren und setzen die beiden sogar gleich.
In einigen Datenbanken können Entwickler frei wählen, welchen Index sie als Clustered-Index verwenden möchten, MySQL unterstützt diese Funktion jedoch nicht.
Wenn in MySQL die Tabelle selbst über einen Primärschlüssel verfügt, ist der Primärschlüssel der Clustered-Index. Wenn die Tabelle selbst keinen Primärschlüssel festlegt, wird ein eindeutiger und nicht leerer Index in der Tabelle als ausgewählt Clustered-Index; Wenn die Tabelle nicht einmal einen eindeutigen, nicht leeren Index hat, wird der implizite Primärschlüssel in der Tabelle automatisch als Clustered-Index ausgewählt. Brother Song wird Ihnen in zukünftigen Artikeln den impliziten Primärschlüssel von MySQL-Tabellen vorstellen.
Aber im Allgemeinen wird empfohlen, den Primärschlüssel für die Tabelle selbst festzulegen, da der implizite Primärschlüssel automatisch inkrementiert wird und es bei der automatischen Inkrementierung ein Problem gibt: Es wird eine sehr starke Sperrkonkurrenz geben Problem beim automatisch inkrementierten Wert. Die Obergrenze wird als Hot Data bezeichnet, da alle Einfügevorgänge eine Erhöhung des Primärschlüssels erfordern und nicht wiederholt werden können, sodass es zu einem Sperrenwettbewerb kommt und die Leistung abnimmt.
Basierend auf der obigen Einführung können wir die Beziehung zwischen Clustered-Index und Primärschlüsselindex in MySQL wie folgt zusammenfassen:
3. Vor- und Nachteile des Clustered-Index
Lassen Sie uns zunächst über die Vorteile sprechen:
Wir können miteinander verbundene Daten speichern. Wenn es beispielsweise eine Benutzer-Bestelltabelle gibt, können wir alle Daten basierend auf Benutzer-ID + Bestell-ID aggregieren. Benutzer-IDs können wiederholt werden, Bestell-IDs werden jedoch nicht wiederholt. Auf diese Weise können wir alle Bestelldaten speichern Wenn Sie alle Bestellungen eines Benutzers zusammen abfragen müssen, ist dies sehr schnell und erfordert nur eine geringe Menge an Festplatten-E/A.
Es müssen keine Tabellen zurückgegeben werden, sodass der Datenzugriff schneller erfolgt. In einem Clustered-Index befinden sich der Index und die Daten im selben B+Baum, sodass das Abrufen von Daten aus dem Clustered-Index schneller ist als das Abrufen von Daten aus einem Nicht-Clustered-Index (Nicht-Cluster-Indizes erfordern eine Tabellensicherung).
Wenn wir im ersten Fall alle Bestell-IDs dieses Benutzers basierend auf der Benutzer-ID abfragen möchten, müssen wir zu diesem Zeitpunkt nicht zum Blattknoten gehen, da der Support-Knoten über die Daten verfügt, die wir haben Bedarf, sodass Sie die erforderlichen Daten direkt anhand der Merkmale des Abdeckindexes lesen können.
Dies sind einige gemeinsame Vorteile von Clustered-Indizes. Tatsächlich sollten wir diese Vorteile bei der täglichen Tabellengestaltung voll ausnutzen.
Werfen wir einen Blick auf die Mängel:
Freunde haben festgestellt, dass der zuvor erwähnte Vorteil des Clustered-Index hauptsächlich darin besteht, dass der Clustered-Index die Anzahl der E/As reduziert und somit die Leistung der Datenbank verbessert Bei intensiven Anwendungen kann es möglich sein, einen ausreichend großen Speicher direkt zu laden und alle Daten für den Betrieb in den Speicher einzulesen. In diesem Fall hat der Clustered-Index keinen Vorteil.
Zufällige Primärschlüssel führen zu Problemen bei der Seitenaufteilung. Wenn die Primärschlüssel nacheinander eingefügt werden, ist die Effizienz relativ höher, da Sie in B + Tree nur weiter hinten anhängen müssen Wenn sie nicht sequentiell eingefügt werden, ist die Effizienz viel geringer, da möglicherweise eine Seitenaufteilung erforderlich ist. Nehmen wir das Bild oben als Beispiel: Angenommen, jeder Knoten kann drei Daten speichern. Jetzt möchten wir einen Datensatz mit einem Primärschlüssel von 4,5 einfügen. Dann müssen wir den Wert des Primärschlüssels von 5 nach hinten verschieben bewirkt, dass der Knoten mit einem Primärschlüssel von 8 ebenfalls zurückbewegt wird. Die Seitenaufteilung führt zu einer weniger effizienten Dateneinfügung und beansprucht mehr Speicherplatz.
Der nicht gruppierte Index (Sekundärindex) muss bei der Abfrage die Tabelle zurückgeben. Da ein Index ein Indexbaum ist und sich alle Daten im Clustered-Index befinden, speichern die Blätter des Nicht-Clustered-Index zuerst den Primärschlüsselwert , und dann halten Der Primärschlüsselwert wird dann im Clustered-Index durchsucht, sodass insgesamt zwei Indexbäume abgefragt werden, was die Tabellenrückgabe darstellt.

