
Heim >Datenbank >MySQL-Tutorial >So lösen Sie das Deep-Paging-Problem der SQL-Abfrage bei der MySQL-Optimierung
So lösen Sie das Deep-Paging-Problem der SQL-Abfrage bei der MySQL-Optimierung

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-27 09:58:371937Durchsuche
1. Problemeinführung
Zum Beispiel gibt es derzeit eine Tabelle test_user, und fügen Sie dann 3 Millionen Daten in diese Tabelle ein:
CREATE TABLE `test_user` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id', `user_id` varchar(36) NOT NULL COMMENT '用户id', `user_name` varchar(30) NOT NULL COMMENT '用户名称', `phone` varchar(20) NOT NULL COMMENT '手机号码', `lan_id` int(9) NOT NULL COMMENT '本地网', `region_id` int(9) NOT NULL COMMENT '区域', `create_time` datetime NOT NULL COMMENT '创建时间', PRIMARY KEY (`id`), KEY `idx_user_id` (`user_id`) ) ENGINE=InnoDB AUTO_INCREMENT;
Im Prozess der Datenbank Entwicklung Wir verwenden häufig Paging. Die Kerntechnologie besteht darin, limit start, count Paging-Anweisungen zum Lesen von Daten zu verwenden.
Schauen wir uns die Ausführungszeit des Paging beginnend bei 0, 10000, 100000, 500000, 1000000, 1800000 (100 Elemente pro Seite) an.
SELECT * FROM test_user LIMIT 0,100; # 0.031 SELECT * FROM test_user LIMIT 10000,100; # 0.047 SELECT * FROM test_user LIMIT 100000,100; # 0.109 SELECT * FROM test_user LIMIT 500000,100; # 0.219 SELECT * FROM test_user LIMIT 1000000,100; # 0.547s SELECT * FROM test_user LIMIT 1800000,100; # 1.625s
Wir haben gesehen, dass mit steigendem Startrekord auch die Zeit zunimmt. Nachdem wir den Startdatensatz auf 2,9 Millionen geändert haben, können wir sehen, dass eine große Korrelation zwischen dem Limit in der Paging-Anweisung und der Startseitenzahl besteht
SELECT * FROM test_user LIMIT 2900000,100; # 3.062s
Wir waren überrascht, dass MySQL dies kann Paging-Startpunkt, desto langsamer ist die Abfragegeschwindigkeit!
Warum kommt es also zu der oben genannten Situation?
Antwort: Weil die Syntax von limit 2900000.100 tatsächlich bedeutet, dass MySQL die ersten 2900100 Daten scannt und dann die ersten 3000000 Zeilen verwirft Abfall. .
Daraus können wir auch folgende zwei Dinge schließen:
Die Abfragezeit der Limit-Anweisung ist proportional zur Position des Startdatensatzes.
Die Limit-Anweisung von MySQL ist sehr praktisch, eignet sich jedoch nicht für die direkte Verwendung in Tabellen mit vielen Datensätzen.
2. Beschränken Sie die Verwendung in MySQL
Die Limit-Klausel kann verwendet werden, um zu erzwingen, dass die SELECT-Anweisung eine bestimmte Anzahl von Datensätzen zurückgibt. Ihr Syntaxformat ist wie folgt folgt: #🎜 🎜#
SELECT * FROM 表名 limit m,n; SELECT * FROM table LIMIT [offset,] rows;limit akzeptiert einen oder zwei numerische Parameter. Der Parameter muss eine Ganzzahlkonstante sein: Der erste Parameter gibt die erste zurückgegebene Datensatzzeile an . Offset
Der zweite Parameter gibt die maximale Anzahl zurückgegebener Datensatzzeilen an.
