
Heim >Datenbank >MySQL-Tutorial >So lösen Sie den Deadlock, der durch die Zusammenführung des MySQL-Optimierungsindex verursacht wird
So lösen Sie den Deadlock, der durch die Zusammenführung des MySQL-Optimierungsindex verursacht wird

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-27 17:49:361725Durchsuche
Hintergrund
In der Produktionsumgebung ist ein Deadlock aufgetreten. Beim Betrachten des Deadlock-Protokolls habe ich gesehen, dass der Deadlock durch zwei identische Aktualisierungsanweisungen verursacht wurde (nur die Werte in den Where-Bedingungen waren unterschiedlich),
wie folgt :
UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx1' AND `status` = 0; UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx2' AND `status` = 0;
一Anfangs war es etwas verwirrend, aber nach vielen Recherchen und Studien habe ich die spezifischen Prinzipien der Deadlock-Bildung analysiert und möchte sie mit Ihnen teilen, in der Hoffnung, Freunden zu helfen, denen das Gleiche passiert Problem.
Da MySQL viele Wissenspunkte hat, werden viele Substantive hier nicht allzu oft vorgestellt. Freunde, die interessiert sind, können eine spezielle Vertiefung durchführen. MySQL知识点较多,这里对很多名词不进行过多介绍,有兴趣的朋友,可以后续进行专项深入学习。
死锁日志
*** (1) TRANSACTION: TRANSACTION 791913819, ACTIVE 0 sec starting index read, thread declared inside InnoDB 4999 mysql tables in use 3, locked 3 LOCK WAIT 4 lock struct(s), heap size 1184, 3 row lock(s) MySQL thread id 462005230, OS thread handle 0x7f55d5da3700, query id 2621313306 x.x.x.x test_user Searching rows for update UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx1' AND `status` = 0; *** (1) WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 110 page no 39167 n bits 1056 index `idx_status` of table `test`.`test_table` trx id 791913819 lock_mode X waiting Record lock, heap no 495 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 *** (2) TRANSACTION: TRANSACTION 791913818, ACTIVE 0 sec starting index read, thread declared inside InnoDB 4999 mysql tables in use 3, locked 3 5 lock struct(s), heap size 1184, 4 row lock(s) MySQL thread id 462005231, OS thread handle 0x7f55cee63700, query id 2621313305 x.x.x.x test_user Searching rows for update UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx2' AND `status` = 0; *** (2) HOLDS THE LOCK(S): RECORD LOCKS space id 110 page no 39167 n bits 1056 index `idx_status` of table `test`.