
Heim >Datenbank >MySQL-Tutorial >Analyse der Wissenspunkte des MySQL-Index
Analyse der Wissenspunkte des MySQL-Index

- PHPznach vorne
- 2023-05-27 20:38:351598Durchsuche
1 Konzept des Index
1.1 Definition
In einer relationalen Datenbank ist ein Index eine separate, physische Speicherstruktur, die einen oder mehrere Spaltenwerte in einer Datenbanktabelle sortiert. Es handelt sich um eine Sammlung von Werten für eine oder mehrere Spalten in einer Tabelle, zusammen mit einer Liste logischer Zeiger auf die Datenseiten in der Tabelle, die diese Werte physisch identifizieren.
Die Rolle des Index entspricht dem Inhaltsverzeichnis des Buches. Sie können den benötigten Inhalt anhand der Schlüsselseitenzahlen des Inhaltsverzeichnisses schnell finden. Die Datenbank verwendet den Index, um einen bestimmten Wert zu finden Folgt dem Zeiger, um die Zeile zu finden, die den Wert enthält. Dadurch kann eine der Tabelle entsprechende SQL-Anweisung schneller ausgeführt werden und auf bestimmte Informationen in Datenbanktabellen zugegriffen werden.
1.2 Typ
InnoDB umfasst drei Indextypen, nämlich einen gewöhnlichen Index, einen eindeutigen Index (der Primärschlüsselindex ist ein spezieller nicht leerer eindeutiger Index) und einen Volltextindex.
Umgeschrieben als: Der gewöhnliche Index, auch nicht eindeutiger Index genannt, unterliegt keinen Einschränkungen. Eindeutig: Ein eindeutiger Index erfordert, dass der Schlüsselwert nicht wiederholt werden kann (kann leer sein). Der Primärschlüsselindex ist eigentlich ein spezieller eindeutiger Index, weist jedoch auch eine zusätzliche Einschränkung auf, die erfordert, dass der Schlüsselwert nicht leer sein darf. Primärschlüsselindizes werden mithilfe von Primärschlüsseln erstellt. Volltext: Bei relativ großen Daten wie Artikeln, Texten, E-Mails usw. kann ein Feld mehrere KB erfordern. Wenn Sie das Problem der geringen Effizienz ähnlicher Abfragen beim Volltextabgleich lösen möchten, können Sie Volltext erstellen Index. Nur Felder vom Typ char, varchar und text können Volltextindizes erstellen. Sowohl MyISAM als auch InnoDB unterstützen die Volltextindizierung.
1.3 Funktion
Zusammenfassung in einem Satz:
Index kann die Effizienz des Datenabrufs verbessern und die IO-Kosten der Datenbank senken.
Stellen Sie eine Frage: Wir tauschen Raum gegen Zeit, aber was ist mit der Datenstruktur, den Abfrage-IO-Kosten und der Speicherung von Daten?
2 Der Entwicklungsprozess der Indexdatenstruktur B+-Baum.
Lassen Sie uns Betrachten Sie den Evolutionsprozess unseres B+-Baums aus einer Perspektive.Page
⼼Die Speichergröße einer Seite beträgt 16 KB.Angenommen, wir möchten dieses SQL ausführen und 10 Datensätze erhalten:
SELECT * FROM INNODB_USER LIMIT 0 , 10;
Wenn die Datengröße eines Datensatzes 4 KB beträgt, wie viele Daten können wir dann auf einer Seite speichern?
16K geteilt durch 4K ergibt 4 Datensätze, richtig.
Jedes Datenelement auf der Seite hat ein Schlüsselattribut namens „record_type“0 Normaler Benutzerdatensatz 1 Verzeichnisindexdatensatz 2 Minimum 3 MaximumZeichnen Sie ein Bild, um zu zeigen, wie die Daten auf der Seite platziert werden:
 Dies ist unsere Seite.
Dies ist unsere Seite.
Wir wissen, dass die Datenspeicherung praktisch ist Praktisch, dann ist das Abfragen kein Problem. Wenn Sie die letzte Seite überprüfen, müssen Sie dann die gesamte Datenseite durchsuchen.
2.1 FrageWas ist, wenn wir ein Datenelement überprüfen möchten?
Wenn die Daten auf unserer Seite miteinander verbunden sind, denken Sie über die Datenstrukturen nach, die wir gelernt haben. Welche Struktur lässt sich am schnellsten abfragen?
