
Heim >Datenbank >MySQL-Tutorial >Was ist der MySQL-Sekundärindex-Abfrageprozess?
Was ist der MySQL-Sekundärindex-Abfrageprozess?

- PHPznach vorne
- 2023-05-27 12:16:131419Durchsuche
Vorwort
Der Clustered-Index ist die Indexstruktur, die standardmäßig auf dem von innodb erstellten Primärschlüssel basiert. Die Daten in der Tabelle werden direkt im Clustered-Index als Datenseite des Blattknotens platziert:
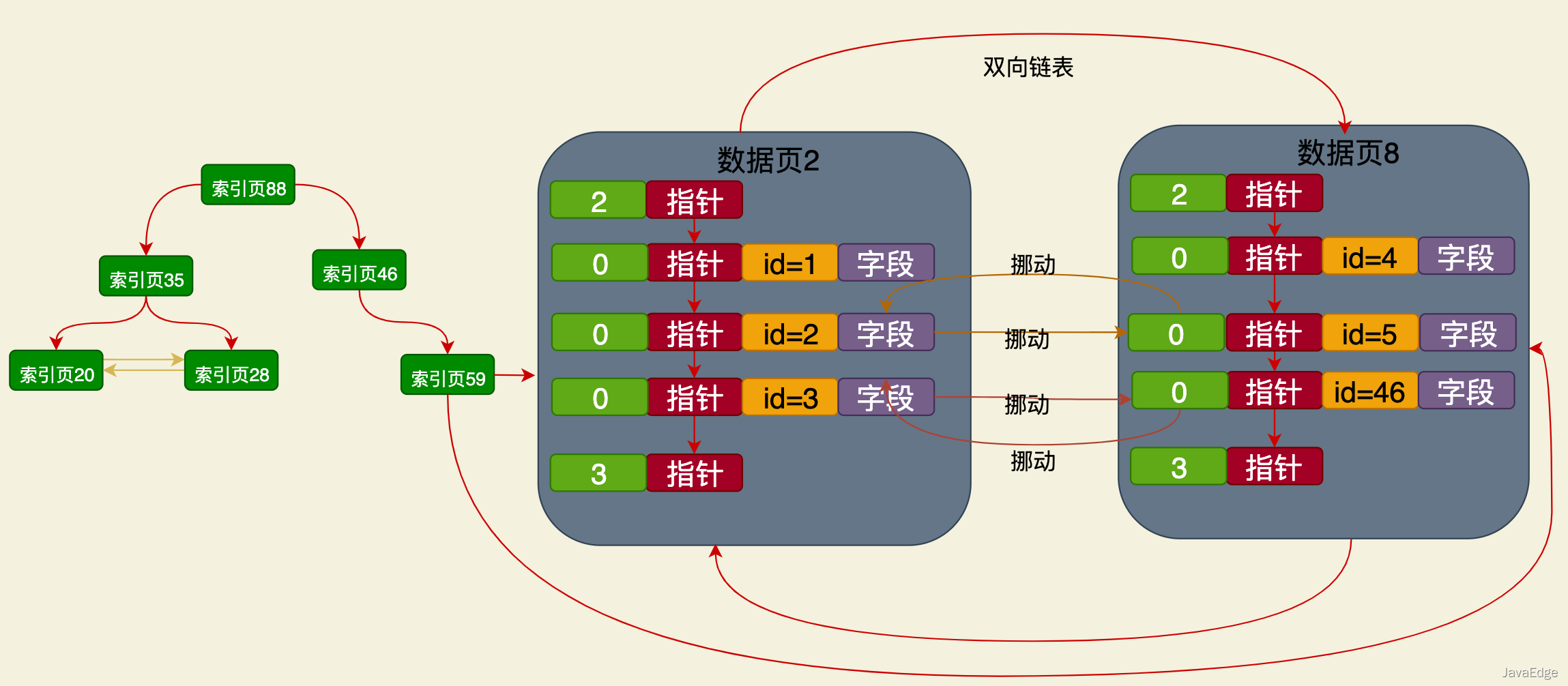
Daten Suche basierend auf dem Primärschlüssel: Starten Sie eine binäre Suche vom Stammknoten des Clustered-Index aus, suchen Sie die entsprechende Datenseite vollständig und suchen Sie direkt die Zieldaten des Primärschlüssels basierend auf dem Seitenverzeichnis.