2,1 m bedeutet, den Abruf ab m+1 Datensatzzeilen zu starten, n bedeutet, n Datenelemente abzurufen . (m kann auf 0 gesetzt werden)
SELECT * FROM 表名 limit 6,5;Das obige SQL zeigt an, dass ab der 7. Datensatzzeile 5 Datenelemente herausgenommen werden # 🎜🎜#2.2 Es lohnt sich. Beachten Sie, dass n auf -1 gesetzt werden kann. Wenn n -1 ist, bedeutet dies, dass mit dem Abrufen ab Zeile m+1 begonnen wird, bis das letzte Datenelement abgerufen wird
Das obige SQL bedeutet, dass alle Daten nach der 6. Datensatzzeile abgerufen werden
2.3 Wenn nur m angegeben ist, bedeutet dies, dass ab dem insgesamt m Datensätze entnommen werden 1. DatensatzzeileSELECT * FROM 表名 limit 6,-1;
2.4 Nehmen Sie die ersten 3 Reihen in umgekehrter Reihenfolge des Alters heraus
SELECT * FROM 表名 limit 6;
2.5 Überspringen Sie die ersten 3 Zeilen und nehmen Sie dann die nächsten 2 Zeilen
Das heißt, suchen Sie zuerst die maximale ID des letzten Pagings und verwenden Sie dann den Index für die ID zur Abfrage:select * from student order by age desc limit 3;Die Verwendung dieses optimierten SQL ist bereits 11-mal schneller als die vorherige Abfrage. Zusätzlich zur Verwendung der Primärschlüssel-ID können Sie auch einen eindeutigen Index verwenden, um bestimmte Daten schnell zu finden und so einen vollständigen Tabellenscan zu vermeiden. Das Folgende ist der entsprechende SQL-Optimierungscode zum Lesen von Daten mit eindeutigen Schlüsseln (pk) im Bereich von 1000 bis 1019:
select * from student order by age desc limit 3,2;Grund: Das Scannen des Index erfolgt sehr schnell. Anwendbare Szenarien: Wenn die Datenabfrage nach PK oder ID sortiert ist und nicht alle Daten fehlen, können Sie auf diese Weise optimieren, da sonst beim Paging-Vorgang Daten verloren gehen. Methode 2: Indexabdeckungsoptimierung verwenden Wir alle wissen, dass die Anweisung, die eine Indexabfrage verwendet, nur diese Indexspalte enthält (d. h.
Indexabdeckung # 🎜🎜#), dann wird diese Situation schnell abgefragt.
Warum ist die Indexabdeckungsabfrage so schnell?Antwort: Da es einen Optimierungsalgorithmus für die Indexsuche gibt und sich die Daten im Abfrageindex befinden, ist es nicht erforderlich, die relevante Datenadresse zu finden, was viel Zeit spart . Wenn die Parallelität hoch ist, stellt MySQL auch einen dem Index zugeordneten Cache bereit. Durch die vollständige Nutzung dieses Caches können bessere Ergebnisse erzielt werden.
Da das ID-Feld der Primärschlüssel in unserer Testtabelle test_user ist, ist der Primärschlüsselindex standardmäßig enthalten. Sehen wir uns nun an, wie die Abfrage mit dem Covering-Index funktioniert. Dieses Mal fragen wir die Daten aus den Zeilen 1000001 bis 1000100 ab (unter Verwendung eines abdeckenden Index, der nur die ID-Spalte enthält):
SELECT * FROM test_user WHERE id>1000000 LIMIT 100; # 0.047秒
Aus diesem Ergebnis haben wir herausgefunden, dass die Abfrage Die Geschwindigkeit ist schneller als bei einem vollständigen Tabellenscan. Die Geschwindigkeit ist sogar noch langsamer (natürlich wird die Geschwindigkeit nach wiederholter Ausführung dieser SQL nach mehreren Abfragen viel schneller, wodurch fast die Hälfte der Zeit gespart wird. Dies liegt an der Zwischenspeicherung). um den Ausführungsplan der SQL anzuzeigen. Den gewöhnlichen Index idx_user_id gefunden, der in dieser SQL-Ausführung verwendet wird:
SELECT * FROM 表名称 WHERE pk>=1000 ORDER BY pk ASC LIMIT 0,20If Wir löschen den gewöhnlichen Index und verwenden bei der Ausführung des oben genannten SQL den Primärschlüsselindex. Wenn wir den normalen Index nicht löschen, können wir in diesem Fall, wenn wir möchten, dass das obige SQL den Primärschlüsselindex verwendet, die Order-By-Anweisung verwenden:
SELECT id FROM test_user LIMIT 1000000,100; # 0.843秒Wenn wir also auch abfragen möchten In allen Spalten gibt es zwei Es gibt zwei Methoden, eine in Form von id>= und die andere in der Verwendung von Join.