- Wenn die Daten auf unserer Seite eine Verbindungsmethode haben, kann sie gelöst werden! Das ist richtig, es ist die verknüpfte Liste
MySQL verbindet die Daten auf der Seite überEinseitig Wenn Sie eine Abfrage basierend auf dem Primärschlüssel durchführen, ist die binäre Positionierung sehr schnell. Wenn Sie eine Abfrage basierend auf einem Nicht-Primärschlüssel-Index durchführen, können Sie die verknüpfte Liste nur in eine Richtung durchlaufen, beginnend mit dem kleinsten.
So stellen Sie eine Verbindung zwischen mehreren Seiten her (die Daten befinden sich auf verschiedenen Seiten):
, können wir sie nur von der ersten Seite an entlang der doppelt verknüpften Liste finden und dann den Schritten folgen Die gleiche Seite auf jeder Seite. Methode zum Auffinden des angegebenen Datensatzes. Dies ist auch ein vollständiger Tabellenscan.MySQL verknüpft verschiedene Seiten über eine bidirektionale verknüpfte Liste, sodass wir die nächste Seite über die vorherige Seite finden können. Suchen Sie eine Seite über die nächste Seite. Da
wir die Seite, auf der sich die Daten befinden, nicht schnell finden können
2.2 Problem

Wenn die Anzahl der Datensätze in unserer verknüpften Liste zunimmt, weil wir sie nicht direkt finden können, haben wir das Problem einer langsamen Abfrage. Bei genauerer Betrachtung handelt es sich bei der sogenannten langsamen Abfrage tatsächlich um die folgenden zwei Probleme:
Abfragezeitkomplexität 0 (N)
-
Zu viele E/A-Zeiten zum Lesen und Schreiben auf die Festplatte
# 🎜🎜#
check
Katalogrichtig? Was ist ein Verzeichnis? Ist es nicht nur ein Index?
Suchen Sie ein Verzeichnis auf Baidu und posten Sie ein Bild:

- Inhaltseinführung (Kapiteltitel)
-
# Die Seite Nummer, in der sich 🎜🎜#
befindet Unsere Schnellabfragedaten Zweck: Fügen Sie den Daten ein Verzeichnis hinzu und überprüfen Sie die Daten. Wir ermitteln zunächst anhand der Verzeichnisseite, auf welcher Seite sich die Daten befinden, um die Abfrageleistung zu verbessern #🎜🎜 #.
Aber
2.3 Frage: Wie erstelle ich ein Verzeichnis? Für jede Seite ein Inhaltsverzeichnis erstellen? Müssen Sie beim Erstellen von Verzeichnissen regelmäßig vorgehen? Beispielsweise wird das Verzeichnis eines Wörterbuchs in alphabetischer Reihenfolge erstellt. Woran haben Sie gedacht? Das ist richtig, es ist
PrimärschlüsselDer automatisch inkrementierte Primärschlüssel erfüllt einfach unsere Anforderungen, hat weniger Inhalt und ist nicht wiederholbar Speichern Sie den Schlüssel jeder Seite gemäß dem regulären Muster und fügen Sie bei der Abfrage direkt basierend auf der Größe des Primärschlüssels die Dichotomiemethode hinzu, um das Verzeichnis schnell zu finden und dann die Daten zu finden . Aber müssen wir für jede Datenseite ein Verzeichnis erstellen? Es scheint, dass dies immer noch notwendig ist, wenn Sie nicht für jede Seite Daten erstellen. Wie können Sie die Daten auf der Seite finden? Handelt es sich um einen ganzseitigen Scan? Aber erstellen Sie ein Verzeichnis für jede Seite
auchwir müssen jedes Verzeichnis durchlaufen
Die Abfrageleistung wird ebenfalls abnehmen.
Können wir ein Verzeichnis für das Verzeichnis erstellen? Wir können also auch ein Verzeichnis für die Verzeichnisseite erstellen und eine Ebene von Wurzelknoten nach oben extrahieren, was uns die Abfrage erleichtert.