Wenn Sie andere Felder indizieren oder sogar einen gemeinsamen Index basierend auf mehreren Feldern erstellen möchten, wie sieht die Indexstruktur aus?
Vorausgesetzt, dass andere Felder indiziert sind, wie z. B. Name, Alter usw., gilt das gleiche Prinzip. Wenn Sie beispielsweise Daten einfügen:
Fügen Sie die vollständigen Daten in die Datenseite des Blattknotens des Clustered-Index ein und pflegen Sie gleichzeitig den Clustered-Index
-
Index, der für Ihre anderen Felder erstellt wurde, und Erstellen Sie einen B+-Baum neu
Wenn Sie beispielsweise einen Index basierend auf dem Namensfeld erstellen, wird beim Einfügen von Daten ein neuer B+-Baum erstellt. Die Blattknoten des B+-Baums sind jedoch auch Datenseiten Auf der Datenseite werden nur das Primärschlüsselfeld und das Namensfeld platziert:
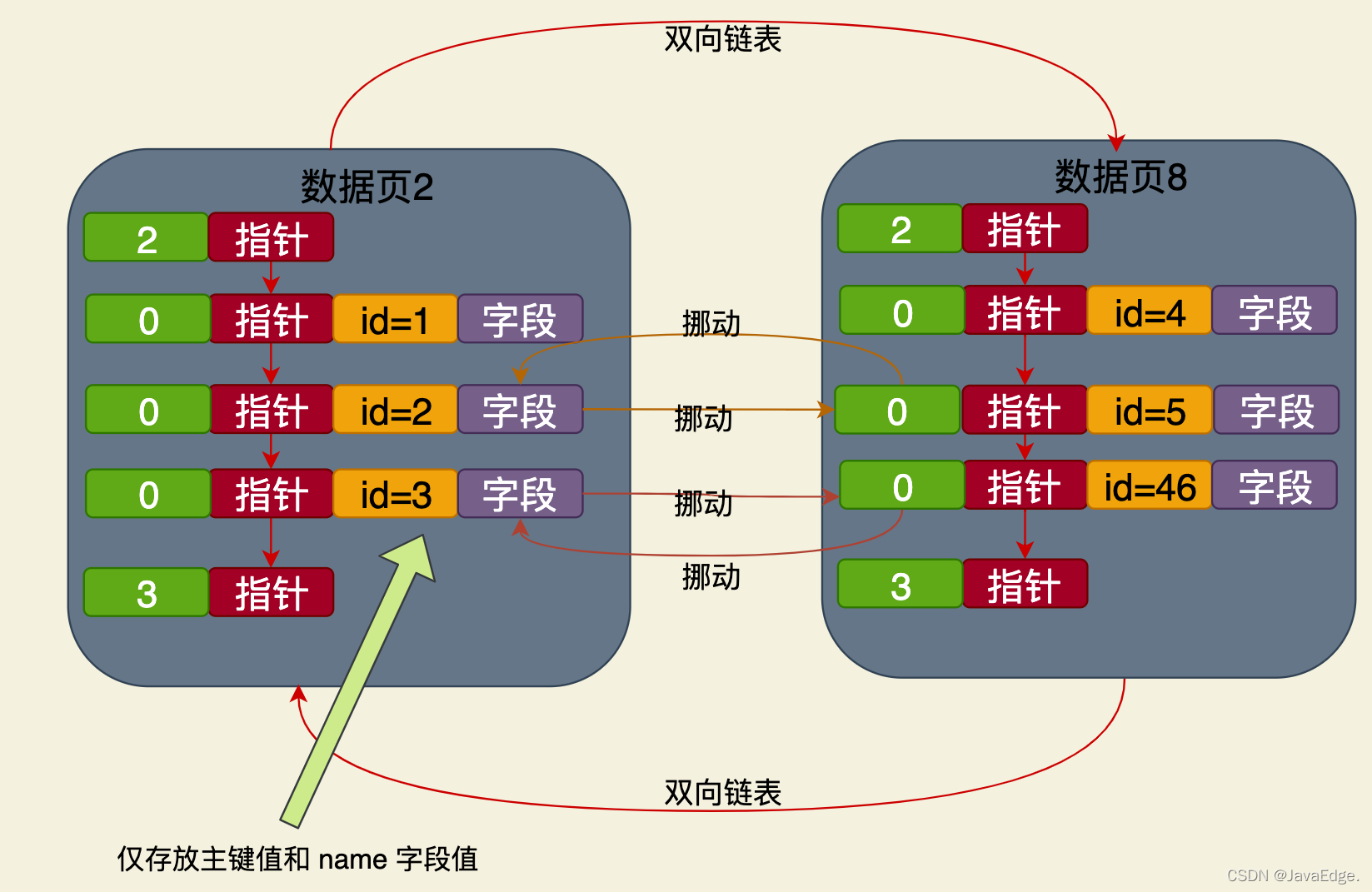
Dies ist eine auf dem B+-Baum basierende Indexstruktur, deren Namensfeld nur die in seinen Blattknoten gespeicherten Daten enthält die Werte des Primärschlüssels und des Namensfelds.
Die allgemeinen Sortierregeln sind dieselben wie die Sortierregeln des Clustered-Index nach dem Primärschlüssel, das heißt:
Die Namenswerte auf der Datenseite des Blattknotens sind alle sortiert
-
Der Namensfeldwert auf der nächsten Datenseite. Beide > Der Namensfeldwert auf der vorherigen Datenseite. Der Index-B+-Baum des Namensfelds erstellt außerdem eine mehrstufige Indexseite
Die Seitenzahl der nächsten Ebene