`test_table` trx id 791913818 lock_mode X Record lock, heap no 495 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 *** (2) WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 110 page no 41569 n bits 88 index `PRIMARY` of table `test`.`test_table` trx id 791913818 lock_mode X locks rec but not gap waiting Record lock, heap no 14 PHYSICAL RECORD: n_fields 30; compact format; info bits 0 *** WE ROLL BACK TRANSACTION (1)
简要分析下上边的死锁日志:
1、第一块内容(第1行到第9行)中,第6行为事务(1)执行的SQL语句,第7和第8行意思为事务(1)在等待 idx_status 索引上的X锁;
2、第二块内容(第11行到第19行)中,第16行为事务(2)执行的SQL语句,第17和第18行意思为事务(2)持有 idx_status 索引上的X锁;
意思为:事务(2)正在等待在 PRIMARY 索引上获取 X 锁。(but not gap指不是间隙锁)
4、最后一句的意思即为,MySQL将事务(1)进行了回滚操作。
表结构
CREATE TABLE `test_table` ( `id` int(11) NOT NULL AUTO_INCREMENT, `trans_id` varchar(21) NOT NULL, `status` int(11) NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `uniq_trans_id` (`trans_id`) USING BTREE, KEY `idx_status` (`status`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
通过表结构可以看出,trans_id 列上有一个唯一索引uniq_trans_id ,status 列上有一个普通索引idx_status ,id列为主键索引 PRIMARY 。
InnoDB引擎中有两种索引:
聚簇索引: 将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据。
辅助索引: 辅助索引叶子节点存储的是主键值,也就是聚簇索引的键值。
主键索引 PRIMARY 就是聚簇索引,叶子节点中会保存行数据。uniq_trans_id 索引和idx_status 索引为辅助索引,叶子节点中保存的是主键值,也就是id列值。
当我们通过辅助索引查找行数据时,先通过辅助索引找到主键id,再通过主键索引进行二次查找(也叫回表),最终找到行数据。
执行计划
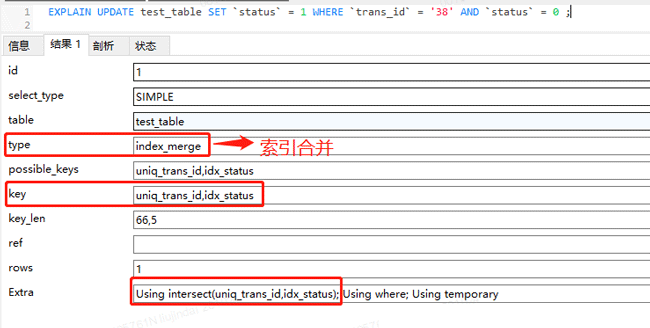
通过看执行计划,可以发现,update语句用到了索引合并,也就是这条语句既用到了 uniq_trans_id 索引,又用到了 idx_status 索引,Using intersect(uniq_trans_id,idx_status)的意思是通过两个索引获取交集。
为什么会用 index_merge(索引合并)
MySQL5.0之前,一个表一次只能使用一个索引,无法同时使用多个索引分别进行条件扫描。但是从5.1开始,引入了 index merge 优化技术,对同一个表可以使用多个索引分别进行条件扫描。
如执行计划中的语句:
UPDATE test_table SET `status` = 1 WHERE `trans_id` = '38' AND `status` = 0 ;
MySQL会根据 trans_id = ‘38’这个条件,利用 uniq_trans_id 索引找到叶子节点中保存的id值;同时会根据 status = 0这个条件,利用 idx_status 索引找到叶子节点中保存的id值;然后将找到的两组id值取交集,最终通过交集后的id回表,也就是通过 PRIMARY 索引找到叶子节点中保存的行数据。
这里可能很多人会有疑问了,uniq_trans_id 已经是一个唯一索引了,通过这个索引最终只能找到最多一条数据,那MySQL优化器为啥还要用两个索引取交集,再回表进行查询呢,这样不是多了一次 idx_status 索引查找的过程么。我们来分析一下这两种情况执行过程。
第一种 只用uniq_trans_id索引 :
根据
trans_id = ‘38’查询条件,利用uniq_trans_id索引找到叶子节点中保存的id值;通过找到的id值,利用PRIMARY索引找到叶子节点中保存的行数据;
再通过
status = 0条件对找到的行数据进行过滤。
第二种 用到索引合并 Using intersect(uniq_trans_id,idx_status):
根据
trans_id = ‘38’查询条件,利用uniq_trans_id索引找到叶子节点中保存的id值;-
根据
Deadlock-Protokoll🎜rrreee🎜🎜Kurze Analyse des obigen Deadlock-Protokolls:🎜🎜status = 0查询条件,利用idx_status- 🎜1. Der erste Inhalt (Zeile 1 bis Zeile 9), der Die 6. Zeile ist die von Transaktion (1) ausgeführte SQL-Anweisung, und die 7. und 8. Zeile bedeuten, dass Transaktion (1) auf die X-Sperre für den idx_status-Index wartet 🎜