Dieser Baum, weil
gemäß dem Primärschlüssel speichert, nennen wir ihn Primärschlüsselindex Baum, weil der Primärschlüssel-Indexbaum alle Daten in unserer Tabelle speichert, dann ist in MySQL
Index Daten
Daten sind Index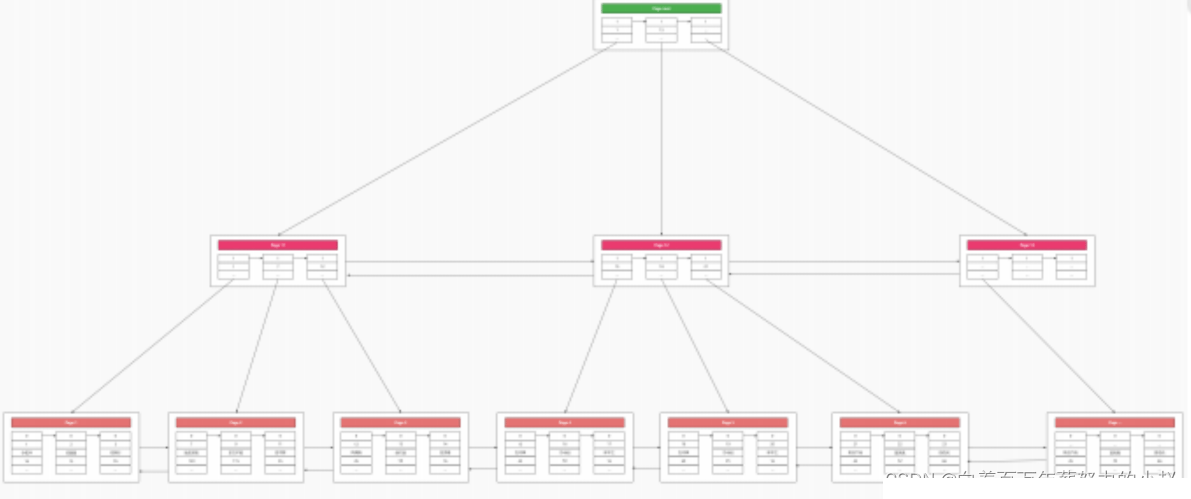 Dies ist auch der Grund.
Dies ist auch der Grund.
Dies ist die Datenstruktur des MysqlB+-Baum-Primärschlüsselindexbaums. Ist sie beeindruckender als das Wissen, das Sie durch direktes Auswendiglernen erhalten? 🎜##🎜 🎜#2.4 Indexbaum, Seitenaufteilung und -zusammenführungWir haben einen Weg gefunden, die Abfrageleistung zu verbessern, wenn Seitenseiten hinzugefügt, geändert oder gelöscht werden. Was passiert, wenn es sich um eine befohlene Erhöhung handelt und ein neues Datenelement hinzugefügt wird? Die -Seite ist voll. Müssen Sie also eine neue Seite öffnen? Und die Daten auf der Seite müssen eine Bedingung erfüllen: Der Primärschlüsselwert des Benutzerdatensatzes auf der nächsten Datenseite muss größer sein als der Primärschlüsselwert des Benutzerdatensatzes auf der vorherigen Seite #🎜 🎜#Weil es so ist Um die Reihenfolge zu erhöhen, können wir direkt eine Seite am Ende der doppelt verknüpften Seitenliste hinzufügen.
Ungeordneten Anstieg handelt und ein neues Datenelement hinzugefügt wird? Öffnen Sie eine neue Seite und suchen Sie den Speicherort der Daten. Verschieben Sie die alten Daten auf die neue Seite und platzieren Sie die neuen Daten an einer geordneten Position.
有序增加,新增一条数据怎么办?
页写满了,那么是不是得开启一个新页!
并且页的数据必须满足一个条件:下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值
因为是有序增加,我们直接在页的双向链表末端增加一个页即可。
那如果是无序增加
- Die Blattknotendaten verschieben sich ständig.
- Löst die Aufteilung und Zusammenführung der Blattknotendatenseite aus und löst erneut die Aufteilung und Zusammenführung des oberen Blattknotens und des Wurzelknotens aus.
- Wie heißt das, „eine einzelne Bewegung wirkt sich auf den ganzen Körper aus“, auch Seitenteilung genannt! !
- Zusammenfassung:
Probleme beim Hinzufügen, Ändern oder Löschen von Seiten:
#🎜🎜 # Wir können sagen, dass es bei Aktualisierungsvorgängen wie ungeordnetem Hinzufügen, Aktualisieren der Primärschlüssel-ID und Löschen von Indexseiten zu einer großen Anzahl von Baumknotenanpassungen kommt, die das Paging und Zusammenführen der Seitenseiten des untergeordneten Blattknotens und des oberen Blattknotens auslösen Dies führt zu einer starken Festplattenfragmentierung und beeinträchtigt die Datenbankleistung, was erklärt, warum wir - keine Indizes für häufig aktualisierte und geänderte Spalten erstellen oder Primärschlüssel
nicht aktualisieren sollten.