- Wenn Sie also Daten basierend auf dem Namensfeld abfragen, ist der Vorgang derselbe. Beginnen Sie vom Wurzelknoten des Namensindexbaums und suchen Sie Schicht für Schicht nach unten, bis Sie die Datenseite des Blattknotens finden Suchen Sie die Hauptseite, die dem Namensfeldwert entspricht.
- Dann suchen Sie für Anweisungen wie
select * from t where name='xx'
zunächst im Namensindexbaum basierend auf dem Namenswert und finden den Blattknoten. Es kann nur der entsprechende Primärschlüsselwert gefunden werden, jedoch nicht alle Felder dieser Datenzeile.
Alle Feldwerte herausnehmen.
Gemeinsamer Index
Beispiel: Name+Alter, der laufende Prozess ist derselbe und es wird ein unabhängiger B+-Baum erstellt. Nachdem die Datenseite des Blattknotens ID+Name+Alter gespeichert hat, wird sie standardmäßig nach Name sortiert . Wenn der Name gleich ist, wird er nach Alter sortiert. Das Gleiche gilt für die Reihenfolge der Namens- und Alterswerte zwischen den Seiten.
Dann wird die Indexseite des B+-Baums des gemeinsamen Indexes von Name + Alter gespeichert: select *
- Wenn Sie also Basieren Sie es auf Name+. Bei der Suche nach Alter durchläuft es den gemeinsamen Indexbaum Name+Alter, sucht nach dem Primärschlüssel und durchsucht dann den Clustered-Index basierend auf dem Primärschlüssel.
Das obige ist der detaillierte Inhalt vonWas ist der MySQL-Sekundärindex-Abfrageprozess?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!