
Heim >Datenbank >MySQL-Tutorial >So implementieren Sie die inkrementelle Datenübertragungsfunktion von MySQL in Echtzeit basierend auf Docker und Canal
So implementieren Sie die inkrementelle Datenübertragungsfunktion von MySQL in Echtzeit basierend auf Docker und Canal

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-26 20:28:311747Durchsuche
Einführung in den Kanal
Der historische Ursprung des Kanals
Anfangs stellte Alibaba Datenbankinstanzen in Computerräumen in Hangzhou und den Vereinigten Staaten bereit. Aufgrund der geschäftlichen Notwendigkeit, Daten über Computerräume hinweg zu synchronisieren, Es war schwierig, Canal zu konzipieren und zu entwickeln, hauptsächlich basierend auf der Trigger-Methode, um inkrementelle Änderungen zu erzielen. Ab 2010 begann Alibaba schrittweise mit der Analyse von Datenbankprotokollen, um schrittweise geänderte Daten für die Synchronisierung zu erhalten, was zu inkrementellen Abonnement- und Verbrauchsgeschäften führte.
Zu den aktuellen MySQL-Versionen der Datenquelle, die von Canal unterstützt werden, gehören: 5.1.x, 5.5.x, 5.6.x, 5.7.x, 8.0.x. Kanalanwendungsszenarien
Indexaufbau und Echtzeitpflege (geteilter heterogener Index, invertierter Index usw.)
- Aktualisierung des Geschäftscaches
- Inkrementelle Datenverarbeitung mit Geschäftslogik
- Funktionsweise des Kanals
- Bevor wir das Kanalprinzip einführen, wollen wir zunächst das Prinzip der MySQL-Master-Slave-Replikation verstehen.
- MySQL-Master-Slave-Replikationsprinzip
- MySQL-Master schreibt Datenänderungsvorgänge in das Binärprotokoll. Der aufgezeichnete Inhalt wird als binäre Protokollereignisse bezeichnet, die über den Befehl „Anzeige von Binlog-Ereignissen“ ausgeführt werden können
MySQL-Slave liest die Ereignisse im Relay-Protokoll erneut und führt sie aus und ordnet die Datenänderungen seiner eigenen Datenbanktabelle zu.
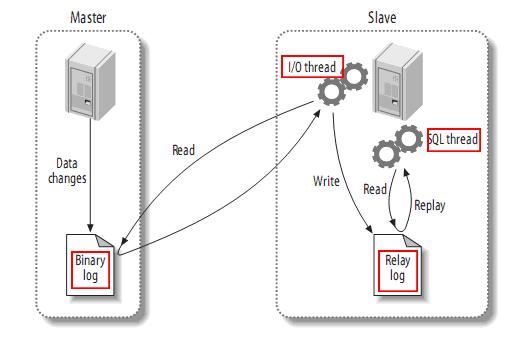
- Wenn wir das Funktionsprinzip von MySQL verstehen, können wir grob vermuten, dass Canal auch eine ähnliche Logik verwenden sollte, um die Funktion des inkrementellen Datenabonnements zu implementieren. Schauen wir uns dann an, wie Canal tatsächlich funktioniert.
- Canal-Funktionsprinzip
- Canal simuliert das Interaktionsprotokoll des MySQL-Slaves, tarnt sich als MySQL-Slave und sendet das Dump-Protokoll an den MySQL-Master.
Kanal analysiert binäre Protokollobjekte (Daten sind Byte-Stream)
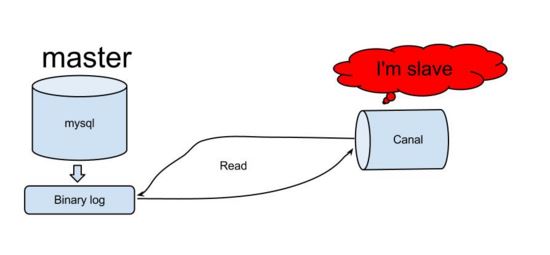
- Basierend auf diesem Prinzip und dieser Methode kann es die Erfassung und Analyse von inkrementellen Datenbankprotokollen abschließen und inkrementelle Protokolle bereitstellen Datenabonnement und -verbrauch realisieren die Funktion der inkrementellen Datenübertragung in Echtzeit mit MySQL.
Da Canal ein solches Framework ist und in reiner Java-Sprache geschrieben ist, beginnen wir zu lernen, wie man es verwendet und auf unsere eigentliche Arbeit anwendet. Vorbereitung der Docker-Umgebung von Canal Wir können uns auch selbst darauf verlassen. Die mit Kürbis bemalte Schöpfkelle wurde erfolgreich gebaut. Da dieser Artikel hauptsächlich den Kanal erklärt, wird er nicht zu viel über Docker behandeln, sondern hauptsächlich die grundlegenden Konzepte und die Befehlsverwendung von Docker vorstellen. Wenn Sie mit weiteren Experten für Containertechnologie kommunizieren möchten, können Sie mich auf WeChat liyingjiese hinzufügen und auf „Gruppe hinzufügen“ klicken. Die Gruppe enthält jede Woche die Best Practices großer Unternehmen auf der ganzen Welt und die neuesten Branchentrends.