Fassen wir zusammen:
Clustered Index (Clustered Index):# 🎜🎜# Der Primärschlüsselindexbaum wird auch als Clustered-Index oder Clustered-Index bezeichnet. In InnoDB verfügt eine Tabelle nur über einen Clustered-Indexbaum. Wenn eine Tabelle einen Primärschlüsselindex erstellt, ist dieser Primärschlüsselindex ein Clustered-Index. Wir bestimmen die physische Speicherreihenfolge der Datenzeilen anhand der Schlüsselwerte des Clustered-Index-Baums. Unser Clustered-Index sortiert und speichert alle Spalten in der Tabelle, und die Daten sind der Index bezieht sich auf unseren Primärschlüssel-Indexbaum.
2.5 Basierend auf dem, was wir gerade abgeleitet haben, hier ein paar Interviewfragen
Warum ist es am besten, wenn die Primärschlüssel-ID einen steigenden Trend aufweist?
你刚刚看完啊,不会没记住吧,有序递增,下一个数据页中用户记录的主键值必须大于上一个页中用户的主键值,假如我是趋势递增,存入的数据肯定是在最末尾链表或者新增一个链表,就不会触发页的分裂与合并,导致添加的速度变慢。
三层B+数能存多少数据?
考察点:Page页的大小,B+树的定义
1GB = 1024 M, 1mb = 1024k,1k= 1024 bytes
答:
已知:索引逻辑单元 16bytes 字节,16KB=16* 1024*1024,肯定比一千万多,在InnoDB中B+树的深度为3层就能满足千万级别的数据存储。
mysql 大字段为什么要拆分?
一个Page页可存放16K的数据,大字段占用大量的存储空间,意味着一个Page页可存储的数据条数变少,那么就需要更多的页来存储,需要更多的Page,意味着树的深度会变高。那么磁盘IO的次数会增加,性能下降,查询更慢。大字段不管是否被使用都会存放在索引上,占据大量内存空间压缩Page数据条数。
为什么用B+树?
B+树的底层是多路平衡查找树,对于每一次的查询的都是从根节点触发,到子叶结点才存放数据,根节点和非叶子结点都是存放的索引指针,查找叶子结点互,可以根据键值数据查询。具备更强的扫库、扫表能力、排序能力以及查询效率和性能的稳定性,存储能力也更强,仅使用三层B+树就能存储千万级别的数据。
3什么是二级索引树
刚才看的是根据主键得来的索引,我们如果不查主键,或者说表里压根就没有主键,怎么办?我们还可以根据几个字段来创建联合索引(组合索引聚合索引。。哎呀名字而已怎么叫都行)。
根据主键得到的索引树叫主键索引树,根据别的字段得到的索引树叫二级索引树。
通过下面的SQL 可以建立一个组合索引
ALTER TABLE INNODB_USER ADD INDEX SECOND_INDEX_AGE_USERNAME_PHONE('age','user_name','phone');
其实,看似建立了1个索引,但是你使用 age 查询 age,user_name 查询 age,user_name,phone 都能生效
您也可以认为建立了三个这样的索引:
ALTER TABLE INNODB__USER ADD INDEX SECOND_INDEX_AGE__USERNAME_PHONE('age'); ALTER TABLE INNODB_USER ADD INDEX SECOND_INDEX_AGE_USERNAME_PHONE('age','user_name'); ALTER TABLE `INNODB_USER`ADD INDEX SECOND_INDEX_AGE_USERNAME_PHONE('age','user_name','phone');
3.1那么二级索引树怎么排序?
首先需要知道参与排序的字段类型是否有有序?
如果是有序字段,就按照有序字段排序比如(int) 1 2 3 4。
如果是无序字段,按照这个列的字符集的排序规则来排序,这点不去深入,知道就好。
我现在有一个组合索引(A-B-C)他会按照你建立字段的顺序来进行排序:
如果A相同按照B排序,如果B相同按照C排序,如果ABC全部相同,会按照聚集索引进行排序。
我们的Page会根据组合索引的字段建立顺序来存储数据,年龄 用户名 手机号。
它的数据结构其实是一样的
3.2索引桥的概念是什么呢(最左匹配原则)?
还是上面那个索引,年龄用户名手机号,age,username,phone
那么可以看到我们第一个字段是AGE,如果需要这个索引生效,是不是在查询的时候需要先使用Age查询,然后如果还需要user_name,就使用user_name。
只使用了user_name 能使用到索引吗?
