
Heim >Datenbank >MySQL-Tutorial >Beispielanalyse für den MySQL-Datenpersistenzprozess
Beispielanalyse für den MySQL-Datenpersistenzprozess

- PHPznach vorne
- 2023-05-26 17:52:171044Durchsuche
1. Kurze Beschreibung des Prozesses
Das Verständnis des Persistenzprozesses von MySQL-Daten kann uns helfen, unser Verständnis des zugrunde liegenden MySQL zu vertiefen. In diesem Artikel werden wir diesen Prozess auf beliebte Weise klären, um jedem zu helfen, ein vorläufiges Verständnis zu entwickeln. Wenn Sie interessiert sind, können Sie diesen Prozess eingehend studieren und erforschen.
Die MySQL-Datenspeicherung lässt sich im Allgemeinen in zwei Teile unterteilen: die gespeicherten Prozeduren im Speicher und die dauerhafte Speicherung auf der Festplatte. Dabei handelt es sich um Pufferabfrage und Redo-Log im Speicher. code> und <code>Transaktionsprotokoll und Tabellenstruktur auf der Festplatte In diesem Artikel werden wir das spezifische Design der einzelnen Teile nicht im Detail erklären, sondern Ihnen nur ein konzeptionelles Verständnis vermitteln: buffer poll和redo log以及磁盘上的事务日志和表结构,在本文中,我们不具体解释每一部分的具体设计,只是给大家一个概念型的认识:
buffer poll是InnoDB引擎缓存池的一部分,我们这里可以简单理解为数据库从磁盘读进内存的内存块的缓存;redo log是内存中的逻辑日志,记录了事务的变更操作事务日志是磁盘上的食物逻辑日志表结构是真正存储数据的结构
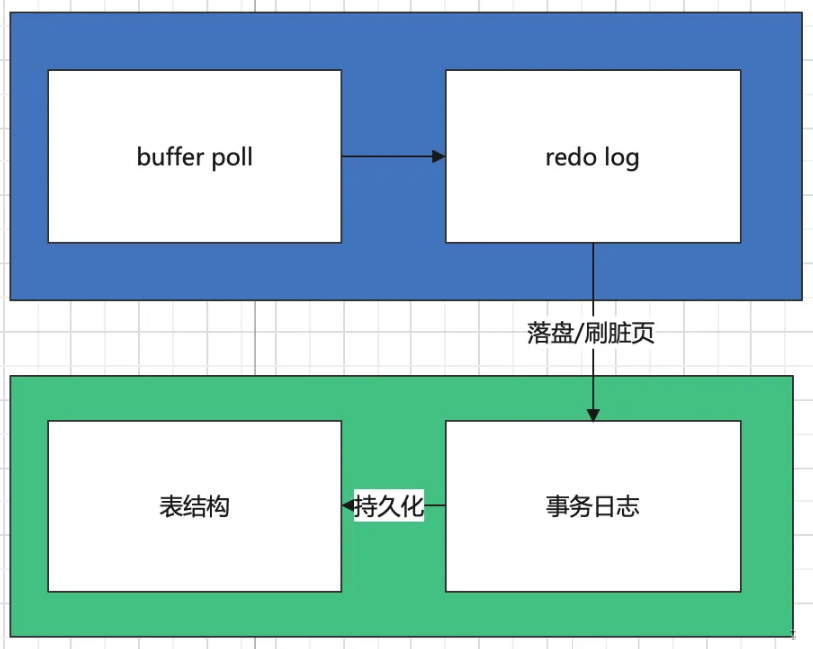
2. 内存中的操作
buffer poll中有对于读入内存的数据的缓存,在查询命令执行时,会优先在缓存中查看是否命中,未命中就会从磁盘中将需要的数据读进来,缓存的管理使用的是改良的LRU算法,这里不做深入地介绍了。
当一条修改指令运行的时候,首先进行的是对于buffer poll中缓存的修改,被修改后的数据会被标记为脏页,同时,修改的操作也会记录在redo log中,我们常说的MVCC中的版本链就是借助redo log实现的。
需要注意的是,脏页不是立刻落到磁盘的,而是有可以设置的刷盘控制机制,例如,一个事务执行结算后立刻落盘,按照一定时间定期落盘等等。
在内存中的操作都是非持久化的,如果这时发生了意料之外的问题导致系统宕机,数据是还没有持久化的,所以理论上也不会对数据库造成破坏性的影响。
3. 磁盘的持久化
3.1 事务日志的作用
InnoDB在磁盘的持久化分为两步,第一步是逻辑日志的存储,之后再将日志中的数据刷进磁盘空间。
在讨论为什么要使用逻辑日志之前,我们需要简单理解随机IO与顺序IO的区别:
寻址过程是磁盘IO中的一个重要瓶颈,因为它需要将探针移动到需要读取的位置来读取磁盘数据。
顺序IO是指寻址的空间是连续的,移动距离很短,随机IO是指我们需要寻找的地址分布在各处,需要移动很长的距离。
所以,我们能很明晰的得出结论:将随机IO替换为顺序IO
-
buffer pollist Teil des InnoDB-Engine-Cache-Pools. Wir können ihn hier einfach als den Cache der Speicherblöcke verstehen, die die Datenbank speichert liest von der Festplatte in den Speicher. -
redo logist ein logisches Protokoll im Speicher, das Transaktionsänderungsvorgänge aufzeichnet -
TransaktionsprotokollEs ist das logische Lebensmittelprotokoll auf der Festplatte -
Tabellenstrukturist die Struktur, in der tatsächlich Daten gespeichert werden
 2. In-Memory-Operationen🎜🎜buffer poll Es gibt einen Cache für die in den Speicher eingelesenen Daten. Wenn der Abfragebefehl ausgeführt wird, wird zunächst geprüft, ob ein Treffer im Cache vorhanden ist wird von der Festplatte eingelesen. Der LRU-Algorithmus wird hier nicht näher vorgestellt. 🎜🎜Wenn eine Änderungsanweisung ausgeführt wird, müssen Sie zunächst den Cache in
2. In-Memory-Operationen🎜🎜buffer poll Es gibt einen Cache für die in den Speicher eingelesenen Daten. Wenn der Abfragebefehl ausgeführt wird, wird zunächst geprüft, ob ein Treffer im Cache vorhanden ist wird von der Festplatte eingelesen. Der LRU-Algorithmus wird hier nicht näher vorgestellt. 🎜🎜Wenn eine Änderungsanweisung ausgeführt wird, müssen Sie zunächst den Cache in buffer poll ändern. Die geänderten Daten werden gleichzeitig als dirty page markiert Gleichzeitig werden Änderungsvorgänge auch im Redo-Log aufgezeichnet. Die Versionskette in MVCC wird oft mit Hilfe von Redo-Log implementiert. 