- Was ist Docker? Ich glaube, dass die meisten Leute die virtuelle Maschine VMware zum Erstellen der Umgebung verwendet haben. Sie müssen lediglich ein normales Systemabbild bereitstellen und es sowie die verbleibende Softwareumgebung und Anwendungen erfolgreich installieren Die Konfiguration erfolgt immer noch in der virtuellen Maschine, wie wir es auf der lokalen Maschine tun, und VMware beansprucht viele Host-Ressourcen, was leicht zum Einfrieren des Hosts führen kann, und auch das System-Image selbst nimmt zu viel Platz ein.
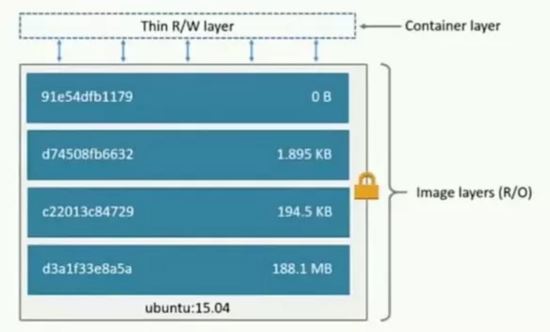
Um es allen zu erleichtern, Docker schnell zu verstehen, vergleichen wir es zur Einführung mit VMware. Docker bietet eine Plattform zum Starten, Packen und Ausführen von Apps, die die App (Anwendung) von der zugrunde liegenden Infrastruktur (Infrastruktur) isoliert. . Die beiden wichtigsten Konzepte in Docker sind Images (ähnlich den System-Images in VMware) und Container (ähnlich den in VMware installierten Systemen).
Eine Sammlung von Dateien und Metadaten (Root-Dateisystem)
Es ist geschichtet und jede Ebene kann Dateien hinzufügen, ändern und löschen, um ein neues Bild zu erstellen
Verschiedene Bilder können dieselbe Ebene teilen.
Das Bild selbst ist schreibgeschützt.
Was ist ein Container?
Erstellen Sie eine Containerschicht (lesbar und beschreibbar) über der Bildebene.
Analogie objektorientiert: Klassen und Instanzen.
Das Bild ist für die Speicherung und Verteilung der App verantwortlich, und der Container ist es Verantwortlich für den Betrieb der App
Einführung in das Docker-Netzwerk
Docker hat drei Netzwerktypen:
Bridge: Bridge-Netzwerk. Standardmäßig verwenden die gestarteten Docker-Container Bridge, ein Bridge-Netzwerk, das bei jedem Neustart des Docker-Containers erstellt wird. Dies führt dazu, dass sich die Docker-IP-Adresse nach dem Neustart ändert.
none: Kein angegebenes Netzwerk. Mit --network=none weist der Docker-Container keine LAN-IP zu.
Host: Host-Netzwerk. Wenn --network=host verwendet wird, teilt der Docker-Container das Netzwerk mit dem Host und die beiden können miteinander kommunizieren. Wenn ein Webdienst ausgeführt wird, der Port 8080 in einem Container überwacht, wird der Container automatisch dem Port 8080 des Hosts zugeordnet.
Erstellen Sie ein benutzerdefiniertes Netzwerk: (Feste IP festlegen)
docker network create --subnet=172.18.0.0/16 mynetwork
Sehen Sie sich das vorhandene Docker-Netzwerk vom Typ Netzwerk ls an:

Erstellen Sie eine Kanalumgebung
Angehängt ist die Docker-Download- und Installationsadresse ==> ; Docker-Download.
Kanalbild docker pull canal/canal-server herunterladen: docker pull canal/canal-server:
下载mysql镜像docker pull mysql,下载过的则如下图:

查看已经下载好的镜像docker images:

接下来通过镜像生成mysql容器与canal-server容器:
##生成mysql容器 docker run -d --name mysql --net mynetwork --ip 172.18.0.6 -p 3306:3306 -e mysql_root_password=root mysql ##生成canal-server容器 docker run -d --name canal-server --net mynetwork --ip 172.18.0.4 -p 11111:11111 canal/canal-server ## 命令介绍 --net mynetwork #使用自定义网络 --ip #指定分配ip
查看docker中运行的容器docker ps:

mysql的配置修改
以上只是初步准备好了基础的环境,但是怎么让canal伪装成salve并正确获取mysql中的binary log呢?