- 🎜2 Im Inhalt (Zeile 11 bis Zeile 19) ist Zeile 16 die von Transaktion (2) ausgeführte SQL-Anweisung und die Zeilen 17 und 18 bedeuten, dass Transaktion (2) die X-Sperre für den idx_status-Index hält 🎜 🎜Bedeutet: Transaktion (2) wartet darauf, die X-Sperre für den PRIMARY-Index zu erhalten. (aber keine Lücke bedeutet keine Lückensperre)🎜
- 🎜4. Der letzte Satz bedeutet, dass MySQL die Transaktion (1) zurückgesetzt hat. 🎜
uniq_trans_id für die Spalte trans_id , status idx_status für die Spalte /code> und die ID-Spalte ist der Primärschlüsselindex PRIMARY . 🎜🎜🎜Es gibt zwei Arten von Indizes in der InnoDB-Engine: 🎜🎜- 🎜🎜Clustered-Index: 🎜 Fügen Sie den Datenspeicher und den Index zusammen und speichern Sie die Blattknoten der Zeilendaten der Indexstruktur. 🎜
- 🎜🎜Hilfsindex: 🎜 Der Hilfsindexblattknoten speichert den Primärschlüsselwert, der der Schlüsselwert des Clustered-Index ist. 🎜
PRIMARY ist ein Clustered-Index und Zeilendaten werden in Blattknoten gespeichert. Der uniq_trans_id -Index und der idx_status -Index sind Hilfsindizes, und die Blattknoten speichern den Primärschlüsselwert, der der ID-Spaltenwert ist. 🎜🎜Wenn wir über den Hilfsindex nach Zeilendaten suchen, finden wir zuerst die Primärschlüssel-ID über den Hilfsindex, führen dann eine sekundäre Suche über den Primärschlüsselindex durch (auch „Zurück zur Tabelle“ genannt) und finden schließlich die Zeilendaten . 🎜🎜Ausführungsplan🎜🎜🎜🎜Wenn Sie sich den Ausführungsplan ansehen, können Sie feststellen, dass die Update-Anweisung die Indexzusammenführung verwendet, d. h. diese Anweisung verwendet sowohl den Index uniq_trans_id als auch den Index idx_status , Die Verwendung von intersect(uniq_trans_id,idx_status) bedeutet, den Schnittpunkt durch zwei Indizes zu erhalten. 🎜🎜Warum wird index_merge verwendet? 🎜🎜Vor MySQL 5.0 konnte eine Tabelle jeweils nur einen Index verwenden und es war nicht möglich, mehrere Indizes gleichzeitig für bedingtes Scannen zu verwenden. Ab 5.1 wurde jedoch die Optimierungstechnologie index merge eingeführt, und mehrere Indizes können verwendet werden, um bedingte Scans für dieselbe Tabelle durchzuführen. 