其实是不行的,因为我是先使用age进行排序的,你必须先命中age,再命中user_name,再命中phone,这个其实
就是我们所说的最左匹配原则。
最左其实就是因为我们是按照组合索引的顺序来存储的。大家常说的"索引桥"也是这个原因。在命中组合索引中,必须像过桥一样,先跨过第一块木板,再到第二块木板,最后到第三块木板。
3.3回表、覆盖索引、索引下推
二级索引树有三个重要的概念,分别是回表、覆盖索引、索引下推。.
回表就是:我们查询的数据不在二级索引树中需要拿到ID去主键索引树找的过程。
覆盖索引就是:我们需要查询的数据都在二级索引树中,直接返回这种情况就叫做覆盖索引。
索引下推(index condition pushdown )简称ICP:在Mysql5.6以后的版本上推出,用于优化回表查询;
3.4延申几个面试题:
为什么离散度低的列不走索引?
Was ist das Konzept der Dispersion? Je mehr identische Daten vorhanden sind, desto geringer ist die Streuung, und je weniger identische Daten vorhanden sind, desto höher ist die Streuung.
Sie haben alle die gleichen Daten, wie sortiert man sie? Kannst du es nicht sortieren?
Es gibt zu viele doppelte Werte in B+Tree. Wenn der MySQL-Optimierer feststellt, dass die Indizierung fast mit der Verwendung eines vollständigen Tabellenscans übereinstimmt, funktioniert sie nicht, selbst wenn der Index erstellt wird. Ob der Index verwendet wird oder nicht, entscheidet der MySQL-Optimierer.
Ist es nicht, je mehr Indizes, desto besser?
In Bezug auf den Speicherplatz: Tauschen Sie Platz gegen Zeit, und der Index muss Speicherplatz belegen.
Zeit: Klicken Sie auf den Index, um unsere Abfrageeffizienz zu beschleunigen. Wenn es sich um eine Aktualisierung und Löschung handelt, führt dies zum Teilen und Zusammenführen von Seiten, was sich auf die Reaktionszeit beim Einfügen und Aktualisieren auswirkt Anweisungen, aber die Leistung verlangsamt sich.
Wenn es sich um eine Spalte handelt, die häufig aktualisiert werden muss, wird die Erstellung eines Index nicht empfohlen, da dies häufig zum Teilen und Zusammenführen von Seiten führt.
3.5 Zusammenfassung des sekundären Indexbaums
Der sekundäre Indexbaum wird auch als kombinierter Index (zusammengesetzter Index) bezeichnet und speichert die Reihenfolge der Spaltennamen, wenn wir den Index erstellen Speichern, es speichert nur einen Teil der Daten, die zum Erstellen sekundärer Indexspaltennamen verwendet werden. Der sekundäre Indexbaum wurde entwickelt, um uns bei der Abfrage zu unterstützen und die Abfrageeffizienz zu verbessern. Es gibt drei Aktionen im sekundären Indexbaum: Tabellenrückgabe, Abdeckungsindex und Indizierung. Nach unten drücken. Unter ihnen ist der Deckungsindex der leistungsstärkste.
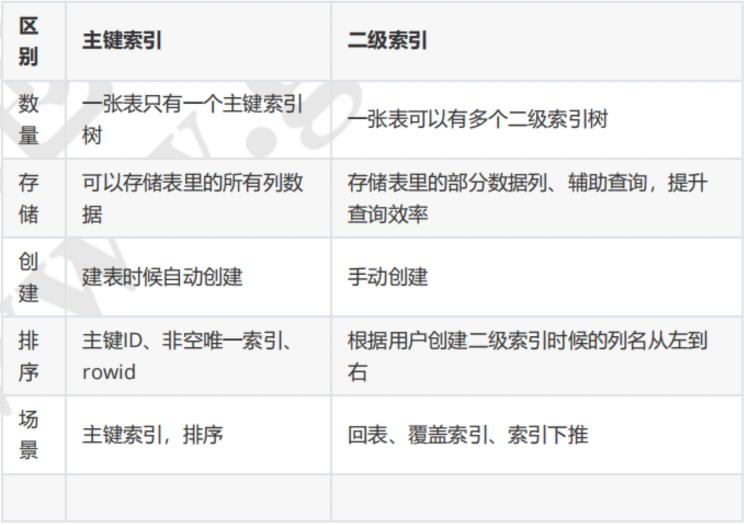
4 Der Unterschied zwischen Primärschlüsselindex und Sekundärindex
Ich habe online ein Unterschiedsbild gefunden
Das obige ist der detaillierte Inhalt vonAnalyse der Wissenspunkte des MySQL-Index. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!