🎜🎜Es ist zu beachten, dass verschmutzte Seiten nicht sofort auf die Festplatte gelöscht werden, es jedoch einen Flush-Kontrollmechanismus gibt, der festgelegt werden kann. Beispielsweise wird eine Transaktion sofort nach der Abrechnung auf die Festplatte gelöscht und entsprechend regelmäßig auf die Festplatte gelöscht eine bestimmte Zeit usw. 🎜🎜Alle Vorgänge im Speicher sind nicht persistent. Wenn ein unerwartetes Problem auftritt und das System abstürzt, wurden die Daten nicht gespeichert, sodass sie theoretisch keine destruktiven Auswirkungen auf die Datenbank haben. 🎜🎜3. Festplattenpersistenz🎜🎜3.1 Die Rolle des Transaktionsprotokolls🎜🎜Die Persistenz von InnoDB auf der Festplatte besteht darin, das logische Protokoll zu speichern und dann die Daten im Protokoll auf den Festplattenspeicher zu übertragen. 🎜🎜Bevor wir diskutieren, warum wir logische Protokolle verwenden sollten, müssen wir kurz den Unterschied zwischen Random IO und Sequential IO verstehen:🎜🎜Die Adressierung Der Prozess stellt einen erheblichen Engpass bei der Festplatten-E/A dar, da er das Verschieben der Sonde an die Stelle erfordert, an der sie gelesen werden muss, um Festplattendaten zu lesen. 🎜🎜Sequentielle E/A bedeutet, dass der adressierte Raum kontinuierlich ist und die Bewegungsdistanz sehr kurz ist. Zufällige E/A bedeutet, dass die Adresse, die wir finden müssen, überall verteilt ist und sein muss bewegte sich sehr schnell über weite Strecken. 🎜🎜Wir können also klar die Schlussfolgerung ziehen: Das Ersetzen von Random IO durch Sequential IO kann die Effizienz von Festplatten-IO effektiv verbessern. Dies ist genau die Rolle logischer Protokolle, da Da die Protokolldateien kontinuierlich auf der Festplatte gespeichert sind, kann die E/A-Effizienz im Vergleich zu den überall verteilten Datentabelleninformationen viel höher sein. 🎜🎜Solange wir den Vorgang im Transaktionsprotokoll vollständig aktualisieren, wurde die Transaktion erfolgreich beibehalten und ein dedizierter Thread ist für die Speicherung der Protokollinformationen in der Tabellenstruktur verantwortlich. 🎜🎜3.2 Zweistufige Speicherung der Tabellenstruktur🎜🎜Der Prozess der Speicherung von Protokollinformationen in der Tabellenstruktur ist in zwei Schritte unterteilt. Zunächst werden die Daten im Cache-Bereich des Tabellenkopfes aktualisiert Wenn der Vorgang abgeschlossen ist, werden die Daten in der entsprechenden Tabellenstruktur aktualisiert. 🎜🎜Der Zweck der zweistufigen Speicherung besteht darin, eine starke Konsistenz der Datenspeicherung sicherzustellen und zu verhindern, dass Daten aufgrund von Datenbankausfallzeiten während des Flashvorgangs auf die Festplatte unvollständig sind. 🎜🎜Der Cache-Bereich des Tabellenkopfes und der Speicherblock der Tabellenstruktur verfügen über Prüfcodes, um die Integrität der Daten zu überprüfen. Wenn ersterer vollständig und letzterer unvollständig ist, flashen Sie einfach die ersteren Daten erneut Letzteres löst das Problem. Wenn Ersteres unvollständig ist, bedeutet dies, dass der Vorgang des Leerens aus dem Protokoll fehlgeschlagen ist und Sie einfach erneut leeren können. 🎜Das obige ist der detaillierte Inhalt vonBeispielanalyse für den MySQL-Datenpersistenzprozess. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!