🎜🎜🎜Zum Beispiel die Anweisung im Ausführungsplan: 🎜🎜rrreee🎜MySQL verwendet den Index uniq_trans_id, um die im Blattknoten gespeicherte ID basierend auf der Bedingung trans_id = &lsquo zu finden ;38’-Wert; Basierend auf der Bedingung von status = 0 wird der idx_status-Index verwendet, um den in gespeicherten ID-Wert zu finden Dann werden die beiden gefundenen ID-Werte geschnitten und schließlich übergeben. Die ID wird nach dem Schnitt an die Tabelle zurückgegeben, dh die im Blattknoten gespeicherten Zeilendaten werden über den PRIMARY-Index gefunden. 🎜🎜Viele Leute haben hier möglicherweise Fragen. uniq_trans_id ist nur ein Datenelement, das über diesen Index gefunden werden kann. und dann zur Abfrage zur Tabelle zurückkehren. Fügt dies nicht einen weiteren idx_status-Indexsuchprozess hinzu? Lassen Sie uns den Ausführungsprozess dieser beiden Situationen analysieren. 🎜🎜🎜Der erste verwendet nur den uniq_trans_id-Index: 🎜🎜- 🎜Verwenden Sie gemäß der Abfragebedingung
trans_id = ‘38’Der Index uniq_trans_id findet den im Blattknoten gespeicherten ID-Wert 🎜 - 🎜Verwenden Sie den PRIMARY-Index, um die im Blattknoten gespeicherten Zeilendaten über den gefundenen ID-Wert zu finden; /li>
- 🎜Dann filtern Sie die gefundenen Zeilendaten durch die Bedingung
status = 0. 🎜
Using intersect(uniq_trans_id,idx_status): 🎜- 🎜Gemäß
trans_id = ‘38’Abfragebedingungen, verwenden Sie den Indexuniq_trans_id, um den im Blattknoten gespeicherten ID-Wert zu finden 🎜 - 🎜Gemäß
status = 0Abfragebedingungen, verwenden Sie den Indexidx_status, um den im Blattknoten gespeicherten ID-Wert zu finden 🎜 Schneiden Sie die in 1/2 gefundenen ID-Werte und verwenden Sie dann den PRIMARY-Index, um die im Blattknoten gespeicherten Zeilendaten zu finden
Der Hauptunterschied zwischen den beiden oben genannten Fällen besteht darin, dass der erste Fall darin besteht Führen Sie die Daten zunächst durch einen Index und verwenden Sie dann andere Abfragebedingungen zum Filtern. Die zweite Methode besteht darin, zunächst den Schnittpunkt der von den beiden Indizes gefundenen ID-Werte zu ermitteln Gehen Sie zurück zur Tabelle, um die Daten abzurufen.
Wenn der Optimierer davon ausgeht, dass die Ausführungskosten des zweiten Falls geringer sind als die des ersten Falls, findet eine Indexzusammenführung statt. (Die Flusstabelle der Produktionsumgebung status = 0 enthält nur sehr wenige Daten, was einer der Gründe ist, warum der Optimierer den zweiten Fall berücksichtigt.) status = 0 的数据非常少,这也是优化器考虑用第二种情况的原因之一)。
为什么用了 index_merge 就死锁了
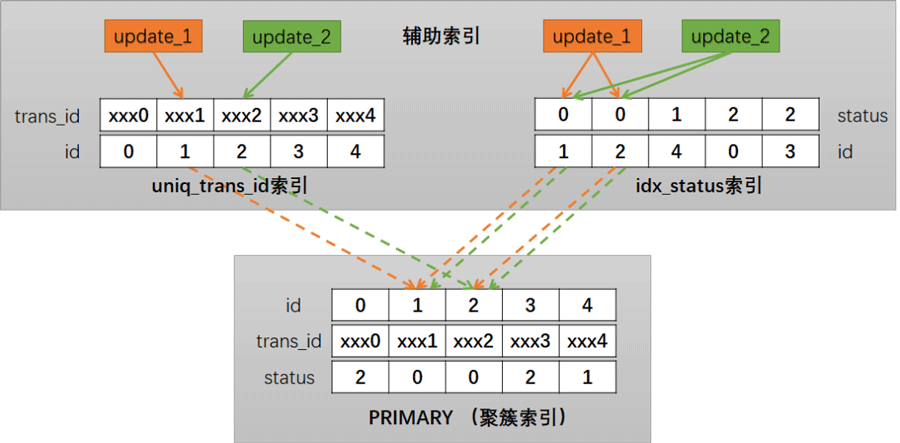
上面简要画了一下两个update事务加锁的过程,从图中可以看到,在idx_status 索引和 PRIMARY (聚簇索引) 上都存在重合交叉的部分,这样就为死锁造成了条件。
如,当遇到以下时序时,就会出现死锁:
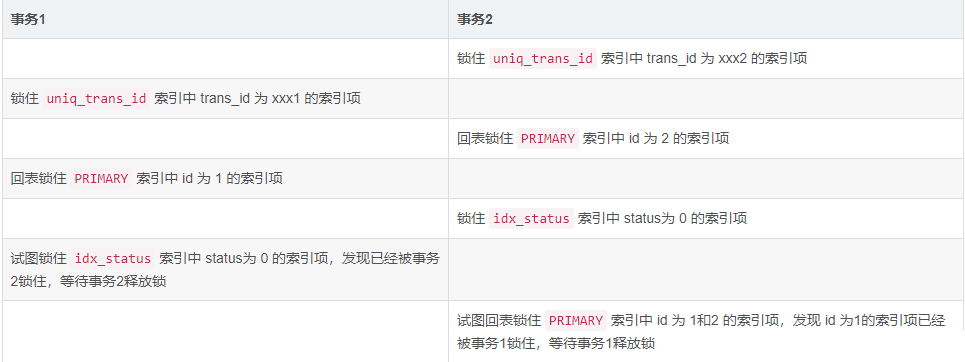
事务1等待事务2释放锁,事务2等待事务1释放锁,这样就造成了死锁。
MySQL检测到死锁后,会自动回滚代价更低的那个事务,如上边的时序图中,事务1持有的锁比事务2少,则MySQL就将事务1进行了回滚。
解决方案
一、从代码层面
where 查询条件中,只传
trans_id,将数据查询出来后,在代码层面判断 status 状态是否为0;使用
force index(uniq_trans_id)强制查询语句使用uniq_trans_id索引;where 查询条件后边直接用 id 字段,通过主键去更新。
二、从MySQL层面
删除
idx_status索引或者建一个包含这俩列的联合索引;-
将MySQL优化器的
Warum ist es nach der Verwendung vonindex mergeindex_mergeblockiert?
🎜🎜Oben wird kurz der Sperrprozess der beiden Aktualisierungstransaktionen dargestellt. Wie aus der Abbildung ersichtlich ist, befinden sich im Index idx_status und PRIMARY (Clustered-Indizes) haben überlappende und sich überschneidende Teile, was Bedingungen für einen Deadlock schafft. 🎜🎜Wenn beispielsweise das folgende Timing auftritt, kommt es zu einem Deadlock:🎜🎜 🎜🎜Transaktion 1 wartet darauf, dass Transaktion 2 die Sperre aufhebt, und Transaktion 2 wartet darauf, dass Transaktion 1 die Sperre aufhebt, was zu einem führt Deadlock. 🎜🎜Nachdem MySQL einen Deadlock erkennt, wird die Transaktion automatisch mit den geringeren Kosten zurückgesetzt. Im obigen Zeitdiagramm enthält Transaktion 1 beispielsweise weniger Sperren als Transaktion 2, sodass MySQL Transaktion 1 zurücksetzt. 🎜
🎜🎜Transaktion 1 wartet darauf, dass Transaktion 2 die Sperre aufhebt, und Transaktion 2 wartet darauf, dass Transaktion 1 die Sperre aufhebt, was zu einem führt Deadlock. 🎜🎜Nachdem MySQL einen Deadlock erkennt, wird die Transaktion automatisch mit den geringeren Kosten zurückgesetzt. Im obigen Zeitdiagramm enthält Transaktion 1 beispielsweise weniger Sperren als Transaktion 2, sodass MySQL Transaktion 1 zurücksetzt. 🎜Lösung
1. Von der Codeebene
- 🎜🎜wobei Abfragebedingungen nur
trans_id übergeben Stellen Sie nach dem Abfragen der Daten fest, ob der Status auf Codeebene 0 ist. 🎜🎜🎜🎜Verwenden Sie force index(uniq_trans_id), um zu erzwingen, dass die Abfrageanweisung den Index uniq_trans_id verwendet ; 🎜 🎜🎜🎜wobei das ID-Feld direkt nach der Abfragebedingung verwendet und über den Primärschlüssel aktualisiert wird. 🎜🎜🎜2. Aus der MySQL-Ebene
- 🎜🎜Löschen Sie den
idx_status-Index oder erstellen Sie einen gemeinsamen Index, der diese beiden Spalten enthält ; 🎜🎜🎜🎜Deaktivieren Sie die index merge-Optimierung des MySQL-Optimierers. 🎜🎜🎜Das obige ist der detaillierte Inhalt vonSo lösen Sie den Deadlock, der durch die Zusammenführung des MySQL-Optimierungsindex verursacht wird. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!