Die erste Schreibweise:
EXPLAIN SELECT id FROM test_user LIMIT 1000000,100;Die obige SQL-Abfragezeit beträgt 0,281 Sekunden
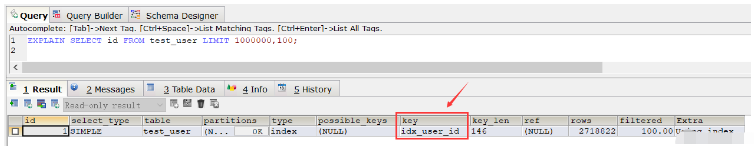 Die zweite Schreibweise:
Die zweite Schreibweise:
SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,100; # 0.250秒#🎜🎜 #Die obige SQL-Abfragezeit beträgt 0,252 Sekunden Methode 3: Neuordnung basierend auf dem Index wobei pageNum die Seitenzahl darstellt und ihr Wert bei 0 beginnt; stellt die Anzahl der Daten auf jeder Seite dar.
SELECT * FROM 表名称 WHERE id_pk > (pageNum*pageSize) ORDER BY id_pk ASC LIMIT pageSize;
适应场景:
适用于数据量多的情况
最好ORDER BY后的列对象是主键或唯一索引
id数据没有缺失,可以作为序号使用
使用ORDER BY操作能利用索引被消除,但结果集是稳定的
原因:
索引扫描,速度会很快
但MySQL的排序操作,只有ASC没有DESC。在MySQL中,索引的存储顺序是升序ASC,没有降序DESC的索引。这就是为什么默认情况下,order by 是按照升序排序的原因
方法四:基于索引使用prepare
PREPARE预编译一个SQL语句,并为其分配一个名称 stmt_name,以便以后引用该语句,预编译好的语句用EXECUTE执行。
PREPARE stmt_name FROM 'SELECT * FROM test_user WHERE id > ? ORDER BY id ASC LIMIT ?'; SET @a = 1000000; SET @b = 100; EXECUTE stmt_name USING @a, @b;;

上述SQL查询时间为0.047秒。
对于定义好的PREPARE预编译语句,我们可以使用下述命令来释放该预编译语句:
DEALLOCATE PREPARE stmt_name;
原因:
索引扫描,速度会很快.
prepare语句又比一般的查询语句快一点。
方法五:利用"子查询+索引"快速定位数据
其中page表示页码,其取值从0开始;pagesize表示指的是每页多少条数据。
SELECT * FROM your_table WHERE id <= (SELECT id FROM your_table ORDER BY id DESC LIMIT ($page-1)*$pagesize ORDER BY id DESC LIMIT $pagesize);
方法六:利用复合索引进行优化
假设数据表 collect ( id, title ,info ,vtype) 就这4个字段,其中id是主键自增,title用定长,info用text, vtype是tinyint,vtype是一个普通索引。
现在往里面填充数据,填充10万条记录,数据库表占用硬1.6G。
select id,title from collect limit 1000,10;
执行上述SQL速度很快,基本上0.01秒就OK。
select id,title from collect limit 90000,10;
然后再执行上述SQL,就发现非常慢,基本上平均8~9秒完成。
这个时候如果我们执行下述,我们会发现速度又变的很快,0.04秒就OK。
select id from collect order by id limit 90000,10;
那么这个现象的原因是什么?
答案:因为用了id主键做索引, 这里实现了索引覆盖,当然快。
所以如果想一起查询其它列的话,可以按照索引覆盖进行优化,具体如下:
select id,title from collect where id >= (select id from collect order by id limit 90000,1) limit 10;
再看下面的语句,带上where 条件:
select id from collect where vtype=1 order by id limit 90000,10;
可以发现这个速度上也是很慢的,用了8~9秒!
这里有一个疑惑:vtype 做了索引了啊?怎么会慢呢?
vtype做了索引是不错,如果直接对vtype进行过滤:
select id from collect where vtype=1 limit 1000,10;
可以看到速度还是很快的,基本上0.05秒,如果从9万开始,那就是0.05*90=4.5秒的速度了。
其实加了 order by id 就不走索引,这样做还是全表扫描,解决的办法是:复合索引!
因此针对下述SQL深度分页优化时可以加一个search_index(vtype,id)复合索引:
select id from collect where vtype=1 order by id limit 90000,10;
综上:
在进行SQL查询深度分页优化时,如果对于有where条件,又想走索引用limit的,必须设计一个索引,将where放第一位,limit用到的主键放第二位,而且只能select 主键。
最后根据查询出的主键走一级索引找到对应的数据。
按这样的逻辑,百万级的limit 在0.0x秒就可以分完,完美解决了分页问题。
Das obige ist der detaillierte Inhalt vonSo lösen Sie das Deep-Paging-Problem der SQL-Abfrage bei der MySQL-Optimierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!