对于自建mysql,需要先开启binlog写入功能,配置binlog-format为row模式,通过修改mysql配置文件来开启bin_log,使用find / -name my.cnf查找my.cnf,修改文件内容如下:
[mysqld] log-bin=mysql-bin # 开启binlog binlog-format=row # 选择row模式 server_id=1 # 配置mysql replaction需要定义,不要和canal的slaveid重复
进入mysql容器docker exec -it mysql bash。
创建链接mysql的账号canal并授予作为mysql slave的权限,如果已有账户可直接grant:
mysql -uroot -proot # 创建账号 create user canal identified by 'canal'; # 授予权限 grant select, replication slave, replication client on *.* to 'canal'@'%'; -- grant all privileges on *.* to 'canal'@'%' ; # 刷新并应用 flush privileges;
数据库重启后,简单测试 my.cnf 配置是否生效:
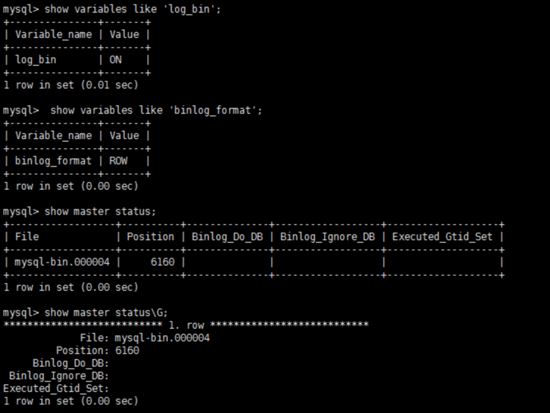
show variables like 'log_bin'; show variables like 'log_bin'; show master status;
canal-server的配置修改
进入canal-server容器docker exec -it canal-server bash。
编辑canal-server的配置vi canal-server/conf/example/instance.properties:

更多配置请参考==>canal配置说明 。
重启canal-server容器docker restart canal-server

Laden Sie das MySQL-Image docker pull mysql herunter. Das heruntergeladene Bild sieht wie folgt aus:
Sehen Sie sich die heruntergeladenen Mirror-Docker-Bilder an:
Als nächstes generieren Sie den MySQL-Container und den Canal-Server-Container über den Spiegel:
docker exec -it canal-server bash tail -100f canal-server/logs/example/example.log
Sehen Sie sich den Container an, der in Docker ausgeführt wird. Docker ps: 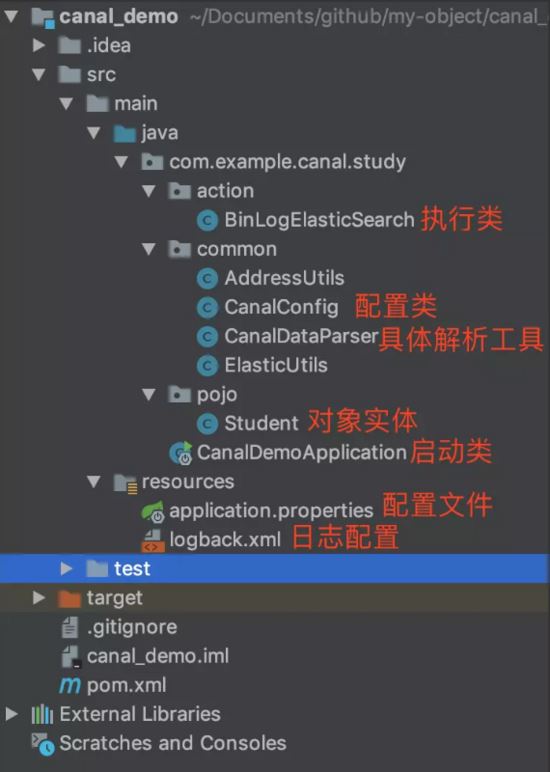
mysql Konfigurationsänderung
Das Obige ist nur eine vorläufige Vorbereitung der Basisumgebung, aber wie kann man den Kanal als Salve tarnen und das Binärprotokoll in MySQL korrekt abrufen? Für selbst erstelltes MySQL müssen Sie zuerst die Binlog-Schreibfunktion aktivieren,binlog-format für den Zeilenmodus konfigurieren, bin_log durch Ändern der MySQL-Konfigurationsdatei öffnen und find / - verwenden Benennen Sie my.cnf Suchen Sie my.cnf und ändern Sie den Dateiinhalt wie folgt: # 下载对镜像 docker pull elasticsearch:7.1.1 docker pull mobz/elasticsearch-head:5-alpine # 创建容器并运行 docker run -d --name elasticsearch --net mynetwork --ip 172.18.0.2 -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.1.1 docker run -d --name elasticsearch-head --net mynetwork --ip 172.18.0.5 -p 9100:9100 mobz/elasticsearch-head:5-alpineGeben Sie den MySQL-Container ein
docker exec -it mysql bash. Erstellen Sie einen mit MySQL verknüpften Kontokanal und erteilen Sie die Berechtigung, ein MySQL-Slave zu sein. Wenn Sie bereits ein Konto haben, können Sie Folgendes direkt gewähren: 🎜package com.example.canal.study.pojo;
import lombok.data;
import java.io.serializable;
// @data 用户生产getter、setter方法
@data
public class student implements serializable {
private string id;
private string name;
private int age;
private string sex;
private string city;
}🎜Testen Sie nach dem Neustart der Datenbank einfach, ob die my.cnf Die Konfiguration wird wirksam: 🎜🎜package com.example.canal.study.common;
import com.alibaba.otter.canal.client.canalconnector;
import com.alibaba.otter.canal.client.canalconnectors;
import org.apache.http.httphost;
import org.elasticsearch.client.restclient;
import org.elasticsearch.client.resthighlevelclient;
import org.springframework.beans.factory.annotation.value;
import org.springframework.context.annotation.bean;
import org.springframework.context.annotation.configuration;
import java.net.inetsocketaddress;
/**
* @author haha
*/
@configuration
public class canalconfig {
// @value 获取 application.properties配置中端内容
@value("${canal.server.ip}")
private string canalip;
@value("${canal.server.port}")
private integer canalport;
@value("${canal.destination}")
private string destination;
@value("${elasticsearch.server.ip}")
private string elasticsearchip;
@value("${elasticsearch.server.port}")
private integer elasticsearchport;
@value("${zookeeper.server.ip}")
private string zkserverip;
// 获取简单canal-server连接
@bean
public canalconnector canalsimpleconnector() {
canalconnector canalconnector = canalconnectors.newsingleconnector(new inetsocketaddress(canalip, canalport), destination, "", "");
return canalconnector;
}
// 通过连接zookeeper获取canal-server连接
@bean
public canalconnector canalhaconnector() {
canalconnector canalconnector = canalconnectors.newclusterconnector(zkserverip, destination, "", "");
return canalconnector;
}
// elasticsearch 7.x客户端
@bean
public resthighlevelclient resthighlevelclient() {
resthighlevelclient client = new resthighlevelclient(
restclient.builder(new httphost(elasticsearchip, elasticsearchport))
);
return client;
}
}🎜🎜canal- Ändern Sie die Serverkonfiguration 🎜🎜🎜 in den Canal-Server-Container docker exec -it canal-server bash. 🎜🎜Kanalserverkonfiguration bearbeiten vi canal-server/conf/example/instance.properties: 🎜🎜package com.example.canal.study.common;
import com.alibaba.fastjson.json;
import com.example.canal.study.pojo.student;
import lombok.extern.slf4j.slf4j;
import org.elasticsearch.client.resthighlevelclient;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.stereotype.component;
import org.elasticsearch.action.docwriterequest;
import org.elasticsearch.action.delete.deleterequest;
import org.elasticsearch.action.delete.deleteresponse;
import org.elasticsearch.action.get.getrequest;
import org.elasticsearch.action.get.getresponse;
import org.elasticsearch.action.index.indexrequest;
import org.elasticsearch.action.index.indexresponse;
import org.elasticsearch.action.update.updaterequest;
import org.elasticsearch.action.update.updateresponse;
import org.elasticsearch.client.requestoptions;
import org.elasticsearch.common.xcontent.xcontenttype;
import java.io.ioexception;
import java.util.map;
/**
* @author haha
*/
@slf4j
@component
public class elasticutils {
@autowired
private resthighlevelclient resthighlevelclient;
/**
* 新增
* @param student
* @param index 索引
*/
public void savees(student student, string index) {
indexrequest indexrequest = new indexrequest(index)
.id(student.getid())
.source(json.tojsonstring(student), xcontenttype.json)
.optype(docwriterequest.optype.create);
try {
indexresponse response = resthighlevelclient.index(indexrequest, requestoptions.default);
log.info("保存数据至elasticsearch成功:{}", response.getid());
} catch (ioexception e) {
log.error("保存数据至elasticsearch失败: {}", e);
}
}
/**
* 查看
* @param index 索引
* @param id _id
* @throws ioexception
*/
public void getes(string index, string id) throws ioexception {
getrequest getrequest = new getrequest(index, id);
getresponse response = resthighlevelclient.get(getrequest, requestoptions.default);
map<string, object> fields = response.getsource();
for (map.entry<string, object> entry : fields.entryset()) {
system.out.println(entry.getkey() + ":" + entry.getvalue());
}
}
/**
* 更新
* @param student
* @param index 索引
* @throws ioexception
*/
public void updatees(student student, string index) throws ioexception {
updaterequest updaterequest = new updaterequest(index, student.getid());
updaterequest.upsert(json.tojsonstring(student), xcontenttype.json);
updateresponse response = resthighlevelclient.update(updaterequest, requestoptions.default);
log.info("更新数据至elasticsearch成功:{}", response.getid());
}
/**
* 根据id删除数据
* @param index 索引
* @param id _id
* @throws ioexception
*/
public void deletees(string index, string id) throws ioexception {
deleterequest deleterequest = new deleterequest(index, id);
deleteresponse response = resthighlevelclient.delete(deleterequest, requestoptions.default);
log.info("删除数据至elasticsearch成功:{}", response.getid());
}
}🎜Die Umgebung ist bereit, jetzt beginnen wir mit dem Codieren Praktischer Teil: So übergeben Sie die Anwendung, um die vom Kanal analysierten Binlog-Daten abzurufen. Zuerst erstellen wir eine Kanal-Demoanwendung basierend auf Spring Boot. Die Struktur ist wie in der folgenden Abbildung dargestellt: 🎜🎜🎜🎜🎜student.java🎜package com.example.canal.study.action;
import com.alibaba.otter.canal.client.canalconnector;
import com.alibaba.otter.canal.protocol.canalentry;
import com.alibaba.otter.canal.protocol.message;
import com.example.canal.study.common.canaldataparser;
import com.example.canal.study.common.elasticutils;
import com.example.canal.study.pojo.student;
import lombok.extern.slf4j.slf4j;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.beans.factory.annotation.qualifier;
import org.springframework.stereotype.component;
import java.io.ioexception;
import java.util.list;
import java.util.map;
/**
* @author haha
*/
@slf4j
@component
public class binlogelasticsearch {
@autowired
private canalconnector canalsimpleconnector;
@autowired
private elasticutils elasticutils;
//@qualifier("canalhaconnector")使用名为canalhaconnector的bean
@autowired
@qualifier("canalhaconnector")
private canalconnector canalhaconnector;
public void binlogtoelasticsearch() throws ioexception {
opencanalconnector(canalhaconnector);
// 轮询拉取数据
integer batchsize = 5 * 1024;
while (true) {
message message = canalhaconnector.getwithoutack(batchsize);
// message message = canalsimpleconnector.getwithoutack(batchsize);
long id = message.getid();
int size = message.getentries().size();
log.info("当前监控到binlog消息数量{}", size);
if (id == -1 || size == 0) {
try {
// 等待2秒
thread.sleep(2000);
} catch (interruptedexception e) {
e.printstacktrace();
}
} else {
//1. 解析message对象
list<canalentry.entry> entries = message.getentries();
list<canaldataparser.twotuple<canalentry.eventtype, map>> rows = canaldataparser.printentry(entries);
for (canaldataparser.twotuple<canalentry.eventtype, map> tuple : rows) {
if(tuple.eventtype == canalentry.eventtype.insert) {
student student = createstudent(tuple);
// 2。将解析出的对象同步到elasticsearch中
elasticutils.savees(student, "student_index");
// 3.消息确认已处理
// canalsimpleconnector.ack(id);
canalhaconnector.ack(id);
}
if(tuple.eventtype == canalentry.eventtype.update){
student student = createstudent(tuple);
elasticutils.updatees(student, "student_index");
// 3.消息确认已处理
// canalsimpleconnector.ack(id);
canalhaconnector.ack(id);
}
if(tuple.eventtype == canalentry.eventtype.delete){
elasticutils.deletees("student_index", tuple.columnmap.get("id").tostring());
canalhaconnector.ack(id);
}
}
}
}
}
/**
* 封装数据至student
* @param tuple
* @return
*/
private student createstudent(canaldataparser.twotuple<canalentry.eventtype, map> tuple){
student student = new student();
student.setid(tuple.columnmap.get("id").tostring());
student.setage(integer.parseint(tuple.columnmap.get("age").tostring()));
student.setname(tuple.columnmap.get("name").tostring());
student.setsex(tuple.columnmap.get("sex").tostring());
student.setcity(tuple.columnmap.get("city").tostring());
return student;
}
/**
* 打开canal连接
*
* @param canalconnector
*/
private void opencanalconnector(canalconnector canalconnector) {
//连接canalserver
canalconnector.connect();
// 订阅destination
canalconnector.subscribe();
}
/**
* 关闭canal连接
*
* @param canalconnector
*/
private void closecanalconnector(canalconnector canalconnector) {
//关闭连接canalserver
canalconnector.disconnect();
// 注销订阅destination
canalconnector.unsubscribe();
}
}🎜canalconfig.java🎜package com.example.canal.study;
import com.example.canal.study.action.binlogelasticsearch;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.boot.applicationarguments;
import org.springframework.boot.applicationrunner;
import org.springframework.boot.springapplication;
import org.springframework.boot.autoconfigure.springbootapplication;
/**
* @author haha
*/
@springbootapplication
public class canaldemoapplication implements applicationrunner {
@autowired
private binlogelasticsearch binlogelasticsearch;
public static void main(string[] args) {
springapplication.run(canaldemoapplication.class, args);
}
// 程序启动则执行run方法
@override
public void run(applicationarguments args) throws exception {
binlogelasticsearch.binlogtoelasticsearch();
}
}🎜canaldataparser.java🎜🎜Da diese Klasse viel Code enthält, werden die wichtigeren Teile davon extrahiert Weitere Teile des Codes finden Sie unter Get it on github: 🎜server.port=8081 spring.application.name = canal-demo canal.server.ip = 192.168.124.5 canal.server.port = 11111 canal.destination = example zookeeper.server.ip = 192.168.124.5:2181 zookeeper.sasl.client = false elasticsearch.server.ip = 192.168.124.5 elasticsearch.server.port = 9200🎜elasticutils.java🎜
docker pull zookeeper docker run -d --name zookeeper --net mynetwork --ip 172.18.0.3 -p 2181:2181 zookeeper docker run -d --name canal-server2 --net mynetwork --ip 172.18.0.8 -p 11113:11113 canal/canal-server🎜binlogelasticsearch.java🎜
package com.example.canal.study.action;
import com.alibaba.otter.canal.client.canalconnector;
import com.alibaba.otter.canal.protocol.canalentry;
import com.alibaba.otter.canal.protocol.message;
import com.example.canal.study.common.canaldataparser;
import com.example.canal.study.common.elasticutils;
import com.example.canal.study.pojo.student;
import lombok.extern.slf4j.slf4j;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.beans.factory.annotation.qualifier;
import org.springframework.stereotype.component;
import java.io.ioexception;
import java.util.list;
import java.util.map;
/**
* @author haha
*/
@slf4j
@component
public class binlogelasticsearch {
@autowired
private canalconnector canalsimpleconnector;
@autowired
private elasticutils elasticutils;
//@qualifier("canalhaconnector")使用名为canalhaconnector的bean
@autowired
@qualifier("canalhaconnector")
private canalconnector canalhaconnector;
public void binlogtoelasticsearch() throws ioexception {
opencanalconnector(canalhaconnector);
// 轮询拉取数据
integer batchsize = 5 * 1024;
while (true) {
message message = canalhaconnector.getwithoutack(batchsize);
// message message = canalsimpleconnector.getwithoutack(batchsize);
long id = message.getid();
int size = message.getentries().size();
log.info("当前监控到binlog消息数量{}", size);
if (id == -1 || size == 0) {
try {
// 等待2秒
thread.sleep(2000);
} catch (interruptedexception e) {
e.printstacktrace();
}
} else {
//1. 解析message对象
list<canalentry.entry> entries = message.getentries();
list<canaldataparser.twotuple<canalentry.eventtype, map>> rows = canaldataparser.printentry(entries);
for (canaldataparser.twotuple<canalentry.eventtype, map> tuple : rows) {
if(tuple.eventtype == canalentry.eventtype.insert) {
student student = createstudent(tuple);
// 2。将解析出的对象同步到elasticsearch中
elasticutils.savees(student, "student_index");
// 3.消息确认已处理
// canalsimpleconnector.ack(id);
canalhaconnector.ack(id);
}
if(tuple.eventtype == canalentry.eventtype.update){
student student = createstudent(tuple);
elasticutils.updatees(student, "student_index");
// 3.消息确认已处理
// canalsimpleconnector.ack(id);
canalhaconnector.ack(id);
}
if(tuple.eventtype == canalentry.eventtype.delete){
elasticutils.deletees("student_index", tuple.columnmap.get("id").tostring());
canalhaconnector.ack(id);
}
}
}
}
}
/**
* 封装数据至student
* @param tuple
* @return
*/
private student createstudent(canaldataparser.twotuple<canalentry.eventtype, map> tuple){
student student = new student();
student.setid(tuple.columnmap.get("id").tostring());
student.setage(integer.parseint(tuple.columnmap.get("age").tostring()));
student.setname(tuple.columnmap.get("name").tostring());
student.setsex(tuple.columnmap.get("sex").tostring());
student.setcity(tuple.columnmap.get("city").tostring());
return student;
}
/**
* 打开canal连接
*
* @param canalconnector
*/
private void opencanalconnector(canalconnector canalconnector) {
//连接canalserver
canalconnector.connect();
// 订阅destination
canalconnector.subscribe();
}
/**
* 关闭canal连接
*
* @param canalconnector
*/
private void closecanalconnector(canalconnector canalconnector) {
//关闭连接canalserver
canalconnector.disconnect();
// 注销订阅destination
canalconnector.unsubscribe();
}
}canaldemoapplication.java(spring boot启动类)
package com.example.canal.study;
import com.example.canal.study.action.binlogelasticsearch;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.boot.applicationarguments;
import org.springframework.boot.applicationrunner;
import org.springframework.boot.springapplication;
import org.springframework.boot.autoconfigure.springbootapplication;
/**
* @author haha
*/
@springbootapplication
public class canaldemoapplication implements applicationrunner {
@autowired
private binlogelasticsearch binlogelasticsearch;
public static void main(string[] args) {
springapplication.run(canaldemoapplication.class, args);
}
// 程序启动则执行run方法
@override
public void run(applicationarguments args) throws exception {
binlogelasticsearch.binlogtoelasticsearch();
}
}application.properties
server.port=8081 spring.application.name = canal-demo canal.server.ip = 192.168.124.5 canal.server.port = 11111 canal.destination = example zookeeper.server.ip = 192.168.124.5:2181 zookeeper.sasl.client = false elasticsearch.server.ip = 192.168.124.5 elasticsearch.server.port = 9200
canal集群高可用的搭建
通过上面的学习,我们知道了单机直连方式的canala应用。在当今互联网时代,单实例模式逐渐被集群高可用模式取代,那么canala的多实例集群方式如何搭建呢!
基于zookeeper获取canal实例
准备zookeeper的docker镜像与容器:
docker pull zookeeper docker run -d --name zookeeper --net mynetwork --ip 172.18.0.3 -p 2181:2181 zookeeper docker run -d --name canal-server2 --net mynetwork --ip 172.18.0.8 -p 11113:11113 canal/canal-server
1、机器准备:
运行canal的容器ip: 172.18.0.4 , 172.18.0.8
zookeeper容器ip:172.18.0.3:2181
mysql容器ip:172.18.0.6:3306
2、按照部署和配置,在单台机器上各自完成配置,演示时instance name为example。
3、修改canal.properties,加上zookeeper配置并修改canal端口:
canal.port=11113 canal.zkservers=172.18.0.3:2181 canal.instance.global.spring.xml = classpath:spring/default-instance.xml
4、创建example目录,并修改instance.properties:
canal.instance.mysql.slaveid = 1235 #之前的canal slaveid是1234,保证slaveid不重复即可 canal.instance.master.address = 172.18.0.6:3306
注意: 两台机器上的instance目录的名字需要保证完全一致,ha模式是依赖于instance name进行管理,同时必须都选择default-instance.xml配置。
启动两个不同容器的canal,启动后,可以通过tail -100f logs/example/example.log查看启动日志,只会看到一台机器上出现了启动成功的日志。
比如我这里启动成功的是 172.18.0.4:
查看一下zookeeper中的节点信息,也可以知道当前工作的节点为172.18.0.4:11111:
[zk: localhost:2181(connected) 15] get /otter/canal/destinations/example/running
{"active":true,"address":"172.18.0.4:11111","cid":1}客户端链接, 消费数据
可以通过指定zookeeper地址和canal的instance name,canal client会自动从zookeeper中的running节点获取当前服务的工作节点,然后与其建立链接:
[zk: localhost:2181(connected) 0] get /otter/canal/destinations/example/running
{"active":true,"address":"172.18.0.4:11111","cid":1}对应的客户端编码可以使用如下形式,上文中的canalconfig.java中的canalhaconnector就是一个ha连接:
canalconnector connector = canalconnectors.newclusterconnector("172.18.0.3:2181", "example", "", "");链接成功后,canal server会记录当前正在工作的canal client信息,比如客户端ip,链接的端口信息等(聪明的你,应该也可以发现,canal client也可以支持ha功能):
[zk: localhost:2181(connected) 4] get /otter/canal/destinations/example/1001/running
{"active":true,"address":"192.168.124.5:59887","clientid":1001}数据消费成功后,canal server会在zookeeper中记录下当前最后一次消费成功的binlog位点(下次你重启client时,会从这最后一个位点继续进行消费):
[zk: localhost:2181(connected) 5] get /otter/canal/destinations/example/1001/cursor
{"@type":"com.alibaba.otter.canal.protocol.position.logposition","identity":{"slaveid":-1,"sourceaddress":{"address":"mysql.mynetwork","port":3306}},"postion":{"included":false,"journalname":"binlog.000004","position":2169,"timestamp":1562672817000}}停止正在工作的172.18.0.4的canal server:
docker exec -it canal-server bash cd canal-server/bin sh stop.sh
这时172.18.0.8会立马启动example instance,提供新的数据服务:
[zk: localhost:2181(connected) 19] get /otter/canal/destinations/example/running
{"active":true,"address":"172.18.0.8:11111","cid":1}与此同时,客户端也会随着canal server的切换,通过获取zookeeper中的最新地址,与新的canal server建立链接,继续消费数据,整个过程自动完成。
异常与总结
elasticsearch-head无法访问elasticsearch
es与es-head是两个独立的进程,当es-head访问es服务时,会存在一个跨域问题。所以我们需要修改es的配置文件,增加一些配置项来解决这个问题,如下:
[root@localhost /usr/local/elasticsearch-head-master]# cd ../elasticsearch-5.5.2/config/ [root@localhost /usr/local/elasticsearch-5.5.2/config]# vim elasticsearch.yml # 文件末尾加上如下配置 http.cors.enabled: true http.cors.allow-origin: "*"
修改完配置文件后需重启es服务。
elasticsearch-head查询报406 not acceptable
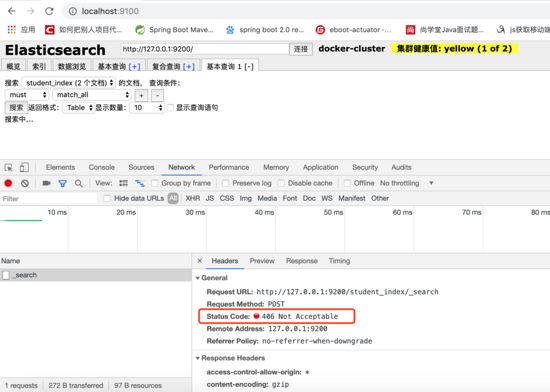
解决方法:
1、进入head安装目录;
2、cd _site/
3、编辑vendor.js 共有两处
#6886行 contenttype: "application/x-www-form-urlencoded 改成 contenttype: "application/json;charset=utf-8" #7574行 var inspectdata = s.contenttype === "application/x-www-form-urlencoded" && 改成 var inspectdata = s.contenttype === "application/json;charset=utf-8" &&
使用elasticsearch-rest-high-level-client报org.elasticsearch.action.index.indexrequest.ifseqno
#pom中除了加入依赖 <dependency> <groupid>org.elasticsearch.client</groupid> <artifactid>elasticsearch-rest-high-level-client</artifactid> <version>7.1.1</version> </dependency> #还需加入 <dependency> <groupid>org.elasticsearch</groupid> <artifactid>elasticsearch</artifactid> <version>7.1.1</version> </dependency>
相关参考: 。
为什么elasticsearch要在7.x版本不能使用type?
参考: 为什么elasticsearch要在7.x版本去掉type?
使用spring-data-elasticsearch.jar报org.elasticsearch.client.transport.nonodeavailableexception
由于本文使用的是elasticsearch7.x以上的版本,目前spring-data-elasticsearch底层采用es官方transportclient,而es官方计划放弃transportclient,工具以es官方推荐的resthighlevelclient进行调用请求。 可参考 resthighlevelclient api 。
设置docker容器开启启动
如果创建时未指定 --restart=always ,可通过update 命令 docker update --restart=always [containerid]
docker for mac network host模式不生效
host模式是为了性能,但是这却对docker的隔离性造成了破坏,导致安全性降低。 在性能场景下,可以用--netwokr host开启host模式,但需要注意的是,如果你用windows或mac本地启动容器的话,会遇到host模式失效的问题。原因是host模式只支持linux宿主机。
参见官方文档: 。
客户端连接zookeeper报authenticate using sasl(unknow error)

zookeeper.jar stimmt nicht mit der Zookeeper-Version in dokcer überein
- #🎜🎜 # zookeeper.jar verwendet eine Version vor 3.4.6
system.setproperty("zookeeper.sasl.client", "false"); zum Projektcode hinzu, Wenn es sich um ein Spring-Boot-Projekt handelt, können Sie es hinzufügen in application. Fügen Sie <code>zookeeper.sasl.client=false zu den Eigenschaften hinzu. system.setproperty("zookeeper.sasl.client", "false");,如果是spring boot项目可以在application.properties中加入zookeeper.sasl.client=false。
参考: increased cpu usage by unnecessary sasl checks 。
如果更换canal.client.jar中依赖的zookeeper.jar的版本
把canal的官方源码下载到本机git clone ,然后修改client模块下pom.xml文件中关于zookeeper的内容,然后重新mvn install:
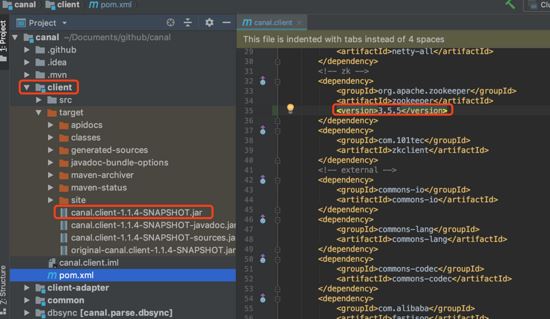
把自己项目依赖的包替换为刚刚mvn installReferenz: Erhöhte CPU-Auslastung durch unnötige Sasl-Prüfungen.
Wenn Sie die Version von zookeeper.jar ändern, hängt canal.client.jar davon ab. 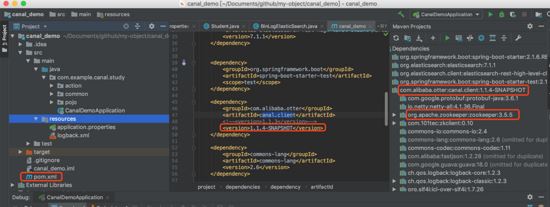
mvn install:# 🎜🎜##🎜🎜##🎜🎜##🎜🎜#Das obige ist der detaillierte Inhalt vonSo implementieren Sie die inkrementelle Datenübertragungsfunktion von MySQL in Echtzeit basierend auf Docker und